LLM-based Mockless Unit Test Generation for Java
Pith reviewed 2026-06-29 15:45 UTC · model grok-4.3
The pith
MocklessTester generates Java unit tests without mocks by mining usage patterns and enforcing constraints to reduce LLM hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
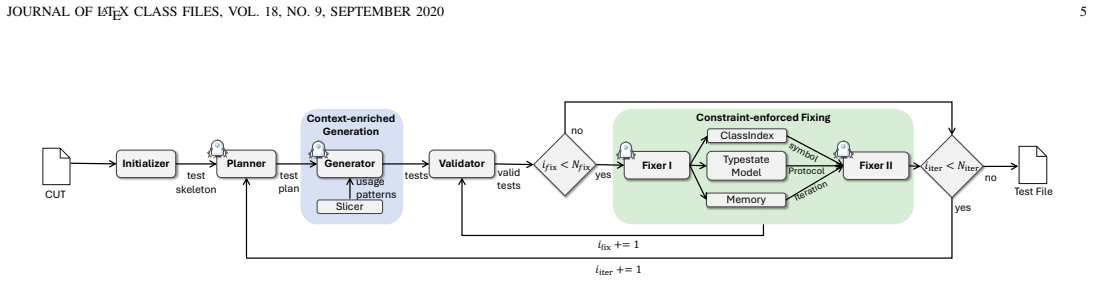
MocklessTester mitigates not knowing hallucinations through context-enriched generation that mines real usage patterns from existing code and mitigates not following hallucinations through constraint-enforced fixing that performs two-stage repair under symbol-, protocol-, and iteration-level constraints using a ClassIndex, a Markov typestate model, and experience memory, yielding higher line coverage, branch coverage, mutation scores, and additional dependency class lines exercised on Defects4J and Deps4J.
What carries the argument
Context-enriched generation combined with two-stage constraint-enforced fixing that uses ClassIndex, Markov typestate model, and experience memory to enforce symbol, protocol, and iteration rules.
If this is right
- Line coverage rises by 19.99 percent on one benchmark and 22.69 percent on the other.
- Branch coverage rises by 24.90 percent and 15.78 percent respectively.
- Mutation scores rise by 13.67 percent and 0.17 percent.
- Tests cover 378 and 55 additional lines of real dependency code on the two benchmarks.
- Total token and time costs increase but stay practical at roughly 70 to 109 seconds and 25k tokens per method.
Where Pith is reading between the lines
- Mockless tests could expose interaction bugs that mocks hide by exercising actual dependency implementations.
- The same pattern-mining and constraint-repair steps might reduce hallucinations in other LLM code-generation tasks such as API usage or refactoring.
- Combining mockless generation with selective mocking for only the hardest dependencies could balance coverage gains against runtime cost.
Load-bearing premise
Mining real usage patterns from code and applying symbol-protocol-iteration repairs will prevent the LLM from producing invalid mockless tests.
What would settle it
Re-running the evaluation on Defects4J and Deps4J and observing no improvement in line or branch coverage over the baseline would show the approach does not deliver the claimed gains.
