MATCHA: Matching Text via Contrastive Semantic Alignment
Pith reviewed 2026-06-29 18:40 UTC · model grok-4.3
The pith
MATCHA improves text evaluation by rewarding agreement with a reference while penalizing contradictions through contrastive alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
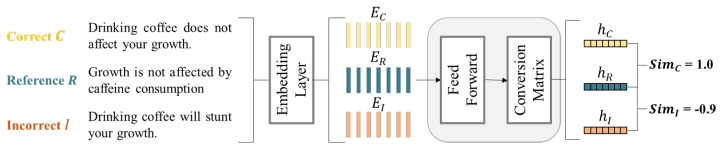
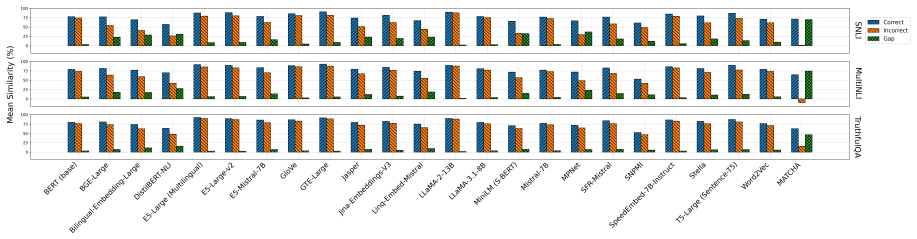
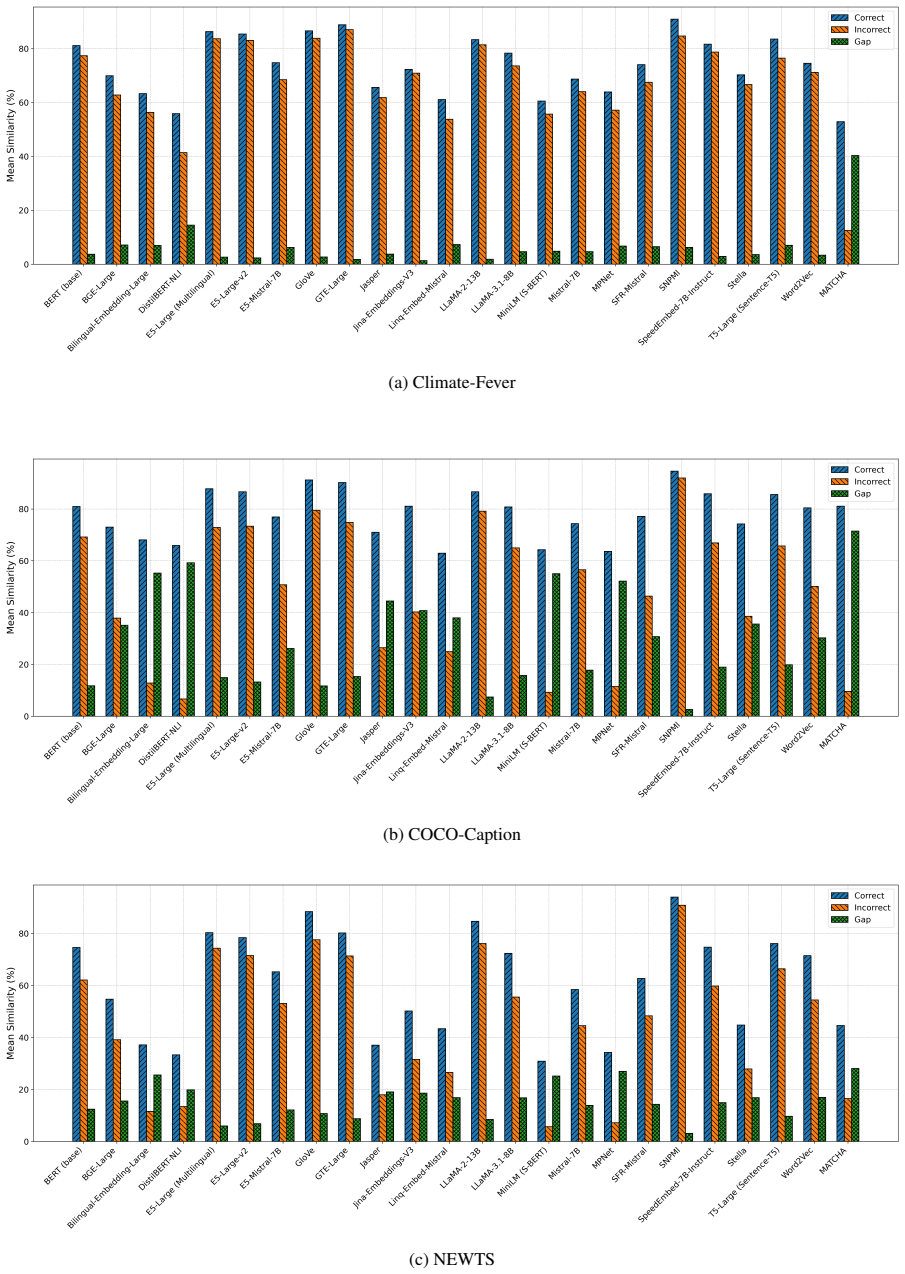
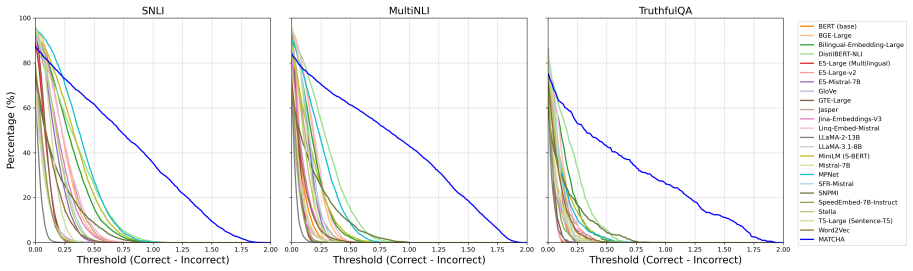
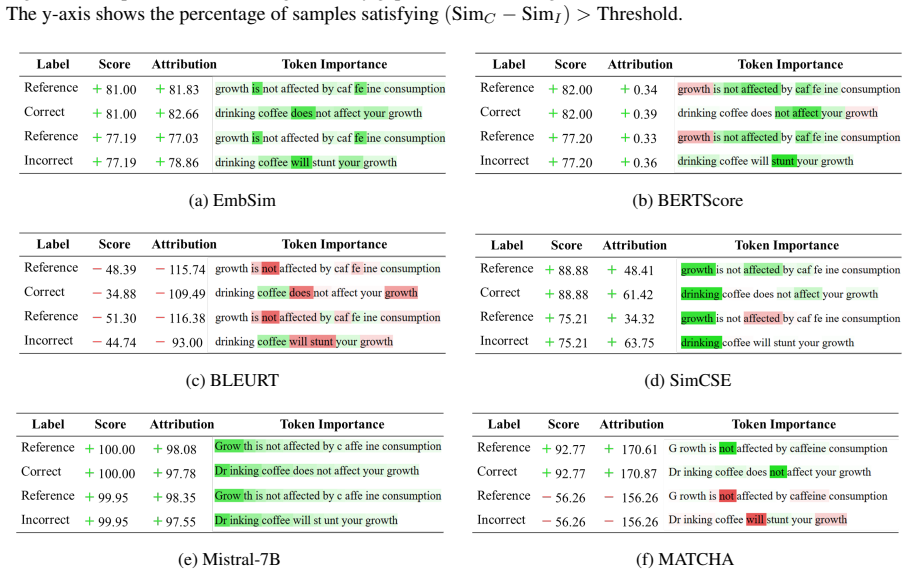
MATCHA employs a dual-view perspective that measures (i) proximity to the gold text and (ii) distance from an adversarially generated counterfactual contradiction, enabling it to jointly reward semantic agreement with a reference and penalize contradictions, which leads to superior performance over token-overlap and embedding-based metrics on eight public benchmarks and better distinction of correct versus incorrect statements than 23 other models.
What carries the argument
Dual-view contrastive alignment that combines proximity to the reference with distance from adversarially generated counterfactual contradictions.
If this is right
- MATCHA distinguishes correct from incorrect statements more accurately than token-overlap or embedding metrics on factual QA tasks.
- The metric requires no task-specific training data and works on datasets such as TruthfulQA.
- It reveals that prior metrics routinely fail to penalize direct contradictions.
- MATCHA can serve as a drop-in replacement for ROUGE or BERTScore in evaluation pipelines for QA, summarization, and NLI.
Where Pith is reading between the lines
- Using MATCHA scores as a reward signal could improve alignment during LLM fine-tuning.
- The contrastive generation step might extend to other modalities such as code or image caption evaluation.
- The dual-view structure suggests similar contrastive penalties could strengthen other semantic comparison tasks.
Load-bearing premise
Adversarially generated counterfactual contradictions provide a reliable and representative measure of semantic distance from the reference for penalizing incorrect statements.
What would settle it
A benchmark where MATCHA assigns comparable scores to a correct reference and its direct semantic contradiction, despite clear human judgments separating the two.
Figures
read the original abstract
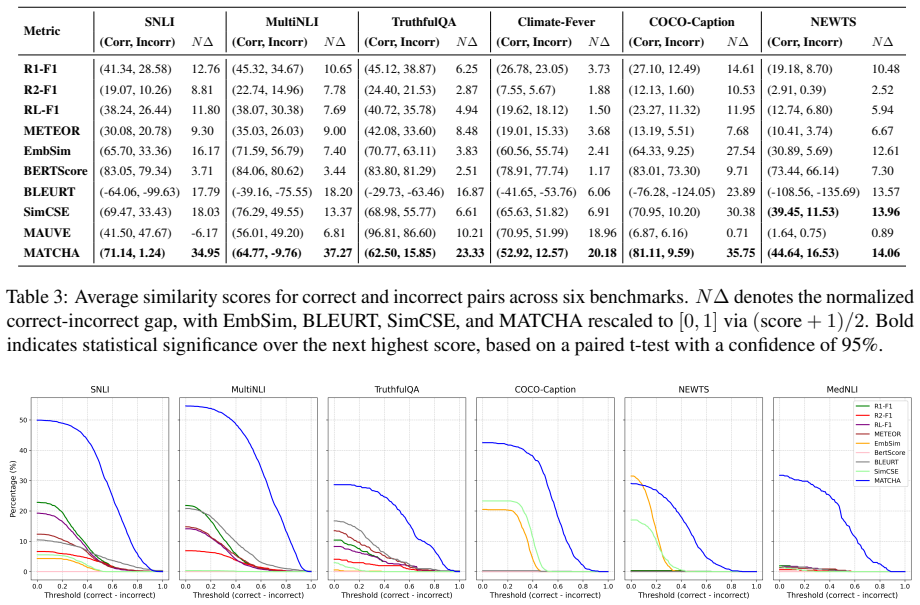
Reliable evaluation is essential for understanding large language model (LLM) performance, yet today's go-to metrics, namely token-overlap scores (e.g., ROUGE) and embedding-based measures (e.g., BERTScore), often misjudge semantic similarity of documents. Our study shows that both token-overlap metrics and embedding-based metrics routinely assign nearly identical scores to texts that directly contradict each other, thereby potentially masking fundamental errors. We introduce MATCHA, an automatic metric that jointly rewards semantic agreement with a reference and penalizes contradictions. MATCHA employs a dual-view perspective that measures (i) proximity to the gold text and (ii) distance from an adversarially generated counterfactual contradiction. In eight public benchmarks, MATCHA outperforms popular metrics, compared with human annotations on question-answering, image caption generation, natural language inference, summarization, and semantic textual similarity tasks. On the TruthfulQA dataset (i.e., a dataset without a training set, where no embedding-based metrics could locally train on), this improvement in terms of matching texts with a reference reaches 18.38% over ROUGE-L and 20.82% over BERTScore. Both quantitative comparison and qualitative human assessments confirm the efficacy and validity of MATCHA and uncover fundamental weaknesses in pre-existing metrics. Compared with 23 embedding models, including top state-of-the-art ones, used as a metric similar to BERTScore, MATCHA remains the most accurate in distinguishing correct from incorrect statements solely based on a reference. Our code and metric are publicly available (https://github.com/Siran-Li/MATCHA).