Counteraction-Aware Multi-Teacher On-Policy Distillation for General Capability Recovery with Domain Preservation
Pith reviewed 2026-06-29 17:26 UTC · model grok-4.3
The pith
Alternating updates and gap-based selection recover general capabilities while preserving domain behavior in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
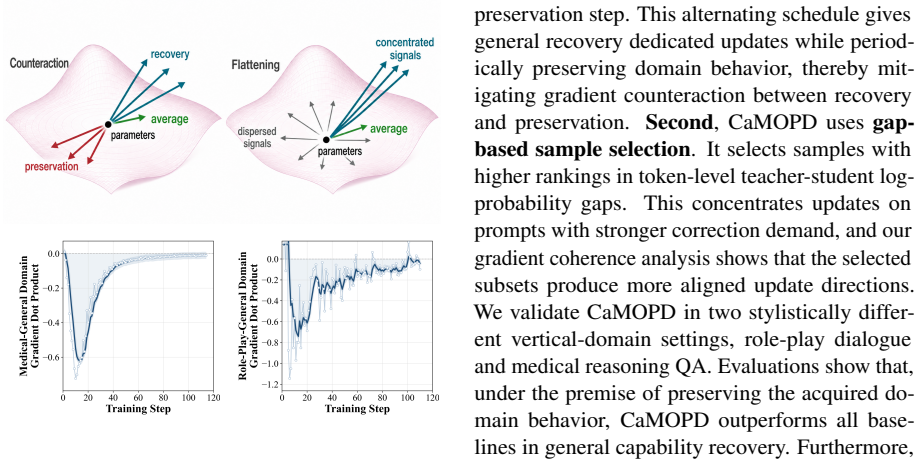
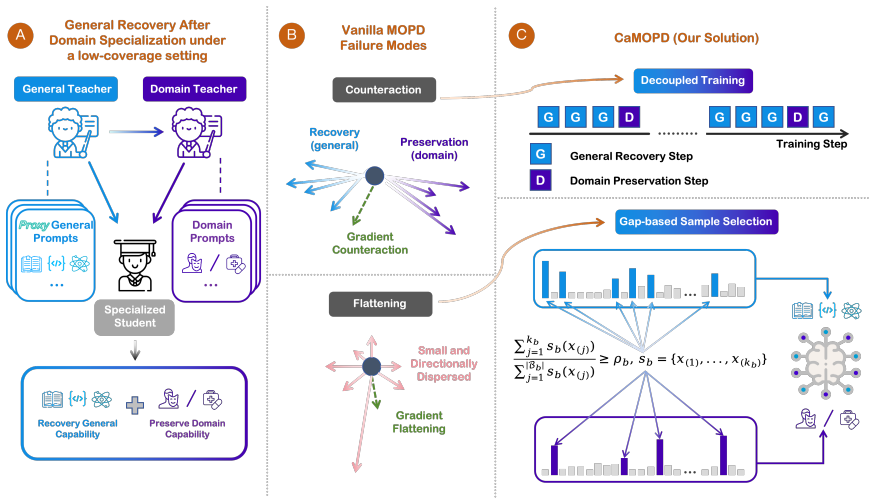
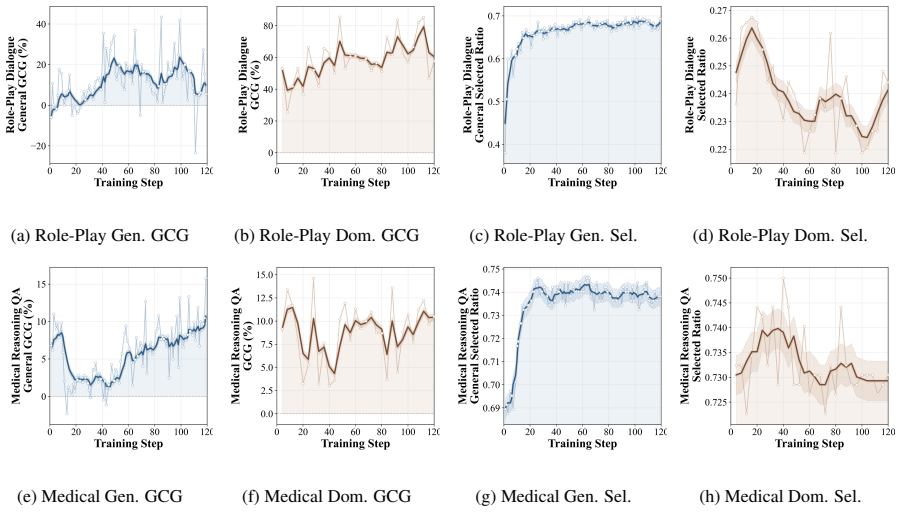
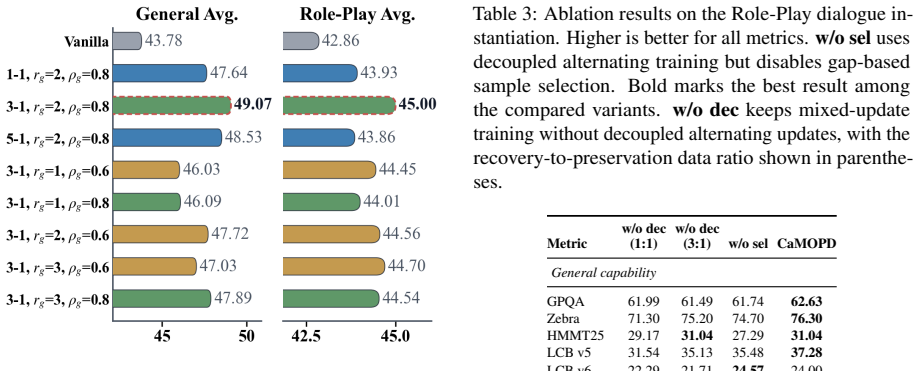
The central claim is that by decoupling the training into alternating phases for general recovery and domain preservation, and by selecting samples according to larger averaged token-level teacher-student log-probability gaps, CaMOPD overcomes the counteraction and flattening issues of vanilla MOPD, resulting in the best general capability recovery while maintaining domain-specific behavior across the tested scenarios.
