Learning Energy-Based Models from Stochastic Interpolants using Spatiotemporal Differences
Pith reviewed 2026-06-29 19:05 UTC · model grok-4.3
The pith
Spatiotemporal differences overcome distinct failure modes when learning energy-based models from stochastic interpolants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
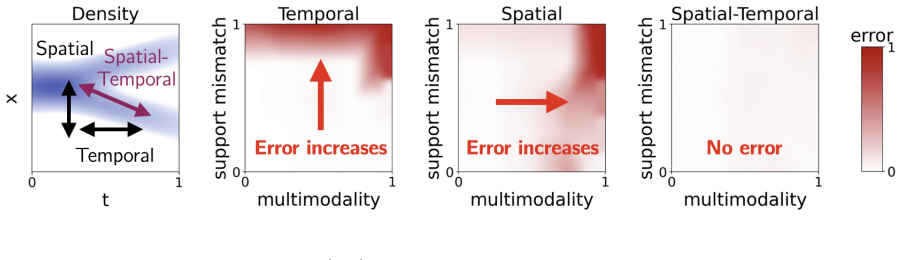
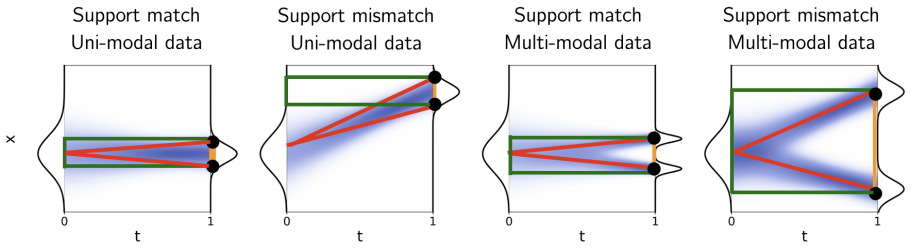
stNCE learns the energy of the joint density over data and time by forming contrastive losses from differences taken simultaneously across spatial coordinates and the interpolation time index; this unifies existing spatial-only and temporal-only approaches and produces new objectives whose performance on image and molecule datasets is competitive with leading density estimation techniques.
What carries the argument
Spatiotemporal Noise-Contrastive Estimation (stNCE), an estimator that constructs noise-contrastive losses from joint spatiotemporal differences of the energy function.
If this is right
- Many existing denoising score matching and related objectives for diffusion-style energy models become special cases of the stNCE loss.
- New training objectives can be obtained simply by choosing different weighting or sampling schedules inside the stNCE framework.
- The resulting models achieve density estimation performance on image and molecule data that matches or approaches current state-of-the-art methods.
Where Pith is reading between the lines
- The same joint-difference construction may extend to other corruption processes that involve both a spatial domain and an auxiliary scheduling variable.
- Because stNCE reduces estimator variance by averaging across two dimensions, it could improve sample efficiency when the data dimension is very large.
- The unification suggests that further variants could be derived by replacing the contrastive loss with other divergence measures while keeping the spatiotemporal difference structure.
Load-bearing premise
The distinct failure modes of purely spatial and purely temporal estimators are the dominant practical obstacles, and joint spatiotemporal differences resolve them without creating comparable new instabilities or biases.
What would settle it
A controlled experiment on a low-dimensional synthetic density where stNCE either underperforms the best spatial-only or temporal-only baseline or exhibits new variance or bias patterns not seen in the separate estimators would falsify the central claim.
Figures


read the original abstract
Learning an energy-based model from data samples is a central problem in machine learning. Many recent and popular methods, such as denoising score matching for training energy-based diffusion models, use stochastic interpolants to corrupt data samples at different noise levels indexed by a time variable. This defines a joint density over both the data space and time, and most methods learn its energy through either spatial or temporal differences. We identify distinct failure modes for both of these approaches. To solve them, we propose Spatiotemporal Noise-Contrastive Estimation (stNCE), a framework for learning the energy through joint spatiotemporal differences. stNCE unifies many existing methods and leads to new training objectives. Experiments on images and molecules demonstrate performance competitive with state-of-the-art density estimation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spatiotemporal Noise-Contrastive Estimation (stNCE) for learning energy-based models from data via stochastic interpolants. It identifies distinct failure modes of purely spatial and purely temporal difference estimators for the joint density over data and time, introduces joint spatiotemporal differences to address them, shows that stNCE unifies existing approaches such as denoising score matching, derives new training objectives, and reports competitive performance against state-of-the-art density estimation methods on image and molecule datasets.
