PersLitEval: Fine-grained Benchmark and Evaluation of LLMs on Persian Literature Questions
Pith reviewed 2026-06-29 18:31 UTC · model grok-4.3
The pith
LLMs achieve higher accuracy on conceptual Persian literature tasks but struggle with formal linguistic analysis such as spelling and word formation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
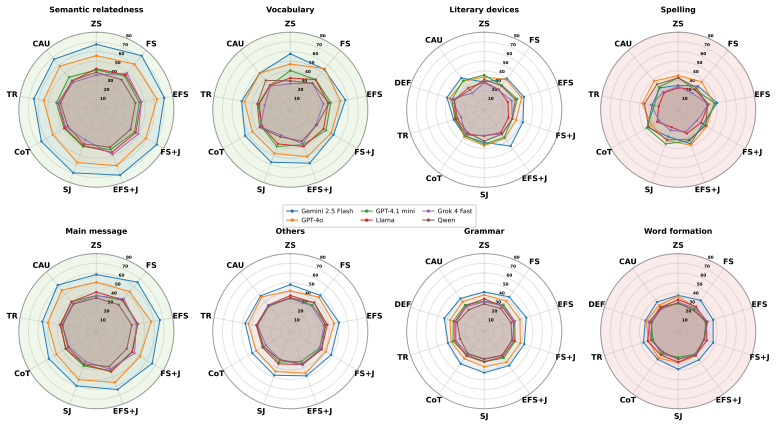
The authors establish that models reach higher accuracy on conceptual similarity tasks but struggle with formal linguistic analysis, with spelling and word formation proving the hardest across all models, and that prompting strategy has a significant impact on performance with explained few-shot examples yielding the best results particularly on formal linguistic categories.
What carries the argument
PersLitEval benchmark of 4,514 questions across eight fine-grained categories, evaluated under ten prompting strategies to measure category-level performance disparities.
If this is right
- Prompting strategy significantly affects performance and works best when using explained few-shot examples on formal categories.
- Models require different improvement approaches for conceptual versus formal linguistic categories.
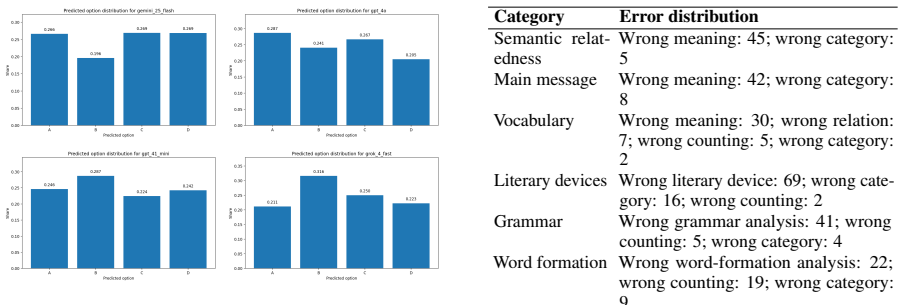
- Three distinct failure modes—semantic comprehension gaps, formal linguistic knowledge gaps, and counting errors—indicate that targeted fixes could address specific weaknesses.
- Category-level disparities suggest that broad multilingual training alone is insufficient for literary tasks.
Where Pith is reading between the lines
- The benchmark could be extended to test whether similar performance gaps appear in other languages' literary domains.
- The results imply that LLMs may benefit from explicit rule-based training modules for formal linguistic features rather than relying solely on pattern exposure.
- Future work could measure whether fine-tuning on the hardest categories closes the gap more effectively than prompting changes.
Load-bearing premise
The questions sourced from Konkur university entrance examination materials accurately represent the eight fine-grained categories of Persian literary knowledge without bias.
What would settle it
A new set of questions in the same categories on which all tested models achieve uniform accuracy levels, or evidence that the original questions systematically misalign with standard definitions of spelling, word formation, or conceptual similarity.