What carries the argument
Decoupled alternating training and gap-based sample selection, where samples are chosen by their averaged token-level teacher-student log-probability gaps.
If this is right
- General recovery outperforms baselines in role-play and medical QA.
- Domain-specific behavior is maintained through periodic domain prompt reviews.
- Gradient coherence improves, indicating more consistent correction signals.
- The method succeeds with proxy prompts rather than requiring exact teacher distributions.
Where Pith is reading between the lines
- This technique might help in other specialization scenarios such as legal or coding domains.
- It suggests that careful sample selection can be key when prompt coverage is incomplete in distillation.
- Future work could test if the method scales to larger models or more teachers.
Load-bearing premise
That recovery-preservation counteraction from mixed gradients and weak-signal flattening from uniform averaging are the main failure modes with proxy prompts, and alternating training plus gap selection will fix them without new instabilities.
What would settle it
If experiments show that applying CaMOPD leads to decreased domain performance or no gain in general recovery metrics compared to baselines.
Figures

read the original abstract
Domain specialization can improve LLM behavior in vertical domains, but often weakens the general capabilities inherited from the original model. Recent Multi-Teacher On-Policy Distillation (MOPD) pipelines recover model capabilities by supervising student-generated trajectories with teacher feedback, but typically assume teacher-aligned prompt coverage, requiring prompts to match the teachers' training distributions. This assumption is difficult to satisfy when the general teacher is an open-source model whose post-training data are unknown. Instead of attempting to reconstruct this hidden distribution, we study general capability recovery with readily available proxy general prompts. We identify two failure modes of vanilla MOPD in this incomplete-coverage situation: recovery-preservation counteraction from mixing conflicting recovery and preservation gradients, and weak-signal flattening from uniformly averaging samples with unequal correction demand. We propose Counteraction-Aware Multi-Teacher On-Policy Distillation (CaMOPD), which addresses these issues with decoupled alternating training and gap-based sample selection. CaMOPD gives general recovery dedicated updates, periodically reviews domain prompts for preservation, and selects samples with larger averaged token-level teacher-student log-probability gaps to concentrate correction signals. Across role-play dialogue and medical reasoning QA scenarios, CaMOPD performs best in general recovery over baselines while maintaining domain-specific behavior. Gradient coherence analyses further support the intended effect of CaMOPD in producing more coherent correction signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Counteraction-Aware Multi-Teacher On-Policy Distillation (CaMOPD) to recover general capabilities in domain-specialized LLMs when using proxy general prompts that do not match teacher distributions. It identifies two failure modes in vanilla MOPD—recovery-preservation counteraction from mixed gradients and weak-signal flattening from uniform averaging—and proposes decoupled alternating updates, periodic domain-prompt review, and selection of samples with larger averaged token-level teacher-student log-probability gaps. Experiments in role-play dialogue and medical reasoning QA claim that CaMOPD achieves the best general recovery over baselines while preserving domain behavior, with gradient coherence analyses cited as supporting evidence for more coherent correction signals.
Significance. If the empirical results and mechanistic analyses hold, the work addresses a practical constraint in LLM specialization pipelines where teacher post-training data are unavailable, providing a targeted engineering fix for gradient interference in on-policy multi-teacher distillation. The emphasis on sample selection and alternating updates could inform similar recovery methods in other distillation settings.
major comments (2)
- [Method and Experiments] The load-bearing assumption that gap-based selection on averaged token-level log-prob gaps will produce coherent correction signals without correlating to sequence length or outlier difficulty (and thus without introducing new instabilities or degrading domain metrics) is not directly tested; the on-policy setting makes such correlation plausible, yet no ablation or correlation analysis is provided to rule it out. (Method section describing sample selection; Experiments section on role-play and medical QA)
- [Gradient coherence analysis] The gradient coherence analyses are presented as support for reduced interference, but without explicit quantitative comparison (e.g., coherence metrics or interference measures) to the vanilla MOPD baseline or to variants without alternating updates, it is unclear whether they confirm the absence of side effects on domain preservation or sample efficiency. (Gradient coherence analysis subsection)
minor comments (2)
- [Abstract] The abstract states performance advantages but supplies no quantitative results, dataset sizes, or statistical details; moving key metrics (e.g., recovery deltas, domain preservation scores) into the abstract would improve readability.
