Leveraging Visual Signals for Robust Token-Level Uncertainty in Vision-Language Generation
Pith reviewed 2026-06-29 17:49 UTC · model grok-4.3
The pith
High-confidence predictions in vision-language models rely more on visual content than uncertain ones, and weighting token uncertainty by visual grounding scores improves estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
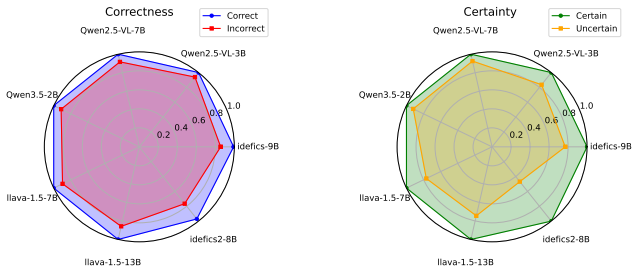
By inspecting hidden states after visual-feature integration, the authors find that high-confidence next-token predictions depend more strongly on the visual stream than low-confidence predictions do; weighting standard token-level language uncertainty by these visual-grounding scores produces a training-free estimator that outperforms language-only baselines on multiple benchmarks and model families.
What carries the argument
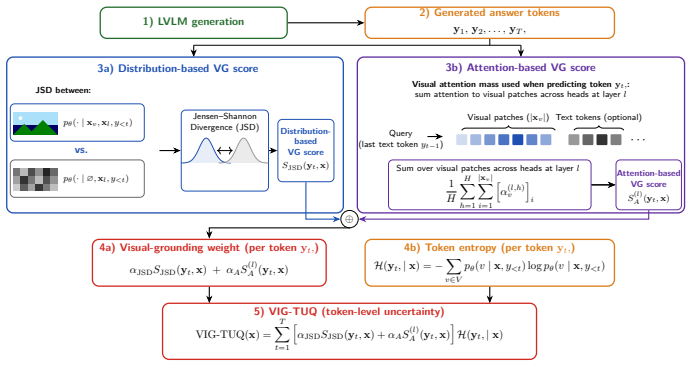
Visual-Grounded Token UQ (VIG-TUQ): a weighting of token-level language uncertainty by visual-grounding scores taken from hidden representations immediately after visual-feature integration.
If this is right
- Token uncertainty estimates become more reliable without any additional training or fine-tuning.
- The improvement holds across early-fusion, late-fusion, and native-fusion LVLM architectures.
- Visual reliance can be quantified at the individual token level during generation.
- Existing language-only uncertainty methods can be upgraded by a post-hoc visual weighting step.
Where Pith is reading between the lines
- Designers of future multimodal models might expose the visual-integration layer explicitly so that downstream uncertainty modules can read it directly.
- The same visual-grounding diagnostic could be applied to other modalities such as audio or sensor data to create modality-balanced uncertainty estimators.
- If the observation generalizes, one could test whether deliberately increasing visual attention in uncertain regions of an image reduces downstream hallucinations.
Load-bearing premise
Visual-grounding scores extracted from hidden representations after visual integration truly measure how much the visual input contributes to each token's confidence.
What would settle it
On a controlled dataset where visual input is deliberately made irrelevant or contradictory, the VIG-TUQ scores would cease to improve uncertainty ranking or calibration relative to the unweighted language baseline.
Figures
read the original abstract
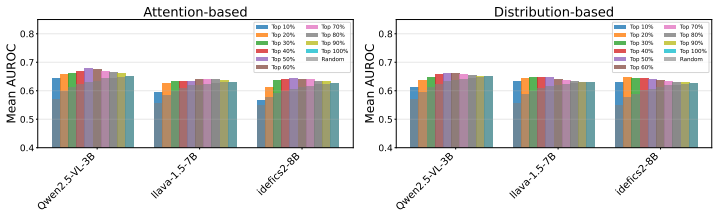
Uncertainty quantification (UQ) remains a critical challenge in Large Vision Language Models (LVLMs) for reliable predictions and real-world deployment. However, most existing methods are adapted from the LLM literature and primarily focus on the language modality, leaving the contribution of visual information to LVLM uncertainty largely underexplored. In this paper, we investigate how LVLMs process visual information and whether this process can be used to improve uncertainty estimation. By analyzing hidden representations after the integration of visual features during the generation process, we observe that high-confidence predictions rely more heavily on visual content than uncertain ones. Building on this insight, we propose Visual-Grounded Token UQ (VIG-TUQ), a training-free framework that explicitly incorporates visual grounding into uncertainty estimation by weighting token-level language uncertainty with visual grounding scores. We evaluate VIG-TUQ on multiple datasets and across diverse LVLM architectures, including early-fusion, late-fusion, and native-fusion models. Results indicate that our method often improves upon existing token-level uncertainty approaches. Code and data will be made available upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that analyzing hidden representations in LVLMs after visual feature integration reveals high-confidence tokens rely more on visual content than uncertain ones; it proposes the training-free VIG-TUQ method that weights token-level language-model uncertainty by derived visual grounding scores, and reports that this often improves uncertainty estimation across multiple datasets and LVLM architectures spanning early-, late-, and native-fusion designs.
