Learning to Adapt SFT Data for Better Reasoning Generalization
Pith reviewed 2026-06-29 18:12 UTC · model grok-4.3
The pith
A reinforcement-learned mapper transforms mismatched SFT demonstrations into model-adapted versions that improve reasoning generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
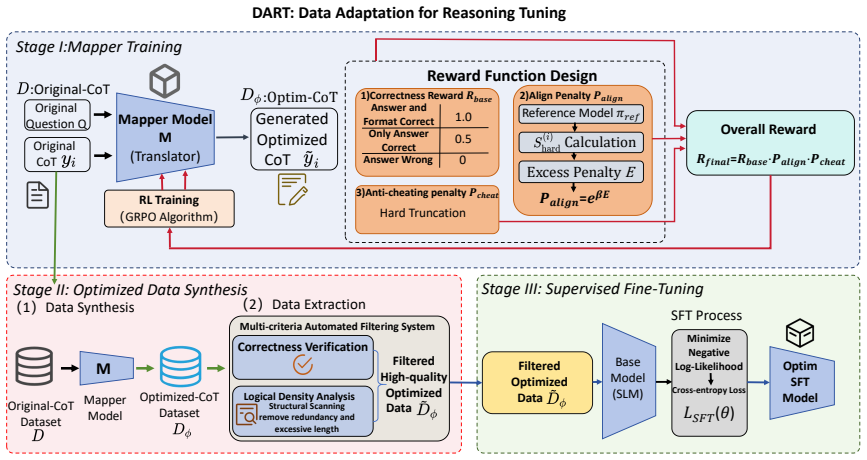
DART formulates the use of a fixed, potentially distributionally misaligned SFT dataset as an optimization problem over demonstration transformations. It trains a mapper model with reinforcement learning to convert original SFT data into model-adapted supervision that better matches the target model's distribution and learning preferences. The transformed data are then used for SFT, allowing the target model to better exploit external supervision.
What carries the argument
The mapper model trained via reinforcement learning to rewrite SFT demonstrations so their distribution aligns with the target model's learning preferences.
If this is right
- DART improves generalization on reasoning tasks across multiple models and datasets.
- Training with the adapted data is more sample-efficient than applying reinforcement learning directly to the target model.
- Models reach higher final performance than they do with standard SFT on the same original dataset.
- The method keeps the benefits of dense SFT supervision while reducing the distribution mismatch that normally limits generalization.
Where Pith is reading between the lines
- The same mapper approach could be applied to other post-training stages such as preference tuning or continued pre-training where data alignment matters.
- If the mapper itself can be trained more cheaply, the overall cost of obtaining high-quality supervision signals would drop relative to full RL runs.
- The technique raises the question of whether learned data transformations can replace hand-crafted data curation pipelines in reasoning domains.
Load-bearing premise
A separately trained mapper model can reliably produce transformed demonstrations whose distribution better matches the target model's learning preferences without introducing new biases or reducing supervision quality.
What would settle it
Training the target model on DART-transformed data yields no improvement or a clear drop in accuracy on held-out reasoning benchmarks compared with the original SFT data.
Figures



read the original abstract
Large language models (LLMs) have achieved remarkable progress, with post-training playing a crucial role in enhancing their reasoning capabilities. Among post-training paradigms, supervised fine-tuning (SFT) is widely used: it leverages external data to provide dense supervision and enables efficient training. However, directly fine-tuning on expert data can hurt generalization when the data distribution is mismatched with the target model's own distribution. In this work, we propose Data Adaptation for Reasoning Tuning (DART), which formulates the use of a fixed, potentially distributionally misaligned SFT dataset as an optimization problem over demonstration transformations. DART trains a mapper model with reinforcement learning to convert original SFT data into model-adapted supervision that better matches the target model's distribution and learning preferences. The transformed data are then used for SFT, allowing the target model to better exploit external supervision. Experiments across multiple models and datasets show that DART improves generalization, achieves higher training efficiency than direct RL, and helps models surpass standard SFT. Our code is available at https://anonymous.4open.science/r/DART525E50D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Data Adaptation for Reasoning Tuning (DART), which frames SFT data adaptation as an optimization problem solved by training a separate mapper model via reinforcement learning; the mapper transforms original demonstrations to better match the target model's distribution and learning preferences, after which the adapted data are used for SFT. The central empirical claim is that this yields improved reasoning generalization, higher training efficiency than direct RL, and performance surpassing standard SFT across multiple models and datasets.
