Not All Disagreement Is Learnable: Token Teachability in On-Policy Distillation
Pith reviewed 2026-06-29 19:08 UTC · model grok-4.3
The pith
Token teachability measures local compatibility to identify which teacher disagreements a student can actually learn from in on-policy distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
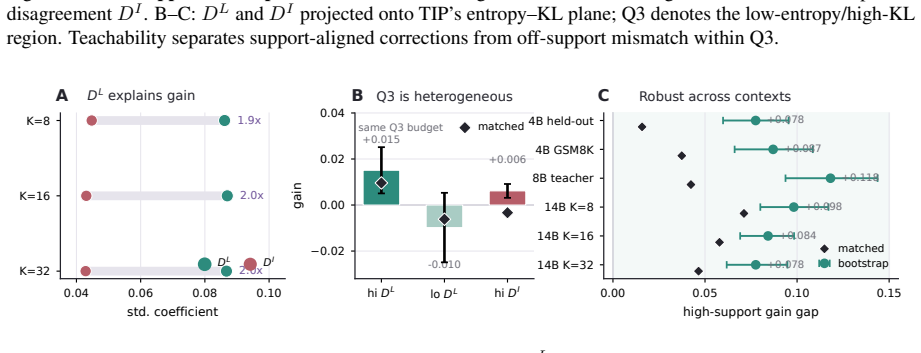
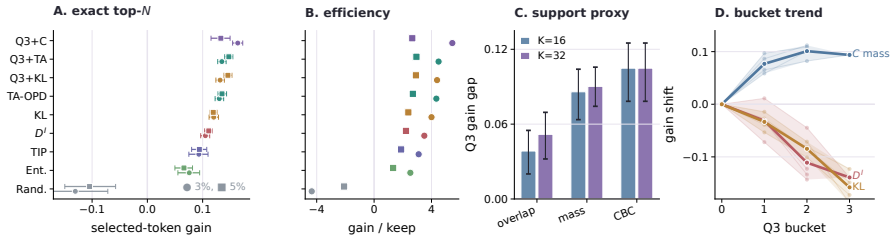
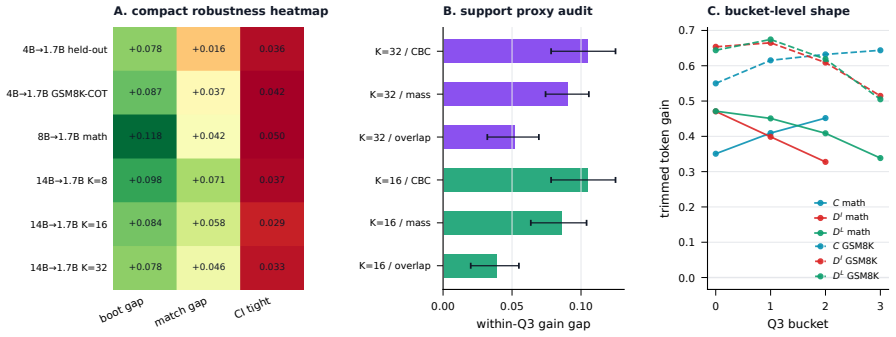
We formalize this local compatibility as token teachability and show that it better predicts fixed-context improvement than raw KL alone. Motivated by this finding, we propose Teachability-Aware OPD (TA-OPD), a lightweight token-position selection method that applies OPD loss to high-teachability positions without reward models or verifiers. Across Qwen2.5 and Qwen 3 teacher-student settings, TA-OPD often surpasses full-token OPD with only 5% retained tokens and improves over entropy- and divergence-based baselines.
What carries the argument
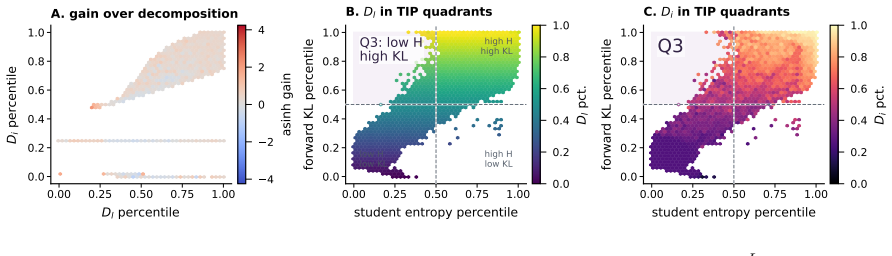
Token teachability: the local compatibility property in which the teacher places corrective probability mass on the student's current top-K candidates within the same context.
If this is right
- TA-OPD with 5 percent of tokens can exceed the performance of supervising every token.
- The method improves over entropy-based and divergence-based token selection without needing reward models or verifiers.
- Results hold across Qwen2.5 and Qwen 3 teacher-student pairs.
- Selective OPD is reframed as choosing learnable signals rather than merely salient tokens.
Where Pith is reading between the lines
- The teachability distinction may extend to other distillation or alignment settings where teacher signals vary in compatibility with the student's current distribution.
- Longer-horizon experiments could test whether teachability scores also predict downstream task gains beyond the fixed-context diagnostic.
- If incompatible disagreement is common, many current selective-distillation heuristics may be discarding useful signal or retaining noise.
Load-bearing premise
The fixed-context diagnostic of same-context KL reduction accurately identifies tokens whose supervision will produce net improvement when inserted into the full on-policy training loop.
What would settle it
Run full on-policy training loops that select supervision by teachability versus by raw KL, then measure whether teachability-based selection produces larger policy improvement on held-out tasks.
