Generating Robust Portfolios of Optimization Models using Large Language Models
Pith reviewed 2026-06-29 16:46 UTC · model grok-4.3
The pith
A single LLM acting as both stochastic generator and reasoning evaluator produces portfolios of optimization models that are guaranteed to contain high-quality candidates whenever at least one of those roles aligns with human preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
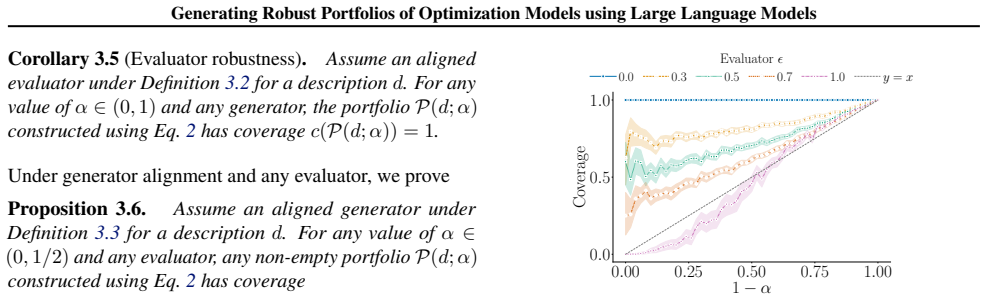
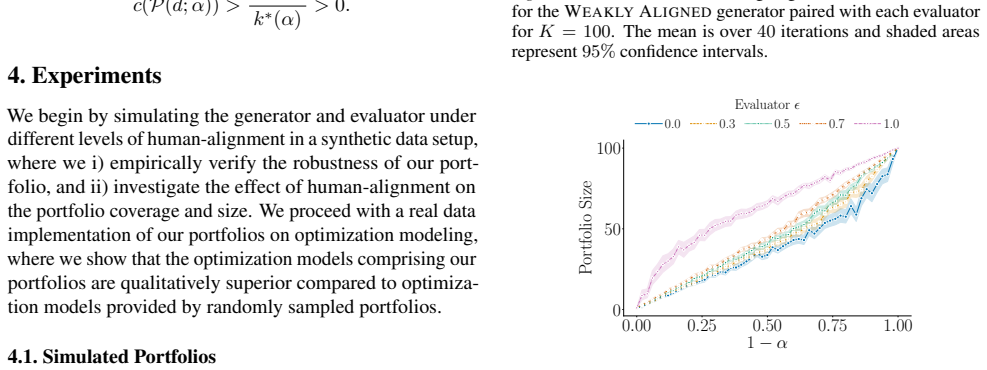
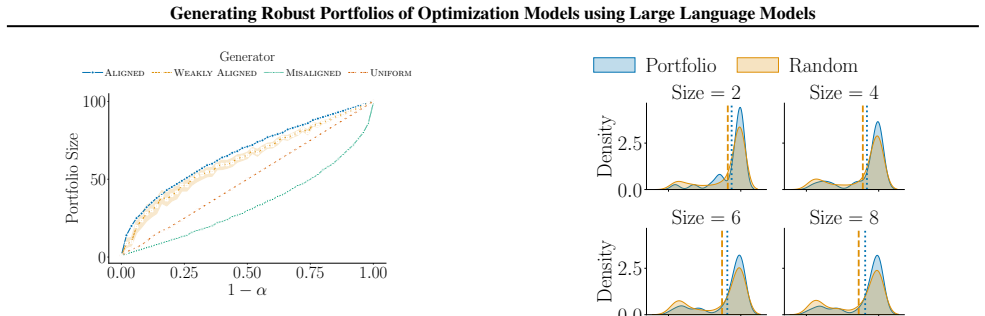
The central claim is that a unified framework in which one LLM serves simultaneously as a stochastic generator of candidate optimization models and as a reasoning evaluator of those candidates yields portfolios that are robust to LLM limitations; specifically, the framework carries a guarantee that high-quality models will be present whenever either the generation process or the evaluation process is well-aligned with human preferences.
What carries the argument
unified framework in which a single LLM performs both stochastic generation of model candidates and reasoning-based evaluation of those candidates
If this is right
- Decision makers can review multiple candidates before selecting a final optimization model.
