Optimising Factual Consistency in Summarisation via Preference Learning from Multiple Imperfect Metrics
Pith reviewed 2026-06-29 18:29 UTC · model grok-4.3
The pith
Aggregating multiple weak factuality metrics into filtered preferences improves summary consistency without human labels or reward shaping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
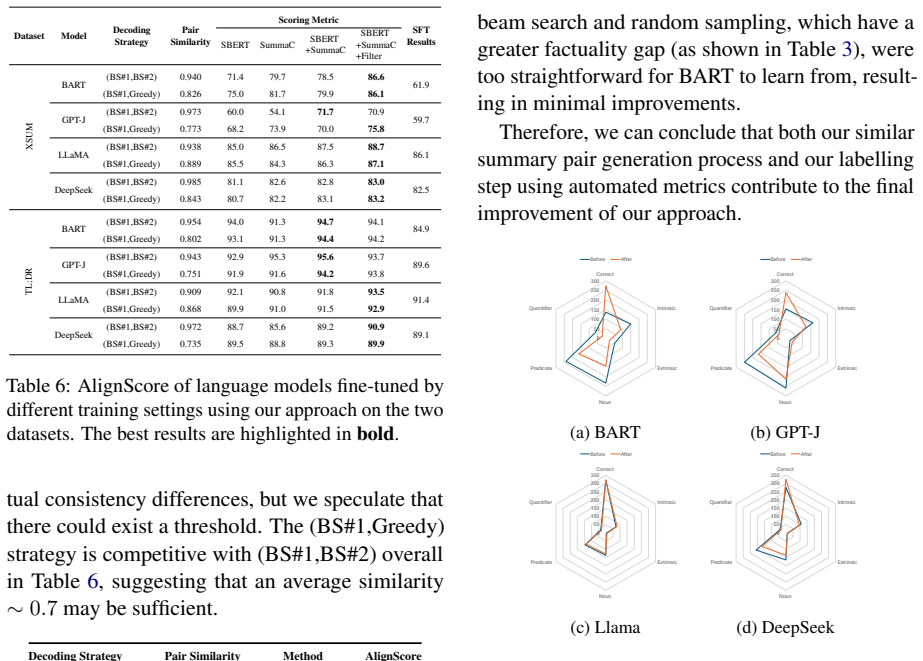
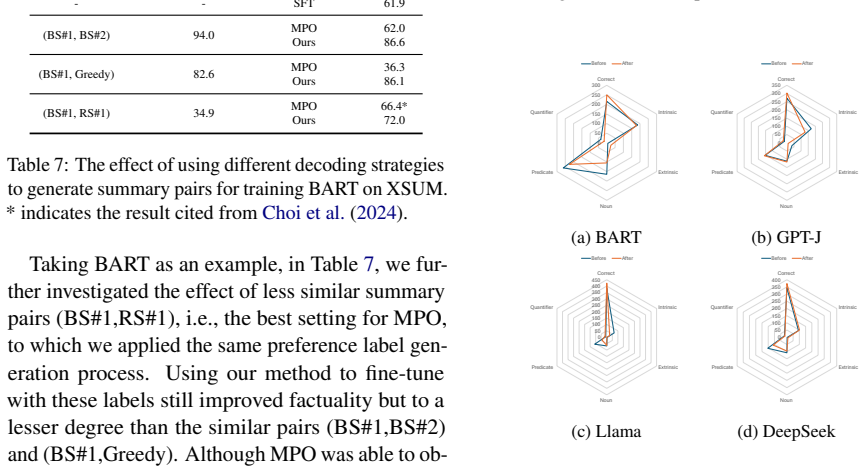
By mapping scores from multiple imperfect factuality metrics to preferences and discarding cases of high disagreement between the metrics, the method builds a high-quality preference dataset using only source documents. Lexically similar summary pairs are created by varying decoding strategies so the model learns factual distinctions arising from subtle wording changes; preference learning on this data yields consistent factuality gains.
What carries the argument
The automated preference-dataset pipeline that aggregates scores from multiple weak metrics, filters high-disagreement pairs, and constructs training pairs via decoding variations on the same source document.
