MGRetrieval: Memory-Guided Reflective Retrieval for Long-Term Dialogue Agents
Pith reviewed 2026-06-30 14:56 UTC · model grok-4.3
The pith
MGRetrieval grounds retrieval in the semantic structure of historical memories to build precise paths for long-term dialogue agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
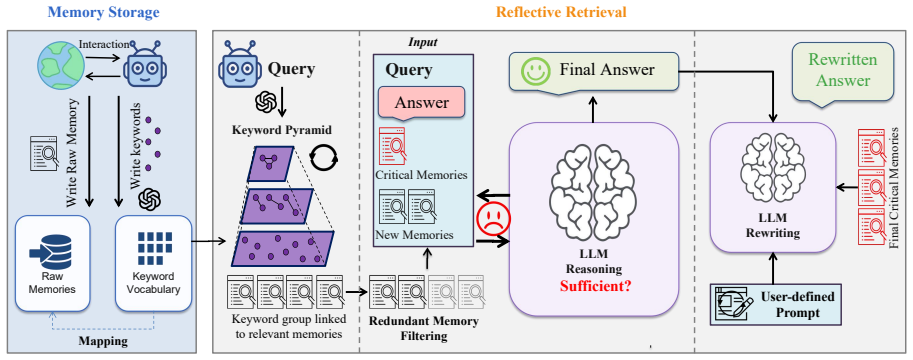
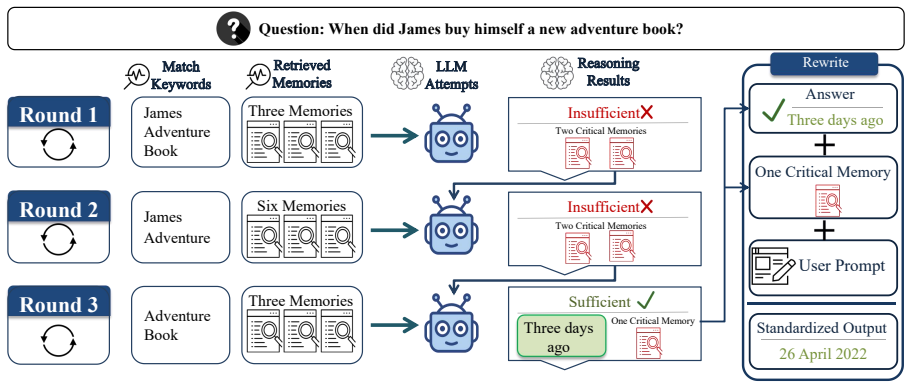
MGRetrieval performs reflective retrieval by first consulting the semantic structure of accumulated historical memories to construct a more precise retrieval path, then allowing the LLM to retain only critical memories and to judge whether the gathered set is already sufficient to halt further retrieval. Through this memory-guided process and critical memory propagation, the system incrementally assembles concise and sufficient memory contexts for the dialogue agent.
What carries the argument
Memory-guided reflective retrieval: a two-step loop that references the semantic structure of prior memories to shape each retrieval path and lets the LLM decide when accumulated memories suffice to stop.
If this is right
- Retrieval paths become semantically coherent rather than unstable guesses from limited evidence.
- Critical memory propagation reduces redundancy while preserving necessary context.
- The iterative process stops when the LLM judges sufficiency, avoiding unnecessary extra steps and latency.
- The same gains appear across two different 14B-scale LLMs, suggesting the mechanism is not tied to one model family.
Where Pith is reading between the lines
- The same structure-guided loop could be tested on long-document question answering or multi-turn reasoning tasks that also accumulate large histories.
- If the structure reference is the main driver, replacing the LLM sufficiency check with a lighter heuristic might further reduce latency.
- Combining the memory-structure signal with existing vector or graph indexes could be explored as a hybrid variant.
- The method's emphasis on propagating only critical memories suggests it may help control context length growth in any agent that maintains persistent state over many turns.
Load-bearing premise
That the semantic structure of historical memories supplies a reliably superior guide for retrieval paths compared with paths the LLM invents from partial evidence, and that the LLM can correctly judge when enough memories have been collected.
