Hybrid Classical-Quantum Neural Networks for Multi-Characteristic Co-Optimization of Recessed-Gate AlGaN/GaN MIS-HEMTs
Pith reviewed 2026-06-30 18:20 UTC · model grok-4.3
The pith
Hybrid quantum-classical neural network reduces modeling error for GaN transistors by 24.4 percent on experimental data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
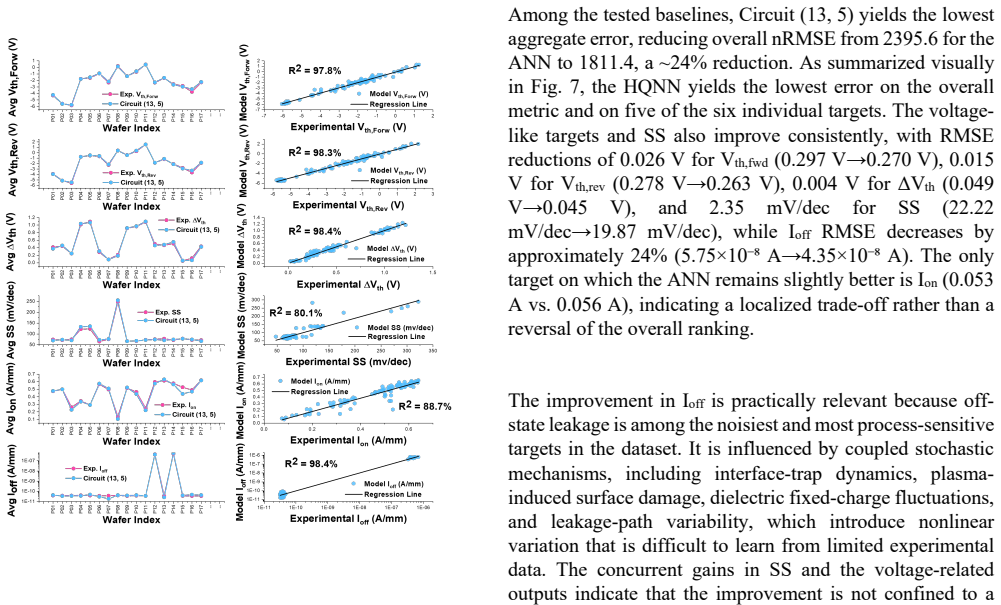
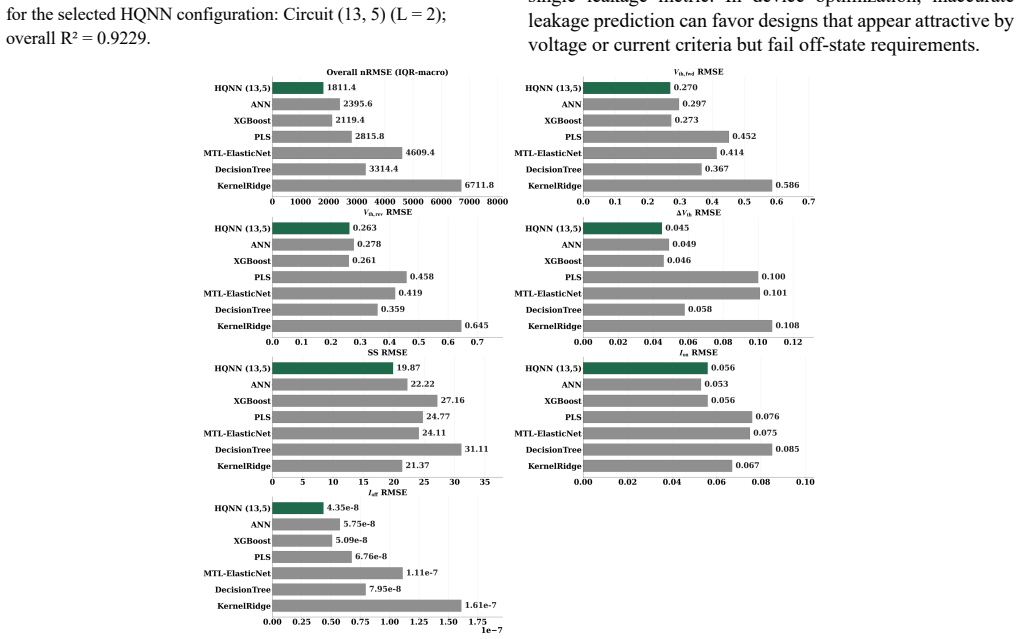
On 468 experimental fabricated devices spanning 17 process splits, the selected HQNN, Circuit (13, 5) at L = 2, reduces overall normalized root mean square error by 24.4 percent relative to ANN, with target-wise improvements including Vth,lin RMSE from 0.297 V to 0.270 V, Vth,rev from 0.278 V to 0.263 V, DeltaVth from 0.049 V to 0.045 V, SS from 22.22 mV/dec to 19.87 mV/dec, and Id from 5.75e-8 A to 4.35e-8 A, while Ion remains competitive.
