From Scores to Gibbs Correctors: Accelerating Uniform-Rate Discrete Diffusion Models
Pith reviewed 2026-06-29 18:53 UTC · model grok-4.3
The pith
GADD constructs Gibbs posterior likelihoods directly from concrete scores to reach O(polylog(ε^{-1})) sampling complexity for uniform-rate discrete diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GADD leverages the structure of the concrete score function to construct Gibbs posterior likelihoods directly, without requiring any additional training beyond standard score estimation. The resulting predictor-corrector scheme achieves an overall sampling complexity of O(polylog(ε^{-1})), the first such rate for diffusion-based samplers on uniform-rate discrete diffusion models. The theoretical analysis relies on an induction argument that tracks error propagation across predictor iterations while accounting for inaccuracies in the corrector updates, providing a new framework for analyzing predictor-corrector methods that differs from Girsanov-based approaches.
What carries the argument
The Gibbs-based corrector, which constructs posterior likelihoods directly from the concrete score function and plugs into the predictor-corrector iteration to accelerate mixing.
If this is right
- Uniform-rate discrete diffusion models can now be sampled in polylogarithmic steps rather than the linear or slower rates of prior diffusion-based methods.
- The same score estimates already computed for training suffice for both the predictor and the new Gibbs corrector, eliminating the need for auxiliary models.
- The induction-based error analysis supplies a template for bounding predictor-corrector schemes that avoids change-of-measure arguments.
- Empirical gains appear in wall-clock time and sample quality on zero-shot text sampling and conditional music generation relative to Euler and CTMC baselines.
Where Pith is reading between the lines
- The direct score-to-Gibbs construction may extend to other discrete diffusion schedules whose transition kernels admit similar posterior forms.
- The induction framework for tracking predictor-corrector errors could be adapted to analyze acceleration in continuous-state diffusion models.
- Because the method re-uses existing score estimates, it lowers the barrier to deploying accelerated discrete diffusion in new symbolic domains.
Load-bearing premise
The structure of the concrete score function permits direct construction of Gibbs posterior likelihoods without any additional training beyond standard score estimation, and the induction argument correctly tracks error propagation while accounting for corrector inaccuracies.
What would settle it
An explicit counterexample or numerical run in which the total number of steps required to reach accuracy ε scales worse than any polylog(ε^{-1}) while using only the score-based Gibbs corrector would falsify the complexity claim.
Figures
read the original abstract
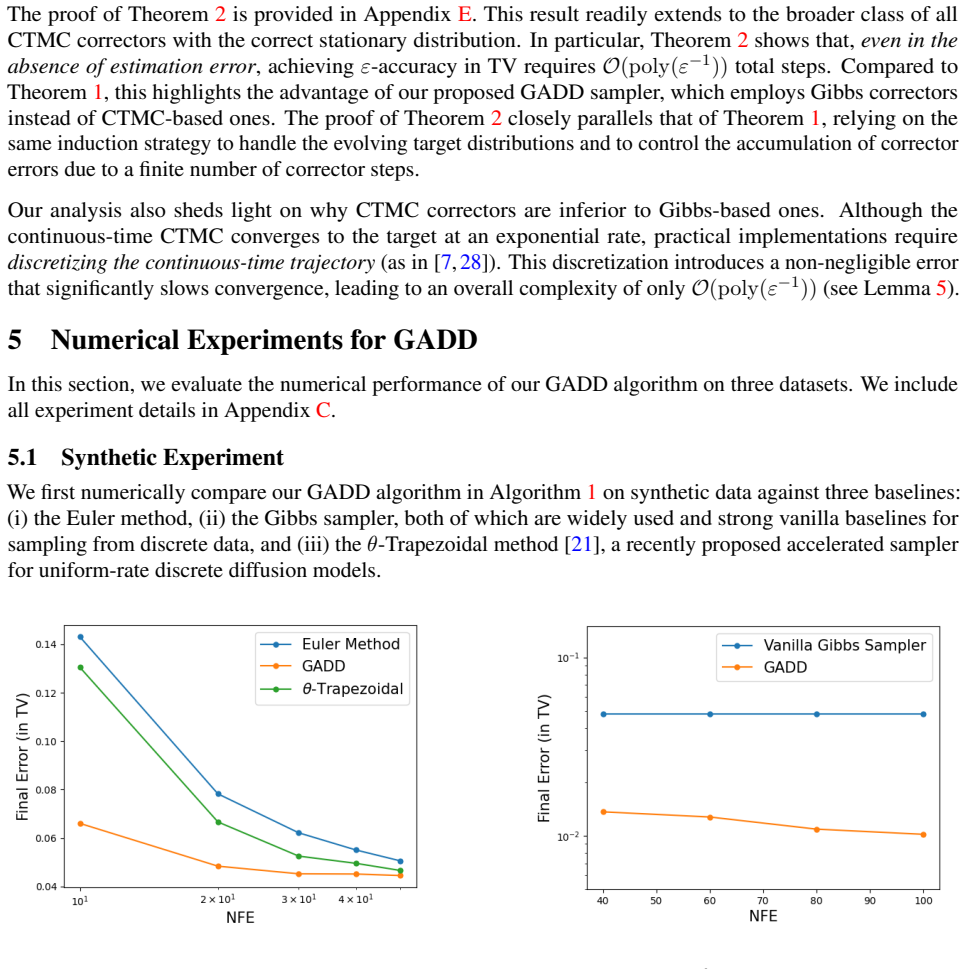
Discrete diffusion models have achieved strong empirical performance in text and other symbolic domains, but, especially for uniform-rate models, they often require many steps to generate a single sample. Existing acceleration methods either rely on training additional quantities or suffer from slow mixing. In this work, we propose a novel Gibbs-based corrector for discrete diffusion models, termed Gibbs-Accelerated Discrete Diffusion (GADD). GADD leverages the structure of the concrete score function to construct Gibbs posterior likelihoods directly, without requiring any additional training beyond standard score estimation. We show that GADD achieves an overall sampling complexity of $\mathcal{O}(\mathrm{polylog} (\varepsilon^{-1}))$, yielding the first such rate for diffusion-based samplers for uniform-rate discrete diffusion models. We also conduct numerical experiments demonstrating the practical advantages of GADD across synthetic data, zero-shot text sampling, and zero-shot