PilotTTS: A Disciplined Modular Recipe for Competitive Speech Synthesis
Pith reviewed 2026-06-29 15:48 UTC · model grok-4.3
The pith
PilotTTS shows a lightweight TTS model trained on 200K hours of openly processed data can lead on error rates and speaker similarity benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PilotTTS demonstrates that a minimalist autoregressive TTS architecture combined with rigorous open-source data engineering can deliver state-of-the-art zero-shot voice cloning and style-controlled synthesis, achieving the lowest WER of 1.50% on test-en, a CER of 0.87% on test-zh, and the highest speaker similarity on both test sets (0.862 and 0.815), outperforming systems trained on significantly larger datasets.
What carries the argument
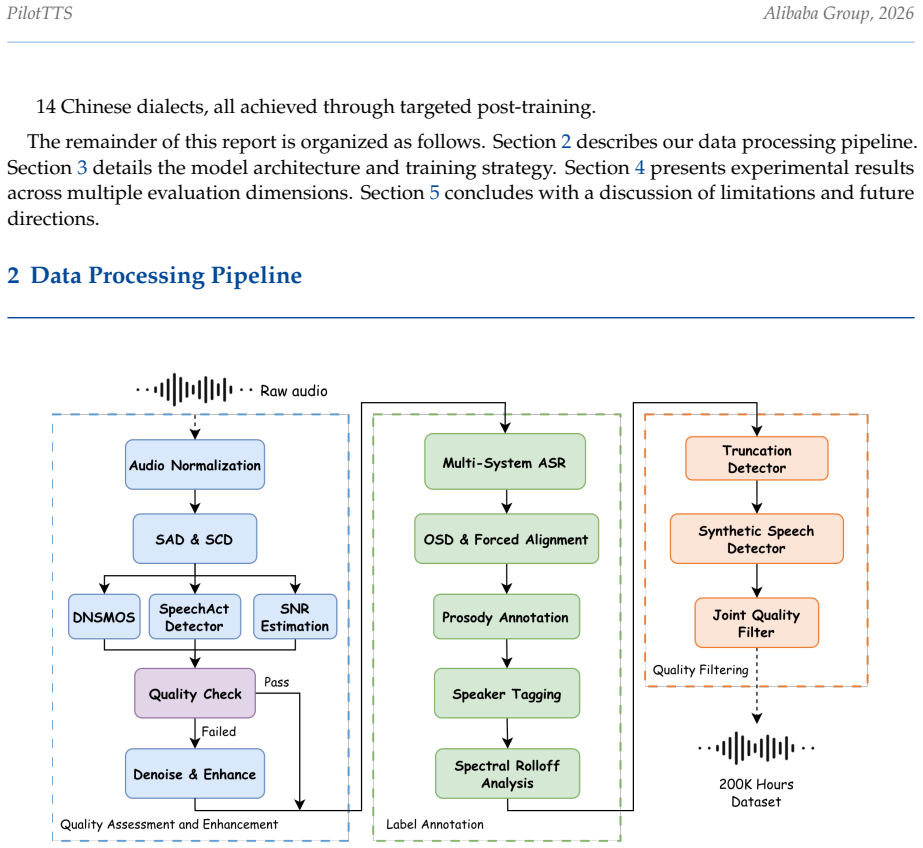
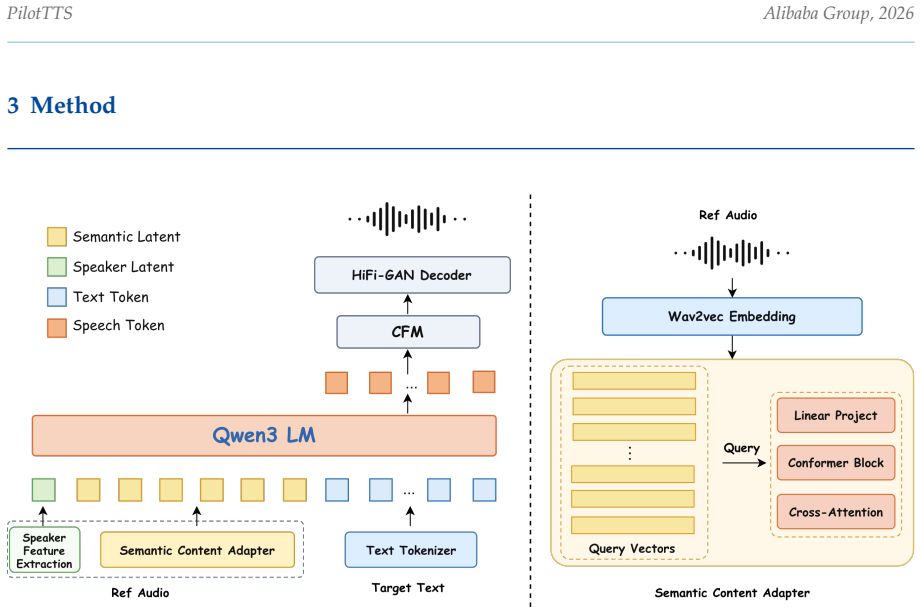
Q-Former-based conditioning that decouples speaker identity from speaking style through cross-sample paired training, supported by a multi-stage open-source data processing pipeline.
If this is right
- Teams can apply the open data pipeline to reach comparable performance without proprietary datasets.
