Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation
Pith reviewed 2026-06-29 17:54 UTC · model grok-4.3
The pith
Explicit planning in LLM agents for CUDA kernel generation works only when feedback is aligned.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
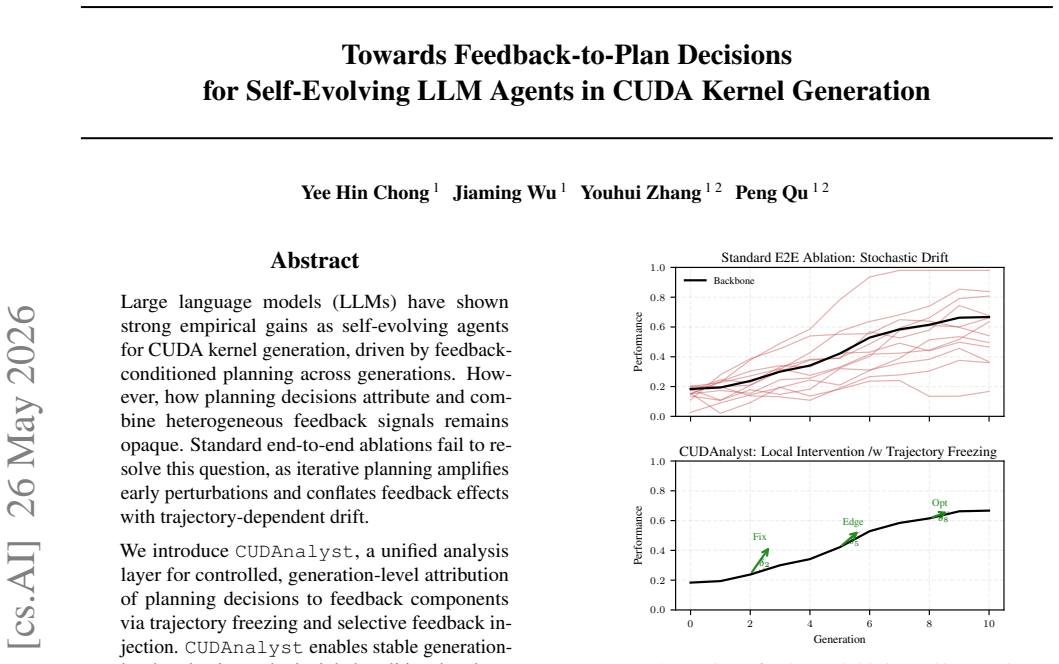
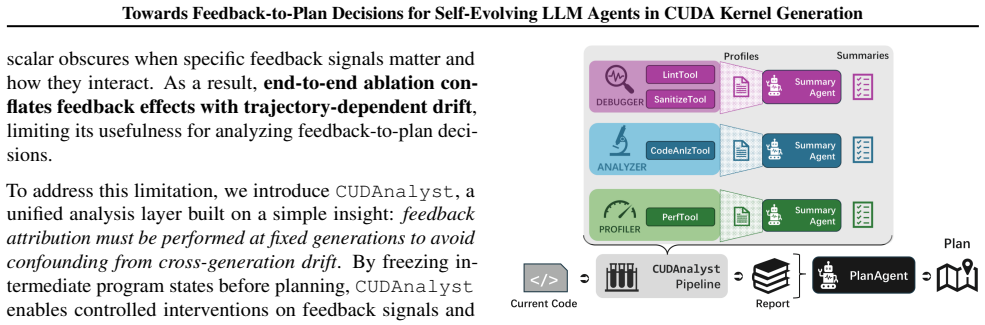
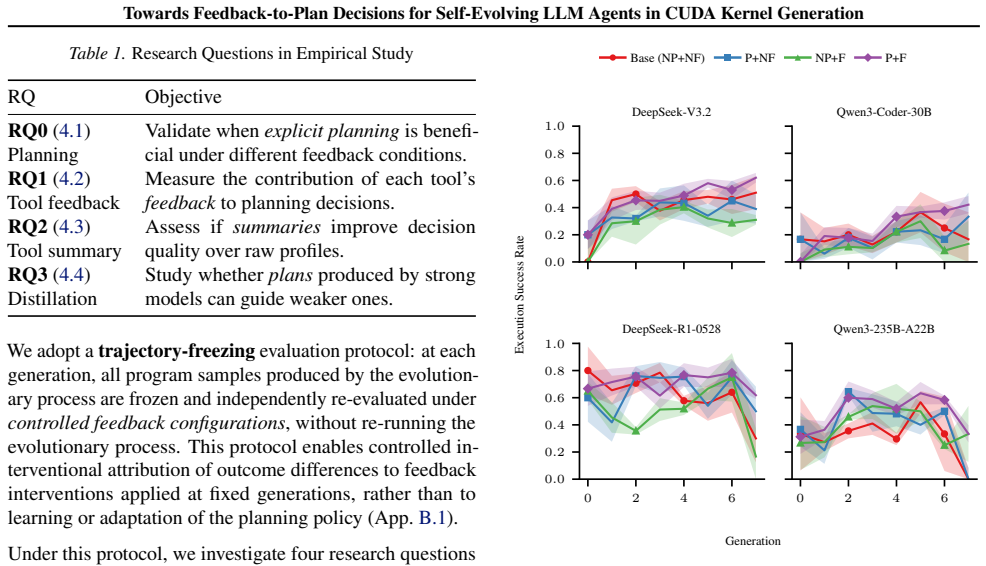
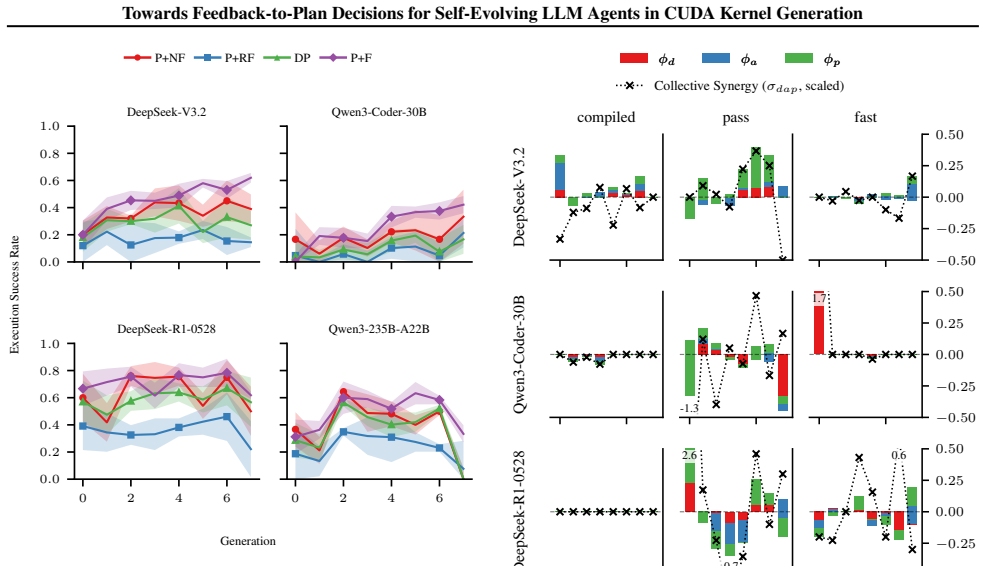
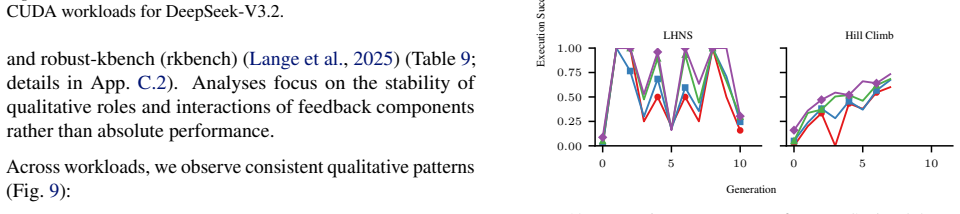
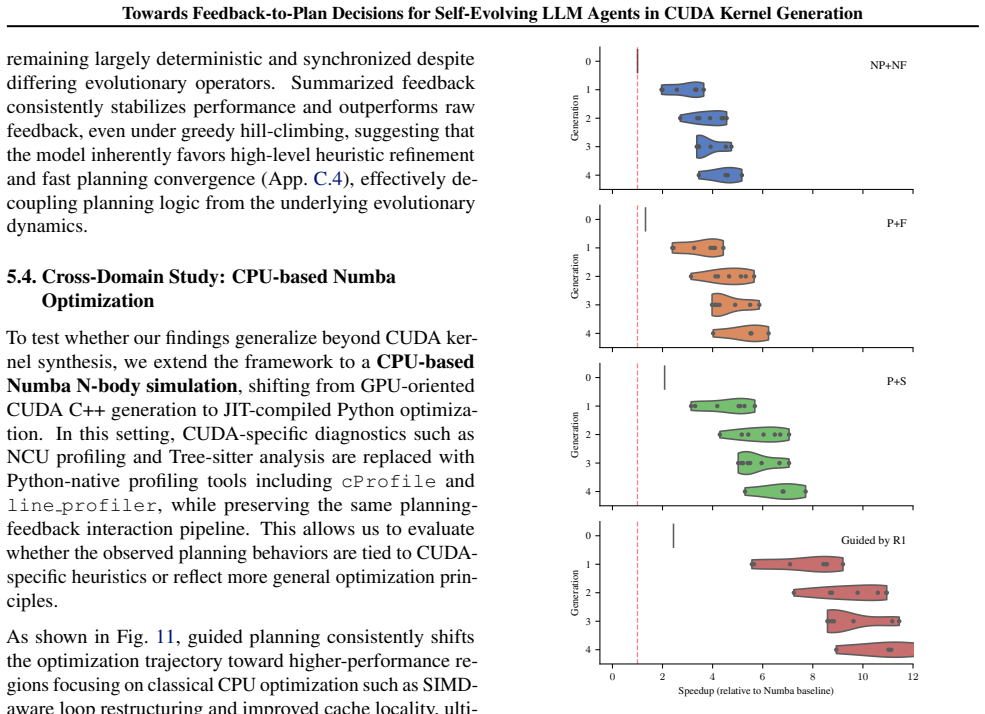
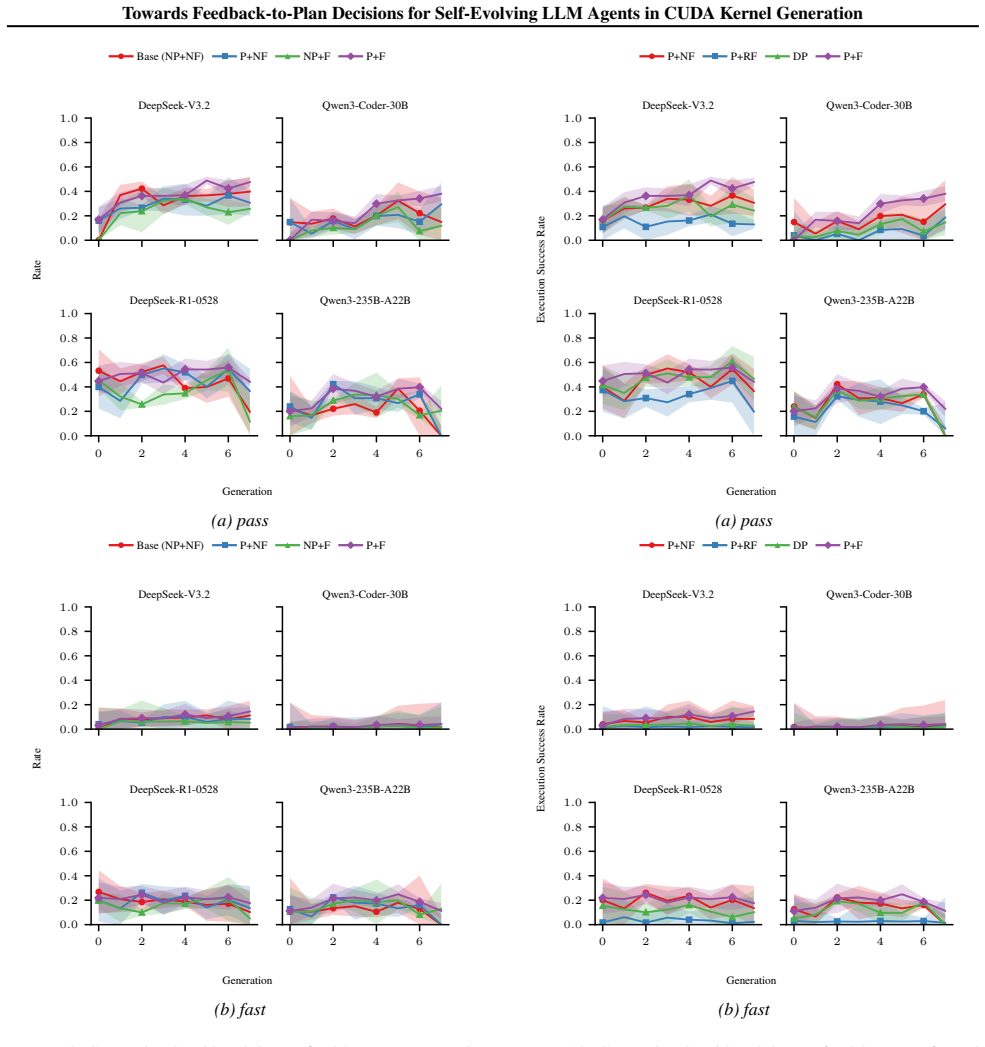