conditional music generation. These results corroborate the theory and show that GADD consistently improves sample quality and wall-clock efficiency over standard baselines, including vanilla Euler methods and CTMC correctors. Beyond this, our theoretical analysis introduces a novel framework for analyzing predictor-corrector methods in discrete diffusion models, which may be of independent interest. Unlike existing approaches that rely on the Girsanov change-of-measure technique, our method is based on an induction argument that tracks error propagation across predictor iterations while accounting for inaccuracies in the corrector updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gibbs-Accelerated Discrete Diffusion (GADD), a predictor-corrector scheme for uniform-rate discrete diffusion models. It constructs Gibbs posterior likelihoods directly from the concrete score function without extra training, proves an overall sampling complexity of O(polylog(ε^{-1})) via an induction argument that tracks predictor error propagation while accounting for corrector inaccuracies, and reports empirical gains in sample quality and wall-clock time versus Euler and CTMC baselines on synthetic data, zero-shot text sampling, and conditional music generation. The analysis framework is presented as novel relative to Girsanov-based approaches.
Significance. If the claimed complexity bound is rigorously established, the result would be significant: it supplies the first polylogarithmic rate for diffusion-based sampling in the uniform-rate discrete setting and introduces an induction-based error analysis that may be reusable. The absence of additional training and the reported practical speed-ups are further strengths. The contribution is tempered by the need for explicit verification of the error-control constants in the discrete setting.
major comments (2)
- [§4] §4 (main complexity theorem): the induction argument claims to bound the accumulation of corrector inaccuracies across predictor steps, yet the manuscript does not exhibit the concrete contraction or Lipschitz constant of the score function nor the explicit dependence on state-space cardinality |X|; without these, it is unclear whether the per-step discrepancy remains small enough to preserve the polylog(ε^{-1}) scaling rather than degrading to poly(1/ε).
- [§4.3] §4.3 (error-propagation lemma): the claim that corrector error is controlled to O(ε) per step is used to close the induction, but the proof sketch does not show how the uniform-rate transition kernel interacts with the Gibbs posterior approximation; a concrete counter-example or numerical check on a small discrete space would strengthen the argument.
minor comments (3)
- Notation for the concrete score and the Gibbs posterior should be introduced with a single consistent symbol table; current usage mixes p_θ and the score notation across sections.
- Figure 3 (music generation) lacks axis labels on the wall-clock vs. quality plot and does not report the number of independent runs used for the error bars.
- The related-work discussion omits recent analyses of CTMC correctors that also target uniform-rate models; a brief comparison paragraph would clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We appreciate the acknowledgment of the potential significance of the polylogarithmic complexity result and the induction-based analysis. We address each major comment below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4] §4 (main complexity theorem): the induction argument claims to bound the accumulation of corrector inaccuracies across predictor steps, yet the manuscript does not exhibit the concrete contraction or Lipschitz constant of the score function nor the explicit dependence on state-space cardinality |X|; without these, it is unclear whether the per-step discrepancy remains small enough to preserve the polylog(ε^{-1}) scaling rather than degrading to poly(1/ε).
Authors: We agree that the current presentation leaves the contraction constants implicit. In the revision we will explicitly derive the Lipschitz constant of the concrete score under the uniform-rate dynamics and state its (polynomial) dependence on |X|. The induction is closed by choosing the number of predictor steps T = O(polylog(ε^{-1})) and step size h = O(1/T) such that the per-step discrepancy factor remains bounded by 1 + O(h); the accumulated error therefore stays O(ε) rather than growing polynomially in 1/ε. The expanded §4 will contain these calculations. revision: yes
-
Referee: [§4.3] §4.3 (error-propagation lemma): the claim that corrector error is controlled to O(ε) per step is used to close the induction, but the proof sketch does not show how the uniform-rate transition kernel interacts with the Gibbs posterior approximation; a concrete counter-example or numerical check on a small discrete space would strengthen the argument.
Authors: The Gibbs corrector is obtained by exponentiating the score to recover the exact conditional distribution of the uniform-rate kernel; consequently the one-step corrector error is bounded by the score estimation error, which is O(ε) by assumption. To make this interaction fully explicit we will enlarge the proof sketch in §4.3 and add a small-scale numerical verification (binary alphabet, |X|=4) confirming that the per-step corrector discrepancy remains O(ε) across predictor iterations. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via induction on error propagation
full rationale
The paper derives its O(polylog(ε^{-1})) sampling complexity claim from a novel induction argument that tracks predictor-corrector error propagation in the uniform-rate discrete setting. This argument is presented as independent of Girsanov techniques and does not reduce to fitted parameters, self-citations, or definitional equivalences. The Gibbs corrector is constructed directly from the concrete score without additional training, and the abstract explicitly contrasts the approach with prior methods. No load-bearing step is shown to collapse by construction to its inputs; the central result therefore retains independent analytical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Induction argument tracks error propagation across predictor iterations while accounting for inaccuracies in the corrector updates.
invented entities (1)
-
GADD
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InProceedings of the 32nd International Conference on Machine Learning, volume 37, pages 2256–2265, 2015
2015
-
[2]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
2020
-
[3]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
2021
-
[4]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 11
2025
-
[5]
Digress: Discrete denoising diffusion for graph generation
Clement Vignac, Igor Krawczuk, Antoine Siraudin, Bohan Wang, V olkan Cevher, and Pascal Frossard. Digress: Discrete denoising diffusion for graph generation. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[6]
Generative diffusion models on graphs: methods and applications
Chengyi Liu, Wenqi Fan, Yunqing Liu, Jiatong Li, Hang Li, Hui Liu, Jiliang Tang, and Qing Li. Generative diffusion models on graphs: methods and applications. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, 2023
2023
-
[7]
A continuous time framework for discrete denoising models
Andrew Campbell, Joe Benton, Valentin De Bortoli, Tom Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[8]
Diffusion models in de novo drug design
Amira Alakhdar, Barnabas Poczos, and Newell Washburn. Diffusion models in de novo drug design. Journal of Chemical Information and Modeling, 2024
2024
-
[9]
Unlocking guidance for discrete state-space diffusion and flow models
Hunter Nisonoff, Junhao Xiong, Stephan Allenspach, and Jennifer Listgarten. Unlocking guidance for discrete state-space diffusion and flow models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[10]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InThe Ninth International Conference on Learning Representations, 2021
2021
-
[11]
Yuhui Wu, Yuxin Chen, and Yuting Wei. Stochastic Runge-Kutta methods: Provable acceleration of diffusion models.arXiv preprint arXiv:2410.04760, 2024
-
[12]
Broadening target distributions for accelerated diffusion models via a novel analysis approach
Yuchen Liang, Peizhong Ju, Yingbin Liang, and Ness Shroff. Broadening target distributions for accelerated diffusion models via a novel analysis approach. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[13]
