Temporal Simultaneity Predicts Annotation Quality in Sentiment Corpora
Pith reviewed 2026-06-29 18:16 UTC · model grok-4.3
The pith
The time gap between when annotators label the same tweet is the strongest predictor of their agreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
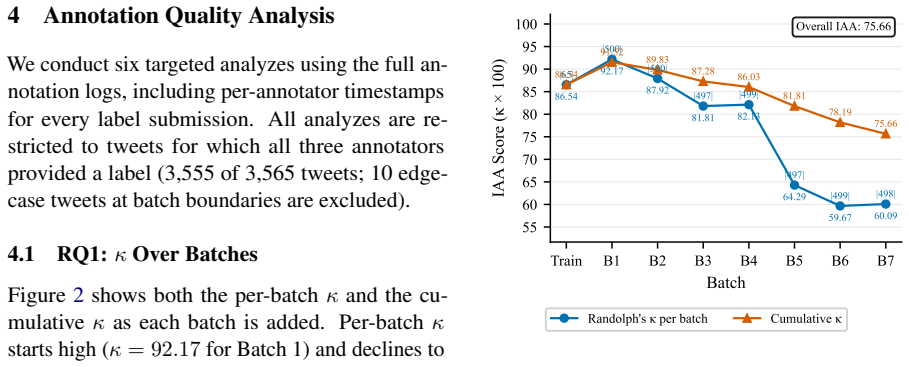
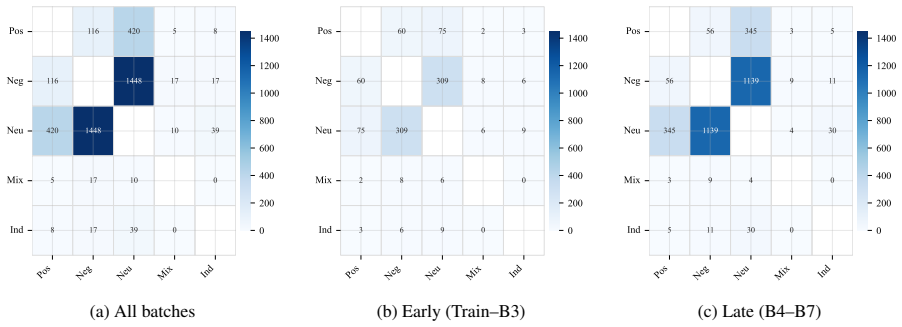
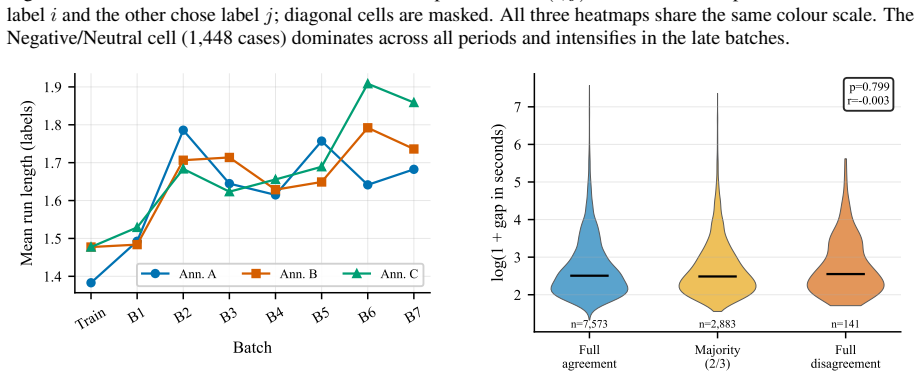
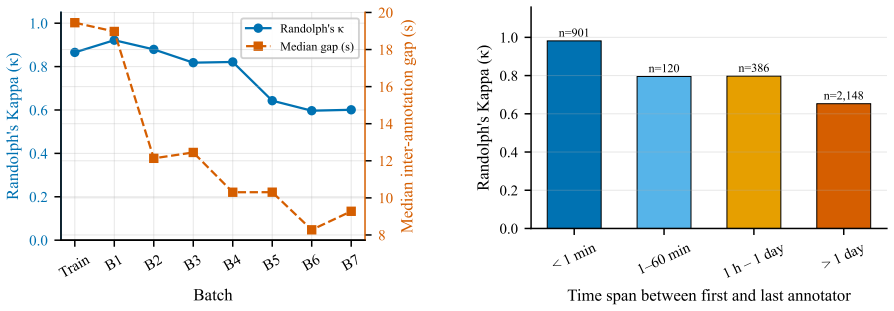
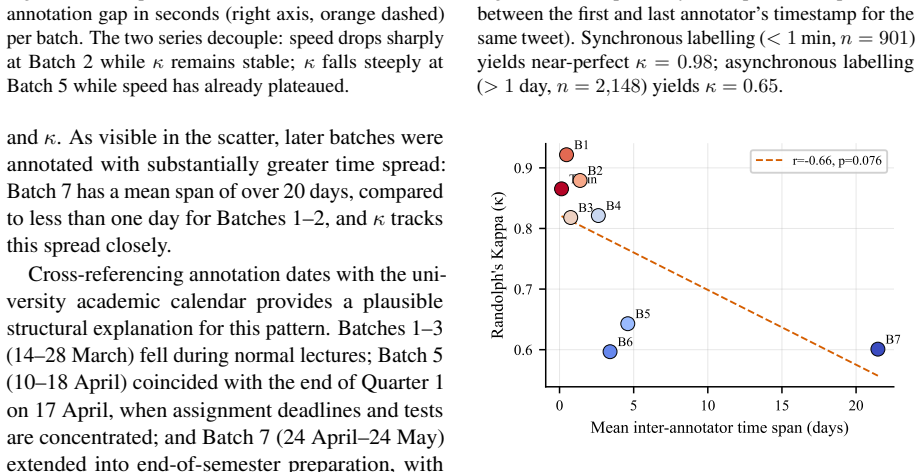
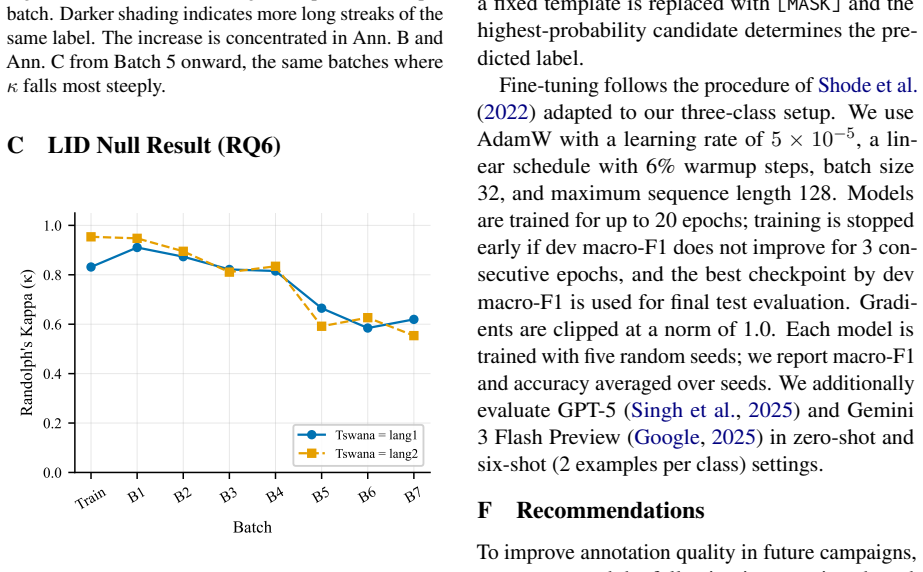
The dominant predictor of inter-annotator agreement is temporal simultaneity: tweets labeled within one minute achieve κ = 0.98, while those labeled more than a day apart reach only κ = 0.65. Annotation speed and tweet-level linguistic features show no meaningful association with κ. Per-batch kappa declines across the task, label confusion concentrates on the negative/neutral boundary, and two annotators exhibit run-length drift.
What carries the argument
temporal simultaneity, defined as the elapsed time between different annotators labeling the identical tweet
If this is right
- Annotation campaigns should schedule simultaneous labeling to sustain high agreement.
- Label confusion is concentrated at the negative/neutral boundary.
- Some annotators exhibit run-length drift consistent with autopilot labeling.
- Fine-tuning yields 29 to 43 macro-F1 gains over pretrained baselines on the three-class task.
- GPT-5 few-shot reaches the highest performance at 62.2 macro-F1.
Where Pith is reading between the lines
- Releasing per-annotation timestamps enables future datasets to audit for similar temporal quality loss.
