Nonlinear Data Integration via Kernel Methods for Data Collaboration Analysis
Pith reviewed 2026-06-29 18:29 UTC · model grok-4.3
The pith
Nonlinear kernel integration aligns decentralized data representations more accurately than linear methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
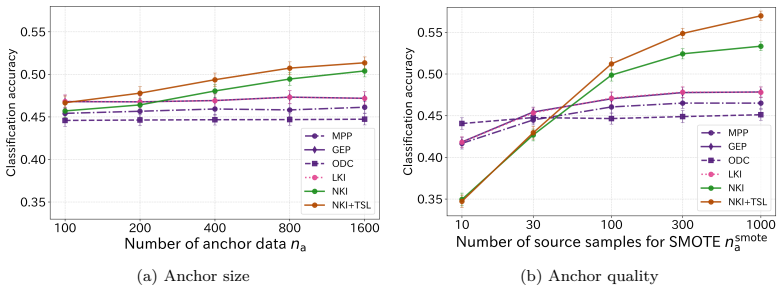
Nonlinear kernel integration admits a globally optimal solution via kernel ridge regression and an eigenvalue problem; when combined with target-variable-aware graph regularization and centering, it produces integrated representations that improve downstream classification accuracy over existing linear integration methods while handling nonlinear dimensionality reduction.
What carries the argument
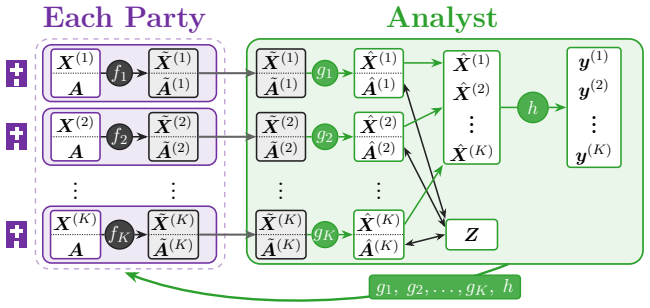
Nonlinear kernel integration (NKI), the kernelized extension of linear kernel integration that aligns nonlinear intermediate representations produced by party-specific obfuscation functions using an anchor dataset.
If this is right
- NKI reaches a globally optimal solution through kernel ridge regression and an eigenvalue problem.
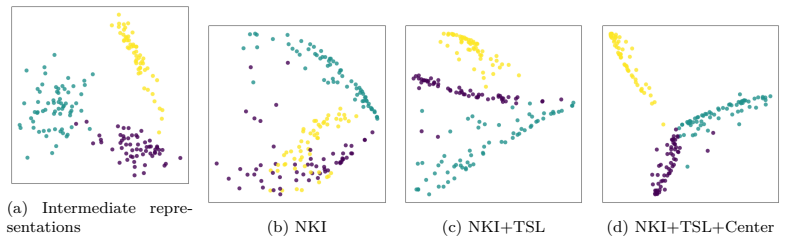
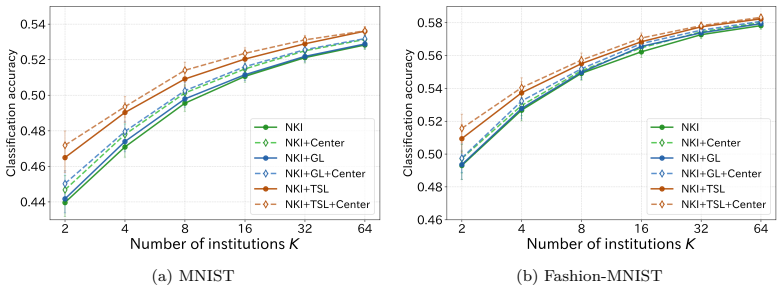
- Target-variable-aware graph regularization and centering further raise classification accuracy.
- Dimensionality reduction choices affect both accuracy and reconstruction risk.
