OmniRetriever: Any-to-Any Audio-Video-Text Retrieval via Fusion-as-Teacher Distillation
Pith reviewed 2026-06-29 18:05 UTC · model grok-4.3
The pith
A stop-gradient fused embedding acts as teacher to train stronger any-to-any audio-video-text retrievers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
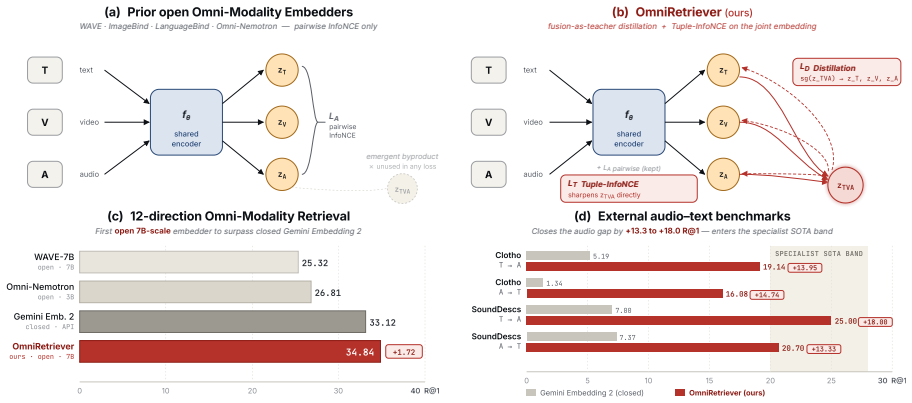
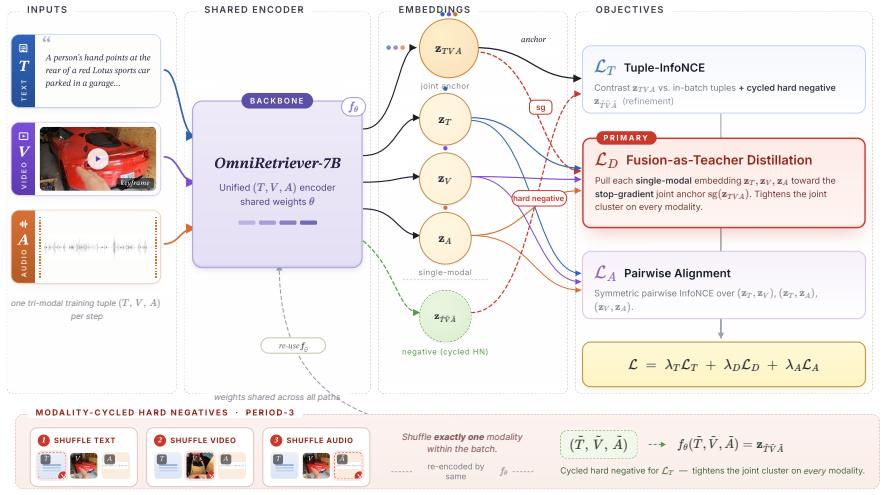
The central discovery is that fusion-as-teacher distillation, which applies a stop-gradient fused (T,V,A) embedding as teacher for the modality embeddings along with Tuple-InfoNCE on the fused embedding, produces better training than pairwise InfoNCE alone, leading to superior zero-shot performance on AVT retrieval benchmarks.
What carries the argument
Fusion-as-teacher distillation, where the joint embedding supervises its single-modal components via stop-gradient and direct Tuple-InfoNCE.
If this is right
- OmniRetriever-7B surpasses Gemini Embedding 2 by 13.3-18.0 R@1 on Clotho and SoundDescs.
- It reaches the zero-shot specialist performance band on MSR-VTT and MSVD.
- On OmniRetriever-Bench it scores 34.84 AVG-all, 1.72 above Gemini and 8.03 above prior open AVT methods.
- Any-to-any retrieval becomes feasible with one model across all modality combinations.
Where Pith is reading between the lines
- The distillation could allow training on datasets where not all modality triples are present by using available fusions.
- Similar teacher signals might improve other contrastive learning setups in multimodal settings.
- The new benchmark provides a standardized way to evaluate joint AVT representations beyond pairwise tasks.
Load-bearing premise
Using the fused embedding as a teacher via stop-gradient and Tuple-InfoNCE yields a better objective than pairwise InfoNCE without new biases or data needs.
What would settle it
Training an identical model with only standard pairwise InfoNCE and observing no performance drop or even gains on the reported benchmarks would falsify the advantage of the new objective.