- High-agreement subsets filtered by short time gaps could serve as cleaner training data for models.
- The pattern may appear in other low-resource annotation projects that span weeks or months.
- Protocols that enforce same-day labeling could reduce the need for post-hoc quality filtering.
Load-bearing premise
The measured time gaps between annotations reflect a genuine effect on consistency rather than unmeasured differences in tweet difficulty or label distributions across batches.
What would settle it
Re-labeling the same tweets while deliberately randomizing the time intervals between annotators and finding no corresponding change in kappa values would falsify the central claim.
Figures
read the original abstract
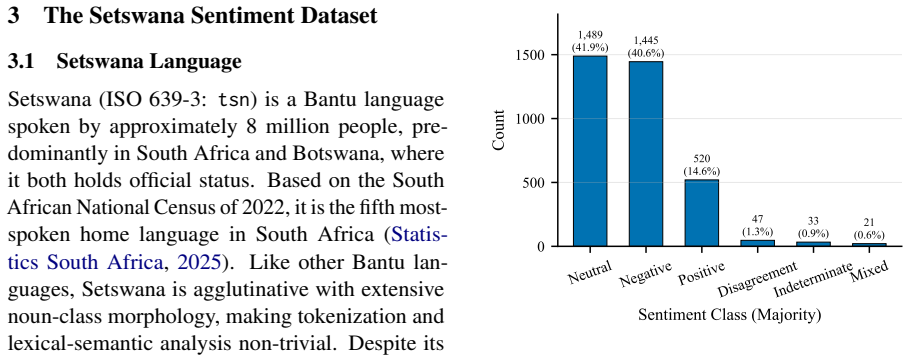
Annotation quality is difficult to sustain when campaigns span weeks or months with small annotator pools. We present a Setswana sentiment dataset of 3,565 tweets annotated by three native-speaker annotators across eight batches and examine why inter-annotator agreement (IAA) declines over time. Despite an aggregate Randolph's free-marginal Kappa of $\kappa = 0.76$, "excellent," per-batch $\kappa$ falls by more than 32 points across the annotation task. Through six targeted analyses, we find that (i) label confusion concentrates on the negative/neutral boundary, (ii) two annotators show run-length drift consistent with autopilot labeling, and (iii) the dominant predictor of $\kappa$ is temporal simultaneity: tweets labeled within one minute achieve $\kappa = 0.98$, while those labeled more than a day apart reach only $\kappa = 0.65$. Annotation speed and tweet-level linguistic features show no meaningful association with $\kappa$. We benchmark three open multilingual encoders and proprietary models (GPT-5 and Gemini) on three-class sentiment classification; fine-tuning yields gains of 29 to 43 macro-F1 points over pretrained baselines, with GPT-5 few-shot leading overall (62.2 macro-F1). We release the dataset, per-annotation timestamps, and analysis code to support reproducible quality auditing for future African language NLP resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Setswana sentiment dataset of 3,565 tweets annotated by three native-speaker annotators across eight sequential batches. It reports an aggregate Randolph's free-marginal kappa of 0.76 that declines by more than 32 points across batches. Through six analyses the authors conclude that temporal simultaneity is the dominant predictor of per-tweet kappa (0.98 for labels within one minute versus 0.65 for labels more than one day apart), while annotation speed and tweet-level linguistic features show no association. The work also benchmarks multilingual encoders and proprietary models on three-class sentiment classification and releases the dataset, per-annotation timestamps, and analysis code.
Significance. If the reported temporal-simultaneity effect survives explicit controls for batch identity, the finding would be a concrete, actionable contribution to annotation-quality management in long-running campaigns, especially for low-resource languages. The public release of timestamps and reproducible code is a clear strength that enables independent verification and extension.