What would settle it
An ablation on the same LoCoMo tasks and models in which the historical-memory-structure reference step is removed and performance falls back to or below the prior reflective baseline.
Figures












read the original abstract
Large Language Models (LLMs) have made significant progress in dialogue, yet redundant memory contexts severely limit their effectiveness in long-term dialogue agents. External memory systems have been proposed to improve memory maintenance. However, these systems mainly rely on one-shot retrieval, which limits their ability to retrieve sufficient and relevant evidence. Although recent methods introduce reflection into retrieval, their retrieval paths are generated by the LLM from limited evidence, leading to unstable retrieval and additional latency overhead. %These limitations highlight the need for effective retrieval mechanisms. To address these limitations, we propose MGRetrieval, a retrieval strategy that grounds reflective retrieval in the semantic structure of historical memories. Specifically, MGRetrieval consists of two steps: (1) It references the structure of historical memories to construct a more precise retrieval path. (2) The LLM retains critical memories and determines whether accumulated memories are sufficient to stop further iterative retrieval. This allows the retrieval process to follow semantically meaningful paths. Through memory-guided retrieval and critical memory propagation, MGRetrieval gradually constructs concise and sufficient memory contexts. Extensive experiments on LoCoMo show that MGRetrieval outperforms the strongest baseline by 8.91\% in F1 and 11.11\% in BLEU-1 on average across Qwen2.5-14B and Qwen3-14B, while maintaining practical token and latency costs. The code can be found in https://anonymous.4open.science/r/MGRetrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MGRetrieval, a memory-guided reflective retrieval method for long-term dialogue agents. It constructs retrieval paths by referencing the semantic structure of historical memories rather than generating them from limited evidence via LLM, and uses the LLM to retain critical memories while deciding when accumulated evidence suffices to halt iteration. On the LoCoMo benchmark, it reports average gains of 8.91% F1 and 11.11% BLEU-1 over the strongest baseline across Qwen2.5-14B and Qwen3-14B, with practical token and latency costs. Code is provided via an anonymous link.