Significance. If the derivations and experiments hold, the work supplies a unified perspective on training EBMs with stochastic interpolants and a practical mechanism for combining spatial and temporal information. The explicit identification of failure modes and the resulting new objectives could influence subsequent work on diffusion-style and energy-based generative models. The competitive empirical results on standard benchmarks add evidence that the approach is viable for density estimation tasks.
minor comments (3)
- [§3.2] §3.2, Eq. (8): the definition of the spatiotemporal difference operator is introduced without an accompanying explicit expansion or pseudocode; adding one would make the unification claim easier to verify against prior spatial-only and temporal-only estimators.
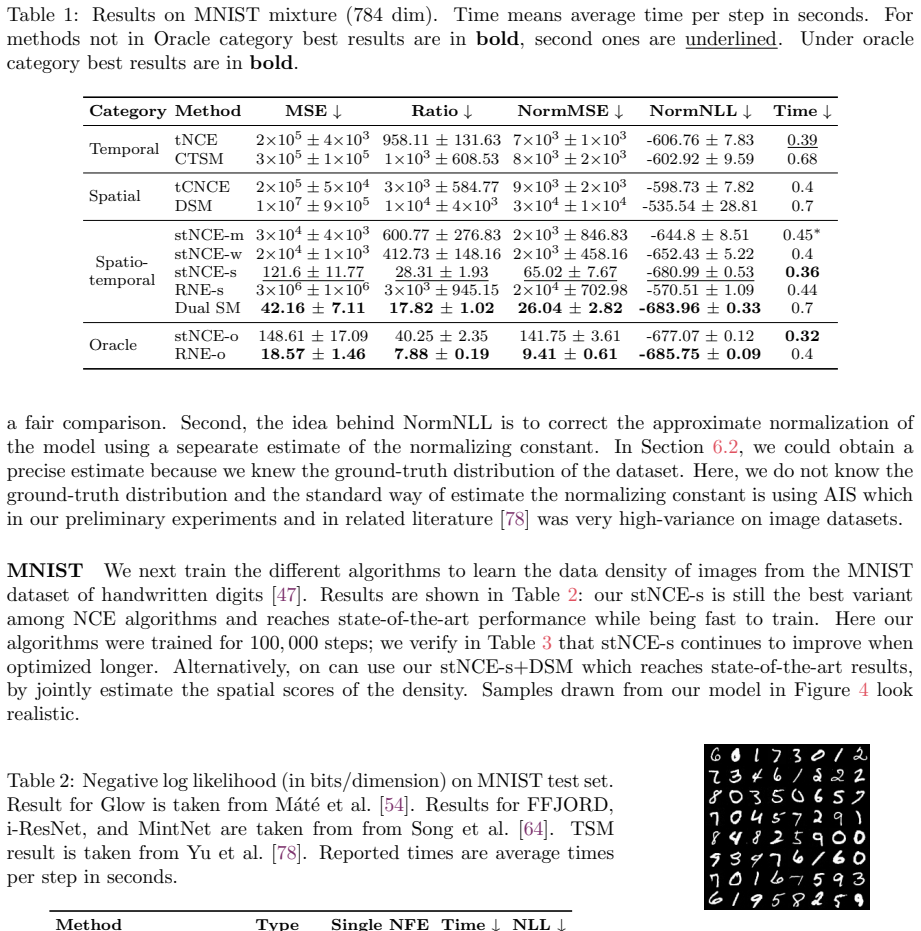
- [Table 2] Table 2: the reported negative log-likelihood values lack standard deviations or number of runs; including these would strengthen the claim of competitiveness with SOTA methods.