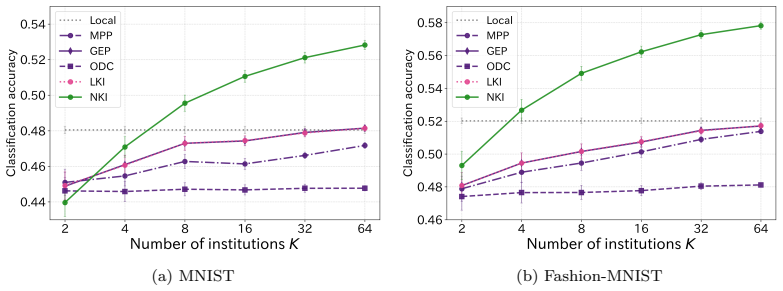
- NKI outperforms linear integration when parties use nonlinear transformations.
Where Pith is reading between the lines
- The same kernelization approach could extend to regression or clustering tasks in decentralized settings.
- Parties might safely choose more aggressive nonlinear obfuscation functions without harming integration quality.
- Adaptive kernel selection based on data properties could be tested as a direct follow-on.
Load-bearing premise
The anchor dataset suffices to align the nonlinear intermediate representations without increasing reconstruction risk or introducing bias in the integrated result.
What would settle it
An experiment in which NKI applied to nonlinear representations yields classification accuracy no higher than linear integration methods on the same image tasks.
Figures

read the original abstract
Collaborative analysis of decentralized confidential datasets is important, but direct sharing of original datasets is often restricted by privacy and institutional constraints. Data collaboration (DC) analysis transforms each dataset into privacy-preserving intermediate representations via party-specific obfuscation functions and integrates them into common collaboration representations using an anchor dataset. However, many existing DC analysis methods rely on linear transformations for data obfuscation and integration, which may increase reconstruction risk. Although nonlinear dimensionality reduction can mitigate this risk, conventional linear integration methods cannot accurately align intermediate representations produced by nonlinear transformations. Moreover, existing integration methods mainly minimize discrepancies among parties and do not explicitly incorporate geometric or target-variable information useful for downstream analysis. To overcome these limitations, we first formulate linear kernel integration (LKI) as a linear integration method and then kernelize it to obtain nonlinear kernel integration (NKI). NKI admits a globally optimal solution via kernel ridge regression and an eigenvalue problem. We also introduce graph regularization and a centering constraint so that the target representation can capture geometric and target-variable information useful for downstream analysis. Experiments on image classification tasks demonstrate that NKI improves classification accuracy over existing linear integration methods under nonlinear dimensionality reduction, with further gains from target-variable-aware graph regularization and centering. The results also show that dimensionality reduction choices substantially affect both classification accuracy and reconstruction risk.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Nonlinear Kernel Integration (NKI) obtained by kernelizing Linear Kernel Integration (LKI) for data collaboration analysis of decentralized datasets. It claims that NKI yields a globally optimal integrated representation via kernel ridge regression and an eigenvalue problem, augmented by target-variable-aware graph regularization and a centering constraint. Experiments on image classification tasks are reported to show accuracy gains over linear integration methods when using nonlinear dimensionality reduction, with dimensionality reduction choices affecting both accuracy and reconstruction risk.
Significance. If the global optimality and unbiased anchor-based alignment hold, the contribution would be significant for privacy-preserving collaborative analysis, as it would enable nonlinear obfuscation without the reconstruction-risk penalty of linear methods while incorporating geometric and label information for downstream tasks.
major comments (2)
- [Abstract] Abstract: the assertion that NKI 'admits a globally optimal solution via kernel ridge regression and an eigenvalue problem' is load-bearing for the central claim, yet no derivation, optimality condition, or closed-form solution is supplied; without it the reduction from the kernelized objective to the stated eigenvalue problem cannot be verified.