- Risk from any single unreliable LLM output is reduced by the portfolio construction.
- The same dual-role procedure applies across a range of optimization modeling tasks.
- Human-in-the-loop selection becomes a principled step rather than an ad-hoc check.
Where Pith is reading between the lines
- The dual-role construction may transfer to other structured generation tasks that currently output only one candidate.
- Empirical checks could compare portfolio quality when the same LLM is used in both roles versus when two different LLMs are assigned the roles.
- The guarantees might be tested by deliberately degrading alignment in one role while keeping the other intact.
Load-bearing premise
A single LLM can be used reliably in both the generator role and the evaluator role so that alignment of either role with human preferences is enough to guarantee portfolio quality.
What would settle it
An experiment in which both the generator and the evaluator are shown to be misaligned with human preferences yet the portfolio still contains high-quality models, or in which one role is aligned yet the portfolio contains no high-quality models.
Figures




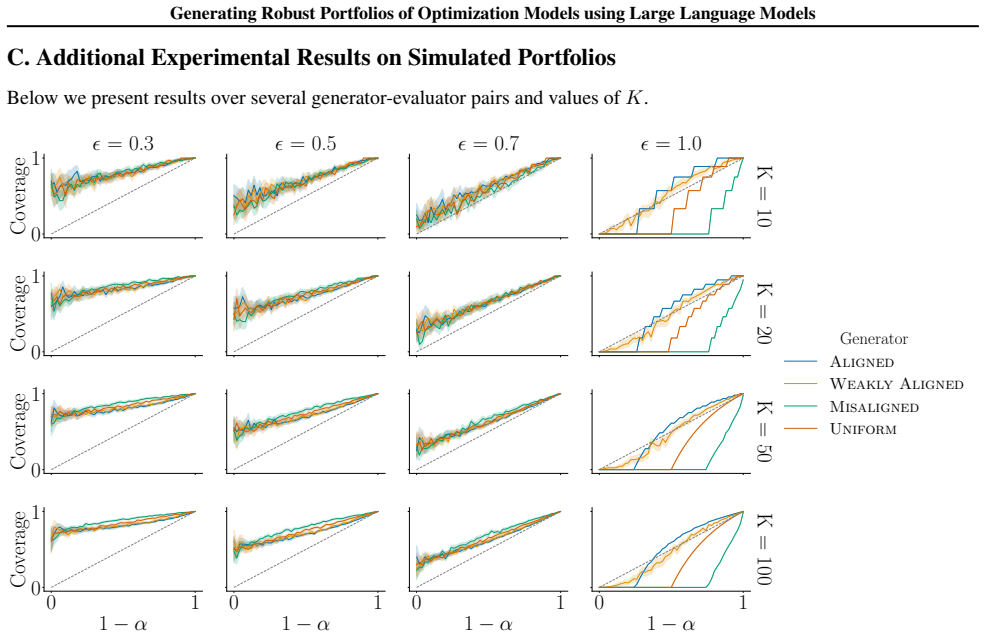
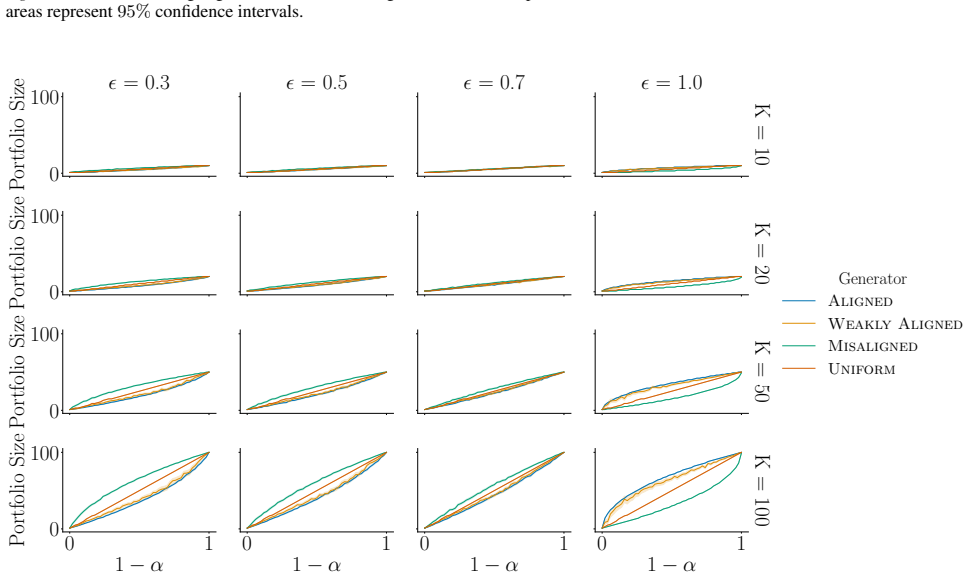
read the original abstract
Mathematical optimization is a powerful tool for structured decision-making across domains such as resource allocation and planning. Formulating optimization models faithful to reality, though, remains a significant bottleneck as it typically demands both domain expertise and optimization knowledge that are often scarce. Recent advances in large language models (LLMs) promise to bridge this gap, enabling the generation of candidate optimization models from natural language descriptions. However, there is no guarantee that any single LLM-generated model is reliable, and existing approaches that output only one model are therefore risky. In this work, we propose a novel algorithm that generates a portfolio of optimization models, designed to be robust to the limitations of LLMs. Our method exploits the observation that a single LLM can play two distinct roles $\unicode{x2014}$ as a stochastic generator and as a reasoning evaluator $\unicode{x2014}$ and proposes a unified framework that leverages both capabilities in a complementary manner. We provide theoretical guarantees showing that, as long as either the generator or the evaluator is well-aligned with human preferences, the portfolio is guaranteed to contain high-quality candidates, enabling a principled human-in-the-loop process in which a decision-maker can review multiple candidates before committing to one. We further validate our approach empirically, demonstrating strong performance across a range of optimization modeling tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an algorithm to generate a portfolio of optimization models from natural language descriptions by using a single LLM in dual roles: as a stochastic generator of candidate models and as a reasoning evaluator. It claims theoretical guarantees that the resulting portfolio is guaranteed to contain high-quality candidates provided that either the generator or the evaluator is well-aligned with human preferences, thereby supporting a human-in-the-loop selection process. The approach is further validated empirically on a range of optimization modeling tasks.
