Lowering LCU Circuit Width through Maximum-Weight Birkhoff-von Neumann Decomposition
Pith reviewed 2026-06-30 16:25 UTC · model grok-4.3
The pith
A bottleneck variant of Birkhoff's algorithm decomposes doubly stochastic matrices into O(N log(1/ε)) permutation terms for LCU circuits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Any square matrix can be transformed into a doubly stochastic matrix via Sinkhorn scaling with diagonal matrices or completing to a larger dimensional matrix. Standard Birkhoff-von Neumann and Pauli decompositions represent such matrices as linear combinations of O(N²) permutation or Pauli terms. A bottleneck variant of Birkhoff's algorithm reduces the number of permutations to O(N log(1/ε)), where ε is the l1-norm approximation error of the reconstructed matrix. A largest-weight greedy variant requires only ≈2N terms for dense matrices (average ≈2.4N). The quadratic reduction in term count directly shrinks the ancilla register from 2 log₂ N to log₂ N qubits, shortens the SELECT circuit, and
What carries the argument
The bottleneck (maximum-weight) variant of Birkhoff's algorithm, which repeatedly extracts a permutation by solving a maximum-weight matching on the support of the current residual matrix.
If this is right
- The ancilla register in an LCU implementation shrinks from 2 log₂ N qubits to log₂ N qubits.
- The SELECT circuit depth decreases in proportion to the drop in term count.
- Success probability in fixed-Hadamard LCU architectures rises because it scales inversely with the number of terms K.
- The uniform superposition state is an eigenvector with eigenvalue 1, allowing high success probability without amplitude amplification in quantum walks and Markov chain simulations.
Where Pith is reading between the lines
- The same term reduction may be available for other preconditioners that produce doubly stochastic forms beyond the two methods named in the abstract.
- The eigenvector property with eigenvalue 1 could be combined with existing quantum-walk speed-ups that already rely on stationary distributions.
Load-bearing premise
The target matrix can be transformed into a doubly stochastic matrix via Sinkhorn scaling or completion to a larger dimension without destroying the structure needed for the subsequent decomposition and LCU embedding.
What would settle it
Running the bottleneck algorithm on a sequence of random dense N-by-N matrices for increasing N and verifying that the number of extracted permutations exceeds O(N log(1/ε)) for any fixed small ε would falsify the claimed bound.
Figures
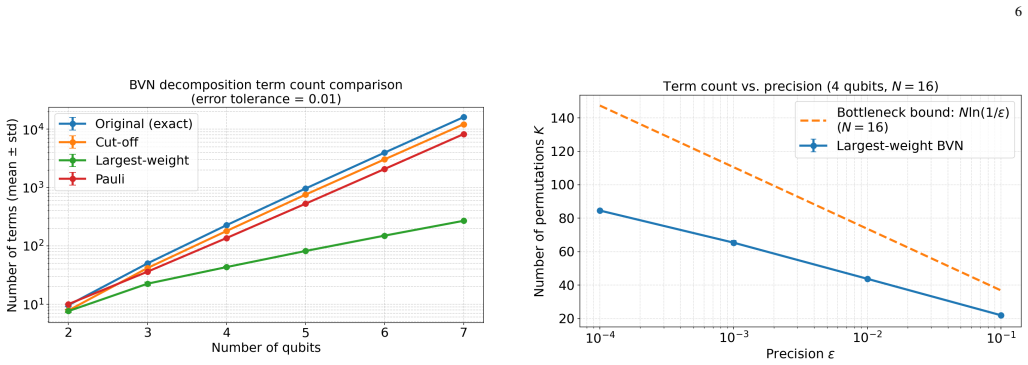
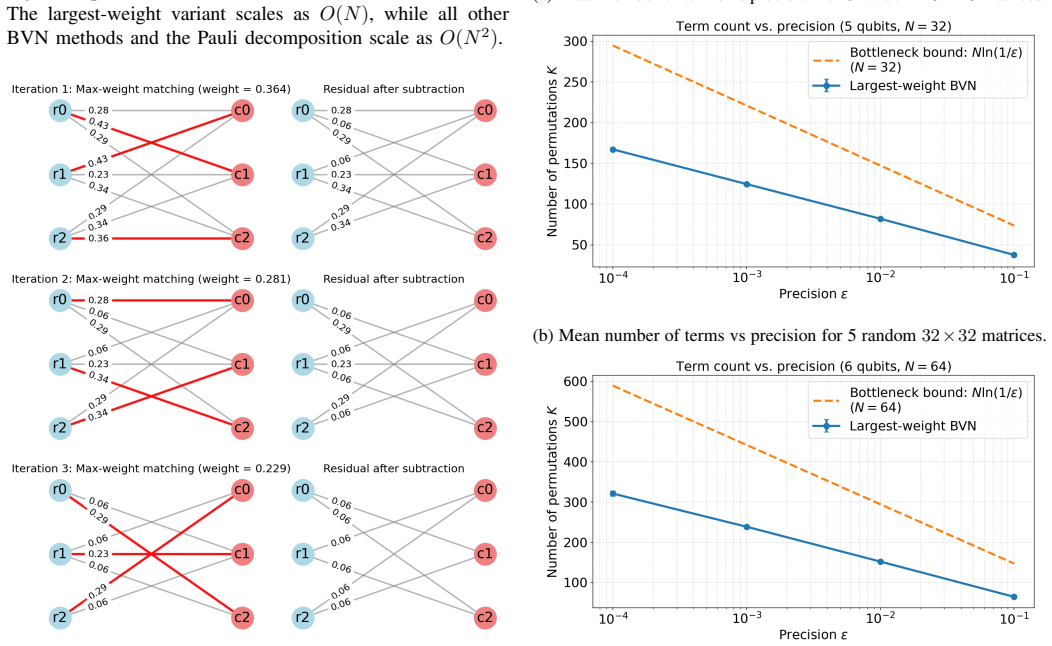
read the original abstract