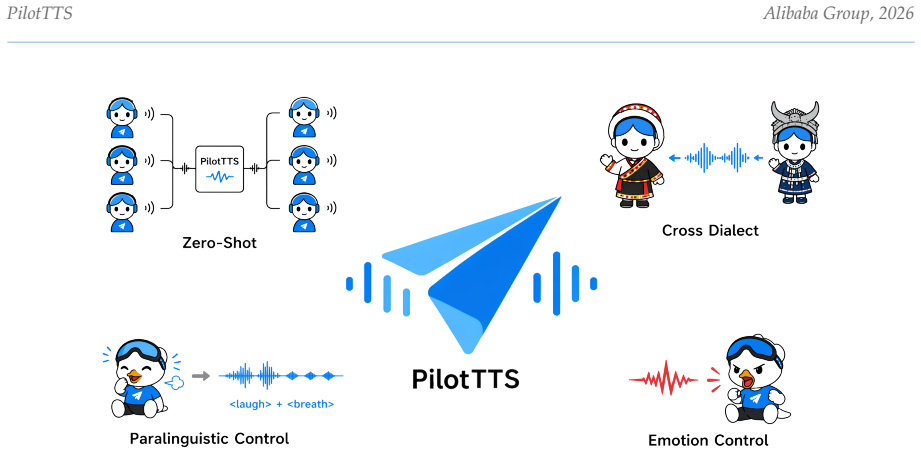
- One model supports zero-shot cloning plus synthesis across 11 emotion categories, 4 paralinguistic categories, and 14 Chinese dialects.
- Data quality and conditioning can offset reductions in training data volume on standard TTS benchmarks.
- The architecture enables unified training for multiple synthesis tasks instead of separate specialized models.
Where Pith is reading between the lines
- If the identity-style separation holds, similar conditioning could transfer to other autoregressive audio or language generation tasks.
- Full release of the pipeline and weights would let the community test incremental improvements to the data steps.
- The results suggest careful curation may matter more for benchmark leadership than raw data scale alone.
Load-bearing premise
The benchmark gains arise solely from the described data pipeline and Q-Former training without undisclosed data selection or post-processing advantages.
What would settle it
An independent replication that applies the exact multi-stage pipeline and trains on 200K hours yet fails to match the reported WER, CER, and speaker similarity on Seed-TTS Eval.