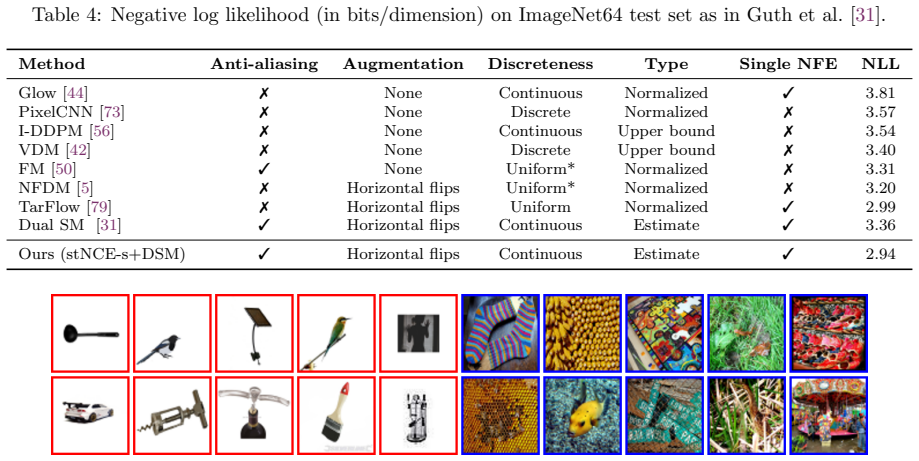
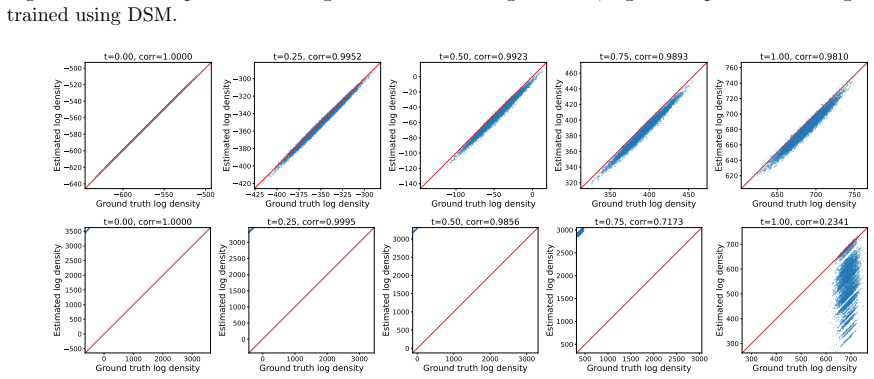
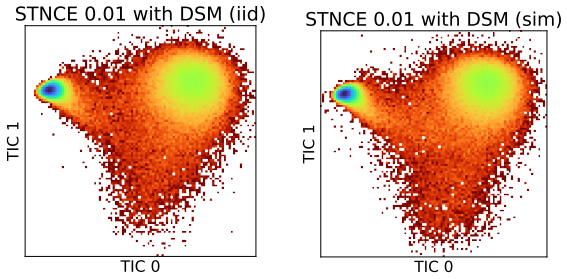
- [Figure 5] Figure 5 caption: the visualization of learned energies does not state the temperature or normalization used, which affects direct comparison to the theoretical joint density.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its significance in unifying training methods for energy-based models via stochastic interpolants, and recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation rests on standard stochastic interpolants without self-referential reduction
full rationale
The paper's central proposal introduces stNCE as a framework using joint spatiotemporal differences on stochastic interpolants to learn energy-based models. The abstract and provided material describe identifying failure modes in spatial/temporal estimators and unifying existing methods via this approach, without any equations or steps that reduce a claimed prediction or result back to a fitted parameter or self-citation by construction. No load-bearing self-citation chains, ansatzes smuggled via prior work, or renamings of known results are evident. The derivation appears self-contained against external benchmarks like standard density estimation methods, with experiments asserted as competitive but not internally forced by the proposal itself.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Few-Step Boltzmann Generators via Scalable Likelihood Flow Maps
SCALLOP replaces Hutchinson's trace estimator with a scalable, vectorized likelihood distillation objective for F2D2 flow maps, cutting training variance and time while improving performance on molecular Boltzmann gen...
Reference graph
Works this paper leans on
-
[1]
Aggarwal, J
R. Aggarwal, J. Chen, N. M. Boffi, and D. Koes. BoltzNCE: Learning likelihoods for boltzmann generation with stochastic interpolants and noise contrastive estimation. InConference on neural information processing systems, 2025
2025
-
[2]
X. Ai, Y. He, A. Gu, R. Salakhutdinov, J. Kolter, N. Boffi, and M. Simchowitz. Joint distillation for fast likelihood evaluation and sampling in flow-based models. InInternational Conference on Learning Representations, 2026
2026
-
[3]
Albergo, N
M. Albergo, N. M. Boffi, and E. Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1–80, 2025
2025
-
[4]
Ansel, E
J. Ansel, E. Yang, H. He, N. Gimelshein, A. Jain, M. Voznesensky, B. Bao, P. Bell, D. Berard, E. Burovski, G. Chauhan, A. Chourdia, W. Constable, A. Desmaison, Z. DeVito, E. Ellison, W. Feng, J. Gong, M. Gschwind, B. Hirsh, S. Huang, K. Kalambarkar, L. Kirsch, M. Lazos, M. Lezcano, Y. Liang, J. Liang, Y. Lu, C. Luk, B. Maher, Y. Pan, C. Puhrsch, M. Reso, ...
