A Unified Structured Query Understanding Framework for Industrial Semantic Search
Pith reviewed 2026-06-30 14:47 UTC · model grok-4.3
The pith
A single small language model replaces multiple task-specific components for structured query understanding in industrial search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
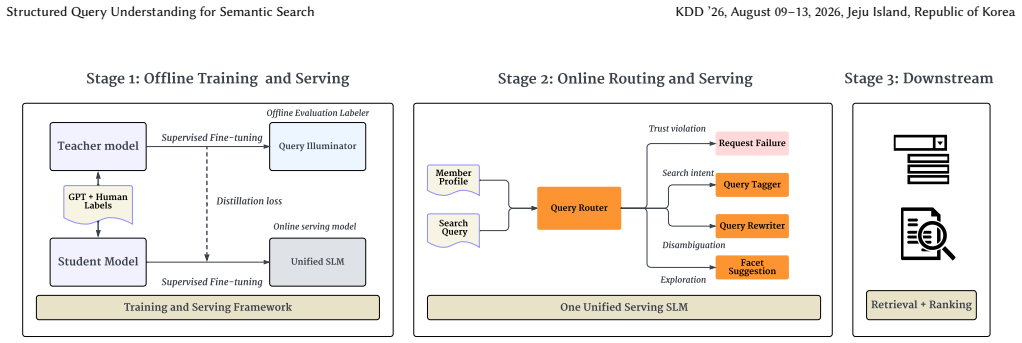
The authors establish that heterogeneous query understanding functions can be consolidated into a single small language model performing schema-constrained generation, with Query Illuminator serving as both a teacher for auto-annotation and a surrogate judge for scalable evaluation.
What carries the argument
A single small language model that performs schema-constrained generation to unify previously separate task-specific query understanding components.
Load-bearing premise
A single small language model can match or exceed the combined performance of multiple specialized components when outputs are constrained to a schema.
What would settle it
An online deployment test showing no gain in user engagement metrics or a breach of latency limits on the target hardware would show the unified model does not deliver the claimed advantages.
Figures


read the original abstract
Query understanding in large-scale industrial search systems is typically implemented as a cascade of disparate, task-specific components. While individually optimizable, this fragmented architecture incurs high maintenance overhead and results in inconsistent behaviors, particularly for long-tail queries. In this work, we propose and deploy a unified structured query understanding system that consolidates these heterogeneous functions into a single Small Language Model (SLM) that performs schema-constrained generation. To address the data bottlenecks inherent in unified modeling, we introduce Query Illuminator, a dual-purpose framework serving as: (i) a teacher model for high-quality auto-annotation and distillation, and (ii) a surrogate judge for scalable evaluation where human labels are scarce. We validate this approach through extensive offline and online tests within LinkedIn's Job Search system. Furthermore, we demonstrate the framework's horizontal extensibility through a cross-domain case study on People Search. The results show improved user engagement and reduced operational costs, achieved while satisfying strict low-latency serving constraints on limited GPU resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that query understanding in industrial search can be unified into a single small language model performing schema-constrained generation, replacing a cascade of task-specific components. Query Illuminator is introduced as a dual-purpose framework for high-quality auto-annotation/distillation and as a surrogate judge for scalable evaluation. The approach is validated via offline and online tests in LinkedIn Job Search, with a cross-domain case study on People Search, yielding improved engagement, lower costs, and compliance with low-latency constraints on limited GPUs.
Significance. If the claimed gains are shown to be non-circular and supported by independent metrics, the work could meaningfully reduce maintenance overhead and inconsistency in production query-understanding pipelines while demonstrating practical deployment of SLMs under strict serving constraints.
major comments (2)
- [Abstract] Abstract: the central claim of improved user engagement, reduced operational costs, and maintained low latency rests on 'extensive offline and online tests' yet supplies no quantitative metrics, baselines, ablation results, error analysis, or training details; without these the superiority over the cascade architecture cannot be evaluated.
- [Abstract] Abstract (Query Illuminator description): the framework is positioned as both teacher for distillation data and surrogate judge for evaluation in human-label-scarce settings; no description is given of how independence is maintained (separate parameters, disjoint data, or external human hold-out), which directly threatens the validity of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Where the comments correctly identify gaps in the abstract, we have revised the manuscript to strengthen clarity and substantiation of claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of improved user engagement, reduced operational costs, and maintained low latency rests on 'extensive offline and online tests' yet supplies no quantitative metrics, baselines, ablation results, error analysis, or training details; without these the superiority over the cascade architecture cannot be evaluated.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we have updated the abstract to report specific online A/B test outcomes (e.g., relative engagement lift, cost reduction percentage, and p99 latency on the target GPU hardware) together with explicit references to the cascade baseline, ablation studies, and error analysis that appear in Sections 4 and 5. Training details and hyper-parameters remain in the experimental section as they exceed abstract length limits. revision: yes
-
Referee: [Abstract] Abstract (Query Illuminator description): the framework is positioned as both teacher for distillation data and surrogate judge for evaluation in human-label-scarce settings; no description is given of how independence is maintained (separate parameters, disjoint data, or external human hold-out), which directly threatens the validity of the reported improvements.