Figures

read the original abstract
Despite impressive multilingual capabilities, large language models (LLMs) remain poorly evaluated on literary knowledge in non-English languages. We introduce PersLitEval, a benchmark of 4,514 Persian literature multiple-choice questions across eight fine-grained categories spanning spelling, literary devices, grammar, vocabulary, word formation, and conceptual understanding, sourced from materials for the Konkur university entrance examination. We evaluate six LLMs across ten prompting strategies, revealing striking category-level disparities across three tiers of task difficulty: models reach higher accuracy on conceptual similarity tasks but struggle with formal linguistic analysis, with spelling and word formation proving the hardest across all models. Prompting strategy has a significant impact on performance, with explained few-shot examples yielding the best results, particularly on formal linguistic categories. An error analysis identifies three failure modes: semantic comprehension gaps, formal linguistic knowledge gaps, and counting/enumeration errors, suggesting that different categories require different improvement strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PersLitEval, a benchmark of 4,514 Persian literature multiple-choice questions drawn from Konkur university entrance exam materials and partitioned into eight fine-grained categories (spelling, literary devices, grammar, vocabulary, word formation, and conceptual understanding). It evaluates six LLMs across ten prompting strategies, reports tiered performance with higher accuracy on conceptual similarity tasks and lowest on spelling/word formation, identifies explained few-shot as the strongest strategy, and analyzes three error modes to argue that categories require distinct improvement approaches.
Significance. If the category assignments hold, the work supplies a needed fine-grained, non-English literary benchmark that isolates specific LLM weaknesses in formal linguistic analysis versus conceptual tasks and demonstrates prompting effects; the use of authentic exam questions and the error-mode breakdown are concrete strengths that could inform targeted multilingual LLM development.
major comments (1)
- [§3] §3 (Benchmark Construction): The assignment of the 4,514 questions to the eight categories is described only at the level of sourcing from Konkur materials; no procedure, single- vs. multi-annotator process, inter-annotator agreement, or handling of multi-category items is reported. This directly threatens the central claim of three distinct difficulty tiers, because the observed accuracy ordering could be an artifact of how mixed or borderline items were binned rather than an intrinsic property of the linguistic distinctions.
minor comments (2)
- [§4] The ten prompting strategies are referenced in the abstract and results but lack an explicit enumerated list or template examples in the methods section, which would aid reproducibility.
- Table or figure captions for per-category accuracies should explicitly state the number of questions per category to allow readers to assess whether low-performing categories are also the smallest.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the need for greater transparency in benchmark construction. We address the major comment below and will revise the manuscript to strengthen the description of category assignment.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The assignment of the 4,514 questions to the eight categories is described only at the level of sourcing from Konkur materials; no procedure, single- vs. multi-annotator process, inter-annotator agreement, or handling of multi-category items is reported. This directly threatens the central claim of three distinct difficulty tiers, because the observed accuracy ordering could be an artifact of how mixed or borderline items were binned rather than an intrinsic property of the linguistic distinctions.
Authors: The 4,514 questions were extracted from official Konkur exam papers in which each item is already labeled with its category by the exam authorities according to the standard Persian literature curriculum divisions. No new annotation was performed; category membership therefore reflects the pre-existing official classification rather than author-defined binning. We will revise §3 to explicitly document this sourcing procedure, confirm that questions retain their original exam labels, and describe the (rare) handling of any multi-category items by retaining the primary label. The three difficulty tiers are not a priori assumptions but are observed post-hoc from model accuracy patterns; documenting the official provenance will clarify that the performance ordering aligns with established linguistic distinctions rather than arbitrary assignment. revision: yes
Circularity Check
No circularity: direct empirical benchmark with no derivations or self-referential reductions.
full rationale
The paper constructs PersLitEval from 4,514 Konkur-sourced questions partitioned into eight categories and reports LLM accuracies across prompting strategies as direct observations. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text; the tiered difficulty claims follow from the empirical results rather than reducing to the categorization procedure by construction. The work is self-contained as an evaluation benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple-choice questions from Konkur exams validly and unbiasedly measure the eight fine-grained literary knowledge categories
Reference graph
Works this paper leans on
-
[1]
Amirhossein Abaskohi, Sara Baruni, Mostafa Masoudi, Nesa Abbasi, Mohammad Hadi Babalou, Ali Edalat, Sepehr Kamahi, Samin Mahdizadeh Sani, Nikoo Naghavian, Danial Namazifard, Pouya Sadeghi, and Yadollah Yaghoobzadeh. 2024. http://arxiv.org/abs/2404.02403 Benchmarking large language models for persian: A preliminary study focusing on chatgpt
-
[2]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Farhan Farsi, Farnaz Aghababaloo, Shahriar Shariati Motlagh, Parsa Ghofrani, MohammadAli SadraeiJavaheri, Shayan Bali, Amirhossein Shabani, Farbod Bijary, Ghazal Zamaninejad, AmirMohammad Salehoof, and Saeedeh Momtazi. 2025. http://arxiv.org/abs/2508.00673 Melac: Massive evaluation of large language models with alignment of culture in persian language
-
[5]
Omid Ghahroodi, Marzia Nouri, Mohammad Vali Sanian, Alireza Sahebi, Doratossadat Dastgheib, Ehsaneddin Asgari, Mahdieh Soleymani Baghshah, and Mohammad Hossein Rohban. 2024. http://arxiv.org/abs/2404.06644 Khayyam challenge (persianmmlu): Is your llm truly wise to the persian language?