2024
-
[5]
Bartosh, D
G. Bartosh, D. Vetrov, and C. A. Naesseth. Neural flow diffusion models: Learnable forward process for improved diffusion modelling. InAnnual Conference on Neural Information Processing Systems, 2024
2024
-
[6]
Batatia, D
I. Batatia, D. P. Kov´ acs, G. N. C. Simm, C. Ortner, and G. Cs´ anyi. Mace: Higher order equivariant message passing neural networks for fast and accurate force fields, 2023
2023
-
[7]
Behrmann, W
J. Behrmann, W. Grathwohl, R. T. Q. Chen, D. Duvenaud, and J.-H. Jacobsen. Invertible residual networks. InInternational Conference on Machine Learning, volume 97, pages 573–582. PMLR, 09–15 Jun 2019
2019
-
[8]
L. Biewald. Experiment tracking with weights and biases, 2020. URLhttps://www.wandb.com/
2020
-
[9]
N. M. Boffi, M. S. Albergo, and E. Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation. InThe thirty-ninth annual conference on neural information processing systems, 2026
2026
-
[10]
Bradbury, R
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, Y. Katariya, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URLhttp://github.com/jax-ml/jax
2018
-
[11]
C. Ceylan. Conditional noise-contrastive estimation: With application to natural image statistics. Master’s thesis, KTH, School of Computer Science and Communication (CSC), Stockholm, Sweden,
-
[12]
Independent thesis, advanced level (20 credits / 30 HE credits)
-
[13]
Ceylan and M
C. Ceylan and M. U. Gutmann. Conditional Noise-Contrastive Estimation of Unnormalised Models. InInternational Conference on Machine Learning, volume 80, pages 726–734. PMLR, July 2018
2018
-
[14]
Chehab, A
O. Chehab, A. Hyvarinen, and A. Risteski. Provable benefits of annealing for estimating normalizing constants: Importance sampling, noise-contrastive estimation, and beyond. InConference on Neural Information Processing Systems, 2023
2023
-
[15]
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud. Neural ordinary differential equa- tions, 2019
2019
-
[16]
W. Chen, S. Li, J. Li, J. Xu, Z. Lin, J. Yang, D. Zeng, J. Paisley, and Q. Zhao. Diffusion secant alignment for score-based density ratio estimation, 2025
2025
-
[17]
W. Chen, S. Li, J. Li, J. Yang, J. Paisley, and D. Zeng. Dequantified diffusion-schr¨ odinger bridge for density ratio estimation. InInternational Conference on Machine Learning, volume 267, pages 8427–8452. PMLR, 13–19 Jul 2025. 13
2025
-
[18]
W. Chen, J. Li, S. Li, Z. Lin, J. Yang, J. Paisley, and D. Zeng. A minimum variance path principle for accurate and stable score-based density ratio estimation. InInternational Conference on Learning Representations, 2026
2026
-
[19]
Chewi, A
S. Chewi, A. Kalavasis, A. Mehrotra, and O. Montasser. DDPM score matching is asymptotically efficient. InICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy, 2025
2025
-
[20]
K. Choi, C. Meng, Y. Song, and S. Ermon. Density ratio estimation via infinitesimal classification. InInternational Conference on Artificial Intelligence and Statistics, volume 151, pages 2552–2573. PMLR, 28–30 Mar 2022
2022
-
[21]
Chrabaszcz, I
P. Chrabaszcz, I. Loshchilov, and F. Hutter. A downsampled variant of imagenet as an alternative to the cifar datasets, 2017
2017
-
[22]
Doucet, W
A. Doucet, W. Grathwohl, A. G. Matthews, and H. Strathmann. Score-based diffusion meets an- nealed importance sampling. InAdvances in Neural Information Processing Systems, volume 35, pages 21482–21494. Curran Associates, Inc., 2022
2022
-
[23]
Du and I
Y. Du and I. Mordatch. Implicit generation and modeling with energy-based models. Ininternational conference on neural information processing systems. Curran Associates Inc., Red Hook, NY, USA, 2019
2019
-
[24]
Y. Du, C. Durkan, R. Strudel, J. B. Tenenbaum, S. Dieleman, R. Fergus, J. Sohl-Dickstein, A. Doucet, and W. S. Grathwohl. Reduce, Reuse, Recycle: Compositional Generation with Energy- Based Diffusion Models and MCMC. InInternational Conference on Machine Learning, volume 202, pages 8489–8510. PMLR, July 2023
2023
-
[25]
P. Eastman, R. Galvelis, R. P. Pel´ aez, C. R. A. Abreu, S. E. Farr, E. Gallicchio, A. Gorenko, M. M. Henry, F. Hu, J. Huang, A. Kr¨ amer, J. Michel, J. A. Mitchell, V. S. Pande, J. P. Rodrigues, J. Rodriguez-Guerra, A. C. Simmonett, S. Singh, J. Swails, P. Turner, Y. Wang, I. Zhang, J. D. Chodera, G. De Fabritiis, and T. E. Markland. OpenMM 8: Molecular ...
