BASIS: Batchwise Advantage Estimation from Single-Rollout Information Sharing for LLM Reasoning
Pith reviewed 2026-06-29 17:58 UTC · model grok-4.3
The pith
BASIS estimates values from single rollouts by sharing batch information, cutting MSE 69% and matching multi-rollout performance with less time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
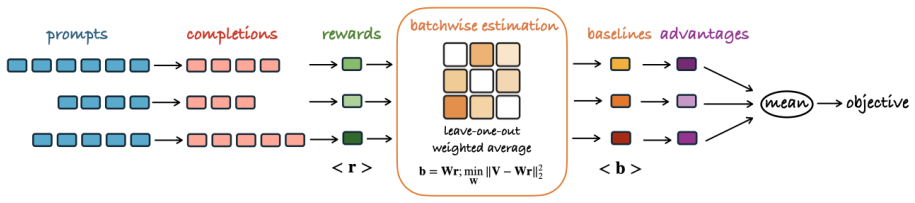
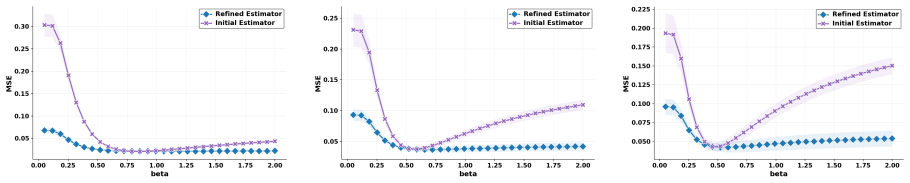
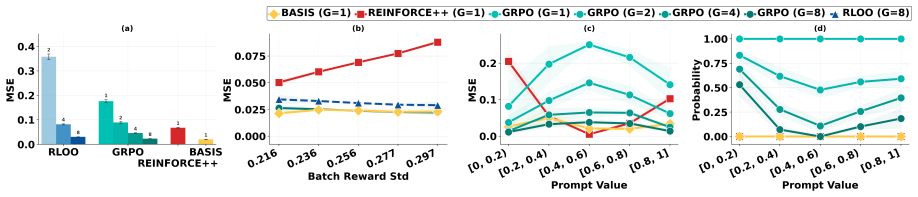
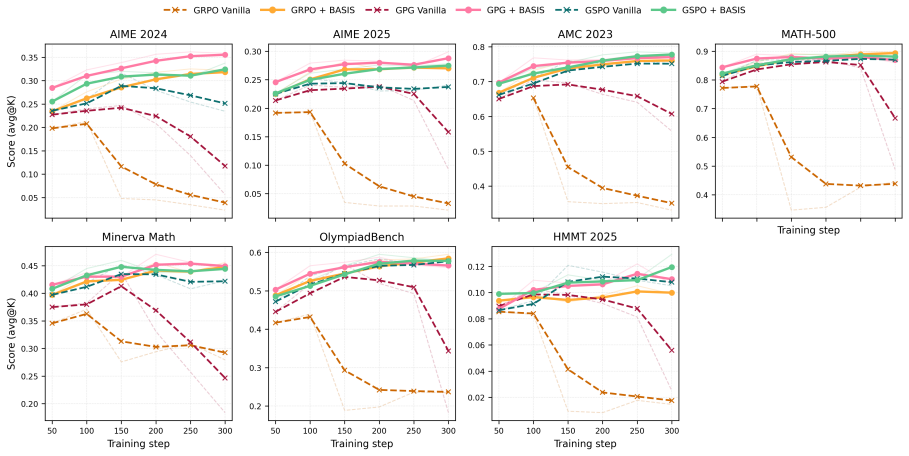
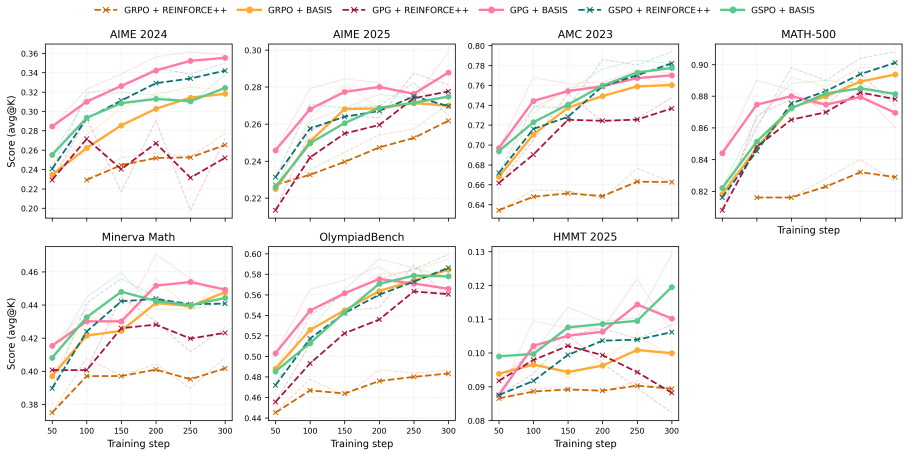
At each online training step, BASIS samples only one rollout per prompt, but leverages rich information across prompts in the entire batch to improve value function estimation. This yields a 69% reduction in MSE compared to REINFORCE++ and lower MSE than group mean estimators using eight rollouts, translating to policy optimization that reaches performance close to multi-rollout baselines with substantially less training time.