Faster diffusion models via higher-order approxima- tion.arXiv preprint arXiv:2506.24042, 2025
Gen Li, Yuchen Zhou, Yuting Wei, and Yuxin Chen. Faster diffusion models via higher-order approxima- tion.arXiv preprint arXiv:2506.24042, 2025
-
[14]
Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[15]
Informed correctors for discrete diffusion models
Yixiu Zhao, Jiaxin Shi, Feng Chen, Shaul Druckmann, Lester Mackey, and Scott Linderman. Informed correctors for discrete diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[16]
Learning flexible forward trajectories for masked molecular diffusion
Hyunjin Seo, Taewon Kim, Sihyun Yu, and SungSoo Ahn. Learning flexible forward trajectories for masked molecular diffusion.arXiv preprint arXiv: 2505.16790, 2025
-
[17]
Mg-diff: A novel molecular graph diffusion model for molecular generation and optimization.PLOS ONE, 2025
Xiaochen Zhang, Shuangxi Wang, Ying Fang, and Qiankun Zhang. Mg-diff: A novel molecular graph diffusion model for molecular generation and optimization.PLOS ONE, 2025
2025
-
[18]
The Diffusion Duality, Chapter II: $\Psi$-Samplers
Justin Deschenaux, Caglar Gulcehre, and Subham Sekhar Sahoo. The diffusion duality, chapter ii: ψ-samplers and efficient curriculum.arXiv preprint arXiv:2602.21185, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Convergence of score-based discrete diffusion models: A discrete-time analysis
Zikun Zhang, Zixiang Chen, and Quanquan Gu. Convergence of score-based discrete diffusion models: A discrete-time analysis. InThe Thirteenth International Conference on Learning Representations, 2025. 12
2025
-
[20]
Discrete diffusion models: Novel analysis and new sampler guarantees
Yuchen Liang, Yingbin Liang, Lifeng Lai, and Ness Shroff. Discrete diffusion models: Novel analysis and new sampler guarantees. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[21]
Rotskoff, Molei Tao, and Lexing Ying
Yinuo Ren, Haoxuan Chen, Yuchen Zhu, Wei Guo, Yongxin Chen, Grant M. Rotskoff, Molei Tao, and Lexing Ying. Fast solvers for discrete diffusion models: Theory and applications of high-order algorithms. InFrontiers in Probabilistic Inference: Learning meets Sampling, 2025
2025
-
[22]
Rotskoff, and Lexing Ying
Yinuo Ren, Haoxuan Chen, Grant M. Rotskoff, and Lexing Ying. How discrete and continuous diffusion meet: Comprehensive analysis of discrete diffusion models via a stochastic integral framework. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[23]
Efficient sampling with discrete diffusion models: Sharp and adaptive guarantees
Daniil Dmitriev, Zhihan Huang, and Yuting Wei. Efficient sampling with discrete diffusion models: Sharp and adaptive guarantees.arXiv preprint arXiv:2602.15008, 2026
work page internal anchor Pith review arXiv 2026
-
[24]
Non-asymptotic convergence of discrete diffusion models: Masked and random walk dynamics
Giovanni Conforti, Alain Durmus, Le-Tuyet-Nhi Pham, and Gael Raoul. Non-asymptotic convergence of discrete diffusion models: Masked and random walk dynamics.arXiv preprint arXiv:2512.00580, 2025
-
[25]
Discrete Markov probabilistic models: An improved discrete score-based framework with sharp con- vergence bounds under minimal assumptions
Le-Tuyet-Nhi Pham, Dario Shariatian, Antonio Ocello, Giovanni Conforti, and Alain Oliviero Durmus. Discrete Markov probabilistic models: An improved discrete score-based framework with sharp con- vergence bounds under minimal assumptions. InForty-second International Conference on Machine Learning, 2025
2025
-
[26]
Hongrui Chen and Lexing Ying. Convergence analysis of discrete diffusion model: Exact implementation through uniformization.arXiv preprint arXiv:2402.08095, 2024
-
[27]
Dimension-Free Convergence of Discrete Diffusion Models: Adjoint Equations Induce the Right Space
Kelvin Kan, Xingjian Li, Benjamin J. Zhang, Tuhin Sahai, Stanley Osher, and Markos A. Katsoulakis. Dimension-free convergence of discrete diffusion models: Adjoint equations induce the right space. arXiv preprint arXiv:2605.17232, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky T. Q. Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[29]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 32819–32848, 2024
2024
-
[30]
Kelly.Reversibility and Stochastic Networks
Frank P. Kelly.Reversibility and Stochastic Networks. Cambridge University Press, 2011
2011
-
[31]
Levin, Yuval Peres, and Elizabeth L
David A. Levin, Yuval Peres, and Elizabeth L. Wilmer.Markov Chains and Mixing Times (Second Edition). American Mathematical Society, 2017
2017
-
[32]
Reverse transition kernel: A flexible framework to accelerate diffusion inference
