Leveraging Text-to-Image Diffusion Models for Unsupervised Visual Object Tracking
Pith reviewed 2026-06-29 17:50 UTC · model grok-4.3
The pith
Pretrained text-to-image diffusion models track arbitrary objects in video by learning prompts that activate matching regions in cross-attention maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
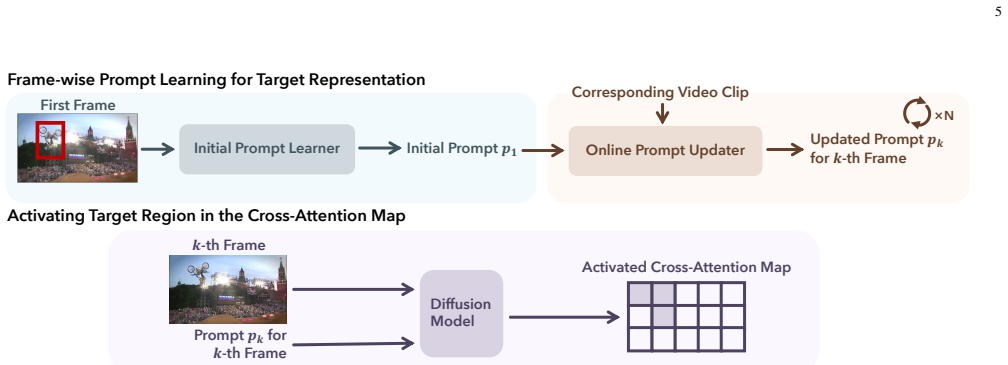
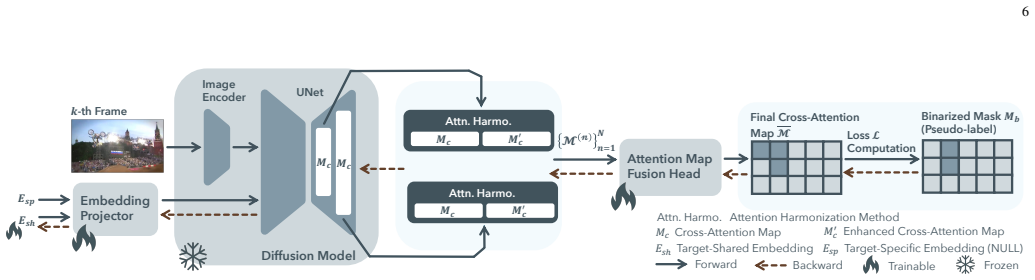
By reinterpreting the diffusion model as a bridge between text and image via cross-attention, a prompt is learned that represents the tracking target and activates its corresponding region in the cross-attention map for each frame, which enables object tracking with the diffusion model. The approach consists of an initial prompt learner that captures the target in the first frame and an online prompt updater that refines the prompt based on motion information for consistent tracking across frames.
What carries the argument
Cross-attention maps produced by a frozen pretrained text-to-image diffusion model, which highlight image regions semantically aligned with a learned text prompt for the tracking target.
If this is right
- Object tracking can proceed without any supervised training on annotated video data.
- Semantic knowledge encoded during large-scale image generation training transfers directly to localization in video.
- A single learned prompt plus online motion-based updates maintains identity across frames for arbitrary targets.
- The frozen model requires no task-specific retraining or fine-tuning on tracking benchmarks.
Where Pith is reading between the lines
- The same cross-attention signal could support related tasks such as unsupervised video segmentation by extracting the highlighted regions.
- Prompt updates based on motion might be combined with appearance cues from other models to handle long-term occlusions.
- Because the diffusion backbone stays frozen, larger future models trained on more data could improve tracking accuracy without extra annotation cost.
Load-bearing premise
Cross-attention maps from a frozen pretrained diffusion model will reliably and consistently highlight the semantic region of any arbitrary unseen tracking target across diverse video frames.
What would settle it
Running the method on standard tracking videos and checking whether the attention maps stop consistently localizing the target object in a large fraction of frames would disprove the claim.
