Scaling, Benchmarking, and Reasoning of Vision-Language Agents for Mobile GUI Navigation
Pith reviewed 2026-06-29 17:19 UTC · model grok-4.3
The pith
Reinforcement-based finetuning outperforms supervised finetuning for vision-language agents navigating mobile GUIs, especially in new domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
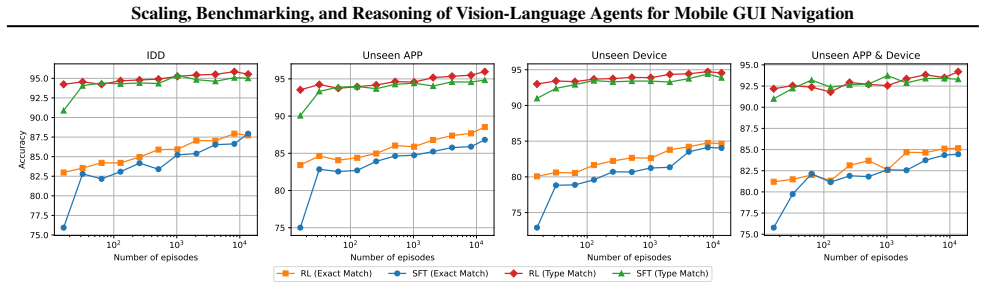
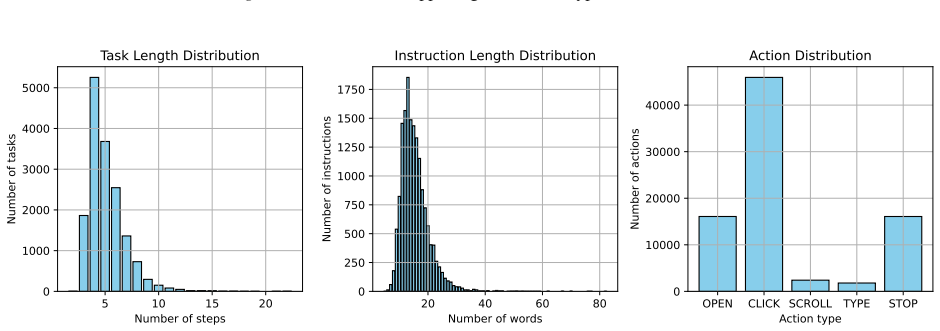
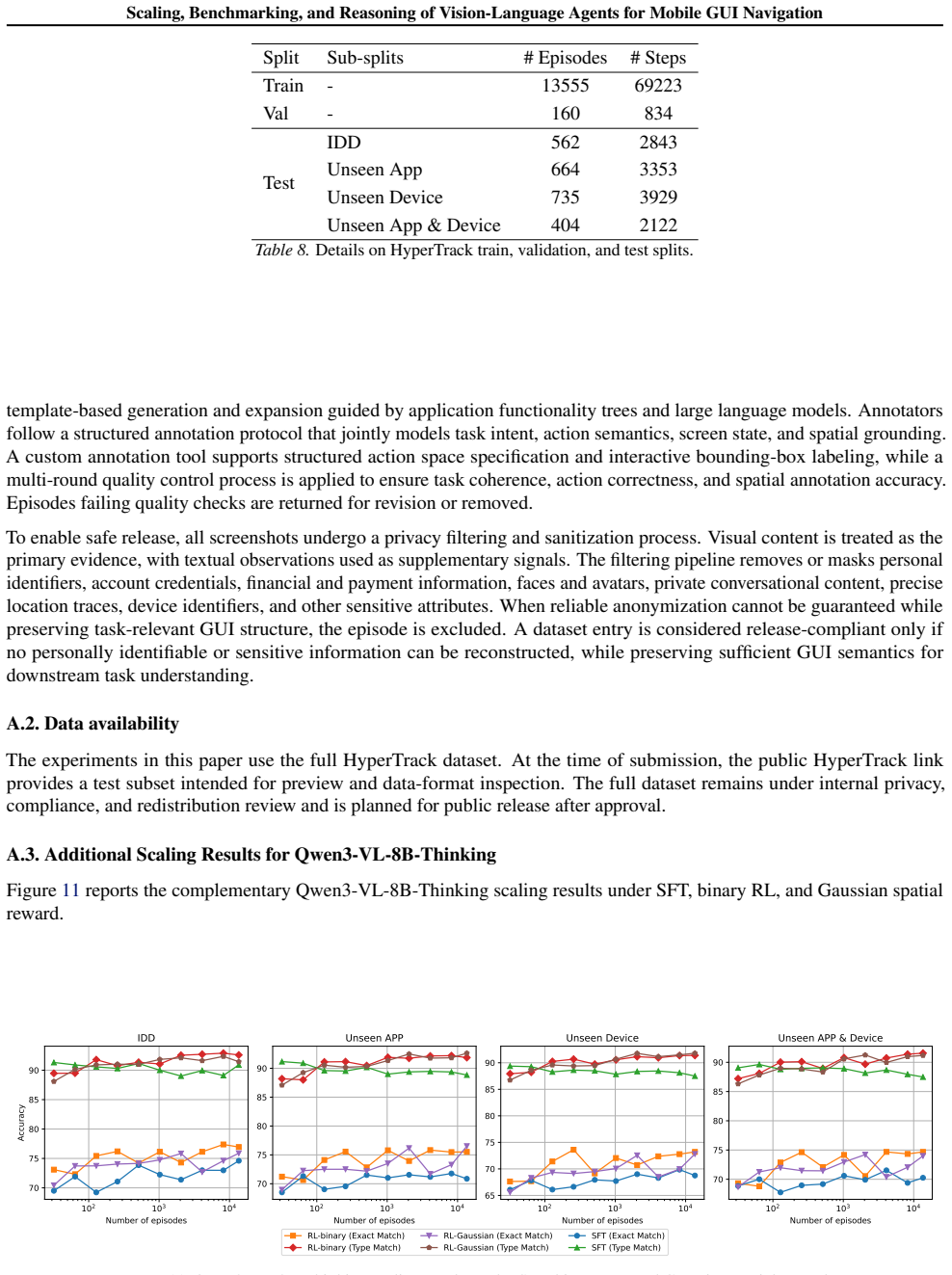
Using the HyperTrack dataset of over 16,000 tasks from more than 650 Chinese mobile applications and the GUIEvalKit benchmark, the paper shows that reinforcement-based finetuning of VLMs consistently outperforms supervised finetuning, with the gap widening in out-of-domain settings, indicating a synergy between data scaling and reinforcement learning for improving agent performance in GUI navigation.
What carries the argument
The comparison of supervised finetuning versus reinforcement-based finetuning on scaled data from the HyperTrack dataset, which carries the argument by showing performance differences in in-domain and out-of-domain tasks.
Load-bearing premise
The 16,000 tasks from Chinese mobile applications represent general real-world GUI navigation challenges, and the offline evaluation in GUIEvalKit measures true agent capability without biases.
What would settle it
A follow-up study collecting tasks from non-Chinese apps and showing that reinforcement finetuning no longer outperforms supervised finetuning on those tasks would falsify the central claim.
Figures

read the original abstract