Figures
read the original abstract
Unified multimodal embedding spaces have become the standard interface for cross-modal retrieval and multimodal RAG, and recent audio-video-text (AVT) encoders extend this setting to three modalities. Such encoders can produce a joint (T,V,A) embedding whenever all three modalities are available, but standard pairwise InfoNCE objectives leave this signal unused during training. We close this gap with fusion-as-teacher distillation, which treats a stop-gradient copy of the fused embedding as a teacher signal for the single-modal embeddings, paired with a Tuple-InfoNCE term that supervises the fused embedding directly. We instantiate this objective as OmniRetriever-7B. Across six zero-shot retrieval benchmarks, OmniRetriever-7B surpasses the closed-source Gemini Embedding 2 by 13.3-18.0 R@1 on Clotho and SoundDescs, and reaches the contemporary zero-shot specialist band of open video-text encoders on MSR-VTT and MSVD. To stress-test joint representations, we further release OmniRetriever-Bench, a 12-direction AVT retrieval benchmark totaling 3782 triples; on it OmniRetriever-7B attains AVG-all 34.84, improving over Gemini Embedding 2 by 1.72 and over the best prior open-source AVT method by 8.03.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces fusion-as-teacher distillation for any-to-any audio-video-text retrieval. A stop-gradient copy of the fused (T,V,A) embedding serves as a teacher signal for single-modal embeddings, combined with a Tuple-InfoNCE objective on the fused embedding itself. The resulting OmniRetriever-7B model is evaluated on six zero-shot benchmarks (Clotho, SoundDescs, MSR-VTT, MSVD and two others), claiming 13.3-18.0 R@1 gains over Gemini Embedding 2 on audio sets and parity with open video-text specialists on video-text sets. A new 12-direction OmniRetriever-Bench (3782 triples) is released, on which the model reports AVG-all of 34.84, exceeding Gemini by 1.72 and the best prior open AVT method by 8.03.
Significance. If the reported zero-shot gains and benchmark results hold under full experimental controls, the work provides a practical training recipe that exploits joint multimodal signals otherwise unused by standard pairwise InfoNCE. The public release of OmniRetriever-Bench supplies a concrete, falsifiable testbed for 12-way AVT retrieval that the community can use to measure progress on joint representations.
minor comments (3)
- [Abstract] Abstract and §4: the precise composition of the training data mixture, the number of epochs, and the temperature schedule for Tuple-InfoNCE are not stated; adding these would allow readers to reproduce the claimed deltas.
- [§3.2] §3.2: the exact formulation of Tuple-InfoNCE (positive/negative tuple construction and weighting) should be written as an equation rather than described in prose only.
- [Table 2] Table 2 and Table 3: report standard deviations over at least three random seeds for all R@1 numbers to confirm the 13+ point margins are stable.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new training recipe (fusion-as-teacher distillation using stop-gradient fused (T,V,A) embedding as teacher plus Tuple-InfoNCE) and evaluates it empirically on six named zero-shot retrieval benchmarks plus the released OmniRetriever-Bench. No equations, parameters, or claims are shown to reduce by construction to the target result itself; the objective is presented as an independent proposal rather than a self-definition, fitted-input renaming, or self-citation chain. The central performance claims are externally falsifiable via standard datasets and the new benchmark, satisfying the criteria for a self-contained, non-circular contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. 2021. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. Advances in neural information processing systems, 34:24206--24221
2021
-
[4]
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. 2017. Localizing moments in video with natural language. In Proceedings of the IEEE international conference on computer vision, pages 5803--5812
2017
-
[5]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, and 1 others. 2025. V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Bangalath, and 1 others. 2026. Perception encoder: The best visual embeddings are not at the output of the network. Advances in Neural Information Processing Systems, 38:60884--60937
2026
-
[8]
David Chen and William B Dolan. 2011. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pages 190--200
2011
- [9]
-
[10]
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. 2023. Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset. Advances in Neural Information Processing Systems, 36:72842--72866
2023
-
[11]
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, and 1 others. 2024. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2024
-
[12]
Konstantinos Drossos, Samuel Lipping, and Tuomas Virtanen. 2020. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 736--740. IEEE
2020
-
[13]
Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev, and Vaishaal Shankar. 2024. Data filtering networks. In International Conference on Learning Representations, volume 2024, pages 36221--36237
2024
-
[14]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, C \'e line Hudelot, and Pierre Colombo. 2025. Colpali: Efficient document retrieval with vision language models. In International Conference on Learning Representations, volume 2025, pages 61424--61449
2025
-
[15]
Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, Sai Aitharaju, Victor G Turrisi da Costa, Louis B \'e thune, Zhe Gan, and 1 others. 2025. Multimodal autoregressive pre-training of large vision encoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9641--9654
2025
-
[16]