What carries the argument
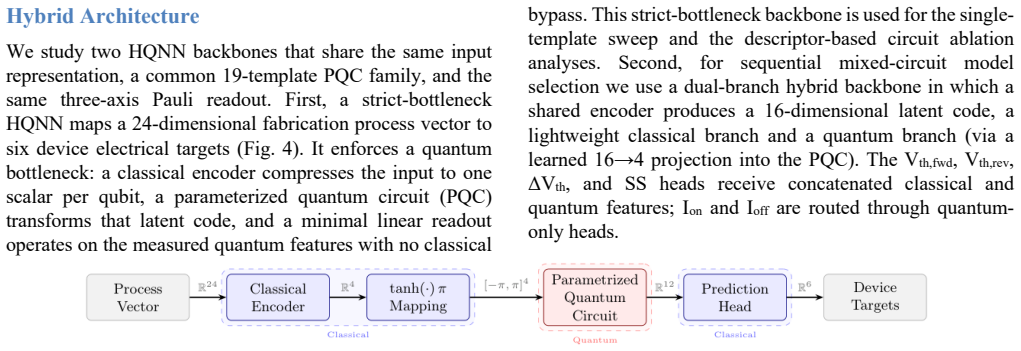
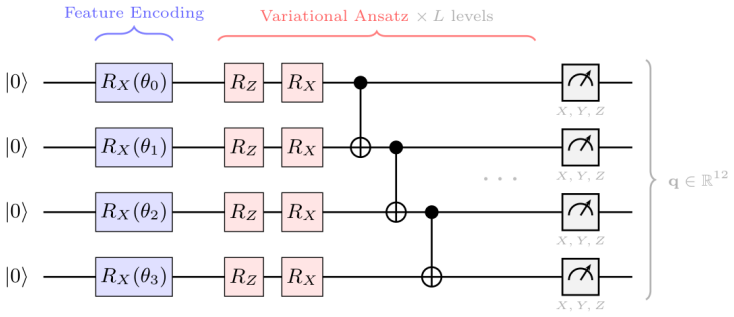
Hybrid classical-quantum neural network (HQNN) built from screened quantum-circuit templates that processes a 24-dimensional fabrication vector to predict six electrical targets simultaneously.
If this is right
- Performance improves when circuit depth, parameter count, and two-qubit gate count are increased.
- Controlled-rotation entanglers outperform static CNOT-based circuits across the screened templates.
- Expressibility measured by DKL correlates negatively with accuracy on this dataset.
- A depolarizing-noise study indicates that similar HQNNs remain trainable or deployable on near-term quantum hardware.
Where Pith is reading between the lines
- The same screening approach could be applied to other semiconductor technologies that produce costly experimental datasets with process variability.
- The negative correlation between expressibility and accuracy suggests that, for this task, circuits that are too expressive may overfit the limited experimental samples.