Figures





read the original abstract
Unsupervised visual object tracking is a challenging task that requires following arbitrary targets in videos without training on ground-truth annotations. Despite considerable progress, existing state-of-the-art unsupervised trackers often struggle in scenarios that demand fine-grained understanding of semantic and visual structural information within video frames. Text-to-image diffusion models are well known for their ability to generate images that accurately reflect the semantics and structures described in the input prompt, demonstrating a strong grasp of visual semantics and structures. Building on this capability, we approach the unsupervised tracking from a new perspective by exploiting the rich semantic knowledge encoded in pretrained text-to-image diffusion models. To adapt the diffusion models, which are originally developed for image generation, to the tracking task, we reinterpret the models as a bridge between text and image modalities. This connection is realized through the cross-attention mechanism: when both text and an image are input into the models, they highlight the regions of the image that are semantically aligned with the text in the cross-attention maps. We therefore learn a prompt that represents the tracking target and activates its corresponding region in the cross-attention map for each frame, which enables object tracking with the diffusion model. Specifically, our method Diff-Tracking is composed of two main components: an initial prompt learner and an online prompt updater. The initial prompt learner generates a prompt that captures the target object in the first frame, allowing the diffusion model to identify the target. The online prompt updater refines the prompt based on motion information, enabling consistent tracking across video frames. We evaluate our approach on six challenging tracking datasets demonstrate the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Diff-Tracking, an unsupervised visual object tracking method that repurposes a frozen pretrained text-to-image diffusion model. A prompt is learned to represent the target and activate its region in the model's cross-attention maps for each video frame. The approach comprises an initial prompt learner (first frame) and an online prompt updater (subsequent frames, using motion information). Effectiveness is claimed on six tracking datasets.
Significance. If the central claim holds, the work offers a novel unsupervised tracking paradigm that exploits the semantic and structural knowledge already present in large-scale diffusion models without fine-tuning or annotated tracking data. The reinterpretation of cross-attention as a text-image bridge is a creative reuse of an existing mechanism and could influence future applications of generative models to video tasks.
major comments (2)
- [Abstract] Abstract and method description: the central claim that a learned prompt activates the target region in cross-attention maps for reliable bounding-box tracking rests on the unverified assumption that these maps from a frozen model consistently localize arbitrary, previously unseen targets despite appearance variation, motion, and distractors. No section provides independent verification, qualitative examples, or quantitative measures of map quality on tracking sequences.
- [Abstract] Abstract and evaluation description: no equations, algorithm, loss function, or optimization procedure is supplied for either the initial prompt learner or the online prompt updater, and no quantitative results, success rates, or ablation studies appear for the six datasets. These omissions make the effectiveness claim impossible to assess and are load-bearing for the contribution.
minor comments (1)
- [Abstract] The final sentence of the abstract contains a grammatical error ('We evaluate our approach on six challenging tracking datasets demonstrate the effectiveness of our approach').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the presentation of our method and evaluation. The comments correctly identify areas where the manuscript can be strengthened for clarity and completeness. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim that a learned prompt activates the target region in cross-attention maps for reliable bounding-box tracking rests on the unverified assumption that these maps from a frozen model consistently localize arbitrary, previously unseen targets despite appearance variation, motion, and distractors. No section provides independent verification, qualitative examples, or quantitative measures of map quality on tracking sequences.
Authors: We agree that direct verification of cross-attention map quality would better support the central claim. The prompt optimization is explicitly designed to maximize target activation in the maps, but the manuscript would benefit from additional evidence. In revision we will add a dedicated analysis subsection with qualitative examples of the maps on sample sequences and quantitative measures such as overlap with ground-truth regions. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: no equations, algorithm, loss function, or optimization procedure is supplied for either the initial prompt learner or the online prompt updater, and no quantitative results, success rates, or ablation studies appear for the six datasets. These omissions make the effectiveness claim impossible to assess and are load-bearing for the contribution.
Authors: The provided manuscript text is limited to the abstract, which is necessarily brief and omits these details. The full paper contains the algorithmic description, loss functions (cross-entropy on attention activation for the initial learner and motion-consistency term for the updater), and optimization via gradient descent on the prompt embeddings. Experiments report success rates and comparisons on the six datasets. To address the concern we will expand the method section with explicit equations and algorithm pseudocode, and ensure the abstract references the evaluation protocol. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central method learns a prompt to activate regions in cross-attention maps produced by a frozen external pretrained text-to-image diffusion model. This relies on the independent properties of the pretrained model rather than any self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations or steps in the provided description reduce the tracking output to the method's own inputs by construction; the approach is self-contained against the external model's semantics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained text-to-image diffusion models encode rich semantic knowledge accessible via cross-attention maps for arbitrary objects in video frames.