Significance. If the performance gains can be attributed to the proposed mechanisms, the work could provide a more stable and semantically grounded alternative to existing reflective retrieval approaches in memory-augmented LLMs, reducing instability and overhead in long-term dialogue. The code release is a positive step toward reproducibility.
major comments (2)
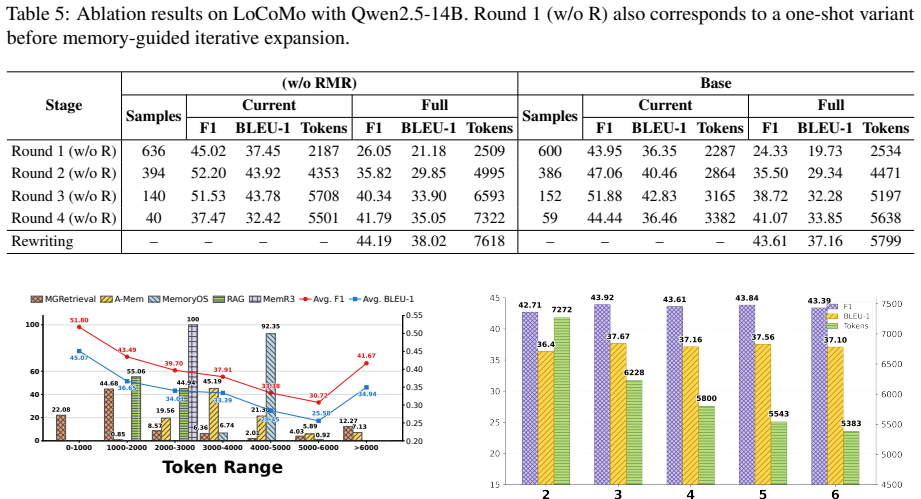
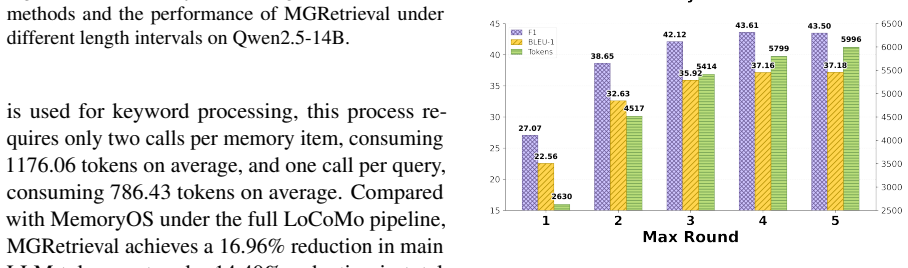
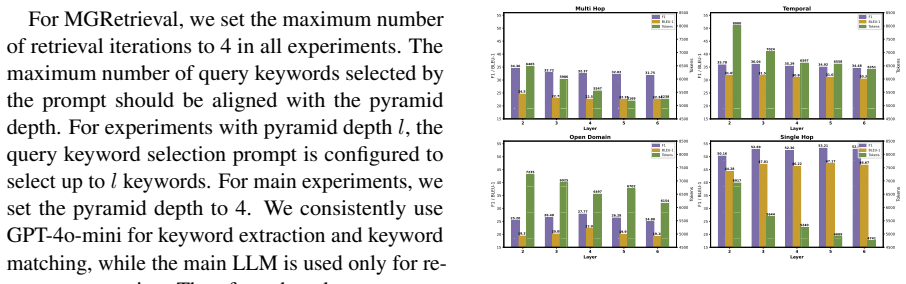
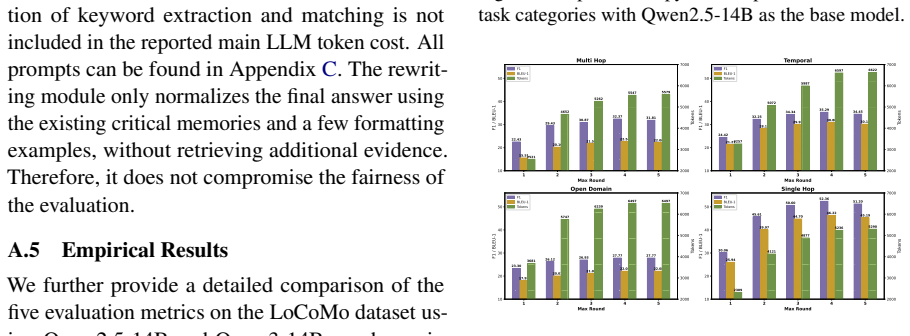
- [Experiments] Experimental section: No ablation studies isolate the contribution of the memory-structure-guided path construction (step 1) or the LLM stopping criterion (step 2) from standard reflective retrieval or implementation choices. Without these, it is impossible to confirm that the reported 8.91% F1 / 11.11% BLEU-1 gains are due to the proposed components rather than other factors, directly undermining attribution of the central empirical claim.
- [Method] Method and Experiments: The paper provides no direct evaluation (e.g., path-quality metrics, comparison of generated paths, or human correlation) of whether referencing historical memory structure yields more precise paths than LLM-generated paths from limited evidence, nor any error analysis on the accuracy of the LLM's sufficiency judgment. These are the two load-bearing premises for the claimed improvement.
minor comments (1)
- [Abstract] Abstract: A stray LaTeX comment ('%These limitations highlight the need for effective retrieval mechanisms.') remains in the text and should be removed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on MGRetrieval. The comments highlight important aspects of experimental validation needed to strengthen attribution of the reported gains. We address each major comment below and commit to incorporating the suggested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experimental section: No ablation studies isolate the contribution of the memory-structure-guided path construction (step 1) or the LLM stopping criterion (step 2) from standard reflective retrieval or implementation choices. Without these, it is impossible to confirm that the reported 8.91% F1 / 11.11% BLEU-1 gains are due to the proposed components rather than other factors, directly undermining attribution of the central empirical claim.