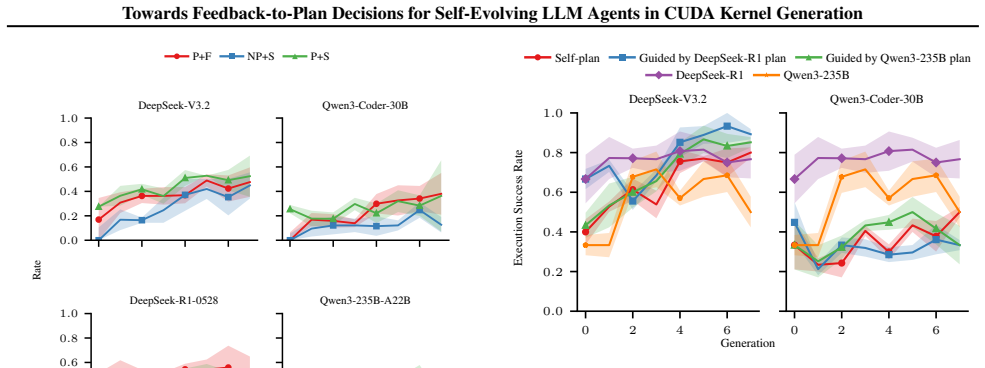
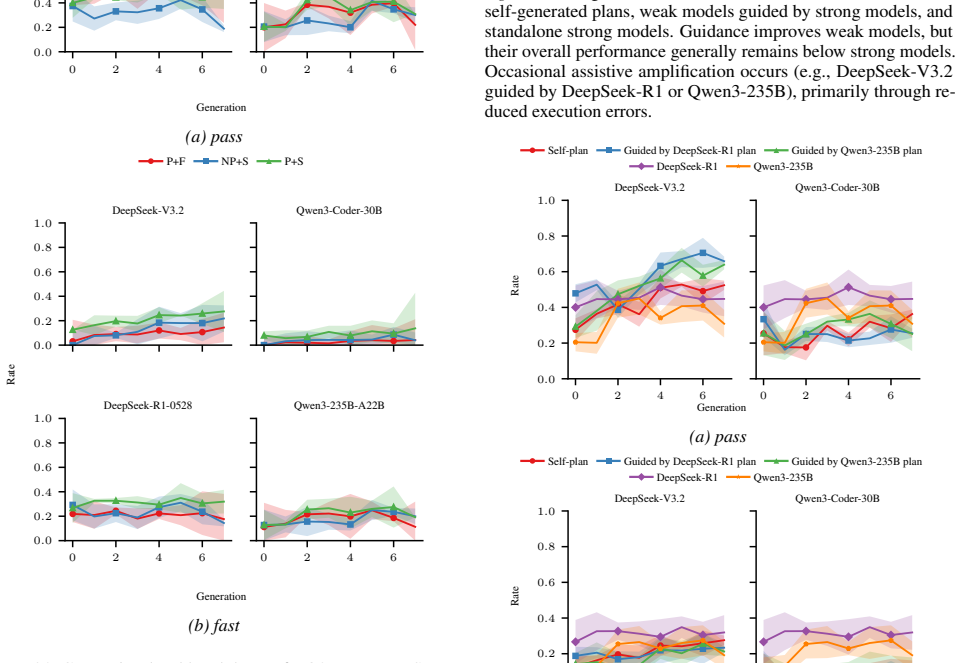
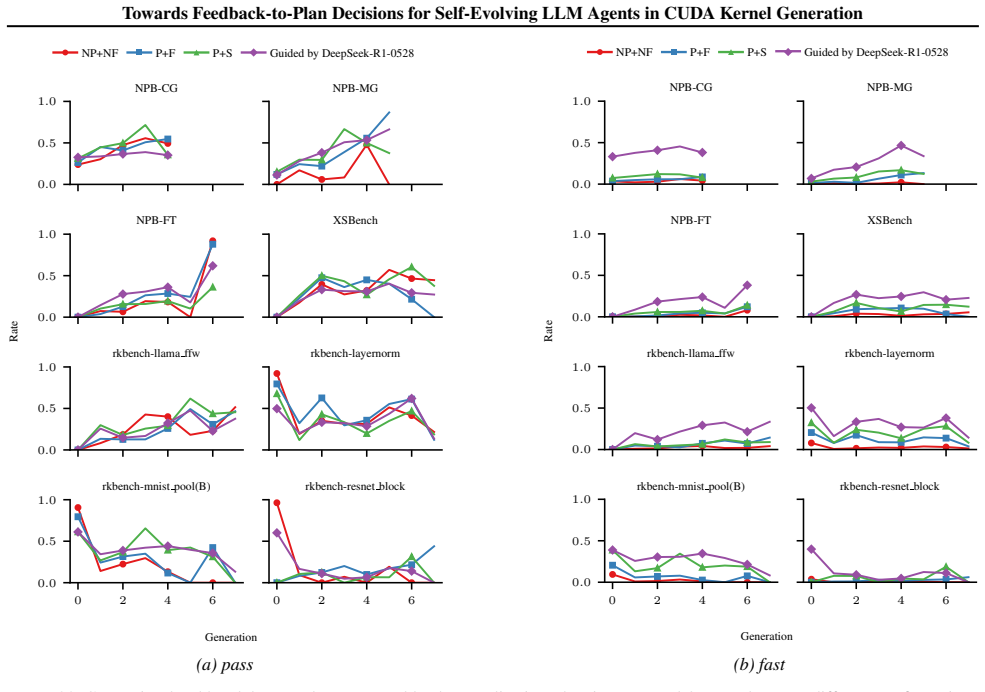
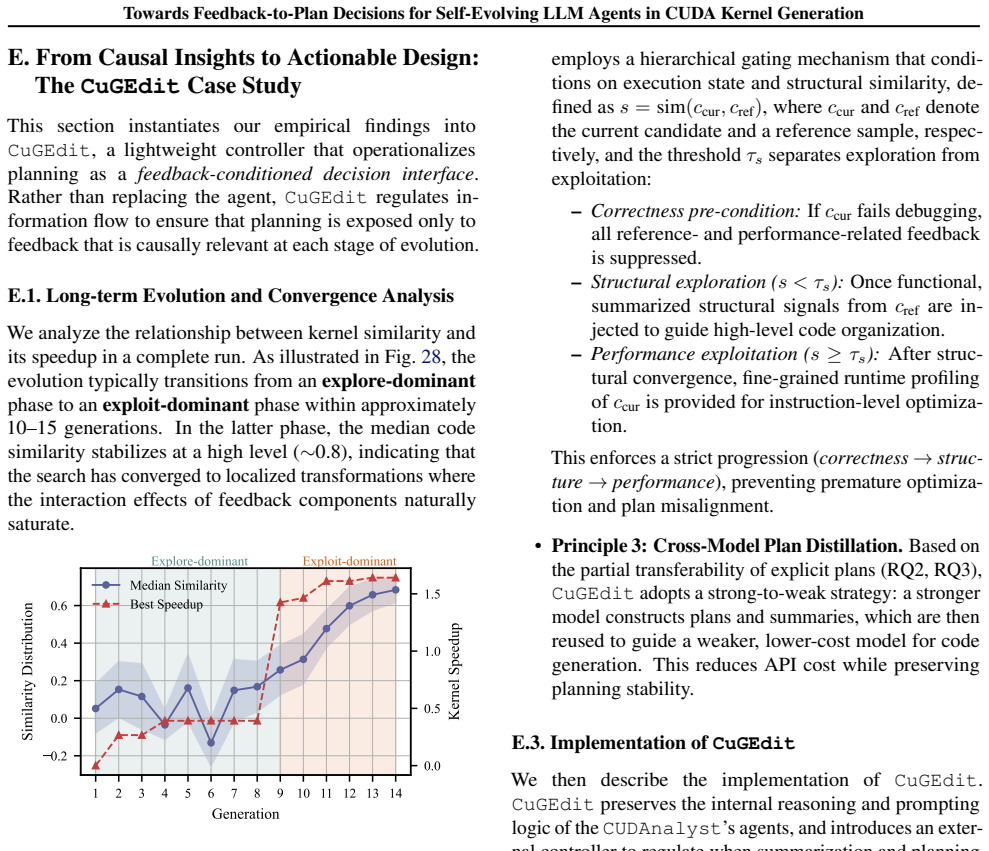
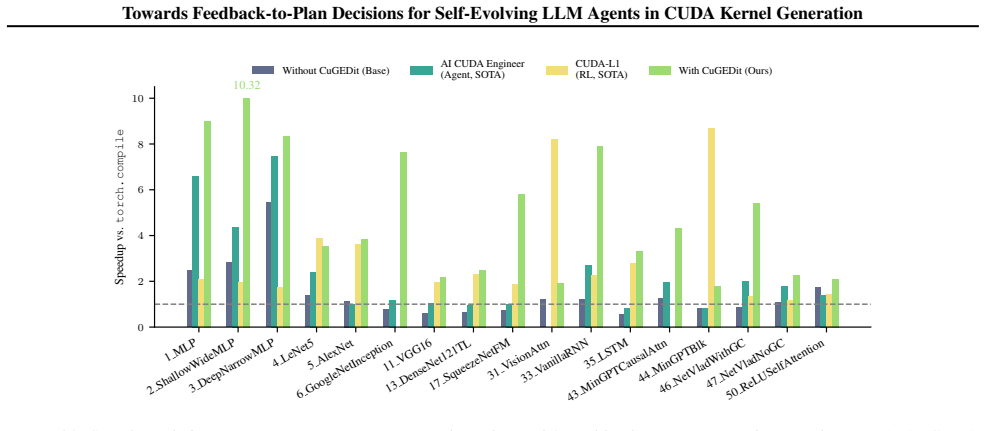
CUDAnalyst is a unified analysis layer that performs controlled, generation-level attribution of planning decisions to feedback components by means of trajectory freezing and selective feedback injection. Using it, the work establishes that explicit planning is beneficial only when feedback is aligned, that effective planning emerges from structured multi-feedback interactions, and that high-level plans from stronger reasoning models can partially transfer to weaker ones. These relations hold across reference backbones, representative workloads, and reference induction regimes.
What carries the argument
CUDAnalyst, an analysis layer that freezes trajectories and injects selected feedback signals to enable stable generation-level evaluation and coalitional-style attribution of feedback effects.
If this is right
- Explicit planning improves kernel generation outcomes solely when feedback signals remain aligned across iterations.