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 2023. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15180--15190
2023
-
[17]
Andrey Guzhov, Federico Raue, J \"o rn Hees, and Andreas Dengel. 2022. Audioclip: Extending clip to image, text and audio. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 976--980. IEEE
2022
-
[18]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904--4916. PMLR
2021
-
[19]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. 2024. Vlm2vec: Training vision-language models for massive multimodal embedding tasks. arXiv preprint arXiv:2410.05160
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 119--132
2019
-
[21]
A Sophia Koepke, Andreea-Maria Oncescu, Jo \ a o F Henriques, Zeynep Akata, and Samuel Albanie. 2022. Audio retrieval with natural language queries: A benchmark study. IEEE Transactions on Multimedia, 25:2675--2685
2022
-
[22]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2025 a . Nv-embed: Improved techniques for training llms as generalist embedding models. In International Conference on Learning Representations, volume 2025, pages 79310--79333
2025
-
[23]
Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gustavo Hern \'a ndez \'A brego, Zhe Li, Kaifeng Chen, Henrique Schechter Vera, and 1 others. 2025 b . Gemini embedding: Generalizable embeddings from gemini. arXiv preprint arXiv:2503.07891
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, and 1 others. 2026. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. arXiv preprint arXiv:2601.04720
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. 2025. Mm-embed: Universal multimodal retrieval with multimodal llms. In International Conference on Learning Representations, volume 2025, pages 44215--44234
2025
-
[26]
Yunze Liu, Qingnan Fan, Shanghang Zhang, Hao Dong, Thomas Funkhouser, and Li Yi. 2021. Contrastive multimodal fusion with tupleinfonce. In Proceedings of the IEEE/CVF international conference on computer vision, pages 754--763
2021
- [27]
- [28]
-
[29]
Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji. 2022. X-clip: End-to-end multi-grained contrastive learning for video-text retrieval. In Proceedings of the 30th ACM international conference on multimedia, pages 638--647
2022
-
[30]
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuexian Zou, and Wenwu Wang. 2024. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:3339--3354
2024
-
[31]
John Morris, Volodymyr Kuleshov, Vitaly Shmatikov, and Alexander M Rush. 2023. Text embeddings reveal (almost) as much as text. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12448--12460
2023
-
[32]
Daisuke Niizumi, Daiki Takeuchi, Masahiro Yasuda, Binh Thien Nguyen, Yasunori Ohishi, and Noboru Harada. 2025. M2d-clap: Exploring general-purpose audio-language representations beyond clap. IEEE Access
2025
-
[33]
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. 2022. Balanced multimodal learning via on-the-fly gradient modulation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8238--8247
2022
-
[34]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PmLR
2021
-
[35]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, and 1 others. 2022. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in neural information processing systems, 35:25278--25294
2022
-
[36]
Oriane Sim \'e oni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha \"e l Ramamonjisoa, and 1 others. 2025. Dinov3. arXiv preprint arXiv:2508.10104
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
- [38]
-
[39]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, and 1 others. 2025. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024 a . Improving text embeddings with large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11897--11916
2024
-
[41]
Weiyao Wang, Du Tran, and Matt Feiszli. 2020. What makes training multi-modal classification networks hard? In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12695--12705
2020
-
[42]
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. 2019. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4581--4591
2019
-
[43]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, and 1 others. 2024 b . Internvid: A large-scale video-text dataset for multimodal understanding and generation. In The Twelfth International Conference on Learning Representations
2024
-
[44]
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, and 1 others. 2024 c . Internvideo2: Scaling foundation models for multimodal video understanding. In European conference on computer vision, pages 396--416. Springer
2024
-
[45]
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. 2024. Uniir: Training and benchmarking universal multimodal information retrievers. In European Conference on Computer Vision, pages 387--404. Springer
2024
-
[46]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE
2023
-
[47]
Hu Xu, Saining Xie, Xiaoqing Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, and Christoph Feichtenhofer. 2024. Demystifying clip data. In International Conference on Learning Representations, volume 2024, pages 47812--47831
2024
-
[48]
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. 2016. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288--5296
2016
- [49]
-
[50]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11975--11986
2023
-
[51]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. 2024. Gme: improving universal multimodal retrieval by multimodal llms. arXiv preprint arXiv:2412.16855
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, WANG HongFa, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, and 1 others. 2024. Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment. In International Conference on Learning Representations, volume 2024, pages 9588--9608
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.