Figures
read the original abstract
Building state-of-the-art text-to-speech (TTS) systems typically demands millions of hours of proprietary data and complex multi-stage architectures, creating substantial barriers for resource-constrained research teams. In this report, we present PilotTTS, a lightweight autoregressive TTS system that achieves competitive performance through minimalist architecture and rigorous data engineering. PilotTTS is trained on only 200K hours of data processed entirely with open-source tools. Specifically, our contributions are: (1) a reproducible multi-stage data processing pipeline covering quality assessment, label annotation, and filtering, and (2) a compact model architecture that employs Q-Former-based conditioning to decouple speaker identity from speaking style via cross-sample paired training. Within a unified framework, PilotTTS supports zero-shot voice cloning, emotion synthesis (11 categories), paralinguistic synthesis (4 categories), and Chinese dialect synthesis (14 dialects). On the Seed-TTS Eval benchmark, PilotTTS achieves the lowest WER of 1.50% on test-en, a CER of 0.87% on test-zh, and the highest speaker similarity on both test sets (0.862 and 0.815), outperforming systems trained on significantly larger datasets. We release the complete data pipeline recipe, pretrained weights, and code at https://github.com/AMAPVOICE/PilotTTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PilotTTS, a lightweight autoregressive TTS system trained on 200K hours of open-source data via a multi-stage processing pipeline (quality assessment, annotation, filtering) and a compact architecture using Q-Former-based cross-sample paired training to decouple speaker identity from speaking style. It claims support for zero-shot voice cloning, 11-category emotion synthesis, 4-category paralinguistic synthesis, and 14-dialect Chinese synthesis, while reporting state-of-the-art results on the Seed-TTS Eval benchmark: lowest WER of 1.50% on test-en, CER of 0.87% on test-zh, and highest speaker similarity (0.862/0.815), outperforming systems trained on larger datasets. The full recipe, weights, and code are released.
Significance. If the benchmark numbers prove reproducible under the stated protocol and the outperformance holds without undisclosed data advantages, the work would be significant for demonstrating that rigorous open-source data engineering plus modular conditioning can achieve competitive TTS performance without proprietary million-hour datasets, thereby reducing barriers for resource-constrained teams.
major comments (3)
- [Abstract / Results] Abstract and results section: The headline claims rest on specific benchmark numbers (WER 1.50% test-en, CER 0.87% test-zh, sim 0.862/0.815) without reported error bars, number of evaluation runs, or statistical significance tests, so it is impossible to determine whether the reported outperformance over larger-data systems is robust or could arise from evaluation variance.
- [Abstract / Experimental setup] Abstract and § on experimental setup: No ablation studies or controlled comparisons are described that isolate the contribution of the Q-Former cross-sample paired training versus the multi-stage data pipeline, leaving the central decoupling claim without direct empirical support.
- [Abstract] Abstract: The assertion that comparisons used identical test conditions on Seed-TTS Eval is stated but not accompanied by protocol details, dataset splits, or verification steps, which is load-bearing for the claim of outperforming larger-data systems.
minor comments (2)
- [Abstract] The abstract mentions support for 14 dialects but provides no quantitative results on dialect synthesis quality or speaker similarity for those cases.
- [Model architecture] Notation for the Q-Former conditioning mechanism is introduced without an accompanying diagram or equation showing the cross-sample pairing loss.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on improving the empirical rigor of our claims. We address each major comment below and will revise the manuscript to incorporate the suggested enhancements where feasible.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: The headline claims rest on specific benchmark numbers (WER 1.50% test-en, CER 0.87% test-zh, sim 0.862/0.815) without reported error bars, number of evaluation runs, or statistical significance tests, so it is impossible to determine whether the reported outperformance over larger-data systems is robust or could arise from evaluation variance.