- Planning effectiveness arises from structured interactions among heterogeneous feedback signals rather than from any single signal.
- High-level plans produced by stronger reasoning models transfer partially to weaker models.
- The identified feedback-to-plan structure remains consistent across different model backbones, workloads, and induction regimes.
Where Pith is reading between the lines
- The same attribution technique could be applied to self-evolving agents in other code-generation or optimization domains to test whether aligned feedback is universally required.
- Agent designs might shift from adding more feedback to engineering explicit alignment mechanisms between signals.
- Partial plan transfer suggests practical hierarchies in which a strong model generates plans once and weaker models execute them repeatedly.
- The work implies that future evaluations of self-evolving agents should routinely separate planning attribution from trajectory drift.
Load-bearing premise
Trajectory freezing combined with selective feedback injection produces stable generation-level evaluations that do not themselves alter the natural planning dynamics or introduce new trajectory-dependent drift beyond what the paper controls for.
What would settle it
An experiment in which the reported benefits of aligned feedback vanish or reverse once trajectory freezing is removed while keeping all other factors fixed.
Figures



read the original abstract
Large language models (LLMs) have shown strong empirical gains as self-evolving agents for CUDA kernel generation, driven by feedback-conditioned planning across generations. However, how planning decisions attribute and combine heterogeneous feedback signals remains opaque. Standard end-to-end ablations fail to resolve this question, as iterative planning amplifies early perturbations and conflates feedback effects with trajectory-dependent drift. We introduce \texttt{CUDAnalyst}, a unified analysis layer for controlled, generation-level attribution of planning decisions to feedback components via trajectory freezing and selective feedback injection. \texttt{CUDAnalyst} enables stable generation-level evaluation and principled coalitional-style attribution of feedback effects and interactions. Our results show that explicit planning is beneficial only when feedback is aligned, that effective planning emerges from structured multi-feedback interactions, and that high-level plans from stronger reasoning models can partially transfer to weaker ones. These trends hold across reference backbones, representative workloads, and reference induction regimes, indicating that the identified feedback-to-plan structure is robust within the controlled axes studied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CUDAnalyst, a unified analysis layer for controlled generation-level attribution of planning decisions to heterogeneous feedback signals in self-evolving LLM agents for CUDA kernel generation. It employs trajectory freezing and selective feedback injection to enable stable evaluations and coalitional-style attribution of feedback effects and interactions. The reported results indicate that explicit planning is beneficial only when feedback is aligned, that effective planning emerges from structured multi-feedback interactions, and that high-level plans from stronger reasoning models can partially transfer to weaker ones; these trends are claimed to hold across reference backbones, representative workloads, and reference induction regimes.
Significance. If the controlled evaluations prove faithful, the work provides useful empirical insights into feedback-to-plan mechanisms in LLM agents for code generation, which could inform the design of more interpretable and effective self-evolving systems. The coalitional-style attribution approach represents a structured way to dissect multi-signal interactions that standard end-to-end ablations cannot resolve.
major comments (1)
- [CUDAnalyst framework description (Methods)] The central claims depend on trajectory freezing combined with selective feedback injection producing stable generation-level evaluations without altering natural planning dynamics or introducing new trajectory-dependent drift. The manuscript provides no quantitative validation (e.g., comparisons of planning statistics, decision distributions, or kernel performance between frozen and open trajectories under identical feedback regimes) to confirm this. This assumption is load-bearing for the attribution results and the reported trends on aligned feedback, multi-feedback emergence, and plan transfer.
minor comments (1)
- [Abstract] The abstract states clear empirical trends but provides no quantitative details on effect sizes, statistical controls, workload selection criteria, or feedback definition choices, limiting immediate assessment of result robustness.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below and agree that additional validation is warranted.
read point-by-point responses
-
Referee: [CUDAnalyst framework description (Methods)] The central claims depend on trajectory freezing combined with selective feedback injection producing stable generation-level evaluations without altering natural planning dynamics or introducing new trajectory-dependent drift. The manuscript provides no quantitative validation (e.g., comparisons of planning statistics, decision distributions, or kernel performance between frozen and open trajectories under identical feedback regimes) to confirm this. This assumption is load-bearing for the attribution results and the reported trends on aligned feedback, multi-feedback emergence, and plan transfer.
Authors: We agree that the manuscript does not contain explicit quantitative comparisons validating that trajectory freezing preserves natural planning dynamics. The method description presents freezing as a controlled intervention that holds the generation trajectory fixed until the selected feedback injection point, but no direct statistics (e.g., decision distributions or performance deltas) between frozen and open runs are reported. In the revised manuscript we will add these comparisons under matched feedback regimes to confirm stability and thereby support the attribution claims. revision: yes
Circularity Check
No circularity: empirical results from controlled experiments
full rationale
The paper introduces CUDAnalyst as an analysis layer using trajectory freezing and selective feedback injection to enable generation-level attribution, then reports empirical trends observed across multiple backbones, workloads, and regimes. No equations, fitted parameters, or derivation steps are presented that reduce by construction to self-defined quantities, self-citations, or renamed inputs. The central claims rest on experimental observations rather than any load-bearing self-referential structure, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
CUDAnalyst
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chan, C.-M., Yu, J., Chen, W., Jiang, C., Liu, X., Chi, X., Shi, W., Liu, Z., Xue, W., and Guo, Y
URL https://openreview.net/forum? id=DzGe40glxs. Chan, C.-M., Yu, J., Chen, W., Jiang, C., Liu, X., Chi, X., Shi, W., Liu, Z., Xue, W., and Guo, Y . Agentmonitor: A plug-and-play framework for predictive and secure multi- agent systems, 2024. URL https://openreview. net/forum?id=gKM8wwsTOg. Chen, J., Wu, Q., Li, B., Ma, L., Si, X., Hu, Y ., Yin, S., and Y...
-
[2]
URL https://openreview.net/forum? id=nWaZTH1JMx. Grabisch, M. and Roubens, M. An axiomatic approach to the concept of interaction among players in coop- erative games.International Journal of Game The- ory, 28(4):547–565, Nov 1999. ISSN 1432-1270. doi: 10.1007/s001820050125. URL https://doi.org/ 10.1007/s001820050125. Grauer-Gray, S., Xu, L., Searles, R.,...
-
[3]
URL https://openreview.net/forum? id=LU27DiW5ik. Ivanov, I. R., Zinenko, O., Domke, J., Endo, T., and Moses, W. S. Retargeting and respecializing gpu work- loads for performance portability. InProceedings of the 2024 IEEE/ACM International Symposium on Code Generation and Optimization, CGO ’24, pp. 119–132. IEEE Press, 2024. ISBN 9798350395099. doi: 10. 1...
-
[4]
Kriege, N
URL https://openreview.net/forum? id=c339hUw3cy. Kriege, N. and Mutzel, P. Subgraph matching kernels for attributed graphs. InProceedings of the 29th Interna- tional Coference on International Conference on Machine Learning, ICML’12, pp. 291–298, Madison, WI, USA,
-
[5]
Omnipress. ISBN 9781450312851. Lange, R. T., Sun, Q., Prasad, A., Faldor, M., Tang, Y ., and Ha, D. Towards robust agentic cuda kernel benchmarking, verification, and optimization, 2025. URL https:// arxiv.org/abs/2509.14279. Lange, R. T., Imajuku, Y ., and Cetin, E. Shinkaevolve: Towards open-ended and sample-efficient program evo- lution. InThe Fourteen...
-
[6]
URL https://proceedings.mlr
PMLR. URL https://proceedings.mlr. press/v5/shervashidze09a.html. Shervashidze, N., Schweitzer, P., van Leeuwen, E. J., Mehlhorn, K., and Borgwardt, K. M. Weisfeiler-lehman graph kernels.Journal of Machine Learning Research, 12(77):2539–2561, 2011. URL http://jmlr.org/ papers/v12/shervashidze11a.html. Siglidis, G., Nikolentzos, G., Limnios, S., Giatsidis,...