-
[26]
R. Gao, E. Nijkamp, D. P. Kingma, Z. Xu, A. M. Dai, and Y. N. Wu. Flow contrastive estimation of energy-based models. In2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pages 7515–7525, 2020
2020
-
[27]
R. Gao, Y. Song, B. Poole, Y. N. Wu, and D. P. Kingma. Learning energy-based models by diffusion recovery likelihood. InInternational conference on learning representations, 2021
2021
-
[28]
Gonzalez, N
M. Gonzalez, N. Fernandez Pinto, T. Tran, e. Gherbi, H. Hajri, and N. Masmoudi. SEEDS: Ex- ponential SDE solvers for fast high-quality sampling from diffusion models. InAdvances in neural information processing systems, volume 36, pages 68061–68120. Curran Associates, Inc., 2023
2023
-
[29]
Goodfellow, J
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative Adversarial Networks.Commun. ACM, 63(11):139–144, Oct. 2020. ISSN 0001-0782. Place: New York, NY, USA
2020
-
[30]
Grathwohl, R
W. Grathwohl, R. T. Q. Chen, J. Bettencourt, and D. Duvenaud. Scalable reversible generative mod- els with free-form continuous dynamics. InInternational Conference on Learning Representations, 2019
2019
-
[31]
Gugger, L
S. Gugger, L. Debut, T. Wolf, P. Schmid, Z. Mueller, S. Mangrulkar, M. Sun, and B. Bossan. Accelerate: Training and inference at scale made simple, efficient and adaptable., 2022. URLhttps: //github.com/huggingface/accelerate
2022
- [32]
-
[33]
M. U. Gutmann and J.-i. Hirayama. Bregman divergence as general framework to estimate un- normalized statistical models. Inconference on uncertainty in artificial intelligence, UAI’11, pages 283–290, Barcelona, Spain, 2011. AUAI Press. ISBN 978-0-9749039-7-2. 14
2011
-
[34]
M. U. Gutmann and A. Hyv¨ arinen. Noise-Contrastive Estimation of Unnormalized Statistical Mod- els, with Applications to Natural Image Statistics.Journal of Machine Learning Research, 13(11): 307–361, 2012
2012
-
[35]
J. He, J. M. Hern´ andez-Lobato, Y. Du, and F. Vargas. RNE: plug-and-play diffusion inference-time control and energy-based training. InInternational Conference on Learning Representations, 2026
2026
-
[36]
G. E. Hinton. Training products of experts by minimizing contrastive divergence.Neural Computa- tion, 14(8):1771–1800, 2002. doi: 10.1162/089976602760128018
-
[37]
G. E. Hinton. Training products of experts by minimizing contrastive divergence.Neural Comput., 14(8):1771–1800, Aug. 2002. ISSN 0899-7667
2002
-
[38]
Holderrieth, U
P. Holderrieth, U. Singer, T. Jaakkola, R. T. Q. Chen, Y. Lipman, and B. Karrer. GLASS flows: Efficient inference for reward alignment of flow and diffusion models. InInternational conference on learning representations, 2026
2026
-
[39]
B. E. Husic, N. E. Charron, D. Lemm, J. Wang, A. P´ erez, M. Majewski, A. Kr¨ amer, Y. Chen, S. Olsson, G. de Fabritiis, F. No´ e, and C. Clementi. Coarse graining molecular dynamics with graph neural networks.The Journal of Chemical Physics, 153(19), Nov. 2020. ISSN 1089-7690. doi: 10.1063/5.0026133. URLhttp://dx.doi.org/10.1063/5.0026133
-
[40]
Hyv¨ arinen, J
A. Hyv¨ arinen, J. Karhunen, and E. Oja.Independent Component Analysis. Adaptive and Cognitive Dynamic Systems: Signal Processing, Learning, Communications and Control. Wiley, 2004. ISBN 9780471464198
2004
-
[41]
Hyv¨ arinen
A. Hyv¨ arinen. Estimation of Non-Normalized Statistical Models by Score Matching.Journal of Machine Learning Research, 6(24):695–709, 2005
2005
-
[42]
Karras, M
T. Karras, M. Aittala, T. Aila, and S. Laine. Elucidating the Design Space of Diffusion-Based Generative Models. InAdvances in Neural Information Processing Systems, volume 35, pages 26565– 26577. Curran Associates, Inc., 2022