What carries the argument
Batchwise advantage estimation that pools single-rollout outcomes across the full batch to produce more accurate per-prompt advantages without additional sampling.
Load-bearing premise
Information from different prompts in the same batch can be combined to improve value estimates for each prompt without adding bias.
What would settle it
A run that disables the batch-sharing step while keeping everything else identical shows the MSE reduction and downstream performance gains disappear.
Figures

read the original abstract
Reinforcement learning with verifiable rewards has become a standard recipe for improving the reasoning abilities of large language models. Existing algorithms face a tradeoff between computational efficiency and sample efficiency in value estimation and policy learning. We introduce BASIS, a critic-free post-training algorithm designed to address this tradeoff. At each online training step, BASIS samples only one rollout per prompt, but leverages rich information across prompts in the entire batch to improve value function estimation. Our experiments demonstrate that BASIS reduces MSE in value function estimation by 69% compared to REINFORCE++, a representative single-rollout baseline, and achieves lower MSE with one rollout than group mean estimators with 8 rollouts. This improvement in value estimation translates to better policy optimization: using substantially less training time, BASIS achieves performance close to multi-rollout GRPO-type baselines and often outperforms single-rollout REINFORCE-type baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BASIS, a critic-free post-training algorithm for RL with verifiable rewards in LLMs. It samples one rollout per prompt but leverages cross-prompt batch information to improve value function estimation, claiming a 69% MSE reduction versus REINFORCE++ and lower MSE than 8-rollout group-mean estimators, which translates to policy optimization performance close to multi-rollout GRPO baselines with less training time.
Significance. If the batchwise single-rollout estimator is unbiased, the approach could meaningfully improve sample efficiency in LLM reasoning post-training by reducing the rollout budget while maintaining or improving gradient quality. The empirical MSE and downstream gains, if reproducible, would be a practical contribution to the efficiency-accuracy tradeoff in online RL for LLMs.
major comments (2)
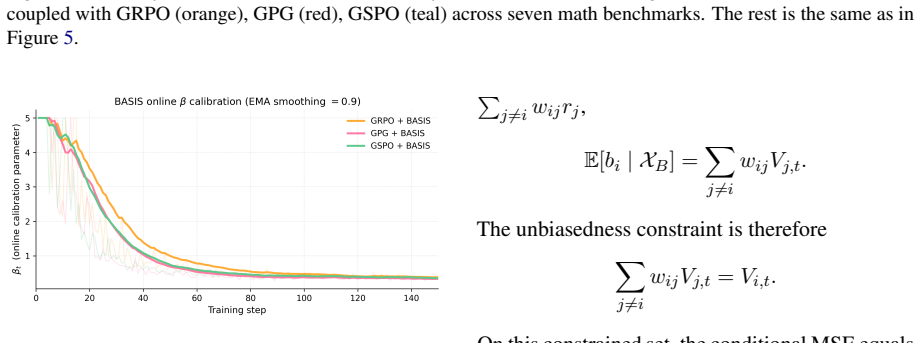
- [Method section (estimator definition)] The central claim that BASIS yields lower-variance yet unbiased advantage estimates from single rollouts rests on the batchwise estimator definition. No derivation or proof is supplied showing that E[BASIS estimate | prompt] equals the true value function (or that any bias is orthogonal to the policy gradient); without this step the reported 69% MSE reduction could reflect correlated batch statistics rather than a general improvement. This is load-bearing for both the value-estimation and policy-optimization results.