Reference graph
Works this paper leans on
-
[1]
Omnitracker: Unifying visual object tracking by tracking-with- detection,
J. Wang, Z. Wu, D. Chen, C. Luo, X. Dai, L. Yuan, and Y .-G. Jiang, “Omnitracker: Unifying visual object tracking by tracking-with- detection,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025
2025
-
[2]
A novel siamese attention net- work for visual object tracking of autonomous vehicles,
J. Chen, Y . Ai, Y . Qian, and W. Zhang, “A novel siamese attention net- work for visual object tracking of autonomous vehicles,”Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering, vol. 235, no. 10-11, pp. 2764–2775, 2021
2021
-
[3]
Manifold siamese network: A novel visual tracking convnet for autonomous vehicles,
M. Gao, L. Jin, Y . Jiang, and B. Guo, “Manifold siamese network: A novel visual tracking convnet for autonomous vehicles,”IEEE Transac- tions on Intelligent Transportation Systems, vol. 21, no. 4, pp. 1612– 1623, 2019
2019
-
[4]
4d iriom: 4d imaging radar inertial odometry and mapping,
Y . Zhuang, B. Wang, J. Huai, and M. Li, “4d iriom: 4d imaging radar inertial odometry and mapping,”IEEE Robotics and Automation Letters, vol. 8, no. 6, pp. 3246–3253, 2023
2023
-
[5]
Visual tracking of a moving target by a camera mounted on a robot: A combination of control and vision,
N. P. Papanikolopoulos, P. K. Khosla, and T. Kanade, “Visual tracking of a moving target by a camera mounted on a robot: A combination of control and vision,”IEEE transactions on robotics and automation, vol. 9, no. 1, pp. 14–35, 1993
1993
-
[6]
Design of object tracking for military robot using pid controller and computer vision,
W. Budiharto, E. Irwansyah, J. S. Suroso, and A. A. S. Gunawan, “Design of object tracking for military robot using pid controller and computer vision,”ICIC Express Letters, vol. 14, no. 3, pp. 289–294, 2020
2020
-
[7]
Gv-iriom: Gnss-visual-aided 4d radar inertial odometry and mapping in large-scale environments,
B. Wang, Y . Zhuang, J. Huai, Y . Chen, J. Chen, and N. El-Bendary, “Gv-iriom: Gnss-visual-aided 4d radar inertial odometry and mapping in large-scale environments,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 221, pp. 310–323, 2025. TABLE XV EFFECT OF PROMPT UPDATE INTERVAL ONLASOT [33]. “INTERVAL” = NUMBER OF FRAMES BETWEEN CONSECUTIVE ONLIN...
2025
-
[8]
Deformable siamese attention networks for visual object tracking,
Y . Yu, Y . Xiong, W. Huang, and M. R. Scott, “Deformable siamese attention networks for visual object tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6728–6737
2020
-
[9]
Probabilistic regression for visual tracking,
M. Danelljan, L. V . Gool, and R. Timofte, “Probabilistic regression for visual tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7183–7192
2020
-
[10]
Unified Pose Sequence Modeling,
L. G. Foo, T. Li, H. Rahmani, Q. Ke, and J. Liu, “Unified Pose Sequence Modeling,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, BC, Canada: IEEE, Jun. 2023, pp. 13 019–13 030
2023
-
[11]
Learning to track objects from unlabeled videos,
J. Zheng, C. Ma, H. Peng, and X. Yang, “Learning to track objects from unlabeled videos,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 13 546–13 555
2021
-
[12]
Unsupervised deep tracking,
N. Wang, Y . Song, C. Ma, W. Zhou, W. Liu, and H. Li, “Unsupervised deep tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 1308–1317
2019
-
[13]
Unsupervised learning of accurate siamese tracking,
Q. Shen, L. Qiao, J. Guo, P. Li, X. Li, B. Li, W. Feng, W. Gan, W. Wu, and W. Ouyang, “Unsupervised learning of accurate siamese tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8101–8110
2022
-
[14]
Unsuper- vised deep representation learning for real-time tracking,
N. Wang, W. Zhou, Y . Song, C. Ma, W. Liu, and H. Li, “Unsuper- vised deep representation learning for real-time tracking,”International Journal of Computer Vision, vol. 129, pp. 400–418, 2021
2021
-
[15]
S2siamfc: Self-supervised fully convolutional siamese network for vi- sual tracking,