- Retraining the selected circuit on new process splits held out from the original 17 would test whether the accuracy gain generalizes beyond the training distribution.
Load-bearing premise
The observed accuracy gains come from properties of the quantum circuits rather than from differences in total parameter count, network depth, or other hyperparameter choices.
What would settle it
A direct comparison in which a classical network is given exactly the same number of trainable parameters and layers as the HQNN and still shows higher error on the same 468-device dataset would falsify the claim that the quantum component supplies the advantage.
Figures

read the original abstract
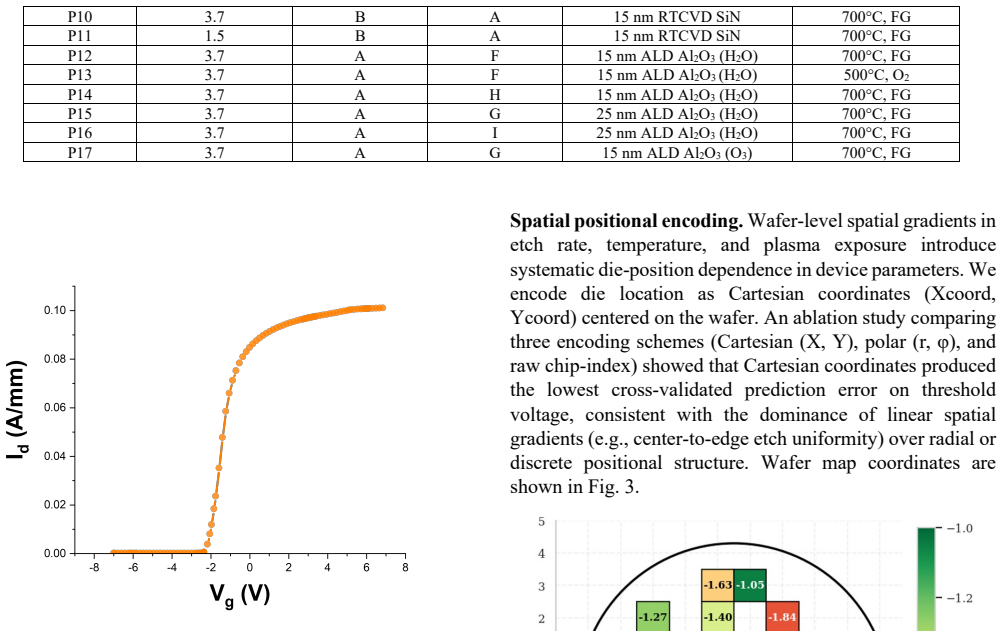
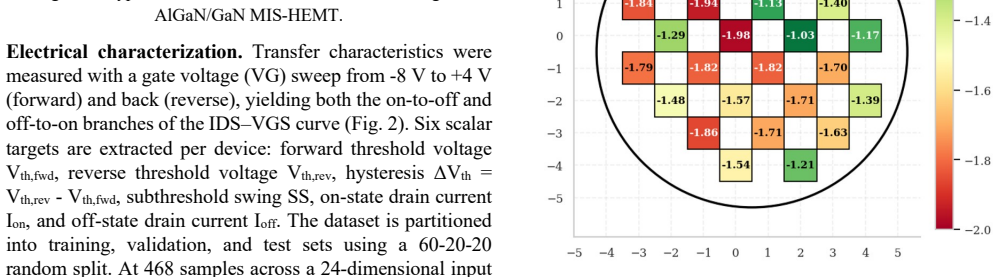
Optimizing recessed-gate AlGaN/GaN MIS-HEMTs requires accurate multi-characteristic models, but experimental semiconductor datasets remain costly and encode process-induced variability that simulations cannot faithfully reproduce. This work proposes a hybrid classical-quantum neural network (HQNN) for joint optimization of six electrical targets from a 24-dimensional fabrication/process vector. We systematically screen quantum-circuit templates to extract circuit-design guidance, then select a final HQNN and compare it directly with classical baselines. On 468 experimental fabricated devices spanning 17 process splits, the selected HQNN, Circuit (13, 5) at L = 2, reduces overall normalized root mean square error (nRMSE) by 24.4% relative to ANN. Target-wise, the HQNN lowers Vth,lin RMSE from 0.297 V to 0.270 V, Vth,rev RMSE from 0.278 V to 0.263 V, DeltaVth RMSE from 0.049 V to 0.045 V, SS RMSE from 22.22 mV/dec to 19.87 mV/dec, and Id RMSE from 5.75 x 10^-8 A to 4.35 x 10^-8 A, while Ion RMSE remains competitive (0.053 A vs. 0.056 A). Controlled ansatz ablations further show that performance depends strongly on architecture: parameter count, depth, and two-qubit gate count correlate positively with accuracy, expressibility (DKL) correlates negatively, and controlled-rotation entanglers outperform static controlled-NOT (CNOT)-based circuits in aggregate. A depolarizing-noise study on a representative 4-qubit circuit further suggests that comparable HQNNs may be trainable or deployable on near-term quantum hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes hybrid classical-quantum neural networks (HQNNs) for joint modeling of six electrical targets (Vth,lin, Vth,rev, DeltaVth, SS, Id, Ion) of recessed-gate AlGaN/GaN MIS-HEMTs from a 24-dimensional process vector. Using data from 468 experimental devices across 17 process splits, it screens quantum-circuit ansatze, selects Circuit (13,5) at depth L=2, and reports a 24.4% overall nRMSE reduction versus a classical ANN baseline, with target-wise RMSE improvements (e.g., Vth,lin: 0.297 V to 0.270 V; Id: 5.75e-8 A to 4.35e-8 A). Ablations link accuracy to parameter count, depth, and two-qubit gates, while a depolarizing-noise study suggests near-term hardware viability.
Significance. If the reported accuracy gains are shown to arise from quantum-circuit properties rather than unmatched model capacity, the work would provide concrete evidence of HQNN utility for multi-objective semiconductor device modeling on limited experimental datasets. The systematic ansatz screening, explicit correlation of expressibility/entanglement metrics with performance, and use of real fabricated-device data (rather than simulation) are strengths that could guide future quantum-classical co-design in electronics.
major comments (3)
- [Abstract] Abstract (comparison paragraph): The central claim of 24.4% nRMSE reduction (and target-wise RMSE drops such as Vth,lin 0.297 V to 0.270 V) is load-bearing for asserting HQNN superiority, yet no information is given on whether the ANN baseline was matched in total trainable parameters to Circuit (13,5) at L=2. The abstract itself states that performance depends strongly on parameter count, depth, and two-qubit gate count; without an explicit capacity-matched ablation, the observed gains cannot be attributed to quantum expressibility or entanglement rather than classical model size.
- [Abstract] Abstract (results and methods description): The reported numerical improvements on 468 devices lack accompanying statistical tests, confidence intervals, or error bars on the RMSE values, and provide no details on data splits, cross-validation procedure, or hyperparameter tuning protocol for either model. These omissions directly affect verifiability of whether the target-wise reductions are robust or could arise from random variation or overfitting.
- [Abstract] Abstract (ablations paragraph): The positive correlation of accuracy with parameter count is noted, but the manuscript does not report the actual parameter counts for the selected HQNN versus the ANN, nor does it include a controlled experiment at fixed parameter budget. This leaves open the possibility that the 24.4% aggregate improvement is explained by capacity differences rather than the quantum-circuit features highlighted in the ablations.
minor comments (1)
- [Abstract] The notation 'Circuit (13, 5)' is used without an explicit definition of what the two numbers index (e.g., qubit count and entangling-gate count); a brief parenthetical clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need for capacity-matched baselines and improved statistical reporting. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim of 24.4% nRMSE reduction is load-bearing for asserting HQNN superiority, yet no information is given on whether the ANN baseline was matched in total trainable parameters to Circuit (13,5) at L=2. Without an explicit capacity-matched ablation, the observed gains cannot be attributed to quantum expressibility or entanglement rather than classical model size.