Authors: We acknowledge the need to explicitly state the independence safeguards. The revised abstract and the expanded Section 3.2 now clarify that the teacher and judge roles are instantiated as two separately fine-tuned SLM checkpoints, trained on disjoint data partitions, and that the surrogate judge’s alignment with human labels is measured on an external held-out human-annotated test set that is never used for distillation or training. revision: yes
Circularity Check
No significant circularity; engineering proposal is self-contained
full rationale
The manuscript presents a system architecture (unified SLM for schema-constrained generation) and a practical dual-use component (Query Illuminator for auto-annotation plus surrogate judging). No equations, derivations, fitted parameters, or prediction steps appear. The dual role is an explicit design decision to address data scarcity; it does not reduce any reported result to its own inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The evaluation claims rest on offline/online tests whose independence is not shown to collapse into the training loop within the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sanjay Agrawal, Srujana Merugu, and Vivek Sembium. 2023. Enhancing e- commerce product search through reinforcement learning-powered query refor- mulation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 4488–4494
2023
-
[2]
2010.Estimating the Query Difficulty for Infor- mation Retrieval
David Carmel and Elad Yom-Tov. 2010.Estimating the Query Difficulty for Infor- mation Retrieval. Morgan & Claypool Publishers
2010
-
[3]
Steve Cronen-Townsend, Yun Zhou, and W. Bruce Croft. 2002. Predicting Query Performance. InProceedings of the 25th Annual International ACM SIGIR Con- ference on Research and Development in Information Retrieval (SIGIR). 299–306. doi:10.1145/564376.564429
-
[4]
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2023. UltraFeedback: Boosting Language Models with Scaled AI Feedback. arXiv:2310.01377 [cs.CL] doi:10.48550/arXiv.2310.01377
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01377 2023
-
[5]
Kaustubh D Dhole and Eugene Agichtein. 2024. Genqrensemble: Zero-shot llm ensemble prompting for generative query reformulation. InEuropean Conference on Information Retrieval. Springer, 326–335
2024
-
[6]
Yixin Dong, Charlie F Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen. 2024. Xgrammar: Flexible and efficient structured generation engine for large language models.Proceedings of Machine Learning and Systems 7(2024)
2024
-
[7]
Yunling Feng, Gui Ling, Yue Jiang, Jianfeng Huang, Dan Ou, Qingwen Liu, Fuyu Lv, and Yajing Xu. 2025. Complicated Semantic Alignment for Long-Tail Query Rewriting in Taobao Search Based on Large Language Model. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4435–4446
2025
-
[8]
Ben He and Iadh Ounis. 2006. Query performance prediction.Information Systems 31, 7 (2006), 585–594. doi:10.1016/j.is.2005.11.003
-
[9]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Rosie Jones, Benjamin Rey, Omid Madani, and Wiley Greiner. 2006. Generating query substitutions. InProceedings of the 15th international conference on World Wide Web. 387–396
2006
-
[11]
Yuchin Juan, Jianqiang Shen, Shaobo Zhang, Qianqi Shen, Caleb Johnson, Luke Simon, Liangjie Hong, and Wenjing Zhang. 2025. Scaling Retrieval for Web- Scale Recommenders: Lessons from Inverted Indexes to Embedding Search. In Proceedings of the 19th ACM Conference on Recommender Systems (RecSys ’25). ACM, Prague, Czech Republic, 1066–1069. doi:10.1145/37053...
-
[12]
Yao Kang, Xin Wang, and Zhiling Lan. 2022. Study of workload interference with intelligent routing on dragonfly. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–14
2022
-
[13]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv:2309.06180 [cs.DC] doi:10.48550/arXiv.2309.06180
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.06180 2023
-
[14]
Guoyao Li, Ran He, Shusen Jing, Kayhan Behdin, Yubo Wang, Sundara Raman Ramachandran, Chanh Nguyen, Jian Sheng, Xiaojing Ma, Chuanrui Zhu, Sri- ram Vasudevan, Muchen Wu, Sayan Ghosh, Lin Su, Qingquan Song, Xiaoqing Wang, Zhipeng Wang, Qing Lan, Yanning Chen, Jingwei Wu, Luke Simon, Wen- jing Zhang, Qi Guo, and Fedor Borisyuk. 2025. MixLM: High-Throughput ...
