SEEK: Semantic Evidence Extraction via Adaptive ChunKing for Multilingual Fact-Checking
Pith reviewed 2026-06-29 17:45 UTC · model grok-4.3
The pith
SEEK extracts coherent evidence chunks from full articles by identifying semantic topic transitions to support more reliable multilingual fact verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
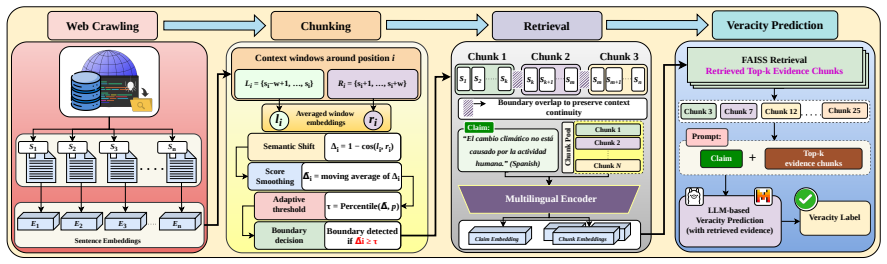
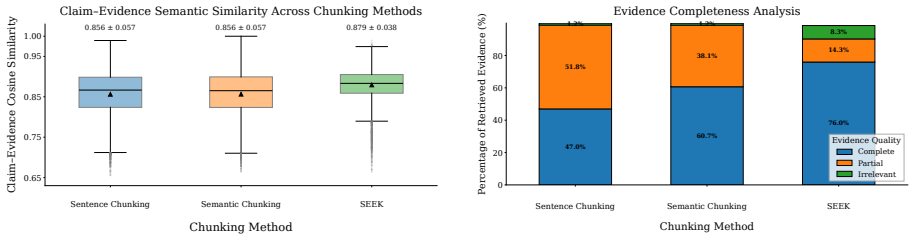
SEEK constructs coherent evidence chunks from full fact-checking articles by identifying semantic topic transitions and preserving local verification context. The constructed chunks are encoded using a multilingual encoder and then multilingual LLMs are finetuned using LoRA adapter for veracity prediction. Experiments on X-FACT and RU22Fact show that SEEK improves macro-f1 by up to 10% over semantic chunking, 19% over sentence chunking, and 20% over search-snippet baselines. Evidence completeness and significance analyses further show that SEEK preserves richer verification context and enables more reliable multilingual fact-checking.
What carries the argument
Adaptive chunKing framework that identifies semantic topic transitions to construct coherent evidence chunks from full articles while preserving local verification context.
If this is right
- Coherent chunks from full articles preserve richer verification context than fragmented sentence or snippet methods.
- Multilingual LLMs fine-tuned on these chunks achieve higher macro-f1 scores for veracity prediction.
- Evidence completeness analyses confirm that the chunks support more reliable fact-checking across languages.
- The method reduces dependence on incomplete external search results for evidence gathering.
Where Pith is reading between the lines
- The same transition-based chunking could be tested on longer documents in other domains that require full-context reasoning.
- If the gains hold, systems might shift from snippet retrieval to processing entire source articles as a default step.
Load-bearing premise
Identifying semantic topic transitions constructs coherent evidence chunks from full articles that preserve richer verification context than sentence-level or snippet-based approaches.
What would settle it
If SEEK-produced chunks yield no improvement or lower macro-f1 scores than sentence-level or search-snippet evidence on the same X-FACT and RU22Fact test sets, the benefit of adaptive semantic chunking would be refuted.