C. H. Sio, Y .-J. Ma, H.-H. Shuai, J.-C. Chen, and W.-H. Cheng, “S2siamfc: Self-supervised fully convolutional siamese network for vi- sual tracking,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 1948–1957
2020
-
[16]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[17]
Text2video-zero: Text-to-image dif- fusion models are zero-shot video generators,
L. Khachatryan, A. Movsisyan, V . Tadevosyan, R. Henschel, Z. Wang, S. Navasardyan, and H. Shi, “Text2video-zero: Text-to-image dif- fusion models are zero-shot video generators,”arXiv preprint arXiv:2303.13439, 2023
-
[18]
Create your world: Lifelong text-to-image diffusion,
G. Sun, W. Liang, J. Dong, J. Li, Z. Ding, and Y . Cong, “Create your world: Lifelong text-to-image diffusion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 9, pp. 6454–6470, 2024
2024
-
[19]
Harnessing text-to-image diffusion models for category-agnostic pose estimation,
D. Peng, Z. Zhang, P. Hu, Q. Ke, D. Yau, and J. Liu, “Harnessing text-to-image diffusion models for category-agnostic pose estimation,” inEuropean Conference on Computer Vision. Springer, 2024
2024
-
[20]
Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision,
L. Qin, J. Gong, Y . Sun, T. Li, M. Yang, X. Yang, C. Qu, Z. Tan, and H. Li, “Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision,” https://arxiv.org/abs/2508.05606v2, Aug. 2025
-
[21]
Emergent cor- respondence from image diffusion,
L. Tang, M. Jia, Q. Wang, C. P. Phoo, and B. Hariharan, “Emergent cor- respondence from image diffusion,”arXiv preprint arXiv:2306.03881, 2023
-
[22]
A. Khani, S. A. Taghanaki, A. Sanghi, A. M. Amiri, and G. Hamarneh, “Slime: Segment like me,”arXiv preprint arXiv:2309.03179, 2023. 17
-
[23]
A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence,
J. Zhang, C. Herrmann, J. Hur, L. Polania Cabrera, V . Jampani, D. Sun, and M.-H. Yang, “A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence,”Advances in Neural Infor- mation Processing Systems, vol. 36, pp. 45 533–45 547, 2023
2023
-
[24]
Weighted part context learning for visual tracking,
G. Zhu, J. Wang, C. Zhao, and H. Lu, “Weighted part context learning for visual tracking,”IEEE Transactions on Image Processing, vol. 24, no. 12, pp. 5140–5151, 2015
2015
-
[25]
Spatial-sequential-spectral context awareness tracking,
J. Fang, Z. Li, and J. Xue, “Spatial-sequential-spectral context awareness tracking,” in2017 IEEE International Conference on Image Processing. IEEE, 2017, pp. 2582–2586
2017
-
[26]
On the connections between saliency and tracking,
V . Mahadevan and N. Vasconcelos, “On the connections between saliency and tracking,”Advances in Neural Information Processing Systems, vol. 25, 2012
2012
-
[27]
Salient object detection: a mini review,
X. Wang, S. Yu, E. G. Lim, and M. D. Wong, “Salient object detection: a mini review,”Frontiers in Signal Processing, vol. 4, p. 1356793, 2024
2024
-
[28]
Implicit motion handling for video camouflaged object detection,
X. Cheng, H. Xiong, D.-P. Fan, Y . Zhong, M. Harandi, T. Drummond, and Z. Ge, “Implicit motion handling for video camouflaged object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 864–13 873
2022
-
[29]
Robust object tracking using joint color-texture histogram,
J. Ning, L. Zhang, D. Zhang, and C. Wu, “Robust object tracking using joint color-texture histogram,”International Journal of Pattern Recognition and Artificial Intelligence, vol. 23, no. 07, pp. 1245–1263, 2009
2009
-
[30]
Chase: Robust visual tracking via cell-level differentiable neural architecture search,
S. M. Marvasti-Zadeh, J. Khaghani, L. Cheng, H. Ghanei-Yakhdan, and S. Kasaei, “Chase: Robust visual tracking via cell-level differentiable neural architecture search,”arXiv preprint arXiv:2107.03463, 2021
-
[31]
K. Hu, Q. Zhang, M. Yuan, and Y . Zhang, “Sfdfusion: an efficient spatial-frequency domain fusion network for infrared and visible image fusion,”arXiv preprint arXiv:2410.22837, 2024
-
[32]
Object tracking benchmark,
Y . Wu, J. Lim, and M.-H. Yang, “Object tracking benchmark,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 9, pp. 1834–1848, 2015
2015
-
[33]
Lasot: A high-quality benchmark for large-scale single object tracking,