Figures




read the original abstract
Large language models (LLMs) have shown strong potential for automated test generation, yet most approaches to generating Java unit tests still rely on mocking frameworks to handle dependencies. Mockless test generation could exercise more real low-level code, but it faces challenges such as invalid test code generation due to hallucination, strict language constraints, and inadequate dependency awareness. We identify two causes behind these hallucinations: not knowing, where the LLM lacks sufficient context, and not following, where the LLM fails to comply with constraints even when they are provided. We present MocklessTester, a mockless unit test generation approach built around two strategies: context-enriched generation and constraint-enforced fixing. To mitigate not knowing, context-enriched generation mines real usage patterns from existing code to generate tests. To mitigate not following, constraint-enforced fixing performs two-stage repair under symbol-, protocol-, and iteration-level constraints, using a ClassIndex, a Markov typestate model, and experience memory. We evaluate MocklessTester against the state-of-the-art baseline on Defects4J and Deps4J. Results show that MocklessTester improves line coverage by 19.99% and 22.69% and branch coverage by 24.90% and 15.78% on the two benchmarks, respectively, and improves mutation score by 13.67% and 0.17%. Beyond the class under test, MocklessTester also exercises more real dependency code, covering 378 and 55 additional lines in dependency classes, respectively. The improvement in test quality comes with higher total token and time costs than the baseline. Nevertheless, the cost per method remains practical, averaging 108.97 seconds and 26.59k tokens on Defects4J, and 69.85 seconds and 25.46k tokens on Deps4J. Ablation results confirm that all major components contribute positively to the final performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MocklessTester, an LLM-based approach for generating mockless Java unit tests. It identifies two hallucination modes ('not knowing' and 'not following') and mitigates them via context-enriched generation (mining real usage patterns from existing code) and constraint-enforced fixing (two-stage repair under symbol-, protocol-, and iteration-level constraints using ClassIndex, a Markov typestate model, and experience memory). On Defects4J and Deps4J, it reports line coverage gains of 19.99% and 22.69%, branch coverage gains of 24.90% and 15.78%, mutation score gains of 13.67% and 0.17%, plus 378 and 55 additional dependency lines covered, with ablations confirming component contributions at higher token/time cost.
Significance. If the results hold, the work is significant for software engineering as it reduces reliance on mocks in automated test generation, enabling tests that exercise more real dependency code. Strengths include the explicit two-hallucination framing, ablation validation of ClassIndex/Markov/experience memory components, and acknowledgment that per-method costs remain practical (108.97s/26.59k tokens on Defects4J). This provides a concrete, empirically grounded advance over prior LLM test generators.
major comments (2)
- [Evaluation] Evaluation section: The manuscript reports specific percentage improvements (e.g., 19.99% line coverage, 13.67% mutation score) but provides insufficient detail on experimental methodology, including number of runs per method, statistical significance tests, or result variance. This is load-bearing for the central empirical claims in the abstract.
- [Method] Constraint-enforced fixing description: The Markov typestate model for protocol-level constraints lacks detail on training data, state definitions, or accuracy metrics, making it difficult to assess its specific contribution to mitigating 'not following' hallucinations despite the ablation results.
minor comments (2)
- [Results] The 0.17% mutation score gain on Deps4J is marginal; the paper should explicitly discuss its practical significance in the results or discussion section.
- [Abstract] Ensure consistent use of 'respectively' when reporting paired metrics across the two benchmarks in the abstract and results tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The manuscript reports specific percentage improvements (e.g., 19.99% line coverage, 13.67% mutation score) but provides insufficient detail on experimental methodology, including number of runs per method, statistical significance tests, or result variance. This is load-bearing for the central empirical claims in the abstract.
Authors: We agree this detail is necessary for reproducibility and to support the reported gains. The original experiments used 5 independent runs per method to mitigate LLM nondeterminism, with results reported as means; however, variance, standard deviations, and statistical tests were omitted. In the revision we will add a new subsection (Evaluation Setup) that explicitly states the run count, reports mean ± std, and includes paired t-test p-values (all < 0.05) against the baseline. This directly addresses the load-bearing concern. revision: yes
-
Referee: [Method] Constraint-enforced fixing description: The Markov typestate model for protocol-level constraints lacks detail on training data, state definitions, or accuracy metrics, making it difficult to assess its specific contribution to mitigating 'not following' hallucinations despite the ablation results.