Authors: We agree that reporting error bars, multiple runs, and statistical tests would better demonstrate robustness. In the revised manuscript, we will include results averaged over multiple evaluation runs with standard deviations and apply appropriate significance testing to the benchmark comparisons. revision: yes
-
Referee: [Abstract / Experimental setup] Abstract and § on experimental setup: No ablation studies or controlled comparisons are described that isolate the contribution of the Q-Former cross-sample paired training versus the multi-stage data pipeline, leaving the central decoupling claim without direct empirical support.
Authors: We recognize the importance of isolating the contributions of the Q-Former conditioning and the data pipeline. We will add targeted ablation studies in the revised version to provide direct empirical evidence for the decoupling mechanism. revision: yes
-
Referee: [Abstract] Abstract: The assertion that comparisons used identical test conditions on Seed-TTS Eval is stated but not accompanied by protocol details, dataset splits, or verification steps, which is load-bearing for the claim of outperforming larger-data systems.
Authors: We will expand the experimental setup section with explicit details on the Seed-TTS Eval protocol, dataset splits, and verification steps used to ensure identical test conditions, thereby supporting the fairness of the comparisons. revision: yes
Circularity Check
No circularity: empirical benchmark claims with no derivations or self-referential predictions
full rationale
The paper describes a data-processing pipeline and Q-Former architecture, then reports empirical results on the external Seed-TTS Eval benchmark (WER, CER, speaker similarity). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims are performance numbers obtained from training and evaluation; they do not reduce to inputs by construction. This is a standard empirical systems paper whose validity hinges on reproducibility of the released artifacts rather than any definitional or self-citation loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural codec language models are zero-shot text to speech synthesizers.IEEE T ransactions on Audio, Speech and Language Processing, 33:705–718, 2025
Sanyuan Chen, Chengyi Wang, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers.IEEE T ransactions on Audio, Speech and Language Processing, 33:705–718, 2025
2025
-
[2]
Naturalspeech 2: Latentdiffusionmodelsarenaturalandzero-shotspeechandsingingsynthesizers
KaiShen,ZeqianJu,XuTan,EricLiu,YichongLeng,LeiHe,TaoQin,JiangBian,etal. Naturalspeech 2: Latentdiffusionmodelsarenaturalandzero-shotspeechandsingingsynthesizers. InInternational conference on learning representations, volume 2024, pages 698–722, 2024
2024
-
[3]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
PhilipAnastassiou,JiaweiChen,JitongChen,YuanzheChen,ZhuoChen,ZiyiChen,JianCong,Lelai 12 PilotTTS Alibaba Group, 2026 Deng, Chuang Ding, Lu Gao, et al. Seed-tts: A family of high-quality versatile speech generation models.arXiv preprint arXiv:2406.02430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Kun Xie, Feiyu Shen, Junjie Li, Fenglong Xie, Xu Tang, and Yao Hu. Fireredtts-2: Towards long conversational speech generation for podcast and chatbot.arXiv preprint arXiv:2509.02020, 2025
-
[7]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, JianZhao JianZhao, Kai Yu, and Xie Chen. F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 6255–6271, 2025
2025
-
[8]
Ditar: Diffusion transformer autoregressive modeling for speech generation
Dongya Jia, Zhuo Chen, Jiawei Chen, Chenpeng Du, Jian Wu, Jian Cong, Xiaobin Zhuang, Chumin Li, Zhen Wei, Yuping Wang, et al. Ditar: Diffusion transformer autoregressive modeling for speech generation. InInternational Conference on Machine Learning, pages 27255–27270. PMLR, 2025
2025
-
[9]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Eric Liu, Yichong Leng, Kaitao Song, Siliang Tang, et al. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. InInternational Conference on Machine Learning, pages 22605–22623. PMLR, 2024
2024
-