- [Method] Notation for the averaged token-level log-probability gap should be defined with an equation on first use to avoid ambiguity with other probability quantities.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate the suggested analyses in a revised version.
read point-by-point responses
-
Referee: [Method and Experiments] The load-bearing assumption that gap-based selection on averaged token-level log-prob gaps will produce coherent correction signals without correlating to sequence length or outlier difficulty (and thus without introducing new instabilities or degrading domain metrics) is not directly tested; the on-policy setting makes such correlation plausible, yet no ablation or correlation analysis is provided to rule it out. (Method section describing sample selection; Experiments section on role-play and medical QA)
Authors: We agree that explicit ablations and correlation analyses between the gap-based selection criterion and sequence length or outlier difficulty proxies are not present in the current manuscript. While the reported experiments demonstrate that CaMOPD improves general recovery without harming domain metrics, these specific checks would strengthen the claim that the selection introduces no new instabilities. We will add the requested analyses, including correlation plots and targeted ablations, in the revision. revision: yes
-
Referee: [Gradient coherence analysis] The gradient coherence analyses are presented as support for reduced interference, but without explicit quantitative comparison (e.g., coherence metrics or interference measures) to the vanilla MOPD baseline or to variants without alternating updates, it is unclear whether they confirm the absence of side effects on domain preservation or sample efficiency. (Gradient coherence analysis subsection)
Authors: The gradient coherence subsection provides supporting evidence for the intended effect of decoupled updates and gap-based selection. However, we acknowledge that direct quantitative side-by-side comparisons of coherence and interference metrics against the vanilla MOPD baseline and ablated variants (without alternating updates) are not fully detailed. We will expand the subsection with these explicit quantitative comparisons and additional metrics in the revised manuscript. revision: yes
Circularity Check
Empirical engineering solution with no load-bearing derivations or self-referential reductions
full rationale
The paper identifies two failure modes of vanilla MOPD under proxy general prompts and proposes CaMOPD as an empirical fix via decoupled alternating updates, periodic domain review, and gap-based sample selection. No equations, derivations, or parameter-fitting steps are described that reduce to inputs by construction. The abstract and method are presented as an engineering response to observed issues, with support from experiments and gradient analyses rather than any self-citation chain or uniqueness theorem. This matches the default expectation of no significant circularity for non-derivational empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proxy general prompts can substitute for the unknown post-training distribution of the general teacher when recovering capabilities
Reference graph
Works this paper leans on
-
[1]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Scaling laws for forgetting during finetuning with pretraining data injection. InProceedings of the 42nd International Conference on Machine Learn- ing, volume 267 ofProceedings of Machine Learning Research, pages 4020–4042. PMLR. Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. 2024. HuatuoGPT-o1: ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Revisiting on-policy distillation: Empiri- cal failure modes and simple fixes.arXiv preprint arXiv:2603.25562. GLM-5 Team. 2026. GLM-5: From vibe cod- ing to agentic engineering.arXiv preprint arXiv:2602.15763. Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2024. MiniLLM: Knowledge distillation of large language models. InInternational Conference on Lear...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Rethinking on-policy distillation of large lan- guage models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016. Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. 2025. ZebraLogic: On the scaling limits of LLMs for logical reasoning. InProceedings of the 42nd International ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
LLM-oriented token-adaptive knowledge distillation, 2025
LLM-oriented token-adaptive knowledge distillation. InProceedings of the AAAI Confer- ence on Artificial Intelligence. Also available as arXiv:2510.11615. 10 Wenda Xu, Rujun Han, Zifeng Wang, Long T. Le, Dhruv Madeka, Lei Li, William Yang Wang, Rishabh Agar- wal, Chen-Yu Lee, and Tomas Pfister. 2025. Specu- lative knowledge distillation: Bridging the teac...
-
[5]
Your role is to be [character]
Nemotron-Cascade 2: Post-training LLMs with cascade RL and multi-domain on-policy distilla- tion.arXiv preprint arXiv:2603.19220. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhan...
-
[6]
We use the GBaker/MedQA-USMLE-4-options test split, which contains 1,273 examples in the local cache
is a four-option medical exam benchmark. We use the GBaker/MedQA-USMLE-4-options test split, which contains 1,273 examples in the local cache. The model is prompted as a multiple-choice question-answering system and is required to end with Final answer: <letter> . We extract the predicted option and compute exact-match accu- racy. C Hyperparameter Analysi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.