- [Abstract] Abstract: the weakest assumption—that an anchor dataset suffices to align party-specific nonlinear obfuscated representations without introducing bias or inflating reconstruction risk—is stated as motivation but receives no formal bound, sensitivity analysis, or ablation; the reported accuracy gains alone do not establish risk-neutrality for arbitrary nonlinear obfuscators.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that NKI 'admits a globally optimal solution via kernel ridge regression and an eigenvalue problem' is load-bearing for the central claim, yet no derivation, optimality condition, or closed-form solution is supplied; without it the reduction from the kernelized objective to the stated eigenvalue problem cannot be verified.
Authors: We agree that an explicit derivation strengthens the central claim. Although the kernelization steps and reduction to the eigenvalue problem appear in Section 3, we will add a dedicated subsection (or appendix) that starts from the kernelized objective, applies the representer theorem and kernel ridge regression, and derives the closed-form optimality condition leading to the eigenvalue problem. This will include all intermediate steps for verifiability. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that an anchor dataset suffices to align party-specific nonlinear obfuscated representations without introducing bias or inflating reconstruction risk—is stated as motivation but receives no formal bound, sensitivity analysis, or ablation; the reported accuracy gains alone do not establish risk-neutrality for arbitrary nonlinear obfuscators.
Authors: We acknowledge that the anchor-dataset assumption would benefit from additional analysis. The current experiments demonstrate practical accuracy gains and controlled reconstruction risk under the tested nonlinear obfuscators, but we will add a sensitivity analysis varying anchor size and selection, plus an ablation on reconstruction risk across different nonlinear methods. A general theoretical bound for arbitrary obfuscators is noted as future work and will be discussed as a limitation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper defines LKI explicitly as a linear integration baseline, then applies the standard kernel trick to obtain NKI, which is solved via kernel ridge regression plus an eigenvalue problem. This is a conventional extension rather than a reduction of the output to the input by construction. Graph regularization and centering are added as explicit constraints with no indication that they are fitted to the target result. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are present in the provided text. The derivation chain remains self-contained against external benchmarks such as standard KRR solvers.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization parameter
axioms (1)
- domain assumption An anchor dataset exists that can align party-specific intermediate representations produced by nonlinear obfuscation functions.
Reference graph
Works this paper leans on
-
[1]
B. Liu, M. Ding, S. Shaham, W. Rahayu, F. Farokhi, Z. Lin, When ma- chine learning meets privacy: A survey and outlook, ACM Computing Surveys (CSUR) 54 (2) (2021) 1–36
2021
-
[2]
B. C. M. Fung, K. Wang, R. Chen, P. S. Yu, Privacy-preserving data publishing: A survey of recent developments, ACM Comput. Surv. 42 (4) (Jun. 2010)
2010
-
[3]
C. J. Hoofnagle, B. van der Sloot, F. Z. Borgesius, The European Union general data protection regulation: What it is and what it means, In- formation & Communications Technology Law 28 (1) (2019) 65–98. 44
2019
- [4]
-
[5]
Dwork, A
C. Dwork, A. Roth, The algorithmic foundations of differential privacy, Found. Trends Theor. Comput. Sci. 9 (34) (2014) 211407