Vision-Language Models (VLMs) have shown rapid progress in mobile GUI navigation. This paper presents a systematic study of data scaling, benchmarking, and reasoning for VLM-based agents in this domain. To facilitate rigorous evaluation, we introduce HyperTrack, a large-scale dataset with over 16000 real-world tasks across more than 650 Chinese mobile applications, along with GUIEvalKit, an open-source toolkit for unified benchmarking of VLMs on offline GUI navigation tasks. Using HyperTrack, we analyze the effects of training data scale on both supervised and reinforcement-based finetuning. Our results show that reinforcement-based finetuning consistently outperforms supervised finetuning, particularly in out-of-domain settings, highlighting the synergy between data scaling and reinforcement learning. Leveraging GUIEvalKit, we further benchmark state-of-the-art (SOTA) VLMs and analyze how interaction history and reasoning capabilities influence task completion. Together, HyperTrack and GUIEvalKit provide a comprehensive platform for developing and evaluating VLM agents in mobile GUI navigation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyperTrack, a dataset of over 16,000 real-world tasks across 650+ Chinese mobile apps, and GUIEvalKit, an open-source toolkit for offline benchmarking of VLM agents on GUI navigation. It studies effects of data scaling on supervised finetuning versus reinforcement-based finetuning, reports that RL finetuning outperforms SFT (especially OOD), benchmarks SOTA VLMs, and analyzes the impact of interaction history and reasoning capabilities on task completion.