Authors: We agree that ablation studies are required to isolate the contributions of the memory-structure-guided path construction and the LLM stopping criterion. In the revised manuscript, we will add these ablations by systematically disabling each component and comparing against standard reflective retrieval baselines, thereby clarifying the source of the observed performance improvements on LoCoMo. revision: yes
-
Referee: [Method] Method and Experiments: The paper provides no direct evaluation (e.g., path-quality metrics, comparison of generated paths, or human correlation) of whether referencing historical memory structure yields more precise paths than LLM-generated paths from limited evidence, nor any error analysis on the accuracy of the LLM's sufficiency judgment. These are the two load-bearing premises for the claimed improvement.
Authors: We acknowledge the value of direct evaluations for the two core premises. The revised version will include path-quality metrics (such as precision of constructed paths versus LLM-generated alternatives) along with an error analysis of the LLM's sufficiency judgments, providing quantitative support for the memory-guided approach. revision: yes
Circularity Check
No circularity; method is procedural with external benchmark validation
full rationale
The paper describes MGRetrieval as a two-step procedural retrieval strategy referencing historical memory structure and LLM stopping decisions. No equations, fitted parameters, self-citations, or derivations are present that reduce any claimed result to its inputs by construction. Performance gains (8.91% F1, 11.11% BLEU-1) are reported on the external LoCoMo benchmark across Qwen models, providing independent empirical grounding rather than internal self-definition or renaming. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972–25981
Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972–25981. Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open- domain question answering. InProceedings of the 2020 conference on empi...
2025
-
[2]
InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6342–6353
Compressing context to enhance inference ef- ficiency of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 6342–6353. Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81. Nelson F Liu, Kevin Lin, John Hewitt, Ashwin P...
2023
-
[3]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. John Mendonça, Alon Lavie, and Isabel Trancoso. 2024. On the benchmarking of llms for open-domain dia- logue evaluation. InProceedings of the 6th Workshop on N...
2024
-
[4]
Vicky Zhao, Lili Qiu, and Jianfeng Gao
On memory construction and retrieval for personalized conversational agents.arXiv preprint arXiv:2502.05589. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evalu- ation of machine translation. InProceedings of the 40th annual meeting of the Association for Computa- tional Linguistics, pages 311–318. Zhihon...
-
[5]
Tokens and Calls.We divide the full LoCoMo pipeline into memory bank construction and ques- tion answering
measures unigram alignment between the generated answer and the reference answer while taking synonyms and paraphrases into account: METEOR =F mean ·(1−Penalty),(24) where Fmean = 10P R R+ 9P ,(25) and Penalty = 0.5· ch m 3 .(26) Here, P and R denote unigram precision and recall, ch is the number of chunks, and m is the number of matched unigrams. Tokens ...
2020
-
[6]
The Name of the Wind
maintains long-term memory by preserving historical memories, event-level summaries, and user profile information, while adjusting memory strength with a forgetting mechanism inspired by the Ebbinghaus curve. It encodes memory units into dense representations and selects the most rel- evant memories according to the query context. A-Mem.A-Mem (Xu et al., ...
2025
-
[7]
Skip greeting content
-
[8]
Extract 1-10 keywords from {speaker_a}'s text into one_stage, and 1-10 keywords from {speaker_b}'s text into two_stage
-
[9]
Prioritize, in order: proper nouns (especially person names, place names, organization names, and titles), then concrete events or activities, then important objects or topics, and finally crucial adjectives or verbs only when they carry core meaning
-
[10]
Only extract content that explicitly appears in the source text
Keywords must be copied exactly from the original text. Only extract content that explicitly appears in the source text. Do not infer, paraphrase, normalize, or summarize
-
[11]
Treat both phrases and hyphenated compounds as multiple single words
If the keyword is a multi-word phrase or a hyphenated compound word, first identify the full unit internally, then split it into its original single words and return all of those words separately in the same original order. Treat both phrases and hyphenated compounds as multiple single words
-
[12]
Do not drop words that are part of a proper noun, title, organization name, or event name, even if some of those words are normally function words
Do not merge, rewrite, or reorder words. Do not drop words that are part of a proper noun, title, organization name, or event name, even if some of those words are normally function words
-
[13]
Outside of selected named entities, titles, organizations, and event names, do not use modal particles, question words, interjections, pronouns, or other function/filler words. Also exclude greetings, politeness, discourse markers, generic praise, vague temporal words, and wrapper words such as: great, nice, okay, time, talk, again, photo, image, picture, general
-
[14]
If a selected keyword is split into multiple single words, those words together count as one keyword unit
Extract high-value keywords within the allowed range, but do not include low-information or repetitive items just to fill the quota. If a selected keyword is split into multiple single words, those words together count as one keyword unit
-
[15]
total": [
Order returned words by importance of the keyword unit first, and by original word order within each split keyword unit. Deduplicate exact duplicates and near-duplicates; keep only the most informative form. Do not mix sources: one_stage must come only from {speaker_a}'s text, and two_stage only from {speaker_b}'s text. Figure 11: The prompt for memory ke...