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
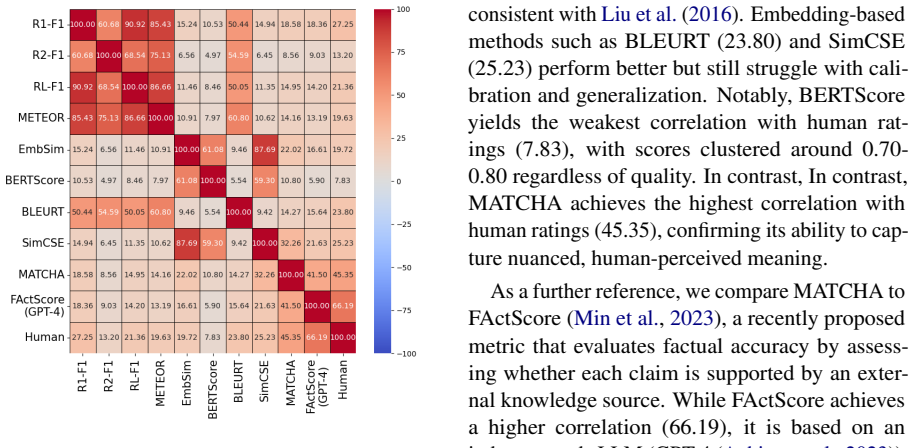
Summary. The paper introduces MATCHA, a contrastive metric for text matching that rewards proximity to a gold reference while penalizing distance from adversarially generated counterfactual contradictions. It reports that MATCHA outperforms token-overlap metrics (e.g., ROUGE-L) and embedding-based metrics (e.g., BERTScore) on eight benchmarks spanning QA, captioning, NLI, summarization, and STS, with specific gains of 18.38% over ROUGE-L and 20.82% over BERTScore on TruthfulQA; it also claims to be the most accurate among 23 embedding models when used similarly to BERTScore, with supporting human evaluations.
Significance. If the adversarial counterfactuals reliably represent semantic contradictions without model-specific artifacts, MATCHA could address a documented weakness in existing automatic metrics (assigning similar scores to contradictory texts) and improve evaluation of LLM outputs on factual correctness and semantic fidelity. The public release of code strengthens potential impact.
major comments (3)
- [Method] Method section (description of dual-view): the central penalty term depends on adversarially generated counterfactual contradictions, yet the manuscript supplies no details on the generator architecture, prompting strategy, temperature, or any validation that the outputs are true semantic opposites rather than distribution-shift artifacts; without this, the 18.38%/20.82% gains on TruthfulQA cannot be assessed for robustness.
- [Experiments] Experiments section (ablation and statistical reporting): no ablation isolates the contribution of the contradiction-distance term versus the reference-proximity term alone, and no standard deviations, sample sizes, or significance tests accompany the reported percentage improvements or the ranking against 23 embedding models.
- [Results] Results on TruthfulQA and embedding-model comparison: the claim that MATCHA is most accurate among 23 models (including SOTA) when used as a metric requires explicit confirmation that all comparators were evaluated under identical reference-only conditions with no local fine-tuning, which is not shown.
minor comments (2)
- [Abstract] The abstract states the code link but the manuscript does not include a reproducibility checklist or exact hyperparameter values used for the reported runs.