-
[15]
Sen Li, Fuyu Lv, Taiwei Jin, Guiyang Li, Yukun Zheng, Tao Zhuang, Qingwen Liu, Xiaoyi Zeng, James Kwok, and Qianli Ma. 2022. Query rewriting in taobao search. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 3262–3271
2022
-
[16]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Car- los Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. AlpacaEval: An Automatic Evaluator of Instruction-following Models. https://github.com/tatsu- lab/alpaca_eval. GitHub repository
2023
- [17]
-
[18]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2511–2522. doi:10.18653/v1/2023.emnlp-main.153
-
[19]
Chen Luo, Xianfeng Tang, Hanqing Lu, Yaochen Xie, Hui Liu, Zhenwei Dai, Limeng Cui, Ashutosh Joshi, Sreyashi Nag, Yang Li, et al. 2024. Exploring Query Understanding for Amazon Product Search. In2024 IEEE International Conference on Big Data (BigData). IEEE, 2343–2348
2024
-
[20]
Mehdi Manshadi and Xiao Li. 2009. Semantic tagging of web search queries. In Proceedings of ACL-IJCNLP’09. Association for Computational Linguistics
2009
-
[21]
Feiteng Mu, Yong Jiang, Liwen Zhang, Chu Liu, Wenjie Li, Pengjun Xie, and Fei Huang. 2024. Query Routing for Homogeneous Tools: An Instantiation in the RAG Scenario. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, U...
2024
-
[22]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[23]
Wenjun Peng, Guiyang Li, Yue Jiang, Zilong Wang, Dan Ou, Xiaoyi Zeng, Derong Xu, Tong Xu, and Enhong Chen. 2024. Large language model based long-tail query rewriting in taobao search. InCompanion Proceedings of the ACM Web Conference 2024. 20–28
2024
-
[24]
1995.Okapi at TREC-3
Stephen E Robertson, Steve Walker, Susan Jones, Micheline M Hancock-Beaulieu, Mike Gatford, et al. 1995.Okapi at TREC-3. British Library Research and Devel- opment Department
1995
-
[25]
Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al
-
[26]
Multitask prompted training enables zero-shot task generalization.arXiv preprint arXiv:2110.08207(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761 [cs.CL] doi:10.48550/arXiv.2302.04761
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04761 2023
-
[28]
Timo Schick and Hinrich Schütze. 2021. It’s not just size that matters: Small language models are also few-shot learners. InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: Human language technologies. 2339–2352
2021
-
[29]
Bhawani Selvaretnam and Mohammed Belkhatir. 2012. Natural language tech- nology and query expansion: issues, state-of-the-art and perspectives.Journal of Intelligent Information Systems38, 3 (2012), 709–740
2012
-
[30]
Ninglu Shao, Jinshan Wang, Chenxu Wang, Qingbiao Li, and Xiaoxue Zang. 2025. GREAT: Guiding Query Generation with a Trie for Recommending Related Search about Video at Kuaishou. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4818–4826
2025
-
[31]
Keyue Shi, Qianqian Shen, Zhongda Qi, Junyao Yang, Zhaoming Ye, Jiajun Bu, and Haishuai Wang. 2025. Enhancing Bone Mineral Density Estimation from X-ray Images with Cross-Modal Knowledge Distillation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4861–4871
2025
-
[32]
Krishna Srinivasan, Karthik Raman, Anupam Samanta, Lingrui Liao, Luca Bertelli, and Michael Bendersky. 2022. QUILL: Query Intent with Large Language Models using Retrieval Augmentation and Multi-stage Distillation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track. 492–501
2022
-
[33]
Ruiming Tang, Chenxu Zhu, Bo Chen, Weipeng Zhang, Menghui Zhu, Xinyi Dai, and Huifeng Guo. 2025. Llm4tag: Automatic tagging system for information retrieval via large language models. arXiv.Uses graph-based and knowledge- enhanced tag generation with LLMs(2025)
2025
-
[34]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_ alpaca
2023
-
[35]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/
2024
-
[36]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. InProceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP. 353–355
2018
-
[37]
Maolin Wang, Jun Chu, Sicong Xie, Xiaoling Zang, Yao Zhao, Wenliang Zhong, and Xiangyu Zhao. 2025. Put Teacher in Student’s Shoes: Cross-Distillation for Ultra-compact Model Compression Framework. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4975–4985
2025
-
[38]
Zhibo Wang, Xiaoze Jiang, Zhiheng Qin, and Enyun Yu. 2025. Personalized Query Auto-Completion for Long and Short-Term Interests with Adaptive Detoxification Generation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5018–5028
2025
-
[39]
Zhongyuan Wang, Kejun Zhao, Haixun Wang, Xiaofeng Meng, and Ji-Rong Wen
-
[40]
In IJCAI
Query understanding through knowledge-based conceptualization. In IJCAI
-
[41]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). https: //arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Huining Yuan, Wenpeng Zhang, Zijie Hao, and Zengde Deng. 2025. Hardness- aware privileged features distillation with latent alignment for CVR prediction. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5182–5193. Structured Query Understanding for Semantic Search KDD ’26, August 09–13, 2026, Jeju Island, Republ...
2025
-
[43]
Yunyi Zhang, Ming Zhong, Siru Ouyang, Yizhu Jiao, Sizhe Zhou, Linyi Ding, and Jