DinoComplete: 3D Shape Completion with Distilled Semantic Priors and State Space Models
Pith reviewed 2026-06-29 17:46 UTC · model grok-4.3
The pith
Distilling DINO semantic features into a voxel Mamba network improves 3D shape completion from partial scans of unseen categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
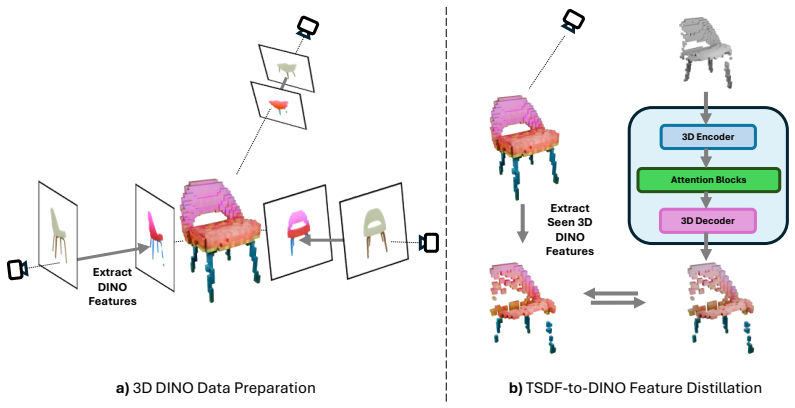
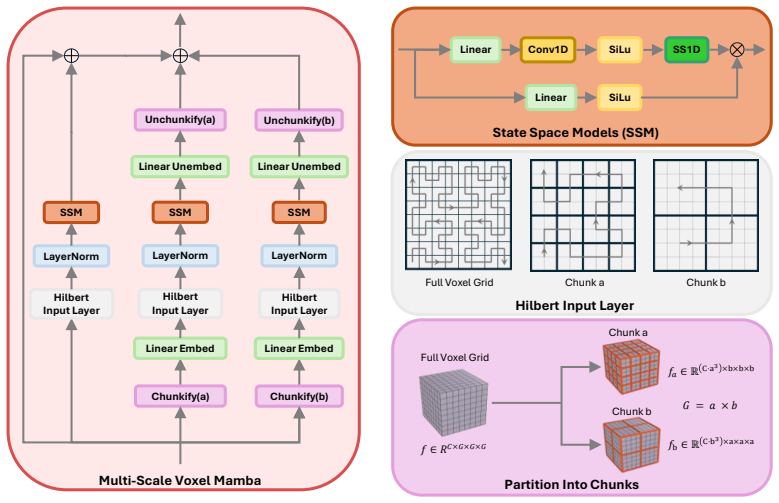
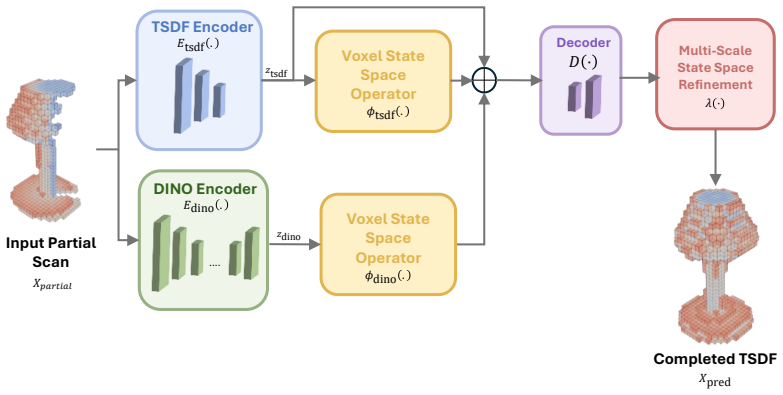
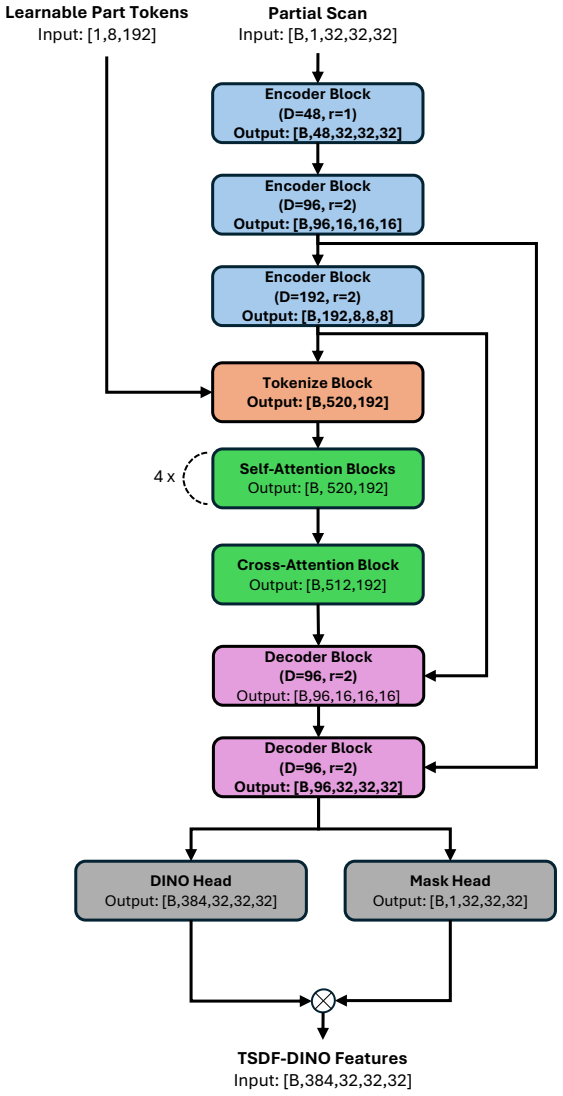
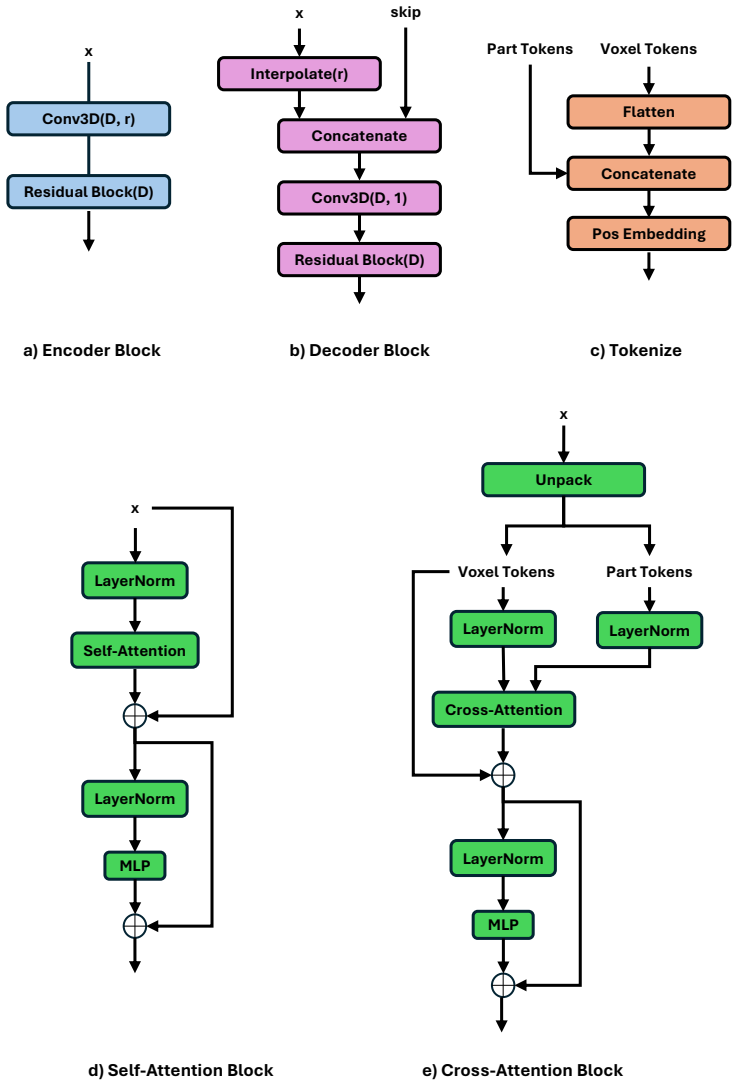
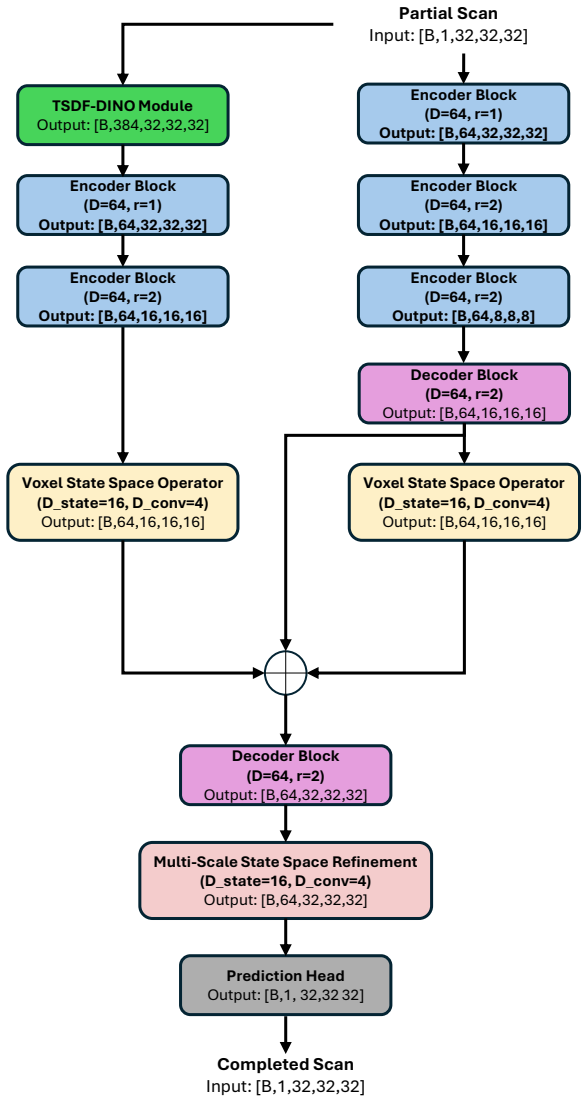
DinoComplete augments geometric reconstruction with voxel-aligned semantic priors distilled from DINO features. A student network predicts dense semantic features directly from incomplete shapes; these are fused with geometric representations through voxel state-space modeling. A multi-scale voxel Mamba module refines the fused features by combining full-grid and chunk-wise sequence modeling, enabling better generalization and efficiency without sacrificing resolution.
What carries the argument
The multi-scale voxel Mamba module, which fuses geometric and distilled semantic voxel features and refines them via combined full-grid and chunk-wise sequence modeling for long-range reasoning.
If this is right
- Stronger completion quality than prior deterministic and generative methods on unseen ShapeNet categories and ScanNet objects.
- Lower parameter count, reduced memory footprint, and faster inference times.
- Improved robustness when inputs are noisy real-world observations.
Where Pith is reading between the lines
- The same distillation step could be tested on other 3D tasks such as surface reconstruction or part segmentation to check transfer of the semantic priors.
- Ablation studies that remove the semantic branch on progressively more distant categories would quantify how much the DINO features drive the reported gains.
- The efficiency numbers suggest the method could run on-device for robotics or AR pipelines, though real-time latency on embedded hardware remains untested in the paper.
Load-bearing premise
DINO features extracted from complete multi-view ShapeNet data remain predictive and semantically useful when the input is a partial or noisy scan of an unseen category.
What would settle it
Evaluating DinoComplete on a fresh collection of unseen object categories with partial scans and finding that its completion metrics such as IoU or Chamfer distance no longer exceed those of prior methods would falsify the performance advantage.
Figures





read the original abstract
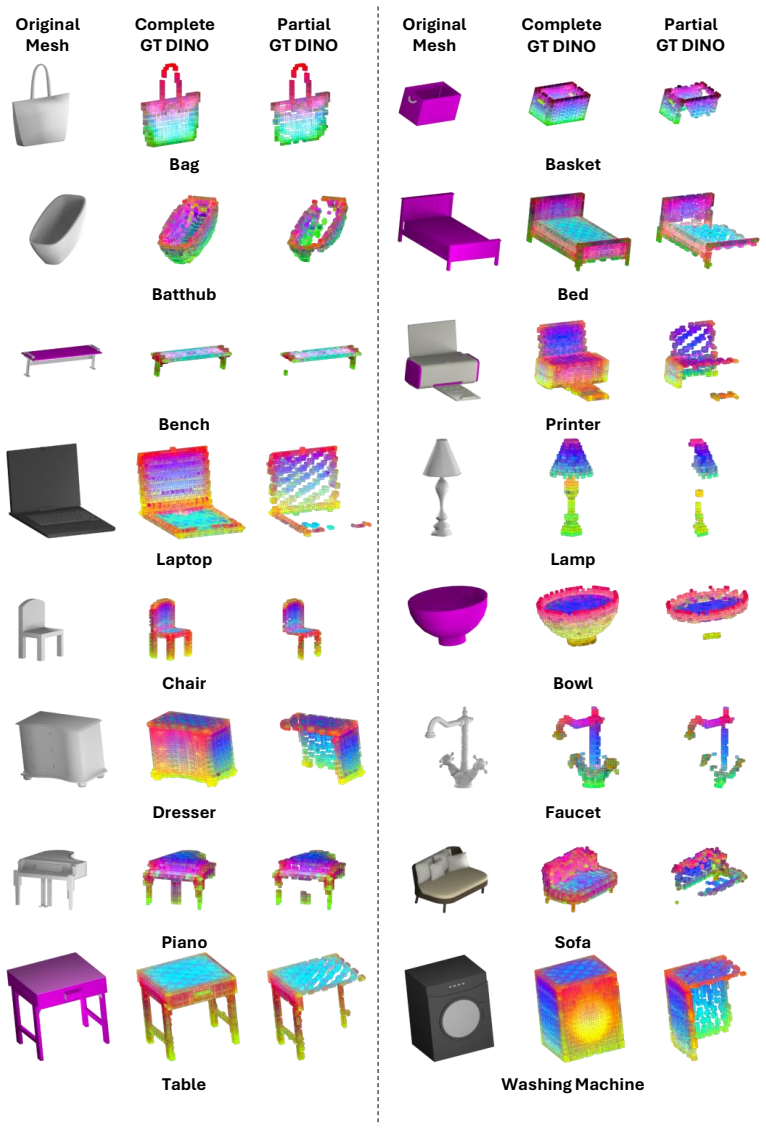
3D shape completion from partial scans remains challenging for unseen categories and noisy real-world observations, where geometry alone is often insufficient for inferring missing structure. We present DinoComplete, a deterministic and efficient shape completion framework that augments geometric reconstruction with voxel-aligned semantic priors distilled from DINO features. First, we construct multi-view DINO feature volumes aligned with ShapeNet data and train a student network to predict dense semantic features directly from incomplete shapes. These predicted features capture global structure and part-aware semantic context while remaining aligned with the underlying geometry. We then integrate these distilled features into a completion network, where geometric and semantic voxel representations are fused through voxel state-space modeling. To enable efficient long-range reasoning without sacrificing resolution, we introduce a multi-scale voxel Mamba module that refines the fused features by combining full-grid and chunk-wise sequence modeling. Experiments on unseen ShapeNet categories and ScanNet objects show that DinoComplete achieves stronger completion quality than prior deterministic and generative based completion methods while using fewer parameters, requiring lower memory, and achieving faster inference. Our results demonstrate that distilling semantic priors from visual foundation models improves generalization and robustness in 3D shape completion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DinoComplete, a deterministic 3D shape completion method that first constructs multi-view DINO feature volumes from complete ShapeNet data, trains a student network to regress these features from partial inputs, and then fuses the predicted semantic features with geometry inside a multi-scale voxel Mamba module for long-range reasoning. Experiments are reported to show improved completion quality over prior deterministic and generative baselines on unseen ShapeNet categories and ScanNet objects, together with lower parameter count, memory usage, and faster inference.
Significance. If the transfer of distilled DINO features to partial unseen inputs holds, the work would demonstrate a practical way to inject semantic context from 2D foundation models into efficient 3D completion pipelines, potentially reducing reliance on generative models while preserving resolution through state-space modeling. The efficiency claims (fewer parameters, lower memory, faster inference) would be a notable practical contribution if substantiated.
major comments (2)
- [Experiments section (unseen-category results)] The headline claim that distilled semantic priors improve generalization on unseen categories rests on the student network producing informative DINO features from partial inputs outside the training distribution. The manuscript should include an explicit ablation (e.g., in the experiments section) that isolates the semantic branch on the unseen ShapeNet and ScanNet test sets; without it, gains could be attributable solely to the voxel Mamba architecture.
- [§3 (method) and corresponding ablation table] The description of the multi-scale voxel Mamba states that geometric and semantic voxel representations are fused before refinement, yet no quantitative measure is provided of how much the semantic features actually contribute versus the Mamba layers alone on out-of-distribution data. A controlled comparison removing the semantic input on the same unseen splits would directly test the central hypothesis.
minor comments (2)
- [§3.2] Notation for the student network output and the voxel feature fusion step could be made more explicit to avoid ambiguity between the predicted DINO volume and the geometric occupancy grid.
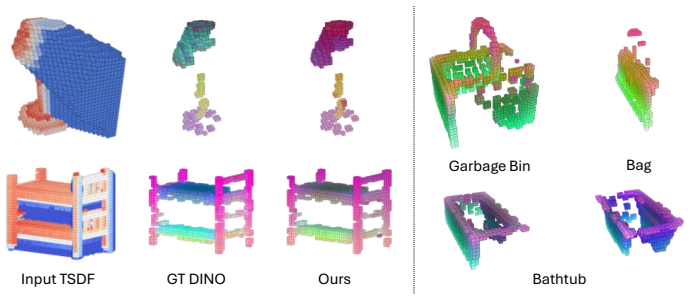
- [Figure 4] Figure captions for the qualitative results on ScanNet should indicate whether the shown completions are from the full model or an ablated variant.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the recommendation for major revision. The two major comments both correctly identify the absence of an explicit ablation that isolates the contribution of the distilled semantic features on unseen categories. We agree this controlled comparison is necessary to substantiate the central hypothesis and will add the requested experiments in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments section (unseen-category results)] The headline claim that distilled semantic priors improve generalization on unseen categories rests on the student network producing informative DINO features from partial inputs outside the training distribution. The manuscript should include an explicit ablation (e.g., in the experiments section) that isolates the semantic branch on the unseen ShapeNet and ScanNet test sets; without it, gains could be attributable solely to the voxel Mamba architecture.
Authors: We agree that the current experimental section does not contain a direct ablation removing the semantic branch on the unseen splits. In the revision we will add this comparison: the full DinoComplete model versus an otherwise identical variant that receives only the geometric voxel input (i.e., the semantic student network and its features are disabled). Results will be reported on the same unseen ShapeNet categories and ScanNet objects using the same metrics, thereby isolating the contribution of the distilled DINO priors from the multi-scale voxel Mamba architecture. revision: yes
-
Referee: [§3 (method) and corresponding ablation table] The description of the multi-scale voxel Mamba states that geometric and semantic voxel representations are fused before refinement, yet no quantitative measure is provided of how much the semantic features actually contribute versus the Mamba layers alone on out-of-distribution data. A controlled comparison removing the semantic input on the same unseen splits would directly test the central hypothesis.
Authors: The referee is correct that no such controlled removal of the semantic input is currently quantified on out-of-distribution data. We will introduce the requested ablation table (or subsection) that reports performance of the geometric-only Mamba variant against the fused model on the identical unseen test sets. This will provide a direct quantitative measure of the semantic features' contribution under the exact conditions highlighted in the paper's claims. revision: yes
Circularity Check
No circularity: derivation chain is self-contained and externally falsifiable
full rationale
The paper describes a pipeline that extracts DINO features from complete multi-view ShapeNet data, trains a student network to regress those features from partial inputs, and fuses the result with geometry inside a voxel Mamba module. None of these steps reduce to a self-definition, a fitted parameter renamed as a prediction, or a load-bearing self-citation. The central claim (superior completion on unseen categories) is presented as an empirical outcome measured against external benchmarks (ShapeNet unseen splits and ScanNet), not derived by algebraic identity from the inputs. No equations are shown that equate the output to the training targets by construction, and no uniqueness theorem or ansatz is imported from prior work by the same authors. The method therefore remains open to falsification by independent evaluation on the reported test sets.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption DINO features extracted from complete multi-view renders remain semantically meaningful when predicted from incomplete geometry.
- domain assumption Voxel-aligned semantic and geometric features can be fused effectively by state-space sequence modeling.
Reference graph
Works this paper leans on
-
[1]
Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
Hervé Abdi and Lynne J Williams. Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
2010
-
[2]
Scan2cad: Learning cad model alignment in rgb-d scans
Armen Avetisyan, Manuel Dahnert, Angela Dai, Manolis Savva, Angel X Chang, and Matthias Nießner. Scan2cad: Learning cad model alignment in rgb-d scans. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 2614–2623, 2019
2019
-
[3]
Dino-vo: A feature-based visual odometry leveraging a visual foundation model.IEEE Robotics and Automation Letters, 2025
Maulana Bisyir Azhari and David Hyunchul Shim. Dino-vo: A feature-based visual odometry leveraging a visual foundation model.IEEE Robotics and Automation Letters, 2025
2025
-
[4]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[6]
Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang
Angel X. Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. In3DV, 2017
2017
-
[7]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
A simple frame- work for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple frame- work for contrastive learning of visual representations. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1597–1607. PMLR, 13–18 Jul 2020
2020
-
[9]
Implicit functions in feature space for 3d shape reconstruction and completion
Julian Chibane, Thiemo Alldieck, and Gerard Pons-Moll. Implicit functions in feature space for 3d shape reconstruction and completion. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, jun 2020
2020
-
[10]
Diffcomplete: Diffusion-based generative 3d shape completion
Ruihang Chu, Enze Xie, Shentong Mo, Zhenguo Li, Matthias Nießner, Chi-Wing Fu, and Jiaya Jia. Diffcomplete: Diffusion-based generative 3d shape completion. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[11]
Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InCVPR, 2017
2017
-
[12]
Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reinte- gration.ACM Transactions on Graphics (ToG), 36(4):1, 2017
Angela Dai, Matthias Nießner, Michael Zollhöfer, Shahram Izadi, and Christian Theobalt. Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reinte- gration.ACM Transactions on Graphics (ToG), 36(4):1, 2017
2017
-
[13]
3d shape completion using 3d-encoder-predictor cnns and shape synthesis
Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, Jürgen Sturm, and Matthias Nießner. 3d shape completion using 3d-encoder-predictor cnns and shape synthesis. InCVPR, 2017
2017
-
[14]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InForty-first International Conference on Machine Learning, 2024
2024
-
[15]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
2023
-
[16]
Bootstrap your own latent - a new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, koray kavukcuoglu, Remi Munos, and Michal Valko. Bootstrap your own latent - a new approach to self-supervised learning. In H. Larochelle, M. Ranzato, R. Hadsell, M....
2020
-
[17]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First Conference on Language Modeling, 2024
2024
-
[18]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. InInternational Conference on Learning Representations, 2022
2022
-
[19]
Combining recurrent, convolutional, and continuous-time models with linear state space layers
Albert Gu, Isys Johnson, Karan Goel, Khaled Kamal Saab, Tri Dao, Atri Rudra, and Christopher Re. Combining recurrent, convolutional, and continuous-time models with linear state space layers. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
2021
-
[20]
Momentum Contrast for Unsupervised Visual Representation Learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum Contrast for Unsupervised Visual Representation Learning . In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9726–9735, Los Alamitos, CA, USA, June 2020. IEEE Computer Society
2020
-
[21]
Über die stetige abbildung einer linie auf ein flächenstück
David Hilbert. Über die stetige abbildung einer linie auf ein flächenstück. InDritter Band: Analysis· Grundlagen der Mathematik· Physik Verschiedenes: Nebst Einer Lebensgeschichte, pages 1–2. Springer, 1935
1935
-
[22]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10579–10596, 2024
2024
-
[23]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
2023
-
[24]
Open- VLA: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Open- VLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learn...