Authors: We agree that the absence of explicit parameter counts and a capacity-matched comparison weakens the attribution of gains to quantum features. Although the manuscript reports ablations correlating accuracy with parameter count, depth, and two-qubit gates, it does not tabulate the trainable parameters of the final HQNN versus ANN. We will revise the abstract and main text to report these counts and add a controlled ablation at matched parameter budgets. revision: yes
-
Referee: The reported numerical improvements on 468 devices lack accompanying statistical tests, confidence intervals, or error bars on the RMSE values, and provide no details on data splits, cross-validation procedure, or hyperparameter tuning protocol for either model.
Authors: The manuscript describes the 468-device dataset and 17 process splits but does not detail the train/test protocol, cross-validation, hyperparameter search, or provide error bars/CIs. We will expand the methods section with these details and add statistical measures (e.g., standard deviation across runs or bootstrap CIs) to the reported RMSE values. revision: yes
-
Referee: The manuscript does not report the actual parameter counts for the selected HQNN versus the ANN, nor does it include a controlled experiment at fixed parameter budget. This leaves open the possibility that the 24.4% aggregate improvement is explained by capacity differences rather than the quantum-circuit features.
Authors: This overlaps with the first comment. We will explicitly report parameter counts for both models and include a fixed-budget comparison to isolate quantum-circuit contributions (e.g., entanglement type) from capacity effects, building on the existing architecture ablations. revision: yes
Circularity Check
No significant circularity; empirical ML comparison on held-out experimental data
full rationale
The paper trains HQNN and ANN models via supervised learning on 468 fabricated devices to predict six electrical targets from 24 process parameters. Reported nRMSE reductions are direct empirical outcomes of that training and comparison, not algebraic identities or self-definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to force the result. Architecture ablations are presented as controlled experiments, not as derivations that collapse to the inputs. This is standard non-circular supervised modeling.
Axiom & Free-Parameter Ledger
free parameters (2)
- HQNN trainable parameters
- Circuit depth L
axioms (1)
- domain assumption The 468 experimental measurements across 17 process splits are representative and sufficient to train and evaluate the model without severe overfitting or selection bias.
Reference graph
Works this paper leans on
-
[1]
Table-Based Nonlinear HEMT Model Extracted from Time-Domain Large-Signal Measurements
M. C. Curras-Francos, “Table-Based Nonlinear HEMT Model Extracted from Time-Domain Large-Signal Measurements”, IEEE Transactions on Microwave Theory and Techniques, vol. 53, no. 5, pp. 1593–1600, 2005. [4] J. Xu, D. Gunyan, M. Iwamoto, A. Cognata, D. E. Root, “Measurement-Based Non-Quasi-Static Large-Signal FET Model Using Artificial Neural Networks”, in ...
-
[2]
Exponential quantum advantage in processing massive classical data
V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, J. M. Gambetta, “Supervised Learning with Quantum-Enhanced Feature Spaces”, Nature, vol. 567, no. 7747, pp. 209–212, 2019. [15] J. R. Glick, T. P. Gujarati, A. D. Córcoles, Y. Kim, A. Kandala, J. M. Gambetta, K. Temme, “Covariant Quantum Kernels for Data with Group Structure”, Na...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
CUDA Quantum: The Platform for Integrated Quantum-Classical Computing
J. Kim, A. McCaskey, B. Heim, M. Modani, S. Stanwyck, T. Costa, “CUDA Quantum: The Platform for Integrated Quantum-Classical Computing”, 2023 60th ACM/IEEE Design Automation Conference (DAC), pp. 1–4, 2023. Appendix A Table 3: Variational ansatz template inventory for Q = 4 qubits [18]. RX(i), RY(i), RZ(i), H(i): single-qubit gates on qubit i. CX(c,t), CZ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.