Authors: We accept that the description is currently too terse. The Markov model was trained on call-sequence traces mined via ClassIndex from the training portions of Defects4J and Deps4J; states encode typestates of dependency classes (e.g., FileInputStream: closed/open/reading), and transition probabilities were estimated by maximum likelihood. On a held-out trace set the model achieved 91.4% next-state accuracy. We will expand the Method section with these specifics plus a short table of state definitions, while retaining the existing ablation that isolates its contribution. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper describes an empirical software engineering approach (MocklessTester) that mines usage patterns and applies constrained repair for LLM-based test generation. All reported results (coverage gains, mutation scores, dependency exercise) are obtained from direct evaluation on public benchmarks (Defects4J, Deps4J) with ablation studies. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided material. The central claims rest on experimental outcomes rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beck,Test driven development: By example
K. Beck,Test driven development: By example. Addison- Wesley Professional, 2022
2022
-
[2]
Hallucination to consensus: Multi-agent llms for end-to-end junit test generation,
Q. Xu, G. Wang, L. Briand, and K. Liu, “Hallucination to consensus: Multi-agent llms for end-to-end junit test generation,”ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[3]
Swe-abs: Adversarial benchmark strengthening exposes inflated success rates on test-based benchmark,
B. Yu, Y . Cao, Y . Zhang, L. Lin, J. Xu, Z. Zhong, Q. Xu, G. Wang, J. Cao, S.-C. Cheunget al., “Swe-abs: Adversarial benchmark strengthening exposes inflated success rates on test-based benchmark,”arXiv preprint arXiv:2603.00520, 2026
-
[4]
A large-scale evaluation of automated unit test generation using evosuite,
G. Fraser and A. Arcuri, “A large-scale evaluation of automated unit test generation using evosuite,”ACM Trans. Softw. Eng. Methodol., vol. 24, no. 2, Dec. 2014. [Online]. Available: https://doi.org/10.1145/2685612
-
[5]
Randoop: feedback-directed random testing for java,
C. Pacheco and M. D. Ernst, “Randoop: feedback-directed random testing for java,” inCompanion to the 22nd ACM SIGPLAN conference on Object-oriented programming sys- tems and applications companion, 2007, pp. 815–816
2007
-
[6]
Mutation-Guided Unit Test Generation with a Large Language Model
G. Wang, Q. Xu, L. C. Briand, and K. Liu, “Mutation- guided unit test generation with a large language model,” arXiv preprint arXiv:2506.02954, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Llm test genera- tion via iterative hybrid program analysis,
S. Gu, N. Nashid, and A. Mesbah, “Llm test genera- tion via iterative hybrid program analysis,”arXiv preprint arXiv:2503.13580, 2025
-
[8]
Large language models for unit test generation: Achievements, challenges, and opportunities,
B. Chu, Y . Feng, K. Liu, Z. Guo, Y . Zhang, H. Shi, Z. Nan, and B. Xu, “Large language models for unit test generation: Achievements, challenges, and opportunities,” arXiv preprint arXiv:2511.21382, 2025
-
[9]
Coverup: Effective high coverage test generation for python,
J. Altmayer Pizzorno and E. D. Berger, “Coverup: Effective high coverage test generation for python,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 2897– 2919, 2025
2025
-
[10]
Llm-based test-driven interactive code generation: User study and empirical evaluation,
S. Fakhoury, A. Naik, G. Sakkas, S. Chakraborty, and S. K. Lahiri, “Llm-based test-driven interactive code generation: User study and empirical evaluation,”IEEE Transactions on Software Engineering, vol. 50, no. 9, pp. 2254–2268, 2024
2024
-
[11]
TestEval: Benchmarking large language models for test case generation,
W. Wang, C. Yang, Z. Wang, Y . Huang, Z. Chu, D. Song, L. Zhang, A. R. Chen, and L. Ma, “TestEval: Benchmarking large language models for test case generation,” inFindings of the Association for Computational Linguistics: NAACL JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 15 2025, L. Chiruzzo, A. Ritter, and L. Wang, Eds. Albuquerque, New ...