H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, H. Bai, Y . Xu, C. Liao, and H. Ling, “Lasot: A high-quality benchmark for large-scale single object tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5374–5383
2019
-
[34]
Diff-tracker: text-to-image diffusion models are unsupervised trackers,
Z. Zhang, L. Xu, D. Peng, H. Rahmani, and J. Liu, “Diff-tracker: text-to-image diffusion models are unsupervised trackers,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 319–337
2024
-
[35]
The eighth visual object tracking vot2020 challenge results,
M. Kristan, A. Leonardis, J. Matas, M. Felsberg, R. Pflugfelder, J.- K. K ¨am¨ar¨ainen, M. Danelljan, L. ˇC. Zajc, A. Luke ˇziˇc, O. Drbohlav et al., “The eighth visual object tracking vot2020 challenge results,” in European conference on computer vision. Springer, 2020, pp. 547–601
2020
-
[36]
Distilled siamese networks for visual tracking,
J. Shen, Y . Liu, X. Dong, X. Lu, F. S. Khan, and S. Hoi, “Distilled siamese networks for visual tracking,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 8896–8909, 2021
2021
-
[37]
Nus-pro: A new visual tracking challenge,
A. Li, M. Lin, Y . Wu, M.-H. Yang, and S. Yan, “Nus-pro: A new visual tracking challenge,”IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 2, pp. 335–349, 2015
2015
-
[38]
UA V-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles,
T. Li, J. Liu, W. Zhang, Y . Ni, W. Wang, and Z. Li, “UA V-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, Jun. 2021, pp. 16 261–16 270
2021
-
[39]
Eco: Efficient convolution operators for tracking,
M. Danelljan, G. Bhat, F. Shahbaz Khan, and M. Felsberg, “Eco: Efficient convolution operators for tracking,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6638– 6646
2017
-
[40]
Atom: Accurate tracking by overlap maximization,
M. Danelljan, G. Bhat, F. S. Khan, and M. Felsberg, “Atom: Accurate tracking by overlap maximization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4660– 4669
2019
-
[42]
Siamrpn++: Evolution of siamese visual tracking with very deep networks,
B. Li, W. Wu, Q. Wang, F. Zhang, J. Xing, and J. Yan, “Siamrpn++: Evolution of siamese visual tracking with very deep networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4282–4291
2019
-
[43]
Siammask: A framework for fast online object tracking and segmentation,
W. Hu, Q. Wang, L. Zhang, L. Bertinetto, and P. H. Torr, “Siammask: A framework for fast online object tracking and segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3072–3089, 2023
2023
-
[44]
Fully-convolutional siamese networks for object tracking,
L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, and P. H. Torr, “Fully-convolutional siamese networks for object tracking,” inComputer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part II 14. Springer, 2016, pp. 850–865
2016
-
[45]
Learning to fuse asymmetric feature maps in siamese trackers,
W. Han, X. Dong, F. S. Khan, L. Shao, and J. Shen, “Learning to fuse asymmetric feature maps in siamese trackers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 570–16 580
2021
-
[46]
Efficient neural architecture search via parameters sharing,
H. Pham, M. Guan, B. Zoph, Q. Le, and J. Dean, “Efficient neural architecture search via parameters sharing,” inInternational conference on machine learning. PMLR, 2018, pp. 4095–4104
2018
-
[47]
Lighttrack: Finding lightweight neural networks for object tracking via one-shot architecture search,
B. Yan, H. Peng, K. Wu, D. Wang, J. Fu, and H. Lu, “Lighttrack: Finding lightweight neural networks for object tracking via one-shot architecture search,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15 180–15 189
2021
-
[48]
Visual object tracking with discriminative filters and siamese networks: a survey and outlook,
S. Javed, M. Danelljan, F. S. Khan, M. H. Khan, M. Felsberg, and J. Matas, “Visual object tracking with discriminative filters and siamese networks: a survey and outlook,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 5, pp. 6552–6574, 2022
2022
-
[49]