[10]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, et al. Qwen3-tts technical report.arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Bowen Zhang, Congchao Guo, Geng Yang, Hang Yu, Haozhe Zhang, Heidi Lei, Jialong Mai, Junjie Yan, Kaiyue Yang, Mingqi Yang, et al. Minimax-speech: Intrinsic zero-shot text-to-speech with a learnable speaker encoder.arXiv preprint arXiv:2505.07916, 2025
-
[12]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[14]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. In11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[15]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[16]
Hifi-gan: generative adversarial networks for efficient and high fidelity speech synthesis
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi-gan: generative adversarial networks for efficient and high fidelity speech synthesis. InProceedings of the 34th International Conference on Neural Information Processing Systems, pages 17022–17033, 2020
2020
-
[17]
Powerset multi-class cross entropy loss for neural speaker diarization
Alexis Plaquet and Hervé Bredin. Powerset multi-class cross entropy loss for neural speaker diarization. In24th Interspeech Conference (INTERSPEECH 2023), pages 3222–3226. ISCA, 2023
2023
-
[18]
pyannote
Hervé Bredin. pyannote. audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe. In24th Interspeech Conference (INTERSPEECH 2023), pages 1983–1987. ISCA, 2023. 13 PilotTTS Alibaba Group, 2026
2023
-
[19]
Dnsmos: A non-intrusive perceptual objective speechqualitymetrictoevaluatenoisesuppressors
Chandan KA Reddy, Vishak Gopal, and Ross Cutler. Dnsmos: A non-intrusive perceptual objective speechqualitymetrictoevaluatenoisesuppressors. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6493–6497. IEEE, 2021
2021
-
[20]
Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition
Zhifu Gao, ShiLiang Zhang, Ian McLoughlin, and Zhijie Yan. Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition. InProc. Interspeech 2022, pages 2063–2067, 2022
2022
- [21]
-
[22]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[23]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, et al. Qwen3-asr technical report.arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
3d-speaker-toolkit: An open-source toolkit for multimodal speaker verification and diarization
YafengChen,SiqiZheng,HuiWang,LuyaoCheng,TinglongZhu,RongjieHuang,ChongDeng,Qian Chen, Shiliang Zhang, Wen Wang, et al. 3d-speaker-toolkit: An open-source toolkit for multimodal speaker verification and diarization. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[25]
Cam++: A fast and efficient network for speaker verification using context-aware masking
Hui Wang, Siqi Zheng, Yafeng Chen, Luyao Cheng, and Qian Chen. Cam++: A fast and efficient network for speaker verification using context-aware masking. InProc. Interspeech 2023, pages 5301–5305, 2023
2023
-
[26]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training.arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Towards efficient visual-language alignment of the q-former for visual reasoning tasks
Sungkyung Kim, Adam Lee, Junyoung Park, Andrew Chung, Jusang Oh, and Jay-Yoon Lee. Towards efficient visual-language alignment of the q-former for visual reasoning tasks. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15155–15165, 2024
2024
-
[28]
W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training
Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, and Yonghui Wu. W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 244–250. IEEE, 2021
2021
-
[29]
Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, et al. Voxcpm: Tokenizer-free tts for context-aware speech generation and true-to-life voice cloning.arXiv preprint arXiv:2509.24650, 2025
-
[30]
Zhiliang Peng, Jianwei Yu, Wenhui Wang, Yaoyao Chang, Yutao Sun, Li Dong, Yi Zhu, Weijiang Xu, Hangbo Bao, Zehua Wang, et al. Vibevoice technical report.arXiv preprint arXiv:2508.19205, 2025
-
[31]
Fish audio s2 technical report.arXiv preprint arXiv:2603.08823, 2026
Shijia Liao, Yuxuan Wang, Songting Liu, Yifan Cheng, Ruoyi Zhang, Tianyu Li, Shidong Li, Yisheng Zheng, Xingwei Liu, Qingzheng Wang, et al. Fish audio s2 technical report.arXiv preprint arXiv:2603.08823, 2026
-
[32]
Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, and Lu Wang. Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system.arXiv preprint arXiv:2502.05512, 2025. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.