Significance. If the results hold under robust evaluation, the work supplies a large-scale public resource and empirical evidence for the value of RL over SFT in scaling VLM agents for mobile GUI tasks, which could inform future agent training pipelines in this domain.
major comments (1)
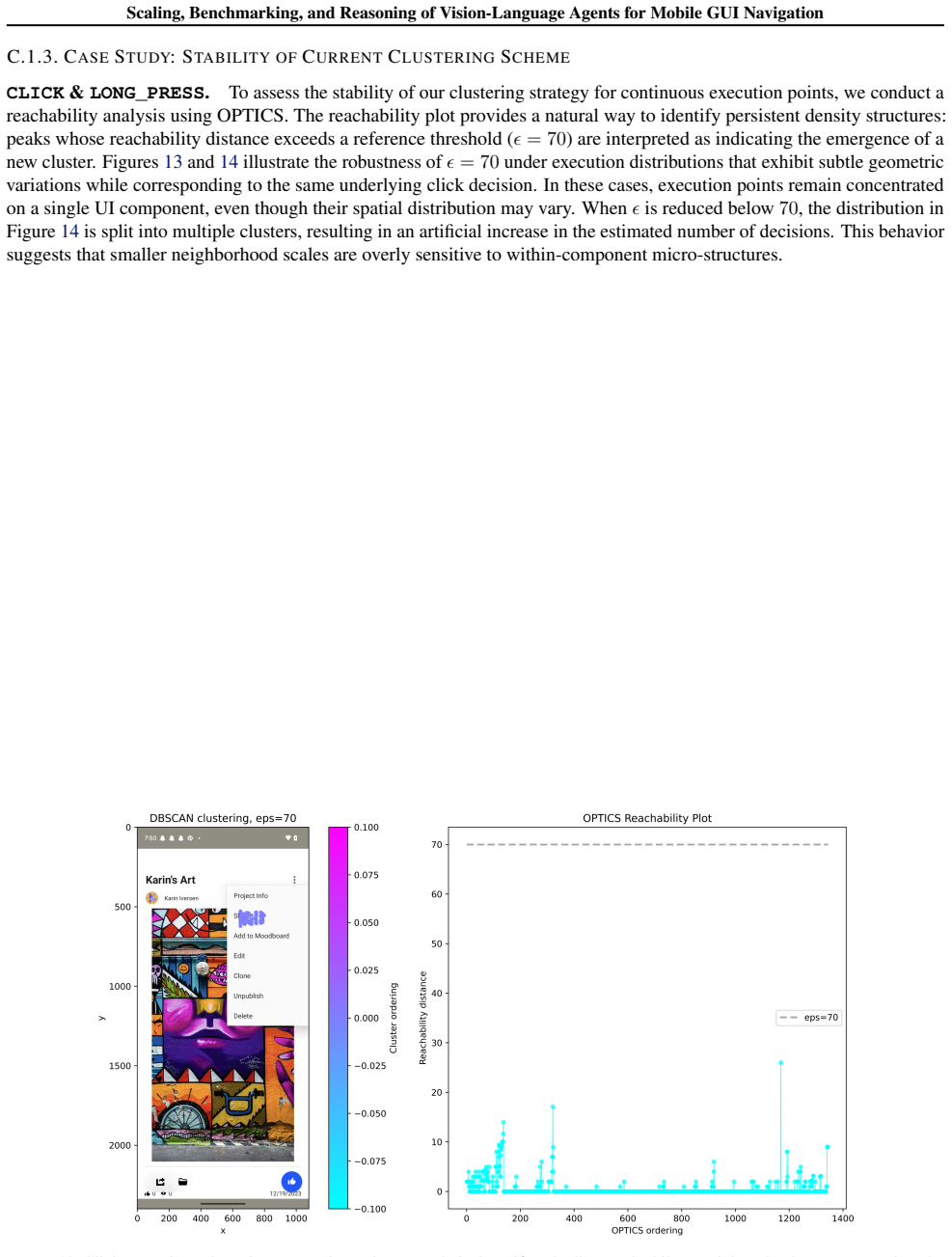
- [GUIEvalKit description and experimental setup] GUIEvalKit / offline evaluation protocol: the central claim that reinforcement-based finetuning outperforms supervised finetuning (especially OOD) rests on automated success metrics whose precise definition is not provided in sufficient detail. If success is computed via exact action-sequence match or final-screen similarity to a single reference trajectory, RL—which directly optimizes reward signals derived from those trajectories—will appear superior by construction even when real-world task completion rates are comparable; the OOD split by app does not automatically eliminate this artifact.