Figures


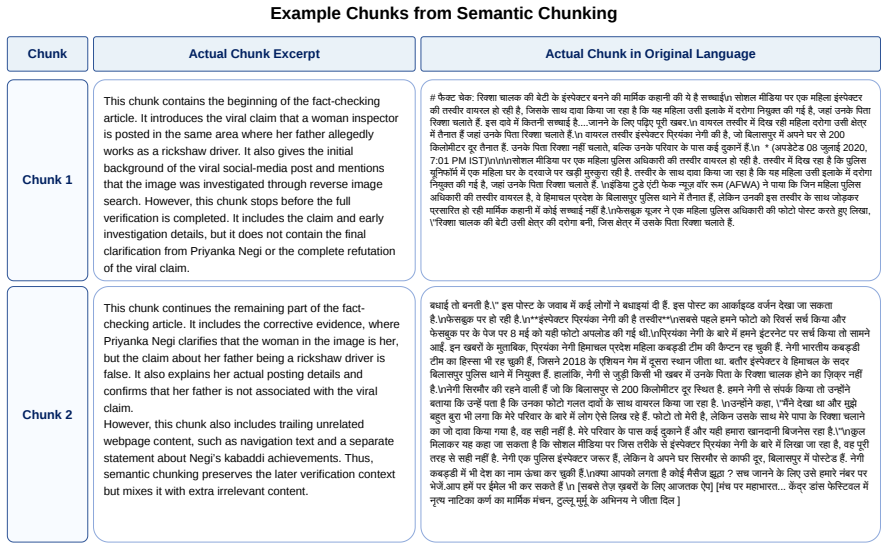


read the original abstract
Multilingual fact verification requires evidence that is both relevant and sufficiently complete for reliable factuality prediction. However, existing systems often rely on search snippets, sentence-level evidence, or locally segmented passages, which can miss decisive context and produce fragmented evidence. To overcome these limitations, we propose SEEK, a Semantic Evidence Extraction with an adaptive chunKing framework that constructs coherent evidence chunks from full fact-checking articles by identifying semantic topic transitions and preserving local verification context. The constructed chunks are encoded using a multilingual encoder and then multilingual LLMs are finetuned using LoRA adapter for veracity prediction. Experiments on X-FACT and RU22Fact show that SEEK improves macro-f1 by up to 10% over semantic chunking, 19% over sentence chunking, and 20% over search-snippet baselines. Evidence completeness and significance analyses further show that SEEK preserves richer verification context and enables more reliable multilingual fact-checking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SEEK, a Semantic Evidence Extraction framework using adaptive chunking to identify semantic topic transitions in full fact-checking articles, thereby constructing coherent evidence chunks that preserve richer verification context. These chunks are encoded via a multilingual encoder and used to fine-tune multilingual LLMs with LoRA adapters for veracity prediction. Experiments on the X-FACT and RU22Fact datasets report macro-F1 improvements of up to 10% over semantic chunking, 19% over sentence chunking, and 20% over search-snippet baselines, accompanied by analyses of evidence completeness and significance.
Significance. If the empirical gains hold under scrutiny, the method could meaningfully advance multilingual fact-checking by mitigating fragmentation in evidence sources. The focus on evidence completeness analyses represents a constructive addition to the literature on context-preserving retrieval for verification tasks.
major comments (3)
- [§3] §3 (Methodology): The description of semantic topic transition detection for adaptive chunking remains high-level with no explicit algorithm, similarity metric, or threshold parameters provided, which directly affects the reproducibility of the central claim that these chunks preserve richer verification context than baselines.
- [§4] §4 (Experiments): No dataset statistics (e.g., instance counts, language distributions, or class balance) are reported for X-FACT or RU22Fact, making it impossible to assess whether the reported macro-F1 gains of 10-20% are driven by the method or by dataset characteristics.
- [§4] §4 (Experiments): The paper provides no error analysis or breakdown of cases where SEEK fails to improve over baselines, which is load-bearing for validating the assumption that semantic topic transitions yield more reliable verification context.
minor comments (2)
- [Title] The title contains an inconsistent capitalization ('ChunKing') that should be standardized to 'Chunking'.
- [Abstract] Abstract and §1 would benefit from a brief statement of the number of languages covered in the multilingual experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for improving the clarity and rigor of our work on SEEK. We address each major comment below and commit to revisions that enhance reproducibility and analysis without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Methodology): The description of semantic topic transition detection for adaptive chunking remains high-level with no explicit algorithm, similarity metric, or threshold parameters provided, which directly affects the reproducibility of the central claim that these chunks preserve richer verification context than baselines.
Authors: We agree that the current description in §3 is high-level and limits reproducibility. In the revised manuscript, we will expand this section to include the explicit algorithm for detecting semantic topic transitions, the similarity metric employed (cosine similarity over multilingual embeddings), and the specific threshold parameters used for chunk boundaries. This addition will directly support the claim regarding richer verification context. revision: yes
-
Referee: [§4] §4 (Experiments): No dataset statistics (e.g., instance counts, language distributions, or class balance) are reported for X-FACT or RU22Fact, making it impossible to assess whether the reported macro-F1 gains of 10-20% are driven by the method or by dataset characteristics.
