Semi-Supervised Gaze Estimation via Disentangled Subspace Contrastive Learning
Pith reviewed 2026-06-29 18:15 UTC · model grok-4.3
The pith
Jacobian regularization splits gaze features into pitch and yaw subspaces so that ordinal contrastive learning on unlabeled images reaches competitive accuracy with only 5 percent labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
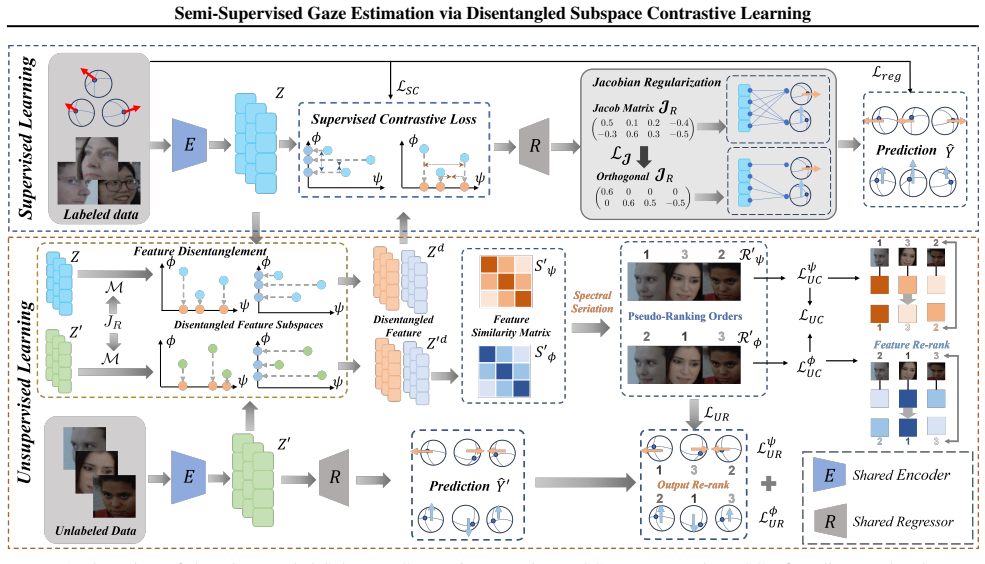
By imposing Jacobian regularization the feature space factors into two subspaces each dedicated to a single gaze component; the intrinsic ordinal structure inside those subspaces then supplies a supervisory signal that lets contrastive learning operate effectively on unlabeled samples, producing robust gaze representations from far fewer annotations than full supervision requires.
What carries the argument
Disentangled Subspace Contrastive Learning (DSCL) that uses Jacobian regularization to create pitch-specific and yaw-specific subspaces whose ordinal rankings drive contrastive pairs on unlabeled data.
If this is right
- The same architecture can be inserted into existing gaze networks without changing their backbone or loss structure.
- Performance remains competitive under both in-domain and cross-domain evaluation when labeled data is reduced to 5 percent.
- The ordinal contrastive term can be computed directly from the continuous angle values inside each disentangled subspace.
- Domain generalization improves because the contrastive objective pulls together images that share the same angle ordering regardless of appearance shifts.
Where Pith is reading between the lines
- If the subspace separation generalizes, similar Jacobian-driven disentanglement could be tested on other continuous regression tasks such as head-pose or body orientation estimation.
- The approach implies that explicit geometric regularization can substitute for some of the diversity that would otherwise have to come from additional labeled domains.
- One could measure whether the learned subspaces remain orthogonal when the model is fine-tuned on entirely new camera setups or lighting conditions.
Load-bearing premise
Jacobian regularization will reliably isolate each gaze angle into its own subspace and the ordering inside those subspaces will supply a useful contrastive signal even when labels are scarce.