Any square matrix can be transformed into a doubly stochastic matrix via Sinkhorn scaling with diagonal matrices or completing to a larger dimensional matrix. Standard Birkhoff-von Neumann and Pauli decompositions represent such matrices as linear combinations of $O(N^2)$ permutation or Pauli terms, leading to a large ancilla overhead in a quantum Linear Combination of Unitaries (LCU) implementation. We prove that a bottleneck variant of Birkhoff's algorithm reduces the number of permutations to $O(N\log(1/\varepsilon))$, where $\varepsilon$ is the $\ell_1$-norm approximation error of the reconstructed matrix, and demonstrate empirically that a largest-weight greedy variant requires only $\approx 2N$ terms for dense matrices (the exact average observed is $\approx 2.4N$). The quadratic reduction in term count directly shrinks the ancilla register from $2\log_2 N$ to $\log_2 N$ qubits, shortens the SELECT circuit, and is especially valuable in fixed-Hadamard LCU architectures whose success probability scales with $1/K$. The approach enables compact quantum implementations of dense operators appearing in optimal transport, non-Hermitian simulation, and other settings amenable to Sinkhorn preconditioning. Furthermore, because the decomposition is a convex combination, the LCU normalization constant is exactly $\alpha = 1$, and the uniform superposition is an eigenvector of the target matrix with eigenvalue~1. This structure can be exploited to achieve high success probability without amplitude amplification in many practical scenarios, including quantum walks and Markov chain simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that any square matrix can be mapped to a doubly stochastic form via Sinkhorn scaling (with diagonal factors) or dimension completion, after which a bottleneck variant of Birkhoff's algorithm yields a decomposition into O(N log(1/ε)) permutation matrices (empirically ≈2.4N terms for dense matrices). This reduces LCU ancilla overhead from 2log₂N to log₂N qubits, shortens the SELECT circuit, guarantees α=1 exactly, and enables high success probability without amplification for applications such as optimal transport and non-Hermitian simulation.
Significance. If the central claims hold, the work supplies a concrete, parameter-free route to lower qubit count and circuit depth for LCU embeddings of dense operators. The O(N log(1/ε)) proof and the reproducible empirical scaling of ≈2.4N terms are clear strengths that directly address a known bottleneck in fixed-Hadamard LCU architectures.
major comments (1)
- [Abstract, first paragraph] Abstract (first paragraph) and §1: the claim that an arbitrary square matrix—including non-Hermitian or signed matrices—can be transformed into a doubly stochastic matrix while preserving the convex-combination property (α=1) and the O(N log(1/ε)) term bound rests on Sinkhorn scaling or completion. Standard Birkhoff-von Neumann decomposition applies only to non-negative matrices; the manuscript must explicitly show how negative or complex entries are handled (e.g., via the completion construction) without inflating the effective dimension or term count enough to cancel the claimed ancilla reduction.