2011
-
[7]
Vatai, E., Drozd, A., Ivanov, I
URL https://openreview.net/forum? id=a5aJi9OAr0. Vatai, E., Drozd, A., Ivanov, I. R., Batista, J. E., Ren, Y ., and Wahib, M. Tadashi: Enabling ai-based automated code generation with guaranteed correctness, 2025. URL https://arxiv.org/abs/2410.03210. Verdoolaege, S. and Grosser, T. Polyhedral extrac- tion tool. InSecond International Workshop on Polyhedr...
-
[8]
- Use cp.async for global to shared transfers and apply double-buffered pipelines
Memory hierarchy & parallel structure - Use shared-memory tiling with aggressive reuse. - Use cp.async for global to shared transfers and apply double-buffered pipelines. - Fuse elementwise ops to eliminate redundant global traffic. - Avoid shared-memory bank conflicts; apply padding/skew when required. - Use vectorized loads/stores ( float4, int4) when a...
-
[9]
- Expose multiple independent MMA ops per warp to increase ILP (instruction-level parallelism)
Tensor Core compute - Use WMMA or mma.sync paths with hardware- aligned MMA tiles (e.g., 16×16×16). - Expose multiple independent MMA ops per warp to increase ILP (instruction-level parallelism). - Use FP32 accumulation for mixed-precision math
-
[10]
- Pick tile sizes that fit SMEM and register budgets (e.g., 64×64×16 as baseline)
Loop transformations - Apply in this order: Tile, Unroll, Skew/Permute, Double-buffer. - Pick tile sizes that fit SMEM and register budgets (e.g., 64×64×16 as baseline). - Fully unroll the inner K-loop to deepen ILP
-
[11]
Occupancy constraints - Choose thread-block sizes that are multiples of 32 (128/256/512 recommended)
-
[12]
- Provide a portable CUDA path and an architecture- tuned fast path
Micro-optimizations - Use inline PTX only where profiling would show un- avoidable hotspots. - Provide a portable CUDA path and an architecture- tuned fast path. B.2. Attributing the Benefits of Explicit Planning to Feedback (RQ0) Counterfactual Controls for Feedback-Aligned Planning To disentangle feedback-aligned planning from superficial prompt or budg...
-
[13]
- **Rationale**: Ensures that the codebase remains aligned with general programming best practices and modularity standards