Learning support correlation filters for visual tracking,
W. Zuo, X. Wu, L. Lin, L. Zhang, and M.-H. Yang, “Learning support correlation filters for visual tracking,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 5, pp. 1158–1172, 2018
2018
-
[50]
Progressive unsupervised learning for visual object tracking,
Q. Wu, J. Wan, and A. B. Chan, “Progressive unsupervised learning for visual object tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2993–3002
2021
-
[51]
Learning correspondence from the cycle-consistency of time,
X. Wang, A. Jabri, and A. A. Efros, “Learning correspondence from the cycle-consistency of time,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2566–2576
2019
-
[52]
Learning video representations from correspondence proposals,
X. Liu, J.-Y . Lee, and H. Jin, “Learning video representations from correspondence proposals,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4273–4281
2019
-
[53]
System-status-aware adaptive network for online streaming video understanding,
L. G. Foo, J. Gong, Z. Fan, and J. Liu, “System-status-aware adaptive network for online streaming video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10 514–10 523
2023
-
[54]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,”Advances in Neural Information Processing Systems, vol. 35, pp. 36 479–36 494, 2022
2022
-
[55]
Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis,
J. Chen, J. Yu, C. Ge, L. Yao, E. Xie, Y . Wu, Z. Wang, J. Kwok, P. Luo, H. Lu, and Z. Li, “Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis,” 2023
2023
-
[56]
Action detection via an image diffusion process,
L. G. Foo, T. Li, H. Rahmani, and J. Liu, “Action detection via an image diffusion process,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 351–18 361
2024
-
[57]
Frequency-enhanced diffusion models: Curriculum-guided semantic alignment for zero-shot skeleton action recognition,
Y . Zhou, Z. Zhang, J. Pan, Z. Lin, and Z. Tu, “Frequency-enhanced diffusion models: Curriculum-guided semantic alignment for zero-shot skeleton action recognition,”The Visual Computer, 2026
2026
-
[58]
Imagic: Text-based real image editing with diffusion models,
B. Kawar, S. Zada, O. Lang, O. Tov, H. Chang, T. Dekel, I. Mosseri, and M. Irani, “Imagic: Text-based real image editing with diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6007–6017
2023
-
[59]
Visual prompting for one-shot controllable video editing without inversion,
Z. Zhang, Y . Zhou, D. Peng, J.-H. Lim, Z. Tu, D. W. Soh, and L. G. Foo, “Visual prompting for one-shot controllable video editing without inversion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 7784–7794
2025
-
[60]
Prompt-to-prompt image editing with cross-attention con- trol,
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or, “Prompt-to-prompt image editing with cross-attention con- trol,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[61]
Attend-and- excite: Attention-based semantic guidance for text-to-image diffusion models,
H. Chefer, Y . Alaluf, Y . Vinker, L. Wolf, and D. Cohen-Or, “Attend-and- excite: Attention-based semantic guidance for text-to-image diffusion models,” inACM SIGGRAPH 2023 Conference Proceedings, 2023, pp. 1–11
2023
-
[62]
What the DAAM: Interpreting stable diffusion using cross attention,
R. Tang, L. Liu, A. Pandey, Z. Jiang, G. Yang, K. Kumar, P. Stenetorp, J. Lin, and F. Ture, “What the DAAM: Interpreting stable diffusion using cross attention,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023, pp. 5644–5659
2023
-
[63]
Plug-and-play diffusion features for text-driven image-to-image translation,
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel, “Plug-and-play diffusion features for text-driven image-to-image translation,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1921–1930
2023
-
[64]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241. 18
2015
-
[65]
Learning by analogy: Reliable supervision from trans- formations for unsupervised optical flow estimation,
L. Liu, J. Zhang, R. He, Y . Liu, Y . Wang, Y . Tai, D. Luo, C. Wang, J. Li, and F. Huang, “Learning by analogy: Reliable supervision from trans- formations for unsupervised optical flow estimation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6489–6498
2020
-
[66]
High-quality restoration image encryption using dct frequency-domain compression coding and chaos,
H. Wen, L. Ma, L. Liu, Y . Huang, Z. Chen, R. Li, Z. Liu, W. Lin, J. Wu, Y . Liet al., “High-quality restoration image encryption using dct frequency-domain compression coding and chaos,”Scientific Reports, vol. 12, no. 1, p. 16523, 2022
2022
-
[67]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[68]
Track- ingnet: A large-scale dataset and benchmark for object tracking in the wild,
M. Muller, A. Bibi, S. Giancola, S. Alsubaihi, and B. Ghanem, “Track- ingnet: A large-scale dataset and benchmark for object tracking in the wild,” inProceedings of the European conference on computer vision, 2018, pp. 300–317
2018
-
[69]
The vi- sual object tracking VOT2017 challenge results,
M. Kristan, A. Leonardis, J. Matas, M. Felsberg, R. Pflugfelder, L. Ce- hovin Zajc, T. V ojir, G. Hager, A. Lukezic, A. Eldesokeyet al., “The vi- sual object tracking VOT2017 challenge results,” inIEEE International Conference on Computer Vision Workshops, 2017, pp. 1949–1972
2017
-
[70]
The sixth visual object tracking vot2018 challenge results,
M. Kristan, A. Leonardis, J. Matas, M. Felsberg, R. Pflugfelder, L.ˇCehovin Zajc, T. V ojir, G. Bhat, A. Lukezic, A. Eldesokeyet al., “The sixth visual object tracking vot2018 challenge results,” inProceed- ings of the European conference on computer vision workshops, 2018
2018
-
[71]
Distractor-aware siamese networks for visual object tracking,
Z. Zhu, Q. Wang, B. Li, W. Wu, J. Yan, and W. Hu, “Distractor-aware siamese networks for visual object tracking,” inProceedings of the European conference on computer vision, 2018, pp. 101–117
2018
-
[72]
Learning discrim- inative model prediction for tracking,
G. Bhat, M. Danelljan, L. V . Gool, and R. Timofte, “Learning discrim- inative model prediction for tracking,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6182–6191
2019
-
[73]
High-speed track- ing with kernelized correlation filters,
J. F. Henriques, R. Caseiro, P. Martins, and J. Batista, “High-speed track- ing with kernelized correlation filters,”IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 3, pp. 583–596, 2014
2014
-
[74]
Robust unsupervised visual tracking via image-to-video identity knowledge transferring,
B. Kang, Z. Wang, D. Liang, T. Ding, and S. Du, “Robust unsupervised visual tracking via image-to-video identity knowledge transferring,” Pattern Recognition, p. 112109, 2025
2025
-
[75]
Got-10k: A large high-diversity benchmark for generic object tracking in the wild,
L. Huang, X. Zhao, and K. Huang, “Got-10k: A large high-diversity benchmark for generic object tracking in the wild,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 5, pp. 1562– 1577, 2019
2019
-
[76]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International journal of computer vision, vol. 115, pp. 211–252, 2015
2015
-
[77]
Youtube-vos: Sequence-to-sequence video object segmentation,
N. Xu, L. Yang, Y . Fan, J. Yang, D. Yue, Y . Liang, B. Price, S. Co- hen, and T. Huang, “Youtube-vos: Sequence-to-sequence video object segmentation,” inProceedings of the European conference on computer vision, 2018, pp. 585–601
2018
-
[78]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inIEEE conference on computer vision and pattern recognition, 2009, pp. 248–255
2009
-
[79]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[80]
Robust visual tracking by segmentation,
M. Paul, M. Danelljan, C. Mayer, and L. Van Gool, “Robust visual tracking by segmentation,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 571–588
2022
-
[81]
Joint feature learning and relation modeling for tracking: A one-stream framework,
B. Ye, H. Chang, B. Ma, S. Shan, and X. Chen, “Joint feature learning and relation modeling for tracking: A one-stream framework,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 341– 357
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.