Significance. If the empirical claims hold under rigorous controls, the approach would be significant for post-training of LLMs: it offers a potentially cheaper alternative to direct RL while addressing distribution mismatch between fixed SFT corpora and target models. The public code release supports reproducibility and is a positive feature.
major comments (2)
- [§3 and §4] §3 (Method) and §4 (Experiments): the reward function and training objective for the RL mapper are not specified in sufficient detail to evaluate whether the mapper avoids hallucination, simplification, or introduction of new biases in the transformed demonstrations; without this, the central assumption that the mapper produces higher-quality adapted supervision cannot be assessed.
- [§4] §4: the experimental design supplies no information on number of runs, statistical significance tests, controls for data volume or quality, or ablation of the mapper's effect versus simple filtering/augmentation; this undermines the claims of improved generalization and efficiency over direct RL and standard SFT.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating where we will revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): the reward function and training objective for the RL mapper are not specified in sufficient detail to evaluate whether the mapper avoids hallucination, simplification, or introduction of new biases in the transformed demonstrations; without this, the central assumption that the mapper produces higher-quality adapted supervision cannot be assessed.
Authors: We agree that the current description of the reward function and RL objective in §3 lacks sufficient explicit detail for full evaluation of potential artifacts such as hallucination or bias. In the revised manuscript we will expand §3 with the complete mathematical formulation of the reward (a weighted sum of task-performance reward from the target model and a content-consistency regularizer) and the full PPO-style training objective. We will also add a short analysis subsection in §4 that quantifies transformation fidelity on held-out examples to directly address concerns about simplification or new biases. revision: yes
-
Referee: [§4] §4: the experimental design supplies no information on number of runs, statistical significance tests, controls for data volume or quality, or ablation of the mapper's effect versus simple filtering/augmentation; this undermines the claims of improved generalization and efficiency over direct RL and standard SFT.
Authors: We acknowledge that §4 currently omits several standard experimental controls. In the revision we will report the number of random seeds (three), include statistical significance tests (paired t-tests with p-values), and add explicit controls confirming that all compared methods use identical data volume. We will also expand the ablation study to include a simple filtering baseline and a basic augmentation baseline. The existing comparisons to direct RL already hold data volume fixed; we will make this explicit. These additions will be incorporated without altering the core empirical claims. revision: partial
Circularity Check
No circularity: empirical optimization method with no derivations or load-bearing self-citations
full rationale
The paper presents DART as an external RL-based optimization to train a mapper that transforms SFT data, followed by standard SFT and empirical evaluation across models/datasets. No equations, first-principles derivations, or uniqueness theorems appear. No self-citations are invoked to justify core premises. The central claim rests on experimental results rather than any reduction to fitted inputs or prior author work by construction. This is a standard empirical ML paper with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
Opencodereasoning: Advancing data dis- tillation for competitive coding.arXiv preprint arXiv:2504.01943. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program synthesis with large language models.Preprint, arXiv:2108.07732. Lichang Chen,...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Xingyu Chen, Junxiu An, Jun Guo, Li Wang, and Jingcai Guo. 2026a. Kg-augmented executable cot for mathematical coding.Neural Networks, page 109006. Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. 2026b. Does rein- forcement learning really ince...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Group-in-group policy optimization for llm agent training.Advances in Neural Information Pro- cessing Systems, 38:46375–46408. Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. 2025. Rstar-math: Small llms can master math reason- ing with self-evolved deep thinking.arXiv preprint arXiv:2501.04519. Etash Guha, Ry...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Are NLP models really able to solve simple math word problems?CoRR, abs/2103.07191. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 oth- ers. 2025. Qwen2.5 technical report.Prepr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
D3: Diversity, difficulty, and dependability- aware data selection for sample-efficient llm instruc- tion tuning.arXiv preprint arXiv:2503.11441. Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, and 1 others. 2023. Lima: Less is more for alignment.Advances in Neural Information Pro- cess...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.