- [Figures/Tables] Figure captions and table headers could more clearly distinguish MATCHA from the embedding baselines to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving clarity and rigor. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Method] Method section (description of dual-view): the central penalty term depends on adversarially generated counterfactual contradictions, yet the manuscript supplies no details on the generator architecture, prompting strategy, temperature, or any validation that the outputs are true semantic opposites rather than distribution-shift artifacts; without this, the 18.38%/20.82% gains on TruthfulQA cannot be assessed for robustness.
Authors: We agree that the Method section requires additional details on the counterfactual generator for reproducibility and to substantiate the robustness of the gains. In the revised manuscript, we will expand this section to specify the generator architecture, prompting strategy, temperature settings, and validation procedures (including human evaluation and NLI-based checks) confirming semantic opposition rather than artifacts. revision: yes
-
Referee: [Experiments] Experiments section (ablation and statistical reporting): no ablation isolates the contribution of the contradiction-distance term versus the reference-proximity term alone, and no standard deviations, sample sizes, or significance tests accompany the reported percentage improvements or the ranking against 23 embedding models.
Authors: We concur that an ablation isolating the two terms and statistical reporting would strengthen the experimental section. The revised manuscript will include an ablation study comparing the full dual-view MATCHA against single-term variants, along with standard deviations, sample sizes, and significance tests (e.g., paired statistical tests) for all reported improvements and rankings. revision: yes
-
Referee: [Results] Results on TruthfulQA and embedding-model comparison: the claim that MATCHA is most accurate among 23 models (including SOTA) when used as a metric requires explicit confirmation that all comparators were evaluated under identical reference-only conditions with no local fine-tuning, which is not shown.
Authors: All 23 embedding models, including SOTA ones, were evaluated under identical reference-only conditions with no local fine-tuning, consistent with the BERTScore protocol and the no-training-set nature of TruthfulQA explicitly noted in the manuscript. To address the concern, we will add an explicit statement in the Results section confirming these evaluation conditions for all comparators. revision: partial
Circularity Check
No circularity: MATCHA defined and evaluated independently of its inputs
full rationale
The paper defines MATCHA explicitly as a dual-view metric combining proximity to a gold reference with distance from adversarially generated counterfactual contradictions, then reports empirical performance gains on eight benchmarks against human annotations and 23 other models. No equation, training step, or result reduces by construction to fitted parameters, self-citations, or renamed inputs; the TruthfulQA results are presented as out-of-distribution evaluation with no local training, and the superiority claims rest on external comparisons rather than definitional equivalence. The derivation chain is self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic agreement can be jointly measured by proximity to a reference and distance from an adversarially generated contradiction.
Reference graph
Works this paper leans on
-
[1]
Open Question Answering Over Curated and Extracted Knowledge Bases. InKDD. Katja Filippova and Yasemin Altun. 2013. Overcom- ing the lack of parallel data in sentence compression. InProceedings of the 2013 Conference on Empiri- cal Methods in Natural Language Processing, pages 1481–1491. Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tieyan Liu. 2019. R...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Knowledge-aware cross-modal text-image re- trieval for remote sensing images. InProceedings of the Second Workshop on Complex Data Challenges in Earth Observation (CDCEO 2022). Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representa- tions in vector space. InInternational Conference on Learning Representation...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
BLEURT: Learning robust metrics for text generation. InProceedings of ACL. Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie- Yan Liu. 2020. Mpnet: Masked and permuted pre- training for language understanding. InAdvances in Neural Information Processing Systems, volume 33, pages 16857–16867. Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günth...
-
[4]
Llama 2: Open Foundation and Fine-Tuned Chat Models
PMLR. The NLP Group. 2023. Gte-large. Available at https: //huggingface.co/thenlper/gte-large. Hugo Touvron, Louis Martin, Kevin Stone, Peter Al- bert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajwal Bhargava, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foundation and fine-tuned chat models.Preprint, arXiv:2307.09288. Cédri...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A broad-coverage challenge corpus for sen- tence understanding through inference. InProceed- ings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, V olume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics. Dun Zhang, Jiacheng Li, Ziyang Zeng, and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.