2014
-
[6]
Dwork, Differential privacy: A survey of results, in: International Conference on Theory and Applications of Models of Computation, Springer, 2008, pp
C. Dwork, Differential privacy: A survey of results, in: International Conference on Theory and Applications of Models of Computation, Springer, 2008, pp. 1–19
2008
-
[7]
Balle, Y.-X
B. Balle, Y.-X. Wang, Improving the Gaussian mechanism for differen- tial privacy: Analytical calibration and optimal denoising, in: Proceed- ings of the 35th International Conference on Machine Learning, Vol. 80 of Proceedings of Machine Learning Research, PMLR, 2018, pp. 394– 403
2018
-
[8]
A. C. Yao, Protocols for secure computations, in: 23rd Annual Sympo- sium on Foundations of Computer Science (SFCS 1982), IEEE, 1982, pp. 160–164
1982
-
[9]
Martins, L
P. Martins, L. Sousa, A. Mariano, A survey on fully homomorphic encryption: An engineering perspective, ACM Computing Surveys (CSUR) 50 (6) (2017) 1–33
2017
-
[10]
A. Acar, H. Aksu, A. S. Uluagac, M. Conti, A survey on homomorphic encryption schemes: Theory and implementation, ACM Computing Sur- veys (CSUR) 51 (4) (2018) 1–35
2018
-
[11]
McMahan, E
B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, Communication-efficient learning of deep networks from decentralized data, in: Artificial Intelligence and Statistics, PMLR, 2017, pp. 1273– 1282
2017
-
[12]
Federated Learning: Strategies for Improving Communication Efficiency
J. Konečn` y, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh, D. Bacon, Federated learning: Strategies for improving communication efficiency, arXiv preprint arXiv:1610.05492 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
Q. Li, Z. Wen, Z. Wu, S. Hu, N. Wang, Y. Li, X. Liu, B. He, A survey on federated learning systems: Vision, hype and reality for data privacy 45 and protection, IEEE Transactions on Knowledge and Data Engineering 35 (4) (2023) 3347–3366
2023
-
[14]
Kairouz, H
P. Kairouz, H. B. McMahan, B. A vent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, et al., Advances and open problems in federated learning, Foundations and Trends® in Machine Learning 14 (1–2) (2021) 1–210
2021
-
[15]
Imakura, T
A. Imakura, T. Sakurai, Data collaboration analysis framework using centralization of individual intermediate representations for distributed data sets, ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part A: Civil Engineering 6 (2) (2020) 04020018
2020
-
[16]
Imakura, X
A. Imakura, X. Ye, T. Sakurai, Collaborative data analysis: Non-model sharing-type machine learning for distributed data, in: Knowledge Man- agement and Acquisition for Intelligent Systems, Springer, 2021, pp. 14–29
2021
-
[17]
X. Wang, S. Ranellucci, J. Katz, Global-scale secure multiparty com- putation, in: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 39–56
2017
-
[18]
Ben-Efraim, Y
A. Ben-Efraim, Y. Lindell, E. Omri, Optimizing semi-honest secure mul- tiparty computation for the internet, in: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016, pp. 578–590
2016
-
[19]
Gascon, P
A. Gascon, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Za- hur, D. Evans, Privacy-preserving distributed linear regression on high- dimensional data, Cryptology ePrint Archive, Paper 2016/892 (2016)
2016
-
[20]
B. D. Rouhani, M. S. Riazi, F. Koushanfar, Deepsecure: Scal- able provably-secure deep learning, Cryptology ePrint Archive, Paper 2017/502 (2017)
2017
-
[21]
Q. Li, Y. Diao, Q. Chen, B. He, Federated learning on non-iid data silos: An experimental study, in: 2022 IEEE 38th International Conference on Data Engineering (ICDE), IEEE, 2022, pp. 965–978
2022
- [22]
-
[23]
T. Li, A. K. Sahu, A. Talwalkar, V. Smith, Federated learning: Chal- lenges, methods, and future directions, IEEE Signal Processing Maga- zine 37 (3) (2020) 50–60