minor comments (1)
- The empirical statement “the exact average observed is ≈2.4N” should be accompanied by the matrix ensemble, number of trials, and any exclusion criteria so that the ≈2N scaling claim can be reproduced.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract, first paragraph] Abstract (first paragraph) and §1: the claim that an arbitrary square matrix—including non-Hermitian or signed matrices—can be transformed into a doubly stochastic matrix while preserving the convex-combination property (α=1) and the O(N log(1/ε)) term bound rests on Sinkhorn scaling or completion. Standard Birkhoff-von Neumann decomposition applies only to non-negative matrices; the manuscript must explicitly show how negative or complex entries are handled (e.g., via the completion construction) without inflating the effective dimension or term count enough to cancel the claimed ancilla reduction.
Authors: We agree the manuscript would benefit from an explicit description of the completion construction. In the revised version we will add a dedicated paragraph in §1 (with a small illustrative example) showing how an arbitrary real matrix A is embedded into a non-negative doubly stochastic matrix B of dimension at most 2N by appending a single non-negative block chosen to restore row/column sums of 1 while leaving the action of A on the original subspace unchanged. The same block-augmentation works for complex entries after separating real and imaginary parts (each embedded independently). Because the new dimension M satisfies M ≤ 2N, the term count scales as O(M log(1/ε)) and the ancilla width remains log₂M = log₂N + O(1) rather than the original 2log₂M; the quadratic reduction relative to a naïve O(M²) decomposition is therefore preserved and the claimed ancilla saving is not cancelled. We will also note that Sinkhorn scaling is used only when A is already non-negative. revision: yes
Circularity Check
No circularity detected in the claimed algorithmic bound or empirical term count
full rationale
The paper states a mathematical proof that a bottleneck variant of Birkhoff's algorithm yields O(N log(1/ε)) permutations and reports an empirical observation of ≈2.4N terms for the greedy variant. These results are presented as direct algorithmic and experimental outcomes without any reduction to a fitted parameter defined by the same decomposition, without self-citation load-bearing the central bound, and without renaming or smuggling an ansatz. The derivation chain for the term-count reduction is therefore self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Any square matrix can be transformed into a doubly stochastic matrix via Sinkhorn scaling with diagonal matrices or completing to a larger dimensional matrix.
- standard math Birkhoff-von Neumann theorem: a doubly stochastic matrix is a convex combination of permutation matrices.
Reference graph
Works this paper leans on
-
[1]
Hamiltonian simulation using linear com- binations of unitary operations,
A. M. Childs and N. Wiebe, “Hamiltonian simulation using linear com- binations of unitary operations,”Quantum Information & Computation, vol. 12, no. 11-12, pp. 901–924, 2012
2012
-
[2]
Simulating hamiltonian dynamics with a truncated taylor series,
D. W. Berry, A. M. Childs, R. Cleve, R. Kothari, and R. D. Somma, “Simulating hamiltonian dynamics with a truncated taylor series,”Phys- ical Review Letters, vol. 114, no. 9, p. 090502, 2015
2015
-
[3]
Grand unification of quantum algorithms,
J. M. Martyn, Z. M. Rossi, A. K. Tan, and I. L. Chuang, “Grand unification of quantum algorithms,”PRX Quantum, vol. 2, no. 4, p. 040203, 2021
2021
-
[4]
Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics,
A. Gily ´en, Y . Su, G. H. Low, and N. Wiebe, “Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics,” inProceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pp. 193–204, ACM, 2019
2019
-
[5]
Explicit quantum circuits for block encodings of certain sparse matrices,
D. Camps, L. Lin, R. Van Beeumen, and C. Yang, “Explicit quantum circuits for block encodings of certain sparse matrices,”SIAM Journal on Matrix Analysis and Applications, vol. 45, no. 1, pp. 801–827, 2024