Significance. If the conditional theoretical guarantee can be established with a clear formal statement and proof, the work would offer a principled way to mitigate the unreliability of individual LLM-generated optimization models. The dual-role framing of a single LLM and the emphasis on portfolio robustness rather than single-model correctness are potentially valuable contributions to LLM-assisted optimization modeling.
major comments (2)
- [Abstract] Abstract (paragraph on unified framework): The central theoretical claim is a conditional guarantee resting on the assumption that one LLM can reliably serve in two complementary roles (stochastic generator and reasoning evaluator) such that alignment of either suffices for portfolio quality. No formal definition of alignment, no statement of the guarantee, and no proof sketch are supplied, rendering the claim impossible to verify or falsify from the manuscript.
- [Abstract] Abstract (empirical validation sentence): The manuscript asserts 'strong performance across a range of optimization modeling tasks' but supplies no experiment details, baselines, metrics, error analysis, or statistical tests, so the empirical support for the portfolio approach cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below with specific references to the full paper and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on unified framework): The central theoretical claim is a conditional guarantee resting on the assumption that one LLM can reliably serve in two complementary roles (stochastic generator and reasoning evaluator) such that alignment of either suffices for portfolio quality. No formal definition of alignment, no statement of the guarantee, and no proof sketch are supplied, rendering the claim impossible to verify or falsify from the manuscript.
Authors: The abstract provides a high-level summary of the contribution. The full manuscript supplies the requested elements: alignment is formally defined in Definition 1 (Section 3.1), the conditional guarantee is stated as Theorem 1 (Section 4.2), and the complete proof appears in Appendix A. We will revise the abstract to include a one-sentence statement of the theorem for improved self-containment. revision: partial
-
Referee: [Abstract] Abstract (empirical validation sentence): The manuscript asserts 'strong performance across a range of optimization modeling tasks' but supplies no experiment details, baselines, metrics, error analysis, or statistical tests, so the empirical support for the portfolio approach cannot be assessed.