2020
-
[24]
L. Zhu, Z. Liu, S. Han, Deep leakage from gradients, in: Advances in Neural Information Processing Systems, Vol. 32, 2019, pp. 14774–14784
2019
-
[25]
Bonawitz, V
K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, K. Seth, Practical secure aggregation for privacy-preserving machine learning, in: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191
2017
-
[26]
Mendes, J
R. Mendes, J. P. Vilela, Privacy-preserving data mining: Methods, met- rics, and applications, IEEE Access 5 (2017) 10562–10582
2017
-
[27]
Bingham, H
E. Bingham, H. Mannila, Random projection in dimensionality reduc- tion: Applications to image and text data, in: Proceedings of the Sev- enth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2001, pp. 245–250
2001
-
[28]
K. Chen, L. Liu, Privacy preserving data classification with rotation perturbation, in: Fifth IEEE International Conference on Data Mining (ICDM’05), 2005, pp. 589–592
2005
-
[29]
K. Liu, H. Kargupta, J. Ryan, Random projection-based multiplicative data perturbation for privacy preserving distributed data mining, IEEE Transactions on Knowledge and Data Engineering 18 (1) (2006) 92–106
2006
-
[30]
K. Liu, C. Giannella, H. Kargupta, A survey of attack techniques on privacy-preserving data perturbation methods, in: C. C. Aggarwal, P. S. Yu (Eds.), Privacy-Preserving Data Mining: Models and Algorithms, Springer US, Boston, MA, 2008, pp. 359–381
2008
-
[31]
Jiang, R
L. Jiang, R. Tan, X. Lou, G. Lin, On lightweight privacy-preserving col- laborative learning for internet-of-things objects, in: Proceedings of the International Conference on Internet of Things Design and Implemen- tation, 2019, pp. 70–81. 47
2019
-
[32]
A. Imakura, A. Bogdanova, T. Yamazoe, K. Omote, T. Sakurai, Ac- curacy and privacy evaluations of collaborative data analysis, arXiv preprint arXiv:2101.11144 (2021)
-
[33]
Yamashiro, K
H. Yamashiro, K. Omote, A. Imakura, T. Sakurai, Toward the applica- tion of differential privacy to data collaboration, IEEE Access 12 (2024) 63292–63301
2024
-
[34]
A. Imakura, T. Sakurai, FedDCL: a federated data collaboration learn- ing as a hybrid-type privacy-preserving framework based on federated learning and data collaboration, arXiv preprint arXiv:2409.18356 (2024)
-
[35]
Kawamata, R
Y. Kawamata, R. Motai, Y. Okada, A. Imakura, T. Sakurai, Collabo- rative causal inference on distributed data, Expert Systems with Appli- cations 244 (2024) 123024
2024
-
[36]
Nakayama, Y
T. Nakayama, Y. Kawamata, A. Toyoda, A. Imakura, R. Kagawa, M. Sanuki, R. Tsunoda, K. Yamagata, T. Sakurai, Y. Okada, Data collaboration for causal inference from limited medical testing and med- ication data, Scientific Reports 15 (1) (2025) 9827
2025
-
[37]
Imakura, R
A. Imakura, R. Tsunoda, R. Kagawa, K. Yamagata, T. Sakurai, DC- COX: Data collaboration cox proportional hazards model for privacy- preserving survival analysis on multiple parties, Journal of Biomedical Informatics 137 (2023) 104264
2023
-
[38]
Bogdanova, A
A. Bogdanova, A. Imakura, T. Sakurai, DC-SHAP method for consis- tent explainability in privacy-preserving distributed machine learning, Human-Centric Intelligent Systems 3 (3) (2023) 197–210
2023
-
[39]
Yanagi, S
T. Yanagi, S. Ikeda, N. Sukegawa, Y. Takano, Privacy-preserving rec- ommender system using the data collaboration analysis for distributed datasets, PLoS ONE 20 (4) (2025) e0319954
2025
-
[40]
Kawamata, K
Y. Kawamata, K. Kamijo, M. Kihira, A. Toyoda, T. Nakayama, A. Imakura, T. Sakurai, Y. Okada, A new type of federated cluster- ing: A non-model-sharing approach (2025)
2025
-
[41]
Imakura, T
A. Imakura, T. Sakurai, Y. Okada, T. Fujii, T. Sakamoto, H. Abe, Non-readily identifiable data collaboration analysis for multiple datasets including personal information, Information Fusion 98 (2023) 101826. 48