minor comments (2)
- Abstract states performance trends but supplies no quantitative numbers, metrics, statistical tests, or error bars, making it impossible to gauge effect sizes from the summary alone.
- [Dataset construction] The manuscript should clarify how task difficulty and success criteria were validated to be free of hidden biases when collecting the 16,000 tasks from Chinese apps.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the concern on the evaluation protocol below and will revise the manuscript to add the requested detail.
read point-by-point responses
-
Referee: [GUIEvalKit description and experimental setup] GUIEvalKit / offline evaluation protocol: the central claim that reinforcement-based finetuning outperforms supervised finetuning (especially OOD) rests on automated success metrics whose precise definition is not provided in sufficient detail. If success is computed via exact action-sequence match or final-screen similarity to a single reference trajectory, RL—which directly optimizes reward signals derived from those trajectories—will appear superior by construction even when real-world task completion rates are comparable; the OOD split by app does not automatically eliminate this artifact.
Authors: We agree that the current description of the success metric in GUIEvalKit is insufficiently detailed and will expand it in the revision. The metric is implemented as a functional task-completion checker that verifies whether the final app state satisfies the task goal (via screen embedding similarity above a threshold plus verification of critical UI elements or state changes), rather than requiring exact action-sequence or single-trajectory matching. This design intentionally permits multiple valid trajectories. We will add pseudocode, threshold values, and concrete examples of how the checker handles trajectory variation in the GUIEvalKit section. The OOD split (by app) further reduces the risk of leakage because reference trajectories are app-specific and the checker operates on semantic state equivalence, not surface-form matching. We will also report an additional human-verified subset to corroborate the automated metric. revision: yes
Circularity Check
Empirical benchmarking study with no circular derivations
full rationale
The paper is a data-collection and benchmarking study: it introduces HyperTrack (16k tasks from Chinese apps) and GUIEvalKit, then reports experimental comparisons of SFT vs. RL finetuning and VLM benchmarks. No equations, derivations, or fitted parameters are presented whose outputs reduce to the inputs by construction. Central claims rest on new empirical results that are externally falsifiable via the released dataset and toolkit. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Xiaomi-GUI-0 Technical Report
Xiaomi-GUI-0 reports 72.0% success on an in-house real-mobile benchmark and 78.9% on AndroidWorld after training a GUI agent in a real-device closed loop with an error-driven data flywheel and three-stage RL pipeline.
Reference graph
Works this paper leans on
-
[1]
In: Findings of the Association for Computational Linguistics: ACL 2025
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl
-
[2]
URL https://aclanthology.org/2025. findings-acl.110/. Gou, B., Wang, R., Zheng, B., Xie, Y ., Chang, C., Shu, Y ., Sun, H., and Su, Y . Navigating the digital world as humans do: Universal visual grounding for GUI agents. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=kxnoqaisCT. Gu, Z., Z...
-
[3]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Shi, J., Wang, X., He, X., and Chua, T
URL https://doi.org/10.18653/v1/ 2024.findings-emnlp.702. Zhang, Z., Lu, Y ., Fu, Y ., Huo, Y ., Yang, S., Wu, Y ., Si, H., Cong, X., Chen, H., Lin, Y ., Xie, J., Zhou, W., Xu, W., Zhang, Y ., Su, Z., Zhai, Z., Liu, X., Mei, Y ., Xu, J., Tian, H., Wang, C., Chen, C., Yao, Y ., Liu, Z., and Sun, M. AgentCPM-GUI: Building mobile-use agents with rein- forcem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.