If this is right
- Factuality scores rise consistently for early encoder-decoder models through to modern large language models.
- After training, smaller models reach factuality levels comparable to larger models.
- No human annotations or hand-crafted reward functions are required.
- Lexical differences alone, induced by decoding changes, suffice to expose learnable factual distinctions.
Where Pith is reading between the lines
- The same aggregation-plus-filter approach could be tested on other text-generation tasks that rely on imperfect automatic metrics.
- If the gains hold, deployment of factual summarizers might shift toward smaller models fine-tuned this way rather than always scaling model size.
- The disagreement-filter step might be reusable in any multi-metric preference-learning setting where direct human feedback is costly.
Load-bearing premise
Filtering out high-disagreement cases between metrics produces a high-quality preference dataset whose factual signal is strong enough to drive reliable model improvement.
What would settle it
Apply the pipeline to train a model and measure no increase in factuality on held-out summarization test sets relative to the un-trained baseline.
Figures






read the original abstract
Reinforcement learning with evaluation metrics as rewards is widely used to enhance specific capabilities of language models. However, for tasks such as factually consistent summarisation, existing metrics remain underdeveloped, limiting their effectiveness as signals for shaping model behaviour.While individual factuality metrics are unreliable, their combination can more effectively capture diverse factual errors. We leverage this insight to introduce an automated training pipeline that improves factual consistency in summaries by aggregating scores from different weak metrics. Our approach avoids the need for complex reward shaping by mapping scores to preferences and filtering out cases with high disagreement between metrics. For each source document, we generate lexically similar summary pairs by varying decoding strategies, enabling the model to learn from factual differences caused by subtle lexical differences. This approach constructs a high-quality preference dataset using only source documents.Experiments demonstrate consistent factuality gains across models, ranging from early encoder-decoder architectures to modern large language models, with smaller models reaching comparable factuality to larger ones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an automated pipeline for improving factual consistency in summarization models. It aggregates scores from multiple imperfect factuality metrics, maps them to preferences after filtering high-disagreement cases, and generates lexically similar summary pairs by varying decoding strategies on source documents alone. Preference learning is then applied to train models ranging from early encoder-decoder architectures to modern LLMs, with the claim that this yields consistent factuality gains and allows smaller models to reach parity with larger ones.
Significance. If the empirical results hold under scrutiny, the work provides a practical, annotation-free method for leveraging weak metrics via preference optimization in summarization. The lexical-similarity pair generation isolates subtle factual differences without external references, which is a constructive contribution. Reproducible code or parameter-free elements are not mentioned, but the approach avoids complex reward shaping and could scale to multiple model families.
major comments (2)
- [Abstract] Abstract: The central claim of 'consistent factuality gains across models' is load-bearing, yet the abstract (and by extension the manuscript summary) supplies no quantitative results, specific metrics (e.g., FactCC, QAFactEval deltas), baselines, dataset sizes, or statistical tests. This prevents verification of whether gains are reliable or driven by the filtering step.
- [Abstract / Method] Method description (abstract): The filtering of high-disagreement cases between metrics is presented as producing a 'high-quality preference dataset,' but no ablation isolating the disagreement threshold (a free parameter) or human validation of retained pairs is referenced. Without this, it remains possible that retained pairs encode only easy consensus cases rather than reliable factual distinctions, undermining the pipeline's justification.
minor comments (1)
- [Abstract] The abstract contains a minor grammatical issue: 'While individual factuality metrics are unreliable, their combination can more effectively capture diverse factual errors.' could be rephrased for clarity.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address each major comment below and propose revisions to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'consistent factuality gains across models' is load-bearing, yet the abstract (and by extension the manuscript summary) supplies no quantitative results, specific metrics (e.g., FactCC, QAFactEval deltas), baselines, dataset sizes, or statistical tests. This prevents verification of whether gains are reliable or driven by the filtering step.