2023
-
[42]
Bogdanova, A
A. Bogdanova, A. Nakai, Y. Okada, A. Imakura, T. Sakurai, Federated learning system without model sharing through integration of dimen- sional reduced data representations (2020)
2020
-
[43]
Imakura, H
A. Imakura, H. Inaba, Y. Okada, T. Sakurai, Interpretable collaborative data analysis on distributed data, Expert Systems with Applications 177 (2021) 114891
2021
-
[44]
Nosaka, Y
K. Nosaka, Y. Suetake, Y. Takano, A. Yoshise, Data collaboration anal- ysis with orthonormal basis selection and alignment, Computers and Electrical Engineering 135 (2026) 111192
2026
-
[45]
Kawakami, Y
Y. Kawakami, Y. Takano, A. Imakura, New solutions based on the generalized eigenvalue problem for the data collaboration analysis, In- formation Sciences 723 (2025) 122642
2025
-
[46]
Mashiko, Y
S. Mashiko, Y. Kawamata, T. Nakayama, T. Sakurai, Y. Okada, Anomaly detection in double-entry bookkeeping data by federated learn- ing system with non-model sharing approach, Scientific Reports 15 (1) (2025) 42208
2025
-
[47]
G. E. Hinton, R. R. Salakhutdinov, Reducing the dimensionality of data with neural networks, Science 313 (5786) (2006) 504507
2006
-
[48]
Fan, On a theorem of Weyl concerning eigenvalues of linear trans- formations I, Proceedings of the National Academy of Sciences 35 (11) (1949) 652–655
K. Fan, On a theorem of Weyl concerning eigenvalues of linear trans- formations I, Proceedings of the National Academy of Sciences 35 (11) (1949) 652–655
1949
-
[49]
S. Yan, D. Xu, B. Zhang, H.-J. Zhang, Q. Yang, S. Lin, Graph embed- ding and extensions: A general framework for dimensionality reduction, IEEE Transactions on Pattern Analysis and Machine Intelligence 29 (1) (2007) 40–51
2007
-
[50]
Belkin, P
M. Belkin, P. Niyogi, Laplacian eigenmaps for dimensionality reduction and data representation, Neural Computation 15 (6) (2003) 13731396
2003
-
[51]
X. He, P. Niyogi, Locality preserving projections, in: Advances in Neural Information Processing Systems, Vol. 16, 2003, pp. 153–160
2003
-
[52]
Deng, The mnist database of handwritten digit images for machine learning research [best of the web], IEEE signal processing magazine 29 (6) (2012) 141–142
L. Deng, The mnist database of handwritten digit images for machine learning research [best of the web], IEEE signal processing magazine 29 (6) (2012) 141–142. 49
2012
-
[53]
H. Xiao, K. Rasul, R. Vollgraf, Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms, arXiv preprint arXiv:1708.07747 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
McInnes, J
L. McInnes, J. Healy, J. Melville, UMAP: Uniform manifold approxima- tion and projection for dimension reduction (2020)
2020
-
[55]
Imakura, M
A. Imakura, M. Kihira, Y. Okada, T. Sakurai, Another use of smote for interpretable data collaboration analysis, Expert Systems with Applica- tions 228 (2023) 120385
2023
-
[56]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, et al., Scikit-learn: Machine learning in python, Journal of Machine Learning Research 12 (2011) 2825–2830
2011
-
[57]
Schölkopf, R
B. Schölkopf, R. Herbrich, A. J. Smola, A generalized representer the- orem, in: Proceedings of the 14th Annual Conference on Computa- tional Learning Theory and 5th European Conference on Computational Learning Theory, 2001, pp. 416–426
2001
-
[58]
Torres-Sospedra, R
J. Torres-Sospedra, R. Montoliu, A. Martínez-Usó, T. Arnau, J. A vari- ento, UJIIndoorLoc, UCI Machine Learning Repository (2014)
2014
-
[59]
Graf, H.-P
F. Graf, H.-P. Kriegel, M. Schubert, S. Pölsterl, A. Cavallaro, Relative location of CT slices on axial axis, UCI Machine Learning Repository (2011). 50
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.