Significance. If the central empirical observation and weighting scheme hold after proper controls, the work supplies a concrete, training-free route to inject visual signals into token-level UQ for LVLMs—an underexplored direction relative to language-only adaptations. The explicit cross-architecture evaluation and stated plan to release code are concrete strengths that would aid reproducibility.
major comments (2)
- [Method (VIG-TUQ definition and visual grounding score extraction)] The justification for visual grounding scores rests on the correlation observed in post-integration hidden states, yet the manuscript provides no ablation that subtracts or contrasts against a language-only forward pass (pre-integration states or visual-feature ablation). Without this control, the reported correlation between confidence and the scores could be driven by activation magnitude or internal confidence encoding rather than visual content specifically; this directly affects the load-bearing claim that the scores measure visual reliance and therefore justify the weighting in VIG-TUQ.
- [Experimental results and tables] The abstract and evaluation summary state that VIG-TUQ 'often improves' existing token-level methods, but supply no numerical deltas, standard errors, dataset sizes, or per-model breakdowns. This absence prevents assessment of whether the improvement is consistent, practically meaningful, or robust to the reported diversity of fusion architectures.
minor comments (2)
- [Method] Clarify the precise formula used to compute the visual grounding score from the hidden representations (e.g., which layer, which aggregation over tokens or heads).
- [Introduction / Related Work] Add a short related-work paragraph contrasting VIG-TUQ with prior multimodal UQ attempts that also attempt to leverage cross-modal attention or feature norms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the justification of the visual grounding scores and the clarity of the reported results. We address each major comment below.
read point-by-point responses
-
Referee: [Method (VIG-TUQ definition and visual grounding score extraction)] The justification for visual grounding scores rests on the correlation observed in post-integration hidden states, yet the manuscript provides no ablation that subtracts or contrasts against a language-only forward pass (pre-integration states or visual-feature ablation). Without this control, the reported correlation between confidence and the scores could be driven by activation magnitude or internal confidence encoding rather than visual content specifically; this directly affects the load-bearing claim that the scores measure visual reliance and therefore justify the weighting in VIG-TUQ.
Authors: We agree that the absence of an explicit control comparing post-integration hidden states to pre-integration or language-only forward passes leaves open the possibility that the observed correlation is not uniquely attributable to visual content. Our analysis is deliberately performed on post-integration representations because that is the stage at which visual features are fused; however, this does not rule out confounding factors such as activation magnitude. To strengthen the claim, we will add a new ablation in the revised manuscript that includes a language-only forward pass (visual features zeroed) and reports the resulting correlations with token confidence. This will directly test whether the visual-grounding signal is specific to the integration step. revision: yes
-
Referee: [Experimental results and tables] The abstract and evaluation summary state that VIG-TUQ 'often improves' existing token-level methods, but supply no numerical deltas, standard errors, dataset sizes, or per-model breakdowns. This absence prevents assessment of whether the improvement is consistent, practically meaningful, or robust to the reported diversity of fusion architectures.
Authors: We acknowledge that the abstract and high-level summary employ a qualitative phrasing. The full manuscript already contains per-model and per-dataset tables with numerical results; however, these details are not summarized in the abstract or the evaluation overview. In the revision we will update the abstract and the results summary paragraph to include representative numerical deltas, note the presence of standard errors, and explicitly reference the per-model breakdowns across the three fusion architectures. Dataset sizes are reported in Section 4.1 and will be cross-referenced in the summary for completeness. revision: partial
Circularity Check
No significant circularity; derivation is observation-driven and empirically evaluated
full rationale
The paper's chain begins with an empirical observation on hidden representations after visual integration, uses that to motivate a training-free weighting of language uncertainty by visual grounding scores, and validates via evaluation on multiple datasets and architectures. No equations or definitions reduce the proposed VIG-TUQ scores or improvements to fitted parameters or self-referential inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The method remains falsifiable through external benchmarks and does not rename known results or smuggle ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-confidence predictions rely more heavily on visual content than uncertain ones, observable from hidden representations after visual feature integration.
Reference graph
Works this paper leans on
-
[1]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman
URLhttps://openreview.net/forum?id=c9TWeKZQR4. Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 2018. Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexa...
-
[2]
Sungjae Lee, Hoyoung Kim, Jeongyeon Hwang, Eunhyeok Park, and Jungseul Ok
URLhttps://aclanthology.org/2025.findings-naacl.231/. Sungjae Lee, Hoyoung Kim, Jeongyeon Hwang, Eunhyeok Park, and Jungseul Ok. Efficient latent semantic clustering for scaling test-time computation of llms, 2025b. URL https://arxiv.org/ abs/2506.00344. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinric...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.