2022
-
[43]
Kingma, T
D. Kingma, T. Salimans, B. Poole, and J. Ho. Variational diffusion models. InAdvances in Neural Information Processing Systems, volume 34, pages 21696–21707. Curran Associates, Inc., 2021
2021
-
[44]
D. P. Kingma and J. Ba. Adam: A Method for Stochastic Optimization. InInternational Conference on Learning Representations, 2015
2015
-
[45]
D. P. Kingma and P. Dhariwal. Glow: Generative flow with invertible 1x1 convolutions. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[46]
Koehler, A
F. Koehler, A. Heckett, and A. Risteski. Statistical efficiency of score matching: The view from isoperimetry. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[47]
C.-H. Lai, Y. Takida, N. Murata, T. Uesaka, Y. Mitsufuji, and S. Ermon. FP-diffusion: Improving score-based diffusion models by enforcing the underlying score fokker-planck equation. InInterna- tional Conference on Machine Learning, volume 202, pages 18365–18398. PMLR, 23–29 Jul 2023
2023
-
[48]
LeCun, C
Y. LeCun, C. Cortes, and C. Burges. MNIST handwritten digit database.ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010
2010
-
[49]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He. Back to basics: Let denoising generative models denoise, 2026. arXiv: 2511.13720 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
K. Lindorff-Larsen, S. Piana, R. O. Dror, and D. E. Shaw. How fast-folding proteins fold.Science, 334(6055):517–520, 2011. doi: 10.1126/science.1208351
-
[51]
Lipman, R
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow Matching for Generative Modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[52]
Y. Lipman, M. Havasi, P. Holderrieth, N. Shaul, M. Le, B. Karrer, R. T. Q. Chen, D. Lopez-Paz, H. Ben-Hamu, and I. Gat. Flow matching guide and code, 2024. arXiv: 2412.06264 [cs.LG]. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InInternational conference on learning representations, 2019
2019
-
[54]
C. Lu, Y. Zhou, F. Bao, J. Chen, C. LI, and J. Zhu. DPM-solver: a fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in neural information processing systems, volume 35, pages 5775–5787. Curran Associates, Inc., 2022
2022
-
[55]
M´ at´ e, S
B. M´ at´ e, S. Klein, T. Golling, and F. Fleuret. Flowification: Everything is a normalizing flow. In Advances in Neural Information Processing Systems, 2022
2022
-
[56]
Molgedey and H
L. Molgedey and H. G. Schuster. Separation of a mixture of independent signals using time delayed correlations.Phys. Rev. Lett., 72:3634–3637, Jun 1994
1994
-
[57]
A. Q. Nichol and P. Dhariwal. Improved denoising diffusion probabilistic models. InInternational Conference on Machine Learning, volume 139, pages 8162–8171. PMLR, 18–24 Jul 2021
2021
-
[58]
tex.eprint: https://www.science.org/doi/pdf/10.1126/science.aaw1147
F. No´ e, S. Olsson, J. K¨ ohler, and H. Wu. Boltzmann generators: Sampling equilibrium states of many-body systems with deep learning.Science, 365(6457):eaaw1147, 2019. tex.eprint: https://www.science.org/doi/pdf/10.1126/science.aaw1147
-
[59]
A Diffusive Classification Loss for Learning Energy-based Generative Models
R. OuYang, L. Grenioux, and J. M. Hern´ andez-Lobato. A diffusive classification loss for learning energy-based generative models, 2026. arXiv: 2601.21025 [stat.ML]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Plainer, H
M. Plainer, H. Wu, L. Klein, S. G¨ unnemann, and F. Noe. Consistent sampling and simulation: Molecular dynamics with energy-based diffusion models. InThe thirty-ninth annual conference on neural information processing systems, 2026
2026
-
[61]
Qin and A