**Standard Module Review** - **Action**: Con- 17 Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation duct a systematic review of all active functions and data structures within the current scope. - **Rationale**: Ensures that the codebase remains aligned with general programming best practices and modularity standards
-
[14]
- **Rationale**: Val- idates that the input-output relationship remains within expected nominal ranges
**Data Flow Verification** - **Action**: Trace the movement of information across the primary interfaces to confirm consistent state transitions. - **Rationale**: Val- idates that the input-output relationship remains within expected nominal ranges. #### [Step 2: Stability Enhancements]
-
[15]
**General Logic Refinement** - Apply standard opti- mization passes to the main execution loops to ensure no redundant operations are performed
-
[16]
#### [Step 3: Future Considerations]
**Interface Synchronization** - Review inter-module communication protocols to ensure optimal handshake timing and resource locking. #### [Step 3: Future Considerations]
-
[17]
**System Profiling** - Utilize standard profiling tools to gather telemetry on execution patterns for future com- parative analysis
-
[18]
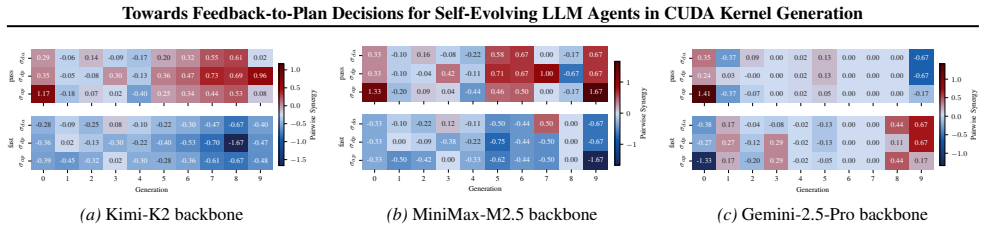
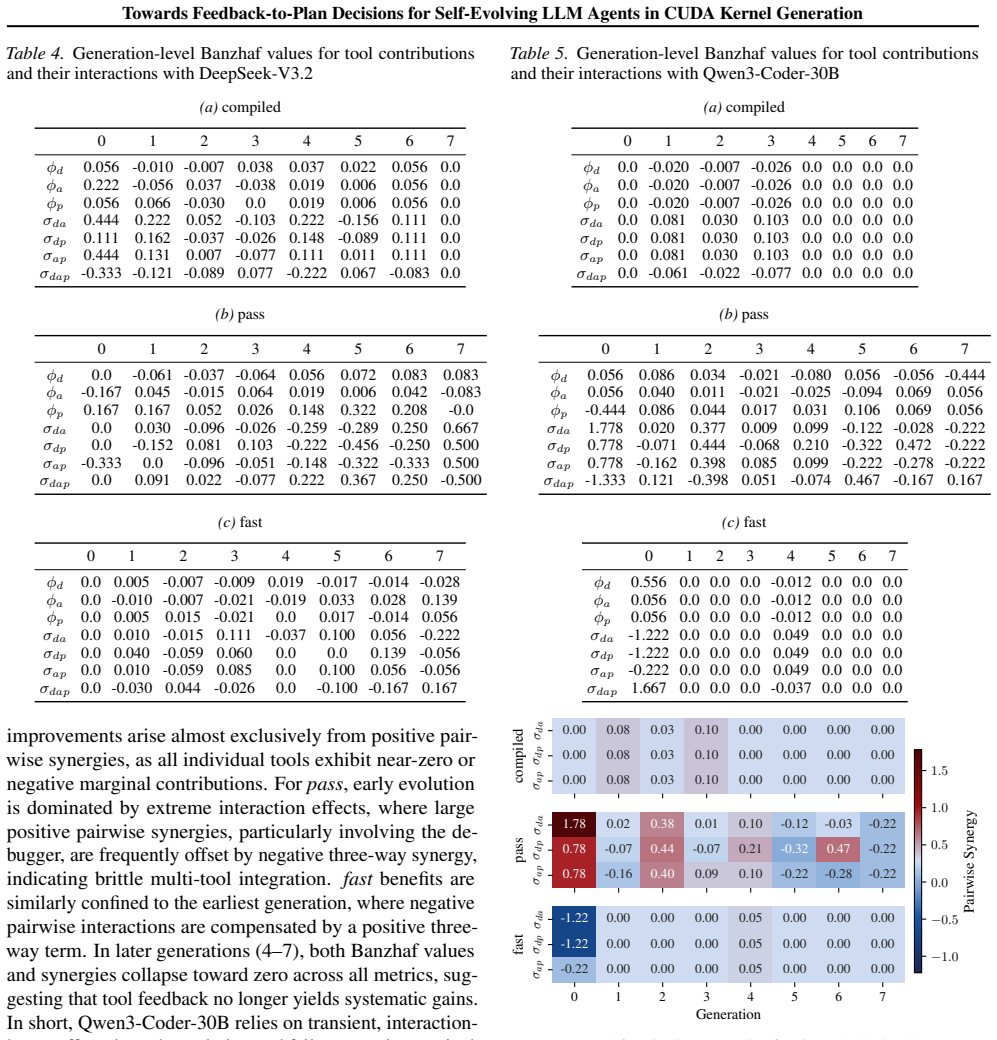
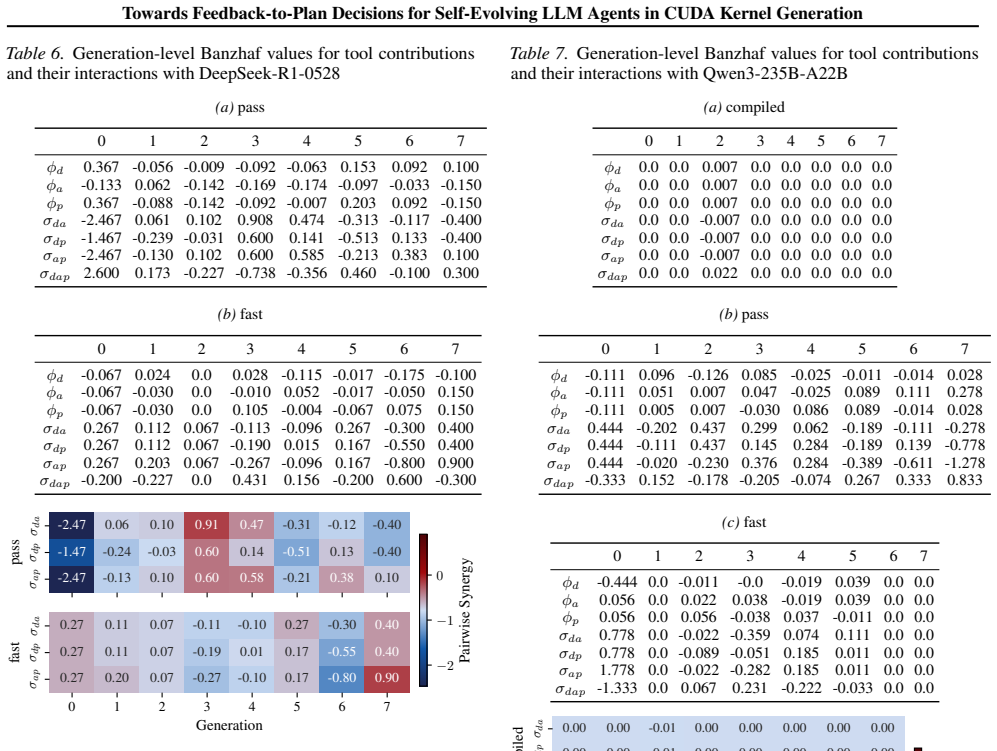
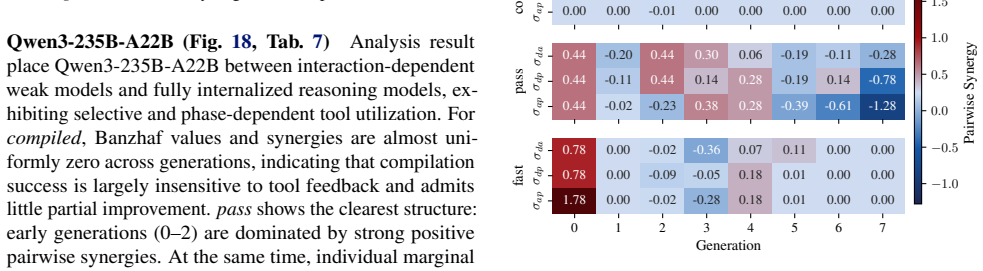
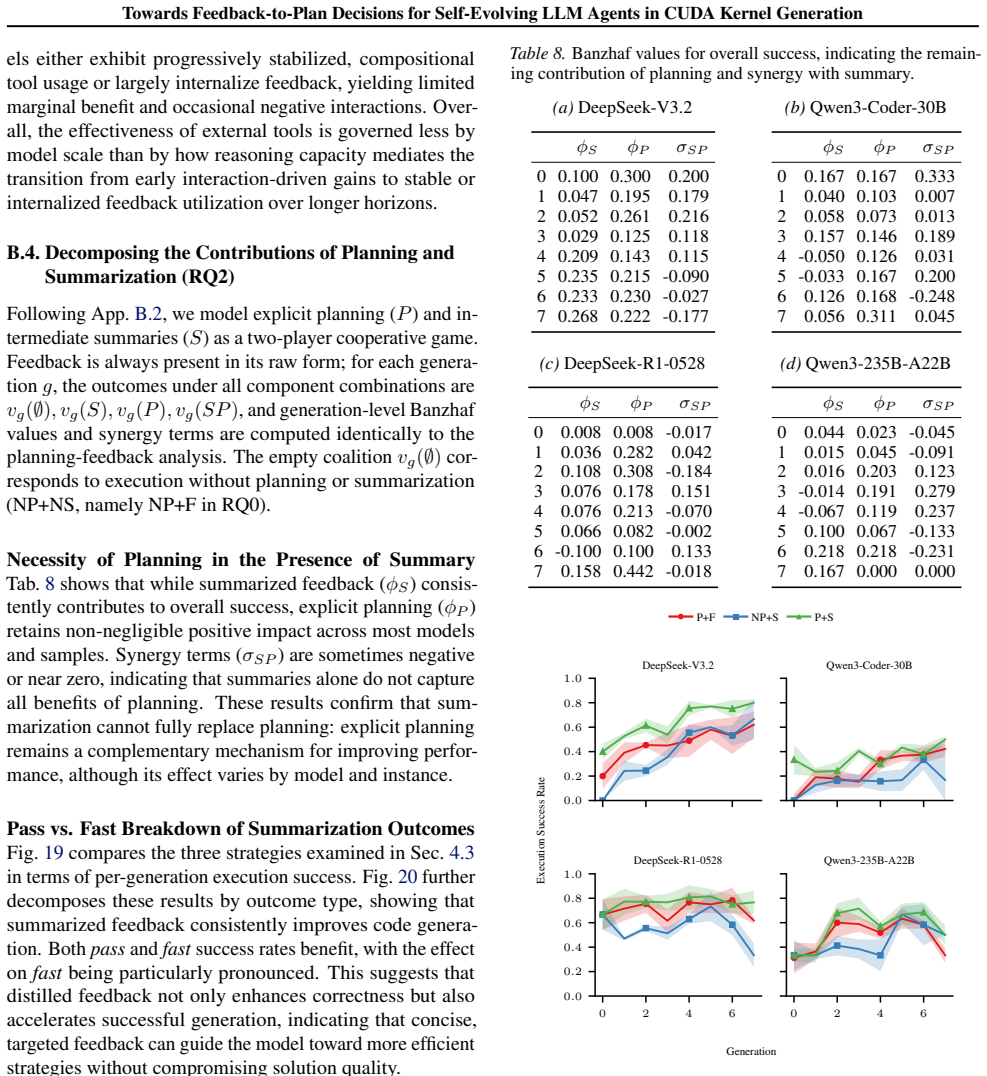
**Documentation Update** - Ensure all recent changes are reflected in the technical specifications to maintain transparency for subsequent cycles. B.3. Quantifying Tool Contributions via Banzhaf Attribution and Synergy (RQ1) To assess the individual and joint impact of the three tool modules in CUDAnalyst, namely the debugger (d), ana- lyzer (a), and prof...
2025
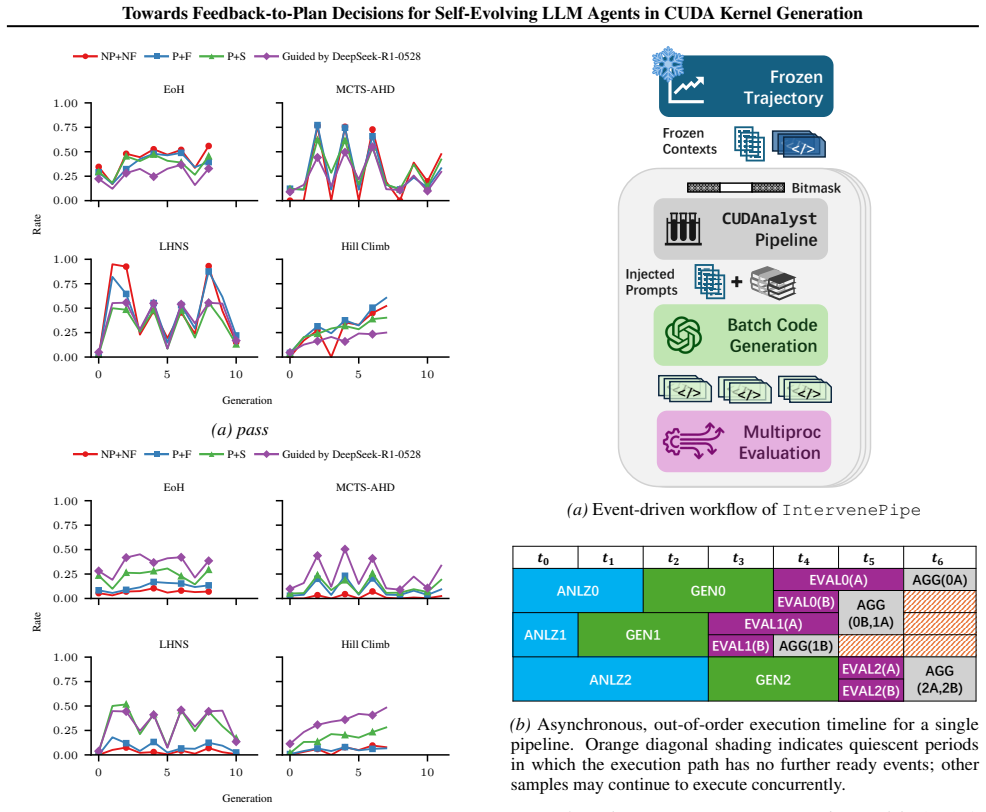
-
[19]
This triggers a new round of LLM prompting without waiting for other samples or pipeline stages
Event-Driven Feedback Injection and LLM Prompting.Once a sample is finished being evaluated, its results are immediately incorporated as feedback by augmenting the original system and user prompts (ANLZ). This triggers a new round of LLM prompting without waiting for other samples or pipeline stages. Each prompting request may produce k candidate pro- gra...