major comments (2)
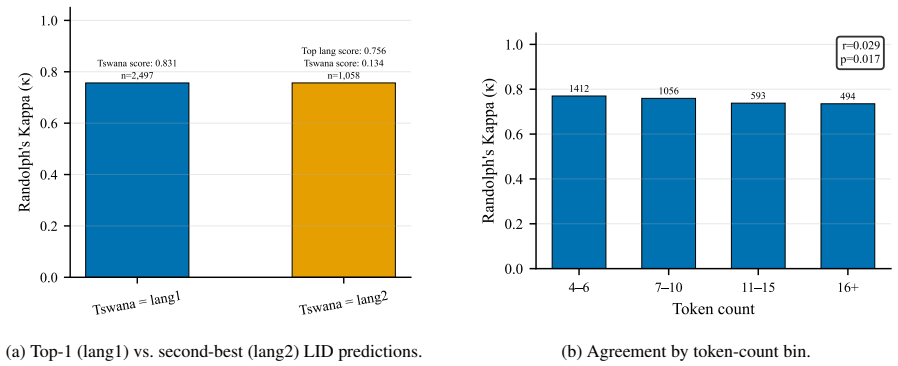
- [Abstract] Abstract: the central claim that temporal simultaneity is the dominant predictor of κ (0.98 vs. 0.65) is load-bearing. Because the eight batches are sequential and per-batch κ already declines >32 points, tweet pairs separated by >1 day are disproportionately likely to straddle batches. The manuscript does not report batch fixed effects, within-batch temporal stratification, or a regression of κ on time conditional on batch; without such a control the simultaneity variable may simply proxy unmeasured batch-level shifts in label distribution, annotator drift, or tweet difficulty.
- [Abstract] Abstract (six targeted analyses): the claim that annotation speed and tweet-level linguistic features show “no meaningful association” with κ is presented without the analogous check against batch identity. A direct comparison of the strength of the simultaneity predictor versus a batch-identity predictor is required to establish dominance.
minor comments (1)
- [Abstract] Abstract: the model name “GPT-5” should be clarified (current model family or placeholder) and the exact few-shot and fine-tuning protocols should be summarized with the number of shots and training examples.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need to explicitly control for batch identity when assessing the dominance of temporal simultaneity. We agree that the current analyses require these controls to strengthen the central claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that temporal simultaneity is the dominant predictor of κ (0.98 vs. 0.65) is load-bearing. Because the eight batches are sequential and per-batch κ already declines >32 points across batches. The manuscript does not report batch fixed effects, within-batch temporal stratification, or a regression of κ on time conditional on batch; without such a control the simultaneity variable may simply proxy unmeasured batch-level shifts in label distribution, annotator drift, or tweet difficulty.
Authors: We agree that the manuscript does not currently report batch fixed effects, within-batch stratification, or a conditional regression of κ on time. In revision we will add a linear regression of per-tweet κ on temporal separation that includes batch identity as a fixed effect, together with within-batch temporal stratification. These additions will test whether the simultaneity effect remains after accounting for batch-level variation. revision: yes
-
Referee: [Abstract] Abstract (six targeted analyses): the claim that annotation speed and tweet-level linguistic features show “no meaningful association” with κ is presented without the analogous check against batch identity. A direct comparison of the strength of the simultaneity predictor versus a batch-identity predictor is required to establish dominance.
Authors: We acknowledge that the manuscript lacks a direct comparison of predictor strength between temporal simultaneity and batch identity. We will add this comparison (via regression coefficients or incremental R²) and will also re-evaluate the null associations for annotation speed and linguistic features after including batch fixed effects, to confirm that the reported dominance holds under these controls. revision: yes
Circularity Check
No significant circularity: temporal bins use independent timestamps; κ computed directly from labels.
full rationale
The paper's central claim rests on binning tweet pairs by annotation timestamp differences (independent data) and computing Randolph's κ within each bin. No equations, definitions, or self-citations reduce the reported κ values (0.98 within 1 min, 0.65 after 1 day) to quantities fitted from or defined by the agreement metric itself. The analysis is an empirical stratification against external timestamp records and does not invoke fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatz smuggling. Batch confounds are a validity concern but do not constitute circularity under the specified criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Randolph's free-marginal kappa provides a valid measure of inter-annotator agreement beyond chance
Reference graph
Works this paper leans on
-
[1]
Evaluating the capabilities of large language models for multi-label emotion understanding. In Proceedings of the 31st International Conference on Computational Linguistics, pages 3523–3540, Abu Dhabi, UAE. Association for Computational Linguis- tics. Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and Psychological Mea- surem...
work page internal anchor Pith review Pith/arXiv arXiv 1960
-
[2]
Confident learning: Estimating uncertainty in dataset labels. InJournal of Artificial Intelligence Research, volume 70, pages 1373–1411. Kelechi Ogueji, Yuxin Zhu, and Jimmy Lin. 2021. Small data? no problem! exploring the viability of pretrained multilingual language models for low- resourced languages. InProceedings of the 1st Work- shop on Multilingual...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Where feasible, shared online annotation sessions, where all annotators label the same tweets in real time, could bring κ closer to the ≥0.98 we observe for the < 1min group
Maximize temporal simultaneity.Requiring all annotators to complete each batch within a short fixed window (e.g., 48 hours) would reduce mean inter-annotator time spans and is the single highest-leverage intervention our results support. Where feasible, shared online annotation sessions, where all annotators label the same tweets in real time, could bring...