-
[16]
total must contain every keyword from latest_total_keywords and preserve their original order
-
[17]
You may only append keywords that already exist in database_keywords
-
[18]
Only append a database keyword when you believe one or more latest keywords can be grouped under that existing database keyword
-
[19]
Do not remove any keyword from latest_total_keywords
-
[20]
Do not invent any new keyword outside database_keywords
-
[21]
keywords
Return latest_total_keywords first, then append the selected database_keywords. This is my latest conversation and the keywords extracted from it. Latest conversation {speaker_a}: {user_input} Latest conversation {speaker_b}: {agent_response} latest_total_keywords: [...] database_keywords: [...] Your task is to decide whether any latest keywords can be gr...
-
[22]
Do NOT select any keyword that is absent from the candidate list
Every selected keyword MUST appear verbatim in the candidate keyword list (case-insensitive match). Do NOT select any keyword that is absent from the candidate list
-
[23]
Keywords do not need to match the current question text exactly, as long as they capture important information in the question, such as people, places, or object types, or otherwise help memory retrieval
-
[24]
What did the charity race raise awareness for?
You may do limited inference, summarization, or generalization, but do not expand, paraphrase, normalize, or translate. Keep close to literal surface-form matching. Select 1-{keywords_number} of the most distinctive keywords that satisfy all rules above. Prioritize, in order: person names and place names, then organization names and titles, then concrete ...
2023
-
[25]
last week
If the question involves When, and the answer or the supporting dialogue contains a relative time expression such as "last week", "last weekend", "yesterday", "today", "tomorrow", "this month", or "last Friday", you must use the Time in <KEY MEMORY> together with the dialogue to reason and normalize the answer into an anchored form that matches the dialog...
2023
-
[26]
How long ago was Caroline's 18th birthday?
If the question asks about duration, answer in the form of several years, months, or days. For example, when the question is "How long ago was Caroline's 18th birthday?", and <KEY MEMORY> is " 【Historical Memory】\nCaroline: Yep, Melanie! I've got some other stuff with sentimental value, like my hand-painted bowl. A friend made it for my 18th birthday ten ...
2023
-
[27]
has", "is
If the question starts with an auxiliary such as "has", "is", "did", or "would" and is asking for a yes-or-no judgment, answer only "Yes" or "No" with no extra explanation. For example, when the question is "Has Andrew moved into a new apartment for his dogs?", answer "No". Keep the answer field within {answer_token_limit} tokens. If the current turn does...
-
[28]
Assign 1 if the retrieved memories contain the information needed to answer the question; otherwise assign 0
Memory Retrieval Accuracy: 0 or 1. Assign 1 if the retrieved memories contain the information needed to answer the question; otherwise assign 0
-
[29]
Assign 1 if the model response correctly answers the question, 0.5 if it is partially correct, and 0 if it is incorrect or unsupported
Response Correctness: 0, 0.5, or 1. Assign 1 if the model response correctly answers the question, 0.5 if it is partially correct, and 0 if it is incorrect or unsupported
-
[30]
memory_retrieval_accuracy
Contextual Coherence: 0, 0.5, or 1. Assign 1 if the response naturally and coherently connects the dialogue context with the retrieved memories, 0.5 if it is partially coherent, and 0 if it is incoherent or inconsistent with the context. Input: Memory Bank: {memory_bank} Retrieved Memories: {retrieved_memories} Question: {question} Ground-truth Answer: {g...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.