DunbaaBERT: From Sacrifice to Semantics
Pith reviewed 2026-06-29 18:04 UTC · model grok-4.3
The pith
Urdu RoBERTa models trained from scratch on a 17GB corpus match multilingual baselines with better efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
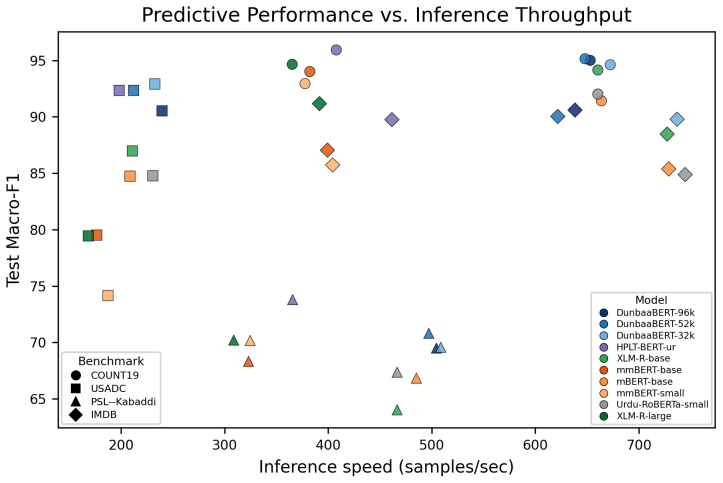
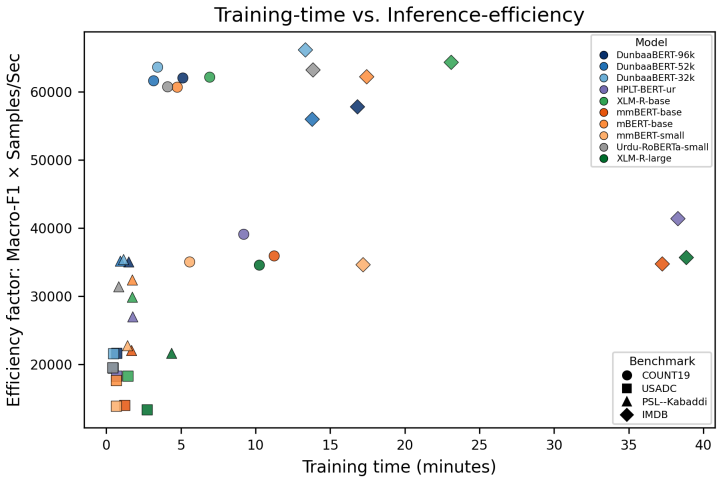
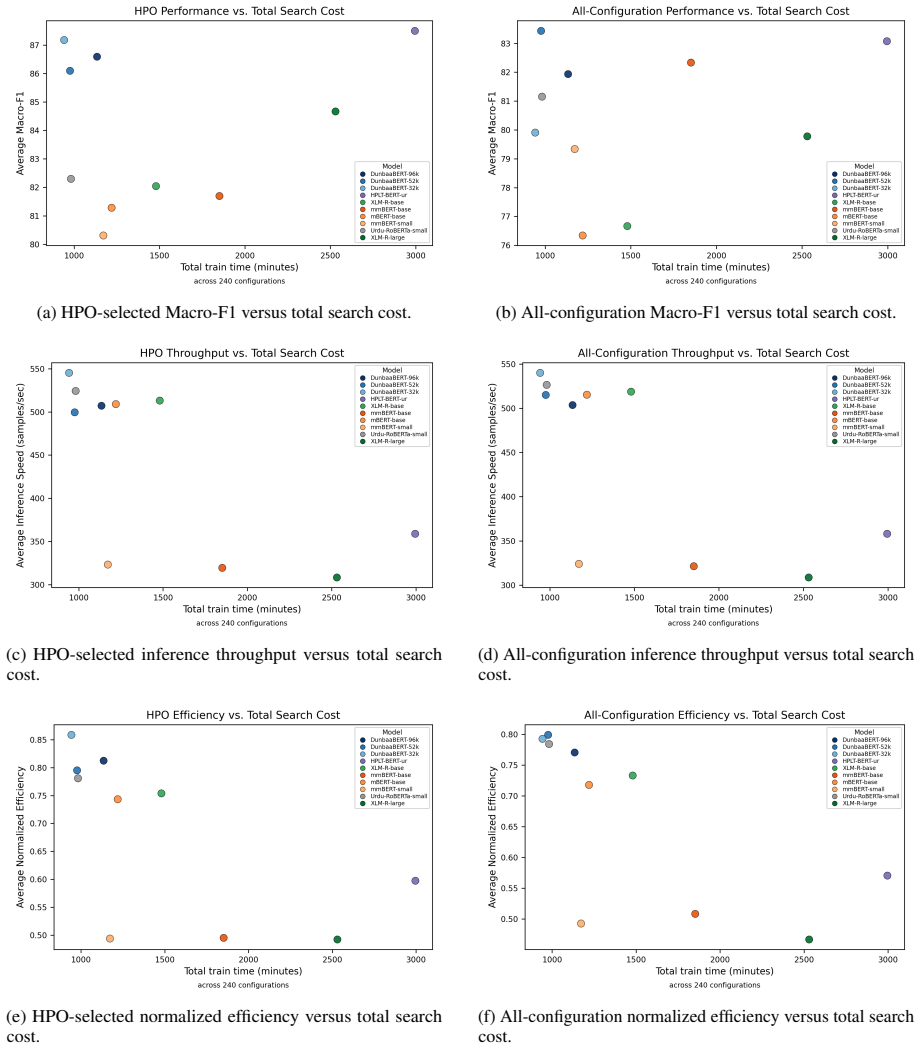
DunbaaBERT models trained from scratch on the 17GB deduplicated Urdu corpus achieve competitive results against multilingual baselines across intrinsic and downstream Urdu benchmarks while maintaining favorable efficiency trade-offs, with the 32k-vocabulary variant repeatedly showing the best overall profile.
What carries the argument
RoBERTa-base encoders pretrained from scratch on a deduplicated 17GB Urdu corpus using Byte-BPE vocabularies of varying sizes.
If this is right
- Language-specific pretraining at compact scale can serve as a practical alternative to multilingual models for Urdu NLP applications.
- Larger token vocabularies do not guarantee better downstream performance and can increase computational cost.
- Releasing the models under an open license supports further development of Urdu-specific tools and datasets.
- Efficiency advantages of the smaller-vocabulary variant enable deployment in lower-resource environments.
Where Pith is reading between the lines
- The same curation and training approach could be tested on other languages with similarly sized corpora to check whether the competitiveness pattern holds.
- If the efficiency edge persists, it may reduce the need for full-scale multilingual pretraining when building task-specific systems for a single language.
- The non-monotonic vocabulary effect suggests that tokenizer design choices deserve systematic study rather than defaulting to larger sizes.
Load-bearing premise
The chosen 17GB Urdu corpus and the selected downstream benchmarks are representative enough to show that language-specific training competes with multilingual baselines.
What would settle it
A broader or more diverse Urdu evaluation set where the multilingual baselines significantly outperform all DunbaaBERT variants on multiple tasks would falsify the competitiveness claim.
Figures
read the original abstract
Large language models have achieved strong performance across many NLP tasks, yet Urdu remains comparatively underexplored due to limited resources and fragmented evaluation settings. To address this gap, we introduce DunbaaBERT, a family of Urdu RoBERTa-base models trained from scratch with Byte-BPE vocabularies of 32k, 52k, and 96k tokens on a deduplicated 17GB Urdu corpus. We evaluate DunbaaBERT across intrinsic and downstream Urdu NLP benchmarks covering linguistic acceptability, news classification, offensive language detection, and sentiment analysis while analyzing vocabulary-size effects on performance and efficiency trade-offs. Across benchmarks, the DunbaaBERT variants achieve competitive performance against strong multilingual baselines while consistently maintaining favorable efficiency trade-offs. Interestingly, larger vocabularies do not consistently improve downstream effectiveness, with DunbaaBERT$_{\text{32k}}$ repeatedly providing the strongest overall efficiency profile. Overall, our results demonstrate that carefully curated Urdu-specific encoder models can remain highly competitive despite comparatively compact model and training scales. All models are released under the MIT license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DunbaaBERT, a family of Urdu RoBERTa-base models trained from scratch on a deduplicated 17GB Urdu corpus using Byte-BPE vocabularies of sizes 32k, 52k, and 96k. It reports evaluations on intrinsic and downstream Urdu NLP tasks covering linguistic acceptability, news classification, offensive language detection, and sentiment analysis, along with vocabulary-size ablations. The central claim is that these compact, language-specific models achieve competitive performance against multilingual baselines while offering favorable efficiency trade-offs, with the 32k variant often strongest; all models are released under MIT license.
Significance. If the empirical results hold with proper documentation, this would provide evidence that carefully curated language-specific pretraining on modest scales (17GB corpus, RoBERTa-base) can compete with multilingual models for Urdu, with practical implications for efficiency in low-resource settings. The public release of the models under MIT is a clear strength that enables reproducibility and follow-on work. The vocabulary-size analysis could inform tokenizer design choices, though its generalizability depends on the breadth of the reported benchmarks.
major comments (2)
- [Abstract] Abstract: The claim that 'DunbaaBERT variants achieve competitive performance against strong multilingual baselines' is stated without any accompanying metrics, tables, error bars, statistical tests, or baseline details. This is load-bearing for the central empirical claim and prevents verification of competitiveness or efficiency trade-offs from the provided text.
- [Corpus description] Corpus section (referenced in abstract as 'deduplicated 17GB Urdu corpus'): No domain breakdown, dialect coverage, or deduplication procedure is described. This directly affects the representativeness assumption required for the claim that language-specific training on this corpus yields general competitiveness.
minor comments (1)
- [Abstract] The notation 'DunbaaBERT$_{\text{32k}}$' is used without prior definition of the subscript convention in the abstract.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'DunbaaBERT variants achieve competitive performance against strong multilingual baselines' is stated without any accompanying metrics, tables, error bars, statistical tests, or baseline details. This is load-bearing for the central empirical claim and prevents verification of competitiveness or efficiency trade-offs from the provided text.
Authors: We agree that the abstract would be more informative if it included key quantitative results. The body of the manuscript contains full tables with performance metrics, baseline comparisons (including XLM-R and mBERT), and efficiency measurements across tasks. We will revise the abstract to incorporate representative numbers (e.g., average scores on acceptability, classification, and sentiment tasks) and a brief reference to the main baselines, while preserving the word limit. revision: yes
-
Referee: [Corpus description] Corpus section (referenced in abstract as 'deduplicated 17GB Urdu corpus'): No domain breakdown, dialect coverage, or deduplication procedure is described. This directly affects the representativeness assumption required for the claim that language-specific training on this corpus yields general competitiveness.
Authors: The referee correctly identifies that the current corpus description is insufficiently detailed. We will expand the relevant section to provide a domain breakdown of the source data, notes on dialect coverage (primarily formal Urdu with limited regional variants), and the exact deduplication method applied (combination of exact matching and MinHash-based near-duplicate removal). These additions will directly support the representativeness claim. revision: yes
Circularity Check
No circularity; empirical training and benchmark comparison is self-contained
full rationale
The paper trains RoBERTa-base models from scratch on a fixed 17GB Urdu corpus using Byte-BPE vocabularies and reports direct performance numbers on four downstream tasks plus intrinsic metrics. No equations, fitted parameters, or predictions are defined in terms of the target quantities; the central claim of competitiveness is an empirical observation against external multilingual baselines rather than a reduction to self-defined inputs or self-citations. No load-bearing self-citation chains, uniqueness theorems, or ansatzes appear in the provided text. The result therefore stands or falls on the representativeness of the corpus and breadth of the benchmarks, which is a validity question rather than circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer. Preprint, arXiv:2004.05150. Muhammad Bilal, Atif Khan, Salman Jan, Shahrulniza Musa, and Shaukat Ali. 2023. Roman urdu hate speech detection using transformer-based model for cyber security applications.Sensors, 23(8):3909. Damian Blasi, Antonios Anastasopoulos, and Gra- ham Neubig. 2021. Systematic inequalities ...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
EuroBERT: Scaling Multilingual Encoders for European Languages
Eurobert: Scaling multilingual encoders for european languages.Preprint, arXiv:2503.05500. Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2016. Enriching word vec- tors with subword information.arXiv preprint arXiv:1607.04606. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, ...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Enhancing Urdu sentiment classification through instruction-tuned LLMs and cross-lingual transfer. InProceedings of the 2nd Workshop on NLP for Languages Using Arabic Script, pages 198– 207, Rabat, Morocco. Association for Computational Linguistics. Lal Khan, Ammar Amjad, Noman Ashraf, and Hsien- Tsung Chang. 2022. Multi-class sentiment analysis of urdu t...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Language Resources and Evaluation, pages 1–26
Roman urdu toxic comment classification. Language Resources and Evaluation, pages 1–26. David Samuel, Andrey Kutuzov, Lilja Øvrelid, and Erik Velldal. 2023. Trained on 100 million words and still in shape: BERT meets British National Corpus. In Findings of the Association for Computational Lin- guistics: EACL 2023, pages 1954–1974, Dubrovnik, Croatia. Ass...
-
[5]
Script identification of multi-script documents: a survey.IEEE access, 5:6546–6559. Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. 2024. Smarter, better, faster, longer: A modern bidir...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Read more
From courtroom to corpora: Building a name entity corpus for Urdu legal texts. InProceed- ings of the 15th International Conference on Recent Advances in Natural Language Processing - Natu- ral Language Processing in the Generative AI Era, pages 1396–1405, Varna, Bulgaria. INCOMA Ltd., Shoumen, Bulgaria. A Pre-training Dynamics During pre-training, perple...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.