Authors: We agree that the abstract would benefit from including key quantitative results to support the central claim. The full paper reports these in the experiments section, but to make the abstract self-contained, we will revise it to include specific deltas, such as improvements in FactCC and QAFactEval scores, along with dataset details. This revision will be made in the next version. revision: yes
-
Referee: [Abstract / Method] Method description (abstract): The filtering of high-disagreement cases between metrics is presented as producing a 'high-quality preference dataset,' but no ablation isolating the disagreement threshold (a free parameter) or human validation of retained pairs is referenced. Without this, it remains possible that retained pairs encode only easy consensus cases rather than reliable factual distinctions, undermining the pipeline's justification.
Authors: The full manuscript details the filtering process in the methods section, including the rationale for the disagreement threshold. However, we acknowledge the value of an ablation study on this parameter and a human validation of the pairs. We will add an ablation analysis in the revised manuscript to show the impact of different thresholds. For human validation, while our approach is automated, we can include a discussion or small pilot study to validate the retained pairs' quality. revision: yes
Circularity Check
No significant circularity; empirical pipeline uses external metrics without self-referential reduction
full rationale
The paper describes an empirical pipeline that aggregates scores from existing external factuality metrics, maps them to preferences, and filters high-disagreement cases to build training data for preference learning. No equations, derivations, or fitted parameters are presented that reduce to the target result by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The method relies on independent metrics and standard preference optimization, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- disagreement threshold
axioms (1)
- domain assumption Combination of weak metrics can more effectively capture diverse factual errors than individual metrics
Reference graph
Works this paper leans on
-
[1]
Factuality challenges in the era of large lan- guage models.Preprint, arXiv:2310.05189. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901....
-
[2]
The Curious Case of Neural Text Degeneration
APRIL: Interactively learning to summarise by combining active preference learning and rein- forcement learning. InProceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing, pages 4120–4130, Brussels, Belgium. Association for Computational Linguistics. Zorik Gekhman, Jonathan Herzig, Roee Aharoni, Chen Elkind, and Idan Szpek...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald
Chatgpt as a factual inconsistency evaluator for text summarization.Preprint, arXiv:2303.15621. Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On faithfulness and factu- ality in abstractive summarization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, On- line. Associatio...
-
[4]
InProceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage Processing, pages 1797–1807, Brussels, Bel- gium
Don‘t give me the details, just the summary! topic-aware convolutional neural networks for ex- treme summarization. InProceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage Processing, pages 1797–1807, Brussels, Bel- gium. Association for Computational Linguistics. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright...
2018
-
[5]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu
Training language models to follow instruc- tions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evalu- ation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Compu- tational Ling...
2002
-
[6]
Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in Neural Information Processing Systems, 36:53728– 53741. Paul Roit, Johan Ferret, Lior Shani, Roee Aharoni, Ge- offrey Cideron, Robert Dadashi, Matthieu Geist, Ser- tan Girgin, Leonard Hussenot, Orgad Keller, Nikola Momchev, Sabela Ramos Garea, Piotr Stanczyk, Nino...
-
[7]
InProceedings of the Thirty-Third Inter- national Joint Conference on Artificial Intelligence, IJCAI ’24
Reinforcement learning from diverse human preferences. InProceedings of the Thirty-Third Inter- national Joint Conference on Artificial Intelligence, IJCAI ’24. Yuxuan Ye and Edwin Simpson. 2023. Towards abstrac- tive timeline summarisation using preference-based reinforcement learning. InECAI 2023, pages 2882–
2023
-
[8]
Yuxuan Ye, Edwin Simpson, and Raul Santos Rodriguez
IOS Press. Yuxuan Ye, Edwin Simpson, and Raul Santos Rodriguez
-
[9]
Weizhe Yuan, Graham Neubig, and Pengfei Liu
Using similarity to evaluate factual consistency in summaries.arXiv preprint arXiv:2409.15090. Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text gener- ation.Advances in neural information processing systems, 34:27263–27277. Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu
-
[10]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, Toronto, Canada
AlignScore: Evaluating factual consistency with a unified alignment function. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, Toronto, Canada. Association for Computational Linguistics. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. B...
2020
-
[11]
A\" or \
Following the prompt, it generates a chain-of- thought that ends with</think>before generating the final output. Therefore, we take all the output after</think>as the final summary for the metrics to score. You are a useful AI assistant that helps people to summarize [reddit posts/news documents]. Think first and then summarize the given post into a singl...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.