What would settle it
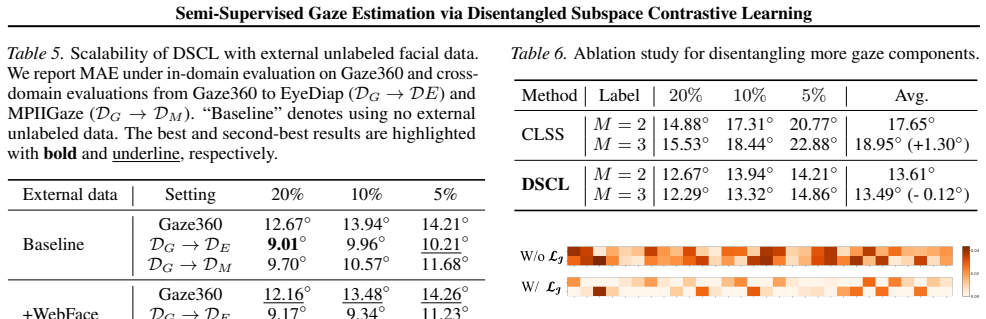
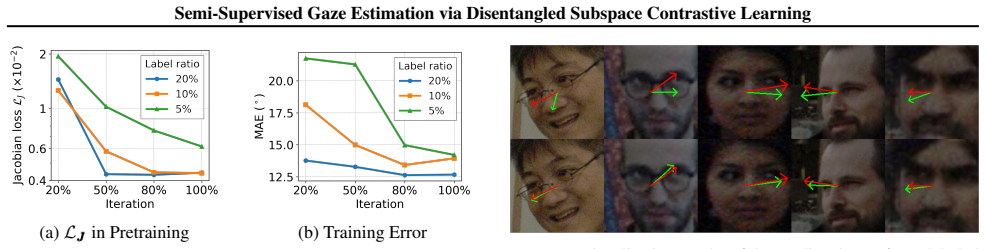
A controlled ablation in which the Jacobian term is removed, after which the subspaces mix pitch and yaw signals and accuracy with 5 percent labels falls back to the level of a standard supervised baseline on the same split.
Figures





read the original abstract
Appearance-based gaze estimation always suffers from poor generalization due to limited annotated samples and insufficient dataset diversity. Leading approaches adopt weakly supervised learning to generate large-scale pseudo-labeled data from unconstrained real-world scenarios, aiming to mitigate the domain shifts. In this work, we devise a simple yet effective semi-supervised learning architecture that leverages unlabeled data to enhance domain generalization, thereby reducing reliance on labor-intensive manual annotations. Our key insight is to impose Jacobian regularization to disentangle feature representations into discriminative subspaces dedicated to specific gaze components, such as pitch and yaw angles. We further exploit the intrinsic ordinal ranking within each subspace for contrastive learning, enabling the model to learn robust gaze representations from a small set of labeled samples and an abundance of unlabeled ones. This ultimately yields our Disentangled Subspace Contrastive Learning (DSCL) framework. Extensive experiments on multiple benchmarks verify that the proposed DSCL is plug-and-play, achieving competitive performance using only 20\%, 10\%, and even 5\% of the annotated data under both in-domain and cross-domain evaluation settings. The public code is available at \href{https://github.com/da60266/DSCL}{https://github.com/da60266/DSCL}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Disentangled Subspace Contrastive Learning (DSCL), a semi-supervised framework for appearance-based gaze estimation. Jacobian regularization is applied to disentangle feature representations into subspaces dedicated to individual gaze components (e.g., pitch and yaw); intrinsic ordinal ranking within each subspace then supplies a contrastive signal on unlabeled samples. The method is presented as plug-and-play and is claimed to deliver competitive performance on multiple benchmarks using only 5–20 % labeled data under both in-domain and cross-domain protocols, with public code released.
Significance. If the disentanglement mechanism and resulting gains are validated, the approach could meaningfully lower annotation costs for gaze estimation while improving cross-domain robustness. The public code release is a concrete strength that supports reproducibility and follow-up work.
major comments (2)
- [§3] §3 (method description): The central claim that Jacobian regularization isolates subspaces each dedicated to a single gaze component (pitch or yaw) and that the resulting ordinal ranking supplies a reliable contrastive signal is not supported by any direct evidence. No visualizations of the subspaces, quantitative disentanglement metrics (e.g., mutual information or correlation between pitch/yaw directions), or ablation isolating the regularization’s effect on subspace purity are provided. Because every downstream claim (low-label performance, cross-domain gains) rests on this assumption, the attribution of results to the proposed mechanism remains unverified.
- [Experiments] Experimental section / abstract: The manuscript asserts competitive results at 5 %, 10 %, and 20 % label fractions on multiple benchmarks, yet the provided description contains no quantitative tables, ablation studies on the Jacobian term, error-bar statistics, or statistical significance tests. Without these, the empirical support for the central performance claim cannot be assessed and the “plug-and-play” assertion cannot be evaluated.
minor comments (1)
- The abstract would benefit from naming the specific benchmarks and evaluation protocols used to support the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the supporting evidence for the proposed mechanism and empirical claims.
read point-by-point responses
-
Referee: [§3] §3 (method description): The central claim that Jacobian regularization isolates subspaces each dedicated to a single gaze component (pitch or yaw) and that the resulting ordinal ranking supplies a reliable contrastive signal is not supported by any direct evidence. No visualizations of the subspaces, quantitative disentanglement metrics (e.g., mutual information or correlation between pitch/yaw directions), or ablation isolating the regularization’s effect on subspace purity are provided. Because every downstream claim (low-label performance, cross-domain gains) rests on this assumption, the attribution of results to the proposed mechanism remains unverified.