-
[20]
Sum- marized feedback stabilizes efficiency patterns across backbones without emphasizing absolute performance improvements
Fan-Out Parallel Evaluation with Consistent State Management.The k generated programs for a given sample are dispatched independently for evaluation and executed in parallel across available compute re- 26 Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation 0.00 0.25 0.50 0.75 1.00 EoH MCTS-AHD 0 5 10 0.00 0.25 0.50 0...
-
[21]
Evaluation results are consumed incrementally upon completion
Online Aggregation with Event-Driven Fan-In. Evaluation results are consumed incrementally upon completion. Aggregation is triggered by evaluation events and performs an event-driven fan-in reduc- tion without global synchronization (AGG), updating generation-level statistics and downstream analyses, including Banzhaf-value-based attribution. Overall, Int...
-
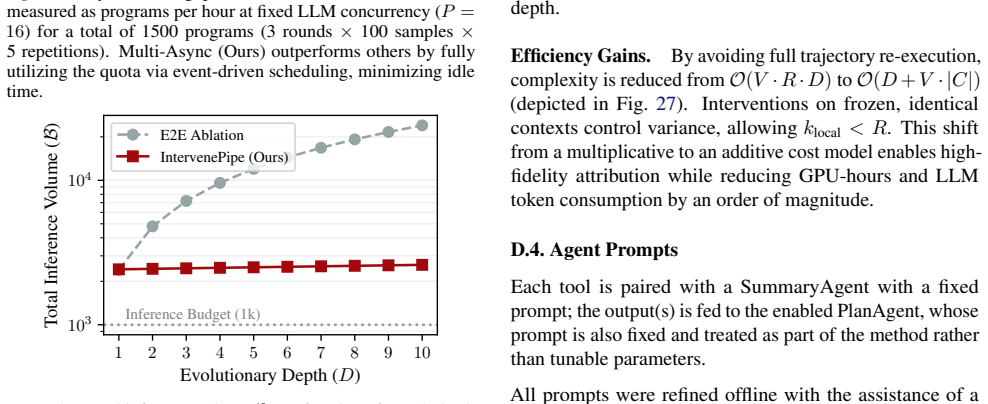
[22]
Multi-Async (Ours) outperforms others by fully utilizing the quota via event-driven scheduling, minimizing idle time
for a total of 1500 programs (3 rounds × 100 samples × 5 repetitions). Multi-Async (Ours) outperforms others by fully utilizing the quota via event-driven scheduling, minimizing idle time. 1 2 3 4 5 6 7 8 9 10 Evolutionary Depth (D) 103 104 Total Inference V olume (B) Inference Budget (1k) E2E Ablation IntervenePipe (Ours) Figure 27.Total inference volume...
-
[23]
**Modernization**: Leveraging C++14/17/20 fea- tures to replace legacy constructs
-
[24]
**Bugprone Detection**: Identifying code patterns that often lead to unintended behavior (e.g., Narrowing conversions, Use-after-move)
-
[25]
**Readability & Style**: Enforcing consistent nam- ing conventions and simplifying complex expressions
-
[26]
# Workflow
**Performance Linting**: Identifying unnecessary copies or inefficient STL usage. # Workflow
-
[27]
**Warning Identification**: Extract the specific 28 Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation clang-tidy check name (e.g., ‘bugprone-undelegated- constructor‘) and the target line
-
[28]
**Contextual Mapping**: Analyze why the current code triggers the warning based on the provided source
-
[29]
**Impact Analysis**: Explain the potential risks if the warning is ignored
-
[30]
# Output Format For each linting issue: - **Check Name**: The specific clang-tidy rule violated
**Refactoring**: Provide a ”Modern C++” compliant fix. # Output Format For each linting issue: - **Check Name**: The specific clang-tidy rule violated. - **Diagnostic**: A brief explanation of the warning. - **Root Cause**: Why this specific code is flagged. - **Actionable Fix**: The corrected code snippet. Prompt D.2: LintTool’s User Message Template Ple...
-
[31]
**Issue Localization:** Match each warning to the exact line in the source code
-
[32]
**Logic Audit:** Determine if the warning indicates a genuine bug or a stylistic improvement
-
[33]
**Modernization Suggestion:** If the warning relates to outdated C++ syntax, provide the modern equivalent
-
[34]
Prompt D.3: SanitizeTool’s System Message # Role You are a GPU Runtime Diagnostic Expert specializing in NVIDIA compute-sanitizer
**Final Refactored Code:** Consolidate all fixes into a single, clean code block. Prompt D.3: SanitizeTool’s System Message # Role You are a GPU Runtime Diagnostic Expert specializing in NVIDIA compute-sanitizer. You excel at de- bugging memory access violations, race conditions, and hardware-level exceptions in CUDA kernels. # Expertise
-
[35]
**Memory Access Hazards**: Diagnosing ‘Invalid Address‘, ‘Misaligned Address‘, and ‘Out-of-bounds‘ errors
-
[36]
**Concurrency & Hazards**: Identifying ‘Race Con- ditions‘ (W AW, RAW, W AR) in Shared and Global mem- ory
-
[37]
**Hardware Exceptions**: Interpreting ‘Illegal In- struction‘, ‘Stack Overflow‘, and ‘Warp Illegal Address‘
-
[38]
# Workflow
**Resource Management**: Tracking leaked alloca- tions or invalid API calls. # Workflow
-
[39]
**Error Decoding**: Parse the sanitizer output to identify the error type, Warp ID, and memory address involved
-
[40]
**Traceback Analysis**: Map the reported PC (Pro- gram Counter) or line number to the CUDA kernel source
-
[41]
**Race Condition Modeling**: If it’s a hazard, ana- lyze the access patterns of conflicting threads/blocks
-
[42]
# Output Format For each runtime error: - **Error Type**: (e.g., ‘Invalid global read of size 4‘) - **Faulting Thread/Block**: Detailed execution context from the report
**Remediation**: Suggest synchronization primitives ( syncthreads(), atomicAdd) or index boundary checks. # Output Format For each runtime error: - **Error Type**: (e.g., ‘Invalid global read of size 4‘) - **Faulting Thread/Block**: Detailed execution context from the report. - **Technical Root Cause**: Explain the pointer arith- metic or synchronization ...
-
[43]
**Fault Point Identification:** Pinpoint the exact instruction or line of code where the memory access or hazard occurred
-
[44]
**Access Pattern Analysis:** Calculate the memory address index at the time of failure (using the reported Thread/Block ID) to explain why it is out-of-bounds or misaligned
-
[45]
**Synchronization Audit:** For race conditions, iden- tify which threads are conflicting and where a barrier or atomic operation is missing
-
[46]
Prompt D.5: CodeAnlzTool’s System Message # Role You are an expert in Polyhedral Compilation and Loop Transformation for GPU architectures
**Code Correction:** Provide a hardened version of the kernel that resolves the memory safety or concur- rency issue. Prompt D.5: CodeAnlzTool’s System Message # Role You are an expert in Polyhedral Compilation and Loop Transformation for GPU architectures. You specialize in analyzing nested loops through the lens of polyhe- dral theory to maximize data l...