Xunpeng Huang, Difan Zou, Hanze Dong, Yi Zhang, Yian Ma, and Tong Zhang. Reverse transition kernel: A flexible framework to accelerate diffusion inference. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[33]
Sharp convergence rates for masked diffusion models, 2026 b
Yuchen Liang, Zhiheng Tan, Ness Shroff, and Yingbin Liang. Sharp convergence rates for masked diffusion models.arXiv preprint arXiv:2602.22505, 2026
-
[34]
Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment
Hao-Wen Dong, Wen-Yi Hsiao, Li-Chia Yang, and Yi-Hsuan Yang. Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment. InProceedings of the AAAI Conference on Artificial Intelligence, 2018. 13
2018
-
[35]
Theory on score-mismatched diffusion models and zero-shot conditional samplers
Yuchen Liang, Peizhong Ju, Yingbin Liang, and Ness Shroff. Theory on score-mismatched diffusion models and zero-shot conditional samplers. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
Accelerating convergence of score-based diffusion models, provably
Gen Li, Yu Huang, Timofey Efimov, Yuting Wei, Yuejie Chi, and Yuxin Chen. Accelerating convergence of score-based diffusion models, provably. InProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[37]
Stochastic relaxation, gibbs distributions, and the bayesian restoration of images.IEEE Transactions on Pattern Analysis and Machine Intelligence, 1984
Stuart Geman and Donald Geman. Stochastic relaxation, gibbs distributions, and the bayesian restoration of images.IEEE Transactions on Pattern Analysis and Machine Intelligence, 1984
1984
-
[38]
A polynomial time MCMC method for sampling from continuous determinantal point processes
Alireza Rezaei and Shayan Oveis Gharan. A polynomial time MCMC method for sampling from continuous determinantal point processes. InProceedings of the 36th International Conference on Machine Learning, 2019
2019
-
[39]
Yves F. Atchadé. Approximate spectral gaps for markov chain mixing times in high dimensions.SIAM Journal on Mathematics of Data Science, 3(3):854–872, 2021
2021
-
[40]
Dimension-free mixing times of Gibbs samplers for Bayesian hierarchical models.The Annals of Statistics, 52(3):869 – 894, 2024
Filippo Ascolani and Giacomo Zanella. Dimension-free mixing times of Gibbs samplers for Bayesian hierarchical models.The Annals of Statistics, 52(3):869 – 894, 2024
2024
-
[41]
Parallel gibbs sampling: From colored fields to thin junction trees
Joseph Gonzalez, Yucheng Low, Arthur Gretton, and Carlos Guestrin. Parallel gibbs sampling: From colored fields to thin junction trees. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 2011
2011
-
[42]
Discrete predictor- corrector diffusion models for image synthesis
Jose Lezama, Tim Salimans, Lu Jiang, Huiwen Chang, Jonathan Ho, and Irfan Essa. Discrete predictor- corrector diffusion models for image synthesis. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[43]
Language models are unsupervised multitask learners.OpenAI, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI, 2019
2019
-
[44]
Split gibbs discrete diffusion posterior sampling.arXiv preprint arXiv:2503.01161, 2025
Wenda Chu, Zihui Wu, Yifan Chen, Yang Song, and Yisong Yue. Split gibbs discrete diffusion posterior sampling.arXiv preprint arXiv:2503.01161, 2025
-
[45]
Improved analysis of score-based generative modeling: user-friendly bounds under minimal smoothness assumptions
Hongrui Chen, Holden Lee, and Jianfeng Lu. Improved analysis of score-based generative modeling: user-friendly bounds under minimal smoothness assumptions. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[46]
Bobkov and Prasad Tetali
Sergey G. Bobkov and Prasad Tetali. Modified logarithmic Sobolev inequalities in discrete settings. Journal of Theoretical Probability, 19(2):289–336, 2006. 14 Appendix A Additional Related Works 15 B Variants of GADD and Posterior Likelihood Estimate 16 C Details of Numerical Experiments 17 C.1 Synthetic Experiment . . . . . . . . . . . . . . . . . . . ....
2006
-
[47]
the outer-loop (or grand) initialization error at the start of the algorithm
-
[48]
the inner-loop initialization error at the beginning of each Gibbs sampling phase; and
-
[49]
X xτ ˜pT−t k,τ|η kℓ(xτ |xηkℓ)gτ(xτ)−g τ(xηkℓ) # ≲E xηk ℓ∼˜pT−t k ,ηk ℓ
the inner-loop error resulting from imperfect score estimation. We analyze each of these error components separately and then combine them to derive the overall convergence guarantee for Algorithm 1. To begin, the following result gives us an upper bound on the grand (i.e., outer-loop) initialization error. From [19, Proposition 2] and [22, Theorem C.1], ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.