-
[4]
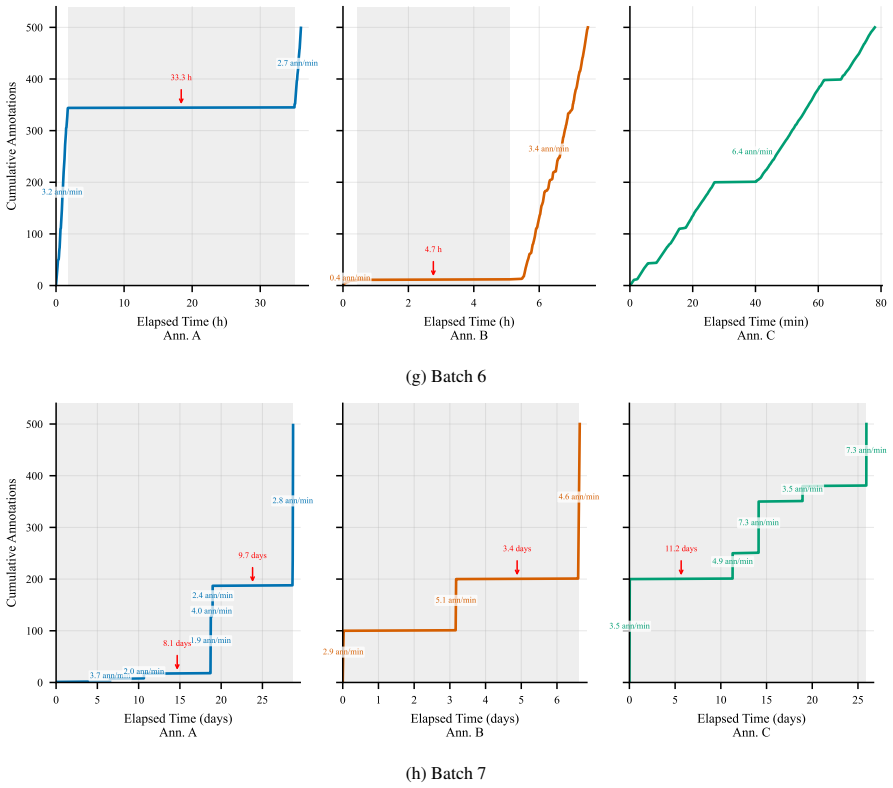
Mean run length is detectable before a batch is finalized and requires only the annotation 0 10 20 30 40 Elapsed Time (min) Ann
Monitor run lengths between batches. Mean run length is detectable before a batch is finalized and requires only the annotation 0 10 20 30 40 Elapsed Time (min) Ann. A 0 10 20 30 40 50 60 70 Cumulative Annotations 1.6 ann/min 0 10 20 30 40 Elapsed Time (min) Ann. B 1.6 ann/min 0 5 10 15 20 Elapsed Time (min) Ann. C 2.9 ann/min (a) Training batch 0 20 40 6...
-
[5]
0 1 2 3 4 Elapsed Time (days) Ann
Include periodic calibration items.Re- annotating a small fixed set from the training batch at the start of each new proper annota- tion batch provides an early-warning signal of label drift and allows re-calibration before it compounds. 0 1 2 3 4 Elapsed Time (days) Ann. A 0 100 200 300 400 500 Cumulative Annotations 1.7 ann/min 2.6 ann/min 3.1 ann/min 4...
-
[6]
Aggregate κ over a multi-batch campaign can be misleadingly high even when the fi- nal batches are severely degraded
Report per-batch κ as standard practice. Aggregate κ over a multi-batch campaign can be misleadingly high even when the fi- nal batches are severely degraded. We rec- ommend per-batch κ as a mandatory element of annotation quality reporting in African- language NLP dataset papers. 0 10 20 30 Elapsed Time (h) Ann. A 0 100 200 300 400 500 Cumulative Annotat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.