2024
-
[6]
Preconditioned block encodings for quantum linear systems,
L. Lapworth and C. S ¨underhauf, “Preconditioned block encodings for quantum linear systems,”Quantum Science and Technology, vol. 10, no. 4, p. 045064, 2025
2025
-
[7]
Compact quantum algorithms for time-dependent differential equations,
S. S. Bharadwaj and K. R. Sreenivasan, “Compact quantum algorithms for time-dependent differential equations,”Physical Review Research, vol. 7, no. 2, p. 023262, 2025. 8
2025
-
[8]
Quantum algorithm for solving differential equations using SLAC derivatives
R. M. Gharat, G. Muraleedharan, D. W. Berry, and G. K. Brennen, “Quantum algorithm for solving differential equations using slac deriva- tives,”arXiv preprint arXiv:2605.04861, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Quantum algorithm for solving linear differential equations: Theory and experiment,
T. Xin, S. Wei, J. Cui, J. Xiao, I. Arrazola, L. Lamata, X. Kong, D. Lu, E. Solano, and G. Long, “Quantum algorithm for solving linear differential equations: Theory and experiment,”Physical Review A, vol. 101, no. 3, p. 032307, 2020
2020
-
[10]
J. Zhai, M. Abdullah, B. Chen, F. Chaudry, P. N. Smith, C. E. Heaney, Y . Wang, J. Xiang, and C. C. Pain, “Quantum neural physics: Solving partial differential equations on quantum simulators using quantum convolutional neural networks,”arXiv preprint arXiv:2603.24196, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Nonunitary quantum machine learning,
J. Heredge, M. West, L. Hollenberg, and M. Sevior, “Nonunitary quantum machine learning,”Physical Review Applied, vol. 23, no. 4, p. 044046, 2025
2025
-
[12]
Nuclear physics in the era of quantum computing and quantum machine learning,
J.-E. Garc ´ıa-Ramos, ´A. S ´aiz, J. M. Arias, L. Lamata, and P. P ´erez- Fern´andez, “Nuclear physics in the era of quantum computing and quantum machine learning,”Advanced Quantum Technologies, vol. 8, no. 12, p. 2300219, 2025
2025
-
[13]
Majorana tensor decomposition: A unifying framework for decompositions of fermionic hamiltonians to linear combination of unitaries,
I. Loaiza, A. Sankar Brahmachari, and A. F. Izmaylov, “Majorana tensor decomposition: A unifying framework for decompositions of fermionic hamiltonians to linear combination of unitaries,”Quantum Science and Technology, vol. 10, no. 3, p. 035035, 2025
2025
-
[14]
Efficient quantum access model for sparse structured matrices using linear combination of “things
A. Gnanasekaran and A. Surana, “Efficient quantum access model for sparse structured matrices using linear combination of “things”,” Physical Review A, vol. 113, no. 2, p. 022437, 2026
2026
-
[15]
Efficient lcu block encodings through dicke states preparation,
F. Della Chiara, M. Nibbi, Y . Shen, and R. Van Beeumen, “Efficient lcu block encodings through dicke states preparation,”arXiv preprint arXiv:2507.20887, 2025
-
[16]
Quantum speed-up of markov chain based algorithms,
M. Szegedy, “Quantum speed-up of markov chain based algorithms,” in45th Annual IEEE symposium on foundations of computer science, pp. 32–41, IEEE, 2004
2004
-
[17]
Entropic optimal transport with quantum amplitude estimation,
F. Orts, “Entropic optimal transport with quantum amplitude estimation,” Future Generation Computer Systems, p. 108570, 2026
2026
-
[18]
The birkhoff theorem for unitary matrices of prime-power dimension,
A. De V os and S. De Baerdemacker, “The birkhoff theorem for unitary matrices of prime-power dimension,”Linear Algebra and its Applica- tions, vol. 578, pp. 27–52, 2019
2019
-
[19]
A quantum compiler design method by using linear com- binations of permutations,
A. Daskin, “A quantum compiler design method by using linear com- binations of permutations,”arXiv preprint arXiv:2404.18226, 2024
-
[20]
Error analysis of quantum operators written as a linear combination of permutations,
A. Daskin, “Error analysis of quantum operators written as a linear combination of permutations,”Quantum Information Processing, vol. 24, no. 5, p. 149, 2025
2025
-
[21]