2020
-
[13]
To mock or not to mock? an empirical study on mocking prac- tices,
D. Spadini, M. Aniche, M. Bruntink, and A. Bacchelli, “To mock or not to mock? an empirical study on mocking prac- tices,” in2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR), 2017, pp. 402–412
2017
-
[14]
Togll: Correct and strong test oracle generation with llms,
S. B. Hossain and M. Dwyer, “Togll: Correct and strong test oracle generation with llms,”arXiv preprint arXiv:2405.03786, 2024
-
[15]
Modeling and discovering vulnerabilities with code property graphs,
F. Yamaguchi, N. Golde, D. Arp, and K. Rieck, “Modeling and discovering vulnerabilities with code property graphs,” inProceedings of the 2014 IEEE Symposium on Security and Privacy (S&P). IEEE, 2014, pp. 590–604
2014
-
[16]
Comex: A tool for generating customized source code representa- tions,
D. Das, N. S. Mathews, A. Mathai, S. Tamilselvam, K. Sedamaki, S. Chimalakonda, and A. Kumar, “Comex: A tool for generating customized source code representa- tions,” in2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2023, pp. 2054–2057
2023
-
[17]
Agent development kit for java (adk-java),
Google, “Agent development kit for java (adk-java),” https: //github.com/google/adk-java, 2025, accessed March 2026
2025
-
[18]
Fit framework: Model- engineering utilities for java,
Huawei ModelEngine Group, “Fit framework: Model- engineering utilities for java,” https://github.com/ ModelEngine-Group/fit-framework, 2025, accessed March 2026
2025
-
[19]
Agentscope: A flexible yet ro- bust multi-agent platform (java runtime),
AgentScope Contributors, “Agentscope: A flexible yet ro- bust multi-agent platform (java runtime),” https://github. com/agentscope-ai/agentscope-java, 2025, accessed March 2026
2025
-
[20]
Agent-to-agent (a2a) sdk for java,
A2A Project Contributors, “Agent-to-agent (a2a) sdk for java,” https://github.com/a2aproject/a2a-java, 2025, accessed March 2026
2025
-
[21]
jquick-curl: An antlr-based curl command parser for java,
H. Pao, “jquick-curl: An antlr-based curl command parser for java,” https://github.com/paohaijiao/jquick-curl, 2025, accessed March 2026
2025
-
[22]
Chatunitest: A framework for llm-based test generation,
Y . Chen, Z. Hu, C. Zhi, J. Han, S. Deng, and J. Yin, “Chatunitest: A framework for llm-based test generation,” inCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, 2024, pp. 572–576
2024
-
[23]
64 Sigma Jahan, Saurabh Singh Rajput, Tushar Sharma, and Mohammad Masudur Rahman
A. Deljouyi, R. Koohestani, M. Izadi, and A. Zaidman, “Leveraging large language models for enhancing the understandability of generated unit tests,” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering, ser. ICSE ’25. IEEE Press, 2025, p. 1449–1461. [Online]. Available: https://doi.org/10.1109/ ICSE55347.2025.00032
-
[24]
Code-aware prompting: A study of coverage-guided test generation in regression setting using llm,
G. Ryan, S. Jain, M. Shang, S. Wang, X. Ma, M. K. Ra- manathan, and B. Ray, “Code-aware prompting: A study of coverage-guided test generation in regression setting using llm,”Proceedings of the ACM on Software Engineering, vol. 1, no. FSE, pp. 951–971, 2024
2024
-
[25]
PIT: A practical mutation testing tool for Java (demo),
H. Coles, T. Laurent, C. Henard, M. Papadakis, and A. Ven- tresque, “PIT: A practical mutation testing tool for Java (demo),” inProceedings of the 25th International Sympo- sium on Software Testing and Analysis (ISSTA). ACM, 2016, pp. 449–452
2016
-
[26]
A practical guide for using statistical tests to assess randomized algorithms in software engineering,
A. Arcuri and L. Briand, “A practical guide for using statistical tests to assess randomized algorithms in software engineering,” inProceedings of the 33rd international con- ference on software engineering, 2011, pp. 1–10
2011
-
[27]
A critique and improvement of the cl common language effect size statistics of mcgraw and wong,
A. Vargha and H. D. Delaney, “A critique and improvement of the cl common language effect size statistics of mcgraw and wong,”Journal of Educational and Behavioral Statis- tics, vol. 25, no. 2, pp. 101–132, 2000