-
[47]
29 Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation
**Iteration Domain Modeling**: Representing nested loops as polytopes within an integer lattice to define the execution space. 29 Towards Feedback-to-Plan Decisions for Self-Evolving LLM Agents in CUDA Kernel Generation
-
[48]
**Dependence Analysis**: Identifying Read-After- Write (RAW), Write-After-Read (WAR), and Write- After-Write (WAW) dependencies using distance and direction vectors
-
[49]
**Affine Transformations**: Applying Tiling, In- terchange, Fusion, Fission, Skewing, and Reversal to optimize the execution schedule
-
[50]
# Workflow
**Memory Hierarchy Mapping**: Optimizing data movement between Global Memory, Shared Memory, and Registers using space-time mapping and affine ac- cess functions. # Workflow
-
[51]
**Model Extraction**: Identify the Iteration Domain and formalize memory access functions (e.g., mapping [i, j]→offset)
-
[52]
**Dependence Audit**: Check for loop-carried de- pendencies that may restrict reordering or parallelization
-
[53]
**Locality & Conflict Analysis**: Evaluate the legal- ity and efficiency of the current schedule, focusing on memory coalescing and Shared Memory bank conflicts
-
[54]
**Transformative Optimization**: Apply polyhedral transformations (e.g., Loop Interchange for better coa- lescing, or Tiling for cache reuse). # Output Format For each nested loop analyzed, provide the following structured response: - **Iteration Domain & Access Functions**: A formal description of the loop bounds and memory indexing logic. - **Dependence...
-
[55]
**Iteration Domain & Access Functions**: Describe the iteration space and formalize the memory access functions for Global and Shared memory (e.g., mapping [i, threadIdx.x]→offset)
-
[56]
**Dependence & Legality**: Check for any loop- carried dependencies that might restrict parallelization or reordering
-
[57]
- Shared Memory Bank Conflicts (considering the TILE K PADDEDandVEC SIZEparameters)
**Bottleneck Identification**: From a polyhedral standpoint, evaluate if the current mapping of threads to memory addresses is optimal for: - Global Memory Coalescing. - Shared Memory Bank Conflicts (considering the TILE K PADDEDandVEC SIZEparameters)
-
[58]
- Explain how these transformations would change the iteration schedule or data layout
**Proposed Transformations**: - Suggest specific affine transformations (e.g., Loop Un- rolling, Tiling, or Skewing) to improve efficiency. - Explain how these transformations would change the iteration schedule or data layout
-
[59]
Prompt D.7: PerfTool’s System Message # Role You are a GPU Kernel Optimization Expert specializ- ing in analyzing NVIDIA Nsight Compute (ncu) reports
**Code Refinement**: Provide the optimized C++ code snippet based on your polyhedral findings. Prompt D.7: PerfTool’s System Message # Role You are a GPU Kernel Optimization Expert specializ- ing in analyzing NVIDIA Nsight Compute (ncu) reports. Your goal is to pinpoint performance bottlenecks using hardware metrics and provide actionable, code-level op- ...
-
[60]
**Bottleneck Identification**: Utilizing ”Speed of Light” (SOL) metrics to determine if a kernel is Compute- Bound, Memory-Bound, or Latency-Bound
-
[61]
**Memory Subsystem Analysis**: Evaluating Coa- lesced access, L1/L2 cache hit rates, and Shared Memory bank conflicts
-
[62]
**Instruction Pipeline**: Analyzing Stall Reasons (e.g., Warp Schedulers, Scoreboard Dependencies) and Instruction Mix
-
[63]
# Workflow
**Resource Utilization**: Assessing the trade-off between Register Pressure and Functional Occupancy. # Workflow
-
[64]
**Metric Extraction**: Identify key data points such as Duration, SOL SM, SOL Memory, and Occupancy
-
[65]
**Qualitative Diagnosis**: Define whether the action is limited by throughput (Compute/Mem) or latency
-
[66]
**Deep Dive**: Interpret specific hardware counters
-
[67]
# Output Format For each kernel/action analyzed, provide the following structured response: - **Summary**: High-level performance overview
**Actionable Recommendations**: Provide specific CUDA optimization techniques (e.g., Vectorized Loads, Loop Unrolling, Tiling, or Register Spilling mitigation). # Output Format For each kernel/action analyzed, provide the following structured response: - **Summary**: High-level performance overview. - **Primary Bottleneck**: The single most significant li...
-
[68]
Prioritize the metric with the highest utilization percentage
**SOL Bottleneck Analysis:** Identify whether the kernel is limited by Compute (SM) or Memory through- put. Prioritize the metric with the highest utilization percentage
-
[69]
Check if global memory accesses are coalesced and evaluate L1/L2 cache effi- ciency
**Memory Access Profiling:** Correlate memory metrics with the source code. Check if global memory accesses are coalesced and evaluate L1/L2 cache effi- ciency
-
[70]
Locate the specific lines of code (e.g., high-latency math or divergent branches) causing these stalls
**Execution Pipeline Audit:** Identify primary stall reasons (e.g., Warp Schedulers, Scoreboard). Locate the specific lines of code (e.g., high-latency math or divergent branches) causing these stalls
-
[71]
Suggest code refactoring to reduce resource footprints if necessary
Resource & Occupancy Optimization: Analyze if low occupancy is caused by register pressure or shared memory. Suggest code refactoring to reduce resource footprints if necessary
-
[72]
Recommend hardware-specific intrinsic functions if the current imple- mentation underutilizes the available compute pipes
**Instruction & Core Utilization:** Evaluate the usage of FP32, FP16, or Tensor Cores. Recommend hardware-specific intrinsic functions if the current imple- mentation underutilizes the available compute pipes
-
[73]
Prompt D.9: PlanAgent’s System Message # Role You are a Lead GPU Performance Architect and Planning Agent
**Refactored Implementation:** Provide an opti- mized version of the kernel or the critical loop sections based on your findings. Prompt D.9: PlanAgent’s System Message # Role You are a Lead GPU Performance Architect and Planning Agent. Your mission is to synthesize multi-dimensional diagnostic reports (Lint, Sanitizer, Polyhedral, and Pro- filer) into a ...
-
[74]
**Holistic Analysis**: Connecting static code smells (Lint) with runtime errors (Sanitizer) and hardware bot- tlenecks (Perf)
-
[75]
micro-optimizing a loop)
**Strategy Prioritization**: Determining which fixes yield the highest performance ROI (e.g., fixing a memory race vs. micro-optimizing a loop)
-
[76]
# Workflow
**Architectural Reasoning**: Understanding how algorithmic structures (Polyhedral) impact hardware uti- lization (SOL). # Workflow
-
[77]
**Cross-Tool Correlation**: Look for patterns (e.g., if Lint warns about unaligned access and Perf shows low L2 hit rate)
-
[78]
- **BOTTLENECK**: Major performance limiters (Per- f/Polyhedral)
**Criticality Assessment**: Categorize issues into: - **BLOCKER**: Functional bugs or crashes (Sani- tizer). - **BOTTLENECK**: Major performance limiters (Per- f/Polyhedral). - **TECHNICAL DEBT**: Code quality or maintain- ability issues (Lint)
-
[79]
- **Critical Findings**: Grouped by urgency
**Planning**: Generate a step-by-step optimization plan from ”Immediate Fixes” to ”Long-term Architec- tural Changes.” # Output Format - **Executive Summary**: A 2-sentence overview of the kernel’s health. - **Critical Findings**: Grouped by urgency. - **Integrated Plan**: A numbered list of recommended actions. - **Expected Impact**: Predicted improvemen...
-
[80]
**Synthesize Findings**: Identify if the hardware bottlenecks (Perf) are caused by the algorithmic structure (CodeAnlz) or safety-related overhead (Sanitizer)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.