- [Experiments section (MSE table)] Table reporting MSE comparisons (single-rollout BASIS vs. REINFORCE++ and vs. 8-rollout group mean): the experimental setup must clarify whether the batchwise sharing introduces any prompt-level correlation that could affect the reported MSE numbers or downstream policy gradients; the current description leaves open whether the improvement holds under independent prompt sampling.
minor comments (2)
- [Method] Notation for the batchwise advantage estimator should be introduced with an explicit equation early in the method section to allow readers to follow the unbiasedness argument.
- [Abstract] The abstract states quantitative claims (69% MSE reduction, performance close to multi-rollout baselines) without referencing the corresponding tables or figures; add those citations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Method section (estimator definition)] The central claim that BASIS yields lower-variance yet unbiased advantage estimates from single rollouts rests on the batchwise estimator definition. No derivation or proof is supplied showing that E[BASIS estimate | prompt] equals the true value function (or that any bias is orthogonal to the policy gradient); without this step the reported 69% MSE reduction could reflect correlated batch statistics rather than a general improvement. This is load-bearing for both the value-estimation and policy-optimization results.
Authors: We agree that the manuscript would benefit from an explicit derivation of the estimator's unbiasedness. The current text defines the batchwise estimator and reports empirical MSE but does not supply a formal proof that its conditional expectation given the prompt equals the true value function. In the revised version we will add a short derivation subsection in Methods establishing unbiasedness under independent prompt sampling and showing that any residual bias is orthogonal to the policy gradient. revision: yes
-
Referee: [Experiments section (MSE table)] Table reporting MSE comparisons (single-rollout BASIS vs. REINFORCE++ and vs. 8-rollout group mean): the experimental setup must clarify whether the batchwise sharing introduces any prompt-level correlation that could affect the reported MSE numbers or downstream policy gradients; the current description leaves open whether the improvement holds under independent prompt sampling.
Authors: We agree that the experimental description requires additional clarity. Prompts within each training batch are drawn independently from the dataset; the batchwise sharing operates across these independent samples. The reported MSE numbers therefore reflect the intended cross-prompt information sharing without extraneous prompt-level correlation. We will revise the Experiments section to state this sampling procedure explicitly and confirm that all MSE and policy results were obtained under independent prompt sampling. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description present BASIS as an empirical algorithm that shares batch information for single-rollout value estimation, with reported MSE reductions and policy gains as experimental outcomes. No equations, derivations, or load-bearing steps are exhibited that reduce by construction to self-definition, fitted inputs renamed as predictions, or self-citation chains. The central claims rest on measured performance differences rather than a mathematical identity or ansatz smuggled via prior work. This is the common case of a self-contained empirical contribution with no detectable circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Variance reduction techniques for gradient esti- mates in reinforcement learning.Journal of Machine Learning Research, 5(Nov):1471–1530. Kevin Han, Yuhang Zhou, Mingze Gao, Gedi Zhou, Serena Li, Abhishek Kumar, Xiangjun Fan, Weiwei Li, and Lizhu Zhang. 2026. Ebpo: Empirical bayes shrinkage for stabilizing group-relative policy opti- mization.arXiv preprin...
-
[2]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization. arXiv preprint arXiv:2501.03262. Yu Huang, Zixin Wen, Yuejie Chi, Yuting Wei, Aarti Singh, Yingbin Liang, and Yuxin Chen. 2026. The implicit curriculum: Learning dynamics in rl with verifiable rewards.arXiv preprint arXiv:2602.14872. Nathan Lambert, Jacob Morriso...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model.Advances in Neu- ral Information Processing Systems (NeurIPS). Herbert Robbins and Sutton Monro. 1951. A stochastic approximation method.The annals of mathematical statistics, pages 400–407. John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 201...
work page internal anchor Pith review Pith/arXiv arXiv 1951
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.