2000
-
[28]
Langchain official website,
“Langchain official website,” Accessed: 2025. [Online]. Available: https://www.langchain.com/
2025
-
[29]
Qwen3-Coder: Agentic coding models,
Qwen Team, “Qwen3-Coder: Agentic coding models,” https://qwenlm.github.io/blog/qwen3-coder/, 2025, accessed March 2026
2025
-
[30]
Efficient memory management for large language model serving with pagedat- tention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedat- tention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[31]
Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation,
H. Qian, Z. Liu, P. Zhang, K. Mao, D. Lian, Z. Dou, and T. Huang, “Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation,” in Proceedings of the ACM on Web Conference 2025, 2025, pp. 2366–2377
2025
-
[32]
EXPEREPAIR: Dual-Memory Enhanced LLM-based Repository-Level Program Repair
F. Mu, J. Wang, L. Shi, S. Wang, S. Li, and Q. Wang, “Experepair: Dual-memory enhanced llm-based repository- level program repair,”arXiv preprint arXiv:2506.10484, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Citrus: Automated unit testing tool for real-world c++ programs,
R. S. Herlim, Y . Kim, and M. Kim, “Citrus: Automated unit testing tool for real-world c++ programs,” in2022 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE Computer Society, 2022, pp. 400–410
2022
-
[34]
Pynguin: Automated unit test generation for python,
S. Lukasczyk and G. Fraser, “Pynguin: Automated unit test generation for python,” inProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, 2022, pp. 168–172
2022
-
[35]
Test generation for embedded executables via concolic execution in a real environment,
T. Chen, X.-S. Zhang, X.-L. Ji, C. Zhu, Y . Bai, and Y . Wu, “Test generation for embedded executables via concolic execution in a real environment,”IEEE Transactions on Reliability, vol. 64, no. 1, pp. 284–296, 2014
2014
-
[36]
Feedback-directed unit test generation for c/c++ using concolic execution,
P. Garg, F. Ivan ˇci´c, G. Balakrishnan, N. Maeda, and A. Gupta, “Feedback-directed unit test generation for c/c++ using concolic execution,” in2013 35th International Con- ference on Software Engineering (ICSE). IEEE, 2013, pp. 132–141
2013
-
[37]
Large language models for c test case generation: A comparative analysis,
A. Guzu, G. Nicolae, H. Cucu, and C. Burileanu, “Large language models for c test case generation: A comparative analysis,”Electronics, vol. 14, no. 11, p. 2284, 2025
2025
-
[38]
N. Huynh and B. Lin, “Large language models for code generation: A comprehensive survey of challenges, techniques, evaluation, and applications,”arXiv preprint arXiv:2503.01245, 2025
-
[39]
Aster: Natural and multi-language unit test generation with llms,
R. Pan, M. Kim, R. Krishna, R. Pavuluri, and S. Sinha, “Aster: Natural and multi-language unit test generation with llms,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 16 (ICSE-SEIP). IEEE, 2025, pp. 413–424
2020
-
[40]
Citywalk: Enhancing llm-based c++ unit test generation via project-dependency awareness and language-specific knowledge,
Y . Zhang, Q. Lu, K. Liu, W. Dou, J. Zhu, L. Qian, C. Zhang, Z. Lin, and J. Wei, “Citywalk: Enhancing llm-based c++ unit test generation via project-dependency awareness and language-specific knowledge,”ACM Transactions on Soft- ware Engineering and Methodology, 2025
2025
-
[41]
Cubetesterai: Automated junit test generation using the llama model,
D. Gorla, S. Kumar, P. N. R. Lorenzini, and A. Alipourfaz, “Cubetesterai: Automated junit test generation using the llama model,” in2025 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 2025, pp. 565– 576
2025
-
[42]
Static program analysis guided llm based unit test genera- tion,
S. Roy Chowdhury, G. Sridhara, A. Raghavan, J. Bose, S. Mazumdar, H. Singh, S. B. Sugumaran, and R. Britto, “Static program analysis guided llm based unit test genera- tion,” inProceedings of the 8th International Conference on Data Science and Management of Data (12th ACM IKDD CODS and 30th COMAD), 2024, pp. 279–283
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.