Y. Qin and A. Risteski. Fit like you sample: Sample-efficient generalized score matching from fast mixing diffusions. InConference on Learning Theory, volume 247, pages 4413–4457. PMLR, 30 Jun–03 Jul 2024
2024
-
[62]
Rhodes, K
B. Rhodes, K. Xu, and M. U. Gutmann. Telescoping density-ratio estimation. InAdvances in Neural Information Processing Systems, volume 33, pages 4905–4916. Curran Associates, Inc., 2020
2020
-
[63]
Skreta, T
M. Skreta, T. Akhound-Sadegh, V. Ohanesian, R. Bondesan, A. Aspuru-Guzik, A. Doucet, R. Brekel- mans, A. Tong, and K. Neklyudov. Feynman-kac correctors in diffusion: Annealing, guidance, and product of experts. InInternational Conference on Machine Learning, 2025
2025
-
[64]
Song and S
Y. Song and S. Ermon. Generative Modeling by Estimating Gradients of the Data Distribution. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[65]
Y. Song, C. Meng, and S. Ermon. Mintnet: Building invertible neural networks with masked convo- lutions. InNeural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[66]
Y. Song, S. Garg, J. Shi, and S. Ermon. Sliced Score Matching: A Scalable Approach to Density and Score Estimation. InUncertainty in Artificial Intelligence Conference, volume 115, pages 574–584. PMLR, July 2020
2020
-
[67]
Y. Song, C. Durkan, I. Murray, and S. Ermon. Maximum Likelihood Training of Score-Based Diffusion Models. InAdvances in Neural Information Processing Systems, volume 34, pages 1415–
-
[68]
Curran Associates, Inc., 2021
2021
-
[69]
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-Based Gener- ative Modeling through Stochastic Differential Equations. InInternational Conference on Learning Representations, 2021
2021
-
[70]
Y. Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency Models. InInternational Conference on Machine Learning, ICML’23. JMLR.org, 2023. Place: Honolulu, Hawaii, USA
2023
-
[71]
Srivastava, S
A. Srivastava, S. Han, K. Xu, B. Rhodes, and M. U. Gutmann. Estimating the Density Ratio between Distributions with High Discrepancy using Multinomial Logistic Regression.Transactions on Machine Learning Research, 2023. ISSN 2835-8856
2023
-
[72]
Sugiyama, T
M. Sugiyama, T. Suzuki, and T. Kanamori.Density ratio estimation in machine learning. Cambridge University Press, 2012. 16
2012
-
[73]
Thornton, L
J. Thornton, L. Bethune, R. Zhang, A. Bradley, P. Nakkiran, and S. Zhai. Composition and control with distilled energy diffusion models and sequential monte carlo. InAISTATS 2025, 2025
2025
-
[74]
Uehara, T
M. Uehara, T. Matsuda, and F. Komaki. Analysis of noise contrastive estimation from the perspective of asymptotic variance, 2018
2018
-
[75]
van den Oord, N
A. van den Oord, N. Kalchbrenner, L. Espeholt, k. kavukcuoglu, O. Vinyals, and A. Graves. Con- ditional image generation with pixelcnn decoders. InAdvances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
2016
-
[76]
P. Vincent. A Connection Between Score Matching and Denoising Autoencoders.Neural Computa- tion, 23(7):1661–1674, 2011
2011
- [77]
-
[78]
Yair and T
O. Yair and T. Michaeli. Contrastive Divergence Learning is a Time Reversal Adversarial Game. In International Conference on Learning Representations, 2021
2021
-
[79]
H. Yu, M. U. Gutmann, A. Klami, and O. Chehab. Conditional noise-contrastive estimation of energy-based models by jumping between modes. InEurIPS 2025 workshop on principles of gener- ative modeling (PriGM), 2025
2025
-
[80]
H. Yu, A. Klami, A. Hyvarinen, A. Korba, and O. Chehab. Density Ratio Estimation with Condi- tional Probability Paths. InForty-second International Conference on Machine Learning, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.