Authors: We agree that direct evidence for the disentanglement effect would strengthen the paper. In the revision we will add (i) visualizations of the feature subspaces, (ii) quantitative metrics including correlation and mutual-information scores between each subspace and the corresponding gaze component, and (iii) an ablation that isolates the Jacobian term’s contribution to subspace purity and downstream performance. revision: yes
-
Referee: [Experiments] Experimental section / abstract: The manuscript asserts competitive results at 5 %, 10 %, and 20 % label fractions on multiple benchmarks, yet the provided description contains no quantitative tables, ablation studies on the Jacobian term, error-bar statistics, or statistical significance tests. Without these, the empirical support for the central performance claim cannot be assessed and the “plug-and-play” assertion cannot be evaluated.
Authors: We will expand the experimental section with (i) full quantitative tables for the 5 %, 10 %, and 20 % label regimes on all reported benchmarks, (ii) a dedicated ablation on the Jacobian regularization term, (iii) error bars computed over multiple random seeds, and (iv) statistical significance tests against the baselines. These additions will allow direct evaluation of the performance claims and the plug-and-play property. revision: yes
Circularity Check
No circularity detected; derivation is self-contained and independent of evaluation results.
full rationale
The paper presents a semi-supervised architecture that applies Jacobian regularization to encourage subspace disentanglement followed by contrastive learning on intrinsic ordinal rankings. No quoted equations, definitions, or claims reduce any output quantity to an input by construction, nor do any 'predictions' collapse to fitted parameters on the same data. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The method description stands independently of the reported benchmark numbers, which are obtained from external evaluation sets rather than being statistically forced by the training procedure itself. This is the normal case of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Lu, F
Cheng, Y . and Lu, F. Gaze estimation using transformer. In 2022 26th International Conference on Pattern Recogni- tion (ICPR), pp. 3341–3347. IEEE,
2022
-
[2]
X., and Bulling, A
Steil, J., Huang, M. X., and Bulling, A. Fixation detection for head-mounted eye tracking based on visual similarity of gaze targets. InProceedings of the 2018 ACM sympo- sium on eye tracking research & applications, pp. 1–9,
2018
-
[3]
Yi, D., Lei, Z., Liao, S., and Li, S. Z. Learning face repre- sentation from scratch.arXiv preprint arXiv:1411.7923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Following the preprocessing steps in (Cheng et al., 2024), we exclude images where the subject’s face is not visible
was collected in both indoor and outdoor environments, comprising labeled 3D gaze data from 238 subjects with a diverse range of head poses and gaze directions. Following the preprocessing steps in (Cheng et al., 2024), we exclude images where the subject’s face is not visible. The remaining data is divided into a training set of 84,902 images, which is f...
2024
-
[5]
MPIIGaze(Zhang et al., 2017a) was collected from 15 subjects in unconstrained real-world environments
And 16,031 images are served as the test set for in-domain evaluations. MPIIGaze(Zhang et al., 2017a) was collected from 15 subjects in unconstrained real-world environments. Adhering to the standard evaluation protocol, we select a subset of 3,000 images from each subject. For cross-domain evaluations, consistent with previous works (Cheng et al., 2022; ...
2022
-
[6]
Adhering to the protocol in (Cheng et al., 2024), we select 16,674 images from 14 subjects to serve as the target domain for cross-domain evaluations
consists of video clips recorded from 16 subjects, where gaze targets are defined by either screen targets or 3D floating balls. Adhering to the protocol in (Cheng et al., 2024), we select 16,674 images from 14 subjects to serve as the target domain for cross-domain evaluations. C. Extension to Other Multi-Target Regression Tasks Beyond the gaze estimatio...
2024
-
[7]
The hyperparameters γ, wSC, wUC and wUR are set to 1.0, 1.0, 0.05, 0.01
We utilize Adam optimizer with learning rate 2e−5 during the training. The hyperparameters γ, wSC, wUC and wUR are set to 1.0, 1.0, 0.05, 0.01. We randomly select samples for Dsprites dataset, and 13 Semi-Supervised Gaze Estimation via Disentangled Subspace Contrastive Learning Table 7.Detailed Statistics of Datasets Dataset # of instance # of feature # o...
-
[8]
and PnP-GA (Liu et al., 2021), and then inject our DSCL into them, results are shown in Figure
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.