Authors: Experiment details are provided in the main body rather than the abstract. Section 5 describes the tasks, baselines (including single-model LLM generation and existing portfolio methods), metrics (feasibility rate, objective value gap), error analysis, and statistical tests (paired t-tests with p-values in Table 3). The abstract follows standard length constraints; we see no need to expand it further. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is a conditional theoretical guarantee: if either the LLM generator or evaluator aligns with human preferences, the generated portfolio contains high-quality candidates. This rests on an external assumption about alignment rather than any internal fitting, redefinition, or self-referential derivation. No equations, self-citations, or ansatzes are presented in the provided text that reduce the guarantee to a tautology or to the method's own outputs by construction. The dual-role observation is used to motivate the framework but does not create a self-definitional loop. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A single LLM can play two distinct roles as stochastic generator and reasoning evaluator in a complementary manner.
- domain assumption Alignment of generator or evaluator with human preferences is a meaningful and usable condition for the guarantee.
Reference graph
Works this paper leans on
-
[1]
Autoformulation of mathematical optimization models using llms.arXiv preprint arXiv:2411.01679,
Astorga, N., Liu, T., Xiao, Y ., and Van Der Schaar, M. Autoformulation of mathematical optimization models using llms.arXiv preprint arXiv:2411.01679,
-
[2]
Cardenoso, F. and Caarls, W. Leveraging llms for reward function design in reinforcement learning control tasks. arXiv preprint arXiv:2511.19355,
-
[3]
Jiang, C., Shu, X., Qian, H., Lu, X., Zhou, J., Zhou, A., and Yu, Y . Llmopt: Learning to define and solve gen- eral optimization problems from scratch.arXiv preprint arXiv:2410.13213,
-
[4]
Reflexion: Language Agents with Verbal Reinforcement Learning
Shinn, N., Cassano, F., Labash, B., Gopinath, A., Narasimhan, K., and Yao, S. Reflexion: Language agents with verbal reinforcement learning, 2023.URL https://arxiv. org/abs/2303.11366, 1,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
doi: 10.1016/j.knosys.2025.114065
ISSN 0950-7051. doi: 10.1016/j.knosys.2025.114065. URL https://doi. org/10.1016/j.knosys.2025.114065. Vercellis, C.Business intelligence: data mining and opti- mization for decision making. John Wiley & Sons,
-
[6]
A survey of optimiza- tion modeling meets llms: Progress and future directions
5 Generating Robust Portfolios of Optimization Models using Large Language Models Xiao, Z., Xie, J., Xu, L., Guan, S., Zhu, J., Han, X., Fu, X., Yu, W., Wu, H., Shi, W., et al. A survey of optimiza- tion modeling meets llms: Progress and future directions. arXiv preprint arXiv:2508.10047,
-
[7]
Yang, Z., Wang, Y ., Huang, Y ., Guo, Z., Shi, W., Han, X., Feng, L., Song, L., Liang, X., and Tang, J. Optibench meets resocratic: Measure and improve llms for opti- mization modeling.arXiv preprint arXiv:2407.09887,
-
[8]
Solving general natural-language-description optimization problems with large language models
Zhang, J., Wang, W., Guo, S., Wang, L., Lin, F., Yang, C., and Yin, W. Solving general natural-language-description optimization problems with large language models. In Proceedings of the 2024 Conference of the North Amer- ican Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 6: In- dustry Track), pp. 483–490,
2024
-
[9]
Using this and the fact that |P \ X |=|P ∗ \ X |=k ∗(α)− |X | , Eq
ForX ⊆ Pwe have X o∈X p(o) + X o′∈P\X p(o′)≥1−α.(6) Since the generator model is human aligned, it must hold that ∀o∈ P \ X and ∀o′ ∈ P ∗ \ X , rank(o)≥rank(o ′) given the human ranking π∗(d) and as a result, p(o)≤p(o ′). Using this and the fact that |P \ X |=|P ∗ \ X |=k ∗(α)− |X | , Eq. 6 becomes X o∈X p(o) + X o′′∈P ∗\X p(o′′)≥ X o∈X p(o) + X o′∈P\X p(...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.