Figures

read the original abstract
On-policy distillation (OPD) trains a student on its own rollouts with token-level teacher supervision. Recent selective OPD methods exploit the non-uniformity of OPD signals by prioritizing high-entropy or high-disagreement tokens. We revisit this principle and ask: which token-level teacher signals are actually learnable? Using a fixed-context diagnostic that measures same-context teacher-student KL reduction, we show that raw KL disagreement is a coarse proxy for learning value. It conflates learnable disagreement, where the teacher assigns corrective mass to the student's top-K candidates, with incompatible disagreement, where the teacher places mass mostly off the student's current support. We formalize this local compatibility as token teachability and show that it better predicts fixed-context improvement than raw KL alone. Motivated by this finding, we propose Teachability-Aware OPD (TA-OPD), a lightweight token-position selection method that applies OPD loss to high-teachability positions without reward models or verifiers. Across Qwen2.5 and Qwen 3 teacher-student settings, TA-OPD often surpasses full-token OPD with only 5% retained tokens and improves over entropy- and divergence-based baselines. Our results reframe selective OPD as selecting learnable teacher signals rather than merely salient tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that raw KL disagreement in on-policy distillation conflates learnable and incompatible token signals. It introduces a fixed-context diagnostic measuring same-context teacher-student KL reduction to define 'token teachability,' which better predicts local improvement than raw KL. Motivated by this, TA-OPD selects the top 5% teachability tokens for supervision and is reported to outperform full-token OPD as well as entropy- and divergence-based baselines across Qwen2.5 and Qwen3 teacher-student pairs.
Significance. If the end-to-end results hold, the work offers a lightweight, reward-model-free method for selective OPD that reframes selection around local compatibility rather than salience. The distinction between learnable and incompatible disagreement is a useful conceptual contribution. Credit is due for grounding the method in an explicit diagnostic and demonstrating gains with a small retained-token fraction; however, significance hinges on whether the fixed-context metric reliably identifies tokens that produce net gains once student rollouts shift the distribution.
major comments (2)
- [Abstract and §4 (TA-OPD definition and experiments)] The central empirical claim (TA-OPD surpassing full OPD) rests on the assumption that tokens selected by the fixed-context teachability diagnostic produce net improvement in the iterative on-policy loop. The manuscript provides no controlled ablation that decouples the diagnostic from the training dynamics (e.g., comparing teachability-selected tokens against tokens that would have been selected by the same diagnostic run inside the actual training loop). This assumption is load-bearing for the claim that teachability is a superior selection criterion.
- [Abstract and experimental section] The 5% retention threshold is presented without justification or sensitivity analysis. It is unclear whether the threshold was chosen a priori, tuned on a held-out set, or selected post-hoc to maximize reported gains; any of these would affect the strength of the 'often surpasses full-token OPD' statement.
minor comments (1)
- [Abstract] The abstract states performance improvements but supplies no quantitative tables, confidence intervals, or statistical tests; the full manuscript should include these for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (TA-OPD definition and experiments)] The central empirical claim (TA-OPD surpassing full OPD) rests on the assumption that tokens selected by the fixed-context teachability diagnostic produce net improvement in the iterative on-policy loop. The manuscript provides no controlled ablation that decouples the diagnostic from the training dynamics (e.g., comparing teachability-selected tokens against tokens that would have been selected by the same diagnostic run inside the actual training loop). This assumption is load-bearing for the claim that teachability is a superior selection criterion.
Authors: We acknowledge that the fixed-context diagnostic is applied outside the full iterative loop and that a controlled comparison against dynamically recomputed teachability scores within training would more rigorously isolate the metric's contribution. The reported end-to-end gains across Qwen2.5/Qwen3 pairs nevertheless indicate that the static diagnostic identifies positions yielding net benefit under on-policy shifts. To address the concern, we will add a discussion of this limitation together with a new ablation that recomputes teachability at selected checkpoints and compares selection quality. revision: partial
-
Referee: [Abstract and experimental section] The 5% retention threshold is presented without justification or sensitivity analysis. It is unclear whether the threshold was chosen a priori, tuned on a held-out set, or selected post-hoc to maximize reported gains; any of these would affect the strength of the 'often surpasses full-token OPD' statement.
Authors: The 5% value emerged from early pilot runs showing that further increases yielded diminishing returns relative to compute savings; it was not tuned on the final test sets. We agree that explicit justification and sensitivity analysis are required. In the revision we will report performance curves for retention rates of 1%, 5%, 10%, and 20% on the same teacher-student pairs, confirming that TA-OPD remains competitive or superior to full OPD across this range. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper defines token teachability via an explicit fixed-context diagnostic (same-context KL reduction with compatibility check on teacher mass placement) and reports an empirical correlation between this measure and observed fixed-context improvement, then applies the resulting selection rule in separate on-policy training experiments. No equations are shown that equate the teachability score to the target training gain by construction, no self-citations supply load-bearing uniqueness theorems, and the diagnostic itself is an independent measurement rather than a fitted parameter renamed as a prediction. The central claim therefore rests on experimental outcomes outside the definitional step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The fixed-context teacher-student KL reduction is a valid proxy for whether a token-level signal will produce learning progress under on-policy rollouts.
invented entities (1)
-
token teachability
no independent evidence
Reference graph
Works this paper leans on
-
[1]
TIP: Token Importance in On-Policy Distillation
Llm-oriented token-adaptive knowledge dis- tillation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34070– 34078. Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. 2026. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084. Wenkai Yang, Weijie Liu, Ruobing Xie,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-distilled reasoner: On-policy self- distillation for large language models.arXiv preprint arXiv:2601.18734. Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Sid- dhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-following evalu- ation for large language models.arXiv preprint arXiv:2311.07911. Qi Zhou, Yiming Zhang, Yanggan Gu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.