R. A. Brualdi,Combinatorial matrix classes, vol. 13. Cambridge University Press, 2006
2006
-
[22]
Scheduling techniques for hybrid circuit/packet networks,
H. Liu, M. K. Mukerjee, C. Li, N. Feltman, G. Papen, S. Savage, S. Seshan, G. M. V oelker, D. G. Andersen, M. Kaminsky,et al., “Scheduling techniques for hybrid circuit/packet networks,” inProceed- ings of the 11th ACM Conference on Emerging Networking Experiments and Technologies, pp. 1–13, 2015
2015
-
[23]
Costly circuits, submodular schedules and approximate carath´eodory theorems,
S. Bojja Venkatakrishnan, M. Alizadeh, and P. Viswanath, “Costly circuits, submodular schedules and approximate carath´eodory theorems,” Queueing Systems, vol. 88, no. 3, pp. 311–347, 2018
2018
-
[24]
Birkhoff’s decomposition revisited: Sparse scheduling for high-speed circuit switches,
V . Valls, G. Iosifidis, and L. Tassiulas, “Birkhoff’s decomposition revisited: Sparse scheduling for high-speed circuit switches,”IEEE/ACM Transactions on Networking, vol. 29, no. 6, pp. 2399–2412, 2021
2021
-
[25]
Concerning nonnegative matrices and doubly stochastic matrices,
R. Sinkhorn and P. Knopp, “Concerning nonnegative matrices and doubly stochastic matrices,”Pacific Journal of Mathematics, vol. 21, no. 2, pp. 343–348, 1967
1967
-
[26]
Efficient quantum circuits for diagonal unitaries without ancillas,
J. Welch, D. Greenbaum, S. Mostame, and A. Aspuru-Guzik, “Efficient quantum circuits for diagonal unitaries without ancillas,”New Journal of Physics, vol. 16, no. 3, p. 033040, 2014
2014
-
[27]
An nˆ5/2 algorithm for maximum matchings in bipartite graphs,
J. E. Hopcroft and R. M. Karp, “An nˆ5/2 algorithm for maximum matchings in bipartite graphs,”SIAM Journal on computing, vol. 2, no. 4, pp. 225–231, 1973
1973
-
[28]
Paths, trees, and flowers,
J. Edmonds, “Paths, trees, and flowers,”Canadian Journal of mathemat- ics, vol. 17, pp. 449–467, 1965
1965
-
[29]
H. N. Gabow,Implementation of algorithms for maximum matching on nonbipartite graphs.Stanford University, 1974
1974
-
[30]
Linear-time approximation for maximum weight matching,
R. Duan and S. Pettie, “Linear-time approximation for maximum weight matching,”Journal of the ACM (JACM), vol. 61, no. 1, pp. 1–23, 2014
2014
-
[31]
Notes on the birkhoff algorithm for doubly stochastic matrices,
R. A. Brualdi, “Notes on the birkhoff algorithm for doubly stochastic matrices,”Canadian Mathematical Bulletin, vol. 25, no. 2, pp. 191–199, 1982
1982
-
[32]
Further notes on birkhoff–von neumann decomposition of doubly stochastic matrices,
F. Dufoss ´e, K. Kaya, I. Panagiotas, and B. Uc ¸ar, “Further notes on birkhoff–von neumann decomposition of doubly stochastic matrices,” Linear Algebra and its Applications, vol. 554, pp. 68–78, 2018
2018
-
[33]
Minimum birkhoff-von neumann decomposition,
J. Kulkarni, E. Lee, and M. Singh, “Minimum birkhoff-von neumann decomposition,” inInternational Conference on Integer Programming and Combinatorial Optimization, pp. 343–354, Springer, 2017
2017
-
[34]
Diagonals of doubly stochastic matrices,
M. Marcus and R. Ree, “Diagonals of doubly stochastic matrices,”The Quarterly Journal of Mathematics, vol. 10, no. 1, pp. 296–302, 1959
1959
-
[35]
A note on erd ˝os matrices and marcus–ree inequality,
A. Kushwaha and R. Tripathi, “A note on erd ˝os matrices and marcus–ree inequality,”Linear Algebra and its Applications, vol. 725, pp. 223–247, 2025
2025
-
[36]
A. Daskin, “Exploiting all ancilla outcomes in linear combinations of unitaries: low-rank recovery and quantum trapdoor functions,”arXiv preprint arXiv:2605.02986, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Synthesis of reversible logic circuits,
V . V . Shende, A. K. Prasad, I. L. Markov, and J. P. Hayes, “Synthesis of reversible logic circuits,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 22, no. 6, pp. 710–722, 2003
2003
-
[38]
Synthesis and optimization of reversible circuits—a survey,
M. Saeedi and I. L. Markov, “Synthesis and optimization of reversible circuits—a survey,”ACM Computing Surveys (CSUR), vol. 45, no. 2, pp. 1–34, 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.