- [6]
-
[7]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Ghazal Kalhor and Yadollah Yaghoobzadeh. 2026. Ghazalbench: Usage-grounded evaluation of llms on persian ghazals. arXiv preprint arXiv:2603.09979
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Daniel Khashabi, Arman Cohan, Siamak Shakeri, Pedram Hosseini, Pouya Pezeshkpour, Malihe Alikhani, Moin Aminnaseri, Marzieh Bitaab, Faeze Brahman, Sarik Ghazarian, Mozhdeh Gheini, Arman Kabiri, Rabeeh Karimi Mahabadi, Omid Memarrast, Ahmadreza Mosallanezhad, Erfan Noury, Shahab Raji, Mohammad Sadegh Rasooli, Sepideh Sadeghi, Erfan Sadeqi Azer, Niloofar Sa...
-
[10]
Erfan Moosavi Monazzah, Vahid Rahimzadeh, Yadollah Yaghoobzadeh, Azadeh Shakery, and Mohammad Taher Pilehvar. 2025. https://doi.org/10.18653/v1/2025.naacl-long.631 P er C ul: A story-driven cultural evaluation of LLM s in P ersian . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistic...
-
[11]
Melika Nobakhtian, Yadollah Yaghoobzadeh, and Mohammad Taher Pilehvar. 2025. Evaluating cultural knowledge and reasoning in llms through persian allusions. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 25725--25737
2025
-
[13]
OpenAI. 2024 a . http://arxiv.org/abs/2303.08774 Gpt-4 technical report
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
OpenAI. 2024 b . http://arxiv.org/abs/2410.21276 Gpt-4o system card
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Qwen Team . 2024. https://arxiv.org/abs/2407.10671 Qwen2: Enhancing language models with multilingual and structured capabilities . arXiv preprint arXiv:2407.10671
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Angelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare, Mohamed A Haggag, Alfonso Amayuelas, et al. 2024. Include: Evaluating multilingual language understanding with regional knowledge. arXiv preprint arXiv:2411.19799
-
[17]
Alireza Sakhaeirad, Ali Ma'manpoosh, and Arshia Hemmat. 2026. Unmasking the factual-conceptual gap in persian language models. In The Proceedings of the First Workshop on NLP and LLMs for the Iranian Language Family, pages 1--12
2026
-
[18]
Mehrnoush Shamsfard, Zahra Saaberi, Seyed Mohammad Hossein Hashemi, Zahra Vatankhah, Motahareh Ramezani, Niki Pourazin, Tara Zare, Maryam Azimi, Sarina Chitsaz, Sama Khoraminejad, et al. 2025. Farseval-pkbets: A new diverse benchmark for evaluating persian large language models. arXiv preprint arXiv:2504.14690
-
[19]
Yueqi Song, Simran Khanuja, Pengfei Liu, Fahim Faisal, Alissa Ostapenko, Genta Indra Winata, Alham Fikri Aji, Samuel Cahyawijaya, Yulia Tsvetkov, Antonios Anastasopoulos, et al. 2023. Globalbench: A benchmark for global progress in natural language processing. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages...
2023
- [20]
-
[21]
xAI . 2025. https://data.x.ai/2025-09-19-grok-4-fast-model-card.pdf Grok 4 fast model card . Technical documentation describing training, evaluation, and limitations of the model
2025
-
[22]
Weihao Xuan, Rui Yang, Heli Qi, Qingcheng Zeng, Yunze Xiao, Aosong Feng, Dairui Liu, Yun Xing, Junjue Wang, Fan Gao, et al. 2025. Mmlu-prox: A multilingual benchmark for advanced large language model evaluation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1513--1532
2025
-
[23]
Tianyang Zhong, Zhenyuan Yang, Zhengliang Liu, Ruidong Zhang, Weihang You, Yiheng Liu, Haiyang Sun, Yi Pan, Yiwei Li, Yifan Zhou, et al. 2024. Opportunities and challenges of large language models for low-resource languages in humanities research. arXiv preprint arXiv:2412.04497
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[25]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.