Authors: We concur that dataset statistics are necessary for contextualizing the results. We will add a dedicated subsection or table in §4 reporting instance counts, language distributions, and class balances for both X-FACT and RU22Fact to allow readers to evaluate the reported macro-F1 improvements appropriately. revision: yes
-
Referee: [§4] §4 (Experiments): The paper provides no error analysis or breakdown of cases where SEEK fails to improve over baselines, which is load-bearing for validating the assumption that semantic topic transitions yield more reliable verification context.
Authors: We acknowledge the importance of error analysis for validating the method's assumptions. In the revision, we will incorporate an error analysis subsection in §4 that examines and categorizes cases where SEEK does not outperform the baselines, including qualitative examples and quantitative breakdowns to assess when semantic topic transitions provide reliable context. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical pipeline for multilingual fact-checking: adaptive chunking via semantic topic transitions to form evidence chunks, followed by multilingual encoding and LoRA fine-tuning of LLMs for veracity prediction. Claims rest on experimental macro-F1 gains versus external baselines (semantic chunking, sentence chunking, search snippets) on X-FACT and RU22Fact. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method; the central result is an observable performance comparison on independent datasets and is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Isabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, and Jakob Grue Simonsen. 2019. https://doi.org/10.18653/v1/D19-1475 M ulti FC : A real-world multi-domain dataset for evidence-based fact checking of claims . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing an...
-
[4]
Recep Firat Cekinel, Pinar Karagoz, and C a g r C \"o ltekin. 2024. https://aclanthology.org/2024.lrec-main.368/ Cross-lingual learning vs. low-resource fine-tuning: A case study with fact-checking in T urkish . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pag...
2024
-
[5]
Jiangui Chen, Ruqing Zhang, Jiafeng Guo, Yixing Fan, and Xueqi Cheng. 2022. https://doi.org/10.1145/3477495.3531827 GERE : Generative evidence retrieval for fact verification . In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '22, pages 2184--2189, New York, NY, USA. Association for ...
-
[6]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. http://arxiv.org/abs/2401.08281 The Faiss library . arXiv preprint
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Zhijiang Guo, Michael Schlichtkrull, and Andreas Vlachos. 2022. https://doi.org/10.1162/tacl_a_00454 A survey on automated fact-checking . Transactions of the Association for Computational Linguistics, 10:178--206
-
[8]
Ashim Gupta and Vivek Srikumar. 2021 a . https://doi.org/10.18653/v1/2021.acl-short.86 X -fact: A new benchmark dataset for multilingual fact checking . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 675--6...
-
[9]
Ashim Gupta and Vivek Srikumar. 2021 b . https://aclanthology.org/2021.acl-short.86 X-fact: A new benchmark dataset for multilingual fact checking . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 675--682, ...
2021
-
[10]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://www.microsoft.com/en-us/research/publication/lora-low-rank-adaptation-of-large-language-models/ Lora: Low-rank adaptation of large language models . In ICLR 2022
2022
-
[11]
Kung-Hsiang Huang, ChengXiang Zhai, and Heng Ji. 2022. https://aclanthology.org/2022.coling-1.86/ CONCRETE : Improving cross-lingual fact-checking with cross-lingual retrieval . In Proceedings of the 29th International Conference on Computational Linguistics, pages 1024--1035, Gyeongju, Republic of Korea. International Committee on Computational Linguistics
2022
-
[12]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.550 Dense passage retrieval for open-domain question answering . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769--6781, Online. Ass...
-
[13]
C. Kiss. 2025. https://doi.org/10.1007/s10791-025-09638-7 Max--min semantic chunking of documents for rag application . Discover Computing, 28(117)
-
[14]
LangChain. 2024. Langchain semantic chunking. https://python.langchain.com/docs/how_to/semantic_chunker/. Accessed: 2024-07-04
2024
-
[15]
Preslav Nakov, David Corney, Maram Hasanain, Firoj Alam, Tamer Elsayed, Alberto Barrón-Cedeño, Paolo Papotti, Shaden Shaar, and Giovanni Da San Martino. 2021. https://doi.org/10.24963/ijcai.2021/619 Automated fact-checking for assisting human fact-checkers . In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-2...
-
[16]
Venktesh, Erik Martin, Henrik Vatndal, Vinay Setty, and Avishek Anand
Kevin Nanhekhan, V. Venktesh, Erik Martin, Henrik Vatndal, Vinay Setty, and Avishek Anand. 2025. https://doi.org/10.1007/978-3-031-88717-8_28 Flashcheck: Exploration of efficient evidence retrieval for fast fact-checking . In Advances in Information Retrieval, volume 15575 of Lecture Notes in Computer Science, pages 385--399, Cham. Springer
-
[17]
Rrubaa Panchendrarajan and Arkaitz Zubiaga. 2024. https://doi.org/10.1016/j.nlp.2024.100066 Claim detection for automated fact-checking: A survey on monolingual, multilingual and cross-lingual research . Natural Language Processing Journal, 7:100066
-
[18]
Q. Peng et al. 2025 a . https://arxiv.org/abs/2505.10740 Semeval-2025 task 7: Multilingual and crosslingual fact-checked claim retrieval . In Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025)
-
[19]
Qiwei Peng, Robert Moro, Michal Gregor, Ivan Srba, Simon Ostermann, Marian Simko, Juraj Podrouzek, Mat \'u s Mesar c \'i k, Jaroslav Kop c an, and Anders S gaard. 2025 b . https://aclanthology.org/2025.semeval-1.323/ S em E val-2025 task 7: Multilingual and crosslingual fact-checked claim retrieval . In Proceedings of the 19th International Workshop on Se...
2025
-
[20]
Qu et al
R. Qu et al. 2025. https://aclanthology.org/2025.findings-naacl.114/ Is semantic chunking worth the computational cost? Findings of the Association for Computational Linguistics: NAACL 2025
2025
-
[21]
Dorian Quelle, Calvin Yixiang Cheng, Alexandre Bovet, and Scott A. Hale. 2025. https://doi.org/10.1140/epjds/s13688-025-00520-6 Lost in translation: using global fact-checks to measure multilingual misinformation prevalence, spread, and evolution . EPJ Data Science, 14(1):22
-
[22]
Michael Schlichtkrull, Zhijiang Guo, and Andreas Vlachos. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/cd86a30526cd1aff61d6f89f107634e4-Paper-Datasets_and_Benchmarks.pdf Averitec: A dataset for real-world claim verification with evidence from the web . In Advances in Neural Information Processing Systems, volume 36, pages 65128--65167....
2023
-
[23]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. http://arxiv.org/abs/1803.05355 FEVER : a large-scale dataset for fact extraction and verification . Updated version of NAACL2018 paper. https://doi.org/10.48550/arXiv.1803.05355
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1803.05355 2018
-
[24]
Sentence Transformers. 2021. sentence-transformers/all-minilm-l6-v2. https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2. Accessed: 2026-05-17
2021
-
[25]
UncleCode. 2024. Crawl4ai: Open-source llm friendly web crawler & scraper. https://github.com/unclecode/crawl4ai. GitHub repository. Please use the commit hash you're working with
2024
-
[26]
V. Viswanathan et al. 2025. https://arxiv.org/abs/2509.11492 Claimiq at checkthat! 2025: Comparing prompted and fine-tuned language models for verifying numerical claims
-
[27]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Multilingual e5 text embeddings: A technical report. arXiv preprint arXiv:2402.05672
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
liar, liar pants on fire
William Y. Wang. 2017. “liar, liar pants on fire”: A new benchmark dataset for fake news detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), pages 422--426. Association for Computational Linguistics
2017
- [29]
-
[30]
Hengran Zhang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.422 From relevance to utility: Evidence retrieval with feedback for fact verification . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 6373--6384, Singapore. Association for Computa...
- [31]
-
[32]
Liwen Zheng, Chaozhuo Li, Xi Zhang, Yu-Ming Shang, Feiran Huang, and Haoran Jia. 2024 a . https://doi.org/10.18653/v1/2024.findings-acl.551 Evidence retrieval is almost all you need for fact verification . In Findings of the Association for Computational Linguistics: ACL 2024, pages 9274--9281, Bangkok, Thailand. Association for Computational Linguistics
-
[33]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024 b . http://arxiv.org/abs/2403.13372 Llamafactory: Unified efficient fine-tuning of 100+ language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand. As...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.