2024
-
[25]
DINO in the room: Leveraging 2D foundation models for 3D segmentation
Karim Knaebel, Kadir Yilmaz, Daan de Geus, Alexander Hermans, David Adrian, Timm Linder, and Bastian Leibe. DINO in the room: Leveraging 2D foundation models for 3D segmentation. In2026 International Conference on 3D Vision (3DV), 2026
2026
-
[26]
Vision mamba: A comprehensive survey and taxonomy.IEEE Transactions on Neural Networks and Learning Systems, 2025
Xiao Liu, Chenxu Zhang, Fuxiang Huang, Shuyin Xia, Guoyin Wang, and Lei Zhang. Vision mamba: A comprehensive survey and taxonomy.IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[27]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022
2022
-
[28]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[29]
Autosdf: Shape priors for 3d completion, reconstruction and generation
Paritosh Mittal, Yen-Chi Cheng, Maneesh Singh, and Shubham Tulsiani. Autosdf: Shape priors for 3d completion, reconstruction and generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 306–315. IEEE, 2022
2022
-
[30]
Newcombe, Shahram Izadi, Otmar Hilliges, David Molyneaux, David Kim, An- drew J
Richard A. Newcombe, Shahram Izadi, Otmar Hilliges, David Molyneaux, David Kim, An- drew J. Davison, Pushmeet Kohli, Jamie Shotton, Steve Hodges, and Andrew Fitzgibbon. Kinectfusion: Real-time dense surface mapping and tracking. InIEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2011. 11
2011
-
[31]
Real-time 3d reconstruction at scale using voxel hashing.ACM Transactions on Graphics (ToG), 32(6):1–11, 2013
Matthias Nießner, Michael Zollhöfer, Shahram Izadi, and Marc Stamminger. Real-time 3d reconstruction at scale using voxel hashing.ACM Transactions on Graphics (ToG), 32(6):1–11, 2013
2013
-
[32]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[33]
Patchcomplete: Learning multi-resolution patch priors for 3d shape completion on unseen categories
Yuchen Rao, Yinyu Nie, and Angela Dai. Patchcomplete: Learning multi-resolution patch priors for 3d shape completion on unseen categories. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
2022
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[35]
Sc-diff: 3d shape completion with latent diffusion models.arXiv preprint arXiv:2403.12470, 2024
Simon Schaefer, Juan D Galvis, Xingxing Zuo, and Stefan Leutengger. Sc-diff: 3d shape completion with latent diffusion models.arXiv preprint arXiv:2403.12470, 2024
-
[36]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[37]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Lichtenberg, and Jianxiong Xiao
Shuran Song, Samuel P. Lichtenberg, and Jianxiong Xiao. Sun rgb-d: A rgb-d scene understand- ing benchmark suite. InCVPR, 2015
2015
-
[39]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[40]
Autorecon: Automated 3d object discovery and reconstruction
Peng Wang et al. Autorecon: Automated 3d object discovery and reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[41]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5261–5271, 2025
2025
-
[42]
Moge-2: Accurate monocular geometry with metric scale and sharp details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[43]
Few-shot 3d shape completion
Yifan Wang, Dragomir Anguelov, Xin Tong, and Angela Dai. Few-shot 3d shape completion. InECCV, 2020
2020
-
[44]
Pointr: Diverse point cloud completion with geometry-aware transformers
Xumin Yu, Yongming Rao, Ziyi Wang, Zuyan Liu, Jiwen Lu, and Jie Zhou. Pointr: Diverse point cloud completion with geometry-aware transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 12498–12507, 2021
2021
-
[45]
AdaPoinTr: Diverse Point Cloud Completion With Adaptive Geometry-Aware Transformers .IEEE Transactions on Pattern Analysis & Machine Intelligence, 45(12):14114–14130, December 2023
Xumin Yu, Yongming Rao, Ziyi Wang, Jiwen Lu, and Jie Zhou. AdaPoinTr: Diverse Point Cloud Completion With Adaptive Geometry-Aware Transformers .IEEE Transactions on Pattern Analysis & Machine Intelligence, 45(12):14114–14130, December 2023. 12
2023
-
[46]
Pcn: Point completion network
Wentao Yuan, Tejas Khot, David Held, Christoph Mertz, and Martial Hebert. Pcn: Point completion network. In2018 international conference on 3D vision (3DV), pages 728–737. IEEE, 2018
2018
-
[47]
Latent uncertainty-aware multi-view sdf scan completion
Faezeh Zakeri, Lukas Ruppert, Raphael Braun, and Hendrik Lensch. Latent uncertainty-aware multi-view sdf scan completion. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3556–3566, 2026
2026
-
[48]
V oxel mamba: Group-free state space models for point cloud based 3d object detection.Advances in Neural Information Processing Systems, 37:81489–81509, 2024
Guowen Zhang, Lue Fan, Chenhang He, Zhen Lei, Zhaoxiang Zhang, and Lei Zhang. V oxel mamba: Group-free state space models for point cloud based 3d object detection.Advances in Neural Information Processing Systems, 37:81489–81509, 2024
2024
-
[49]
Sdf-stylegan: implicit sdf-based stylegan for 3d shape generation
Xinyang Zheng, Yang Liu, Pengshuai Wang, and Xin Tong. Sdf-stylegan: implicit sdf-based stylegan for 3d shape generation. InComputer Graphics Forum, volume 41, pages 52–63. Wiley Online Library, 2022. 13 A Technical appendices and supplementary material A.1 TSDF-DINO Model In this section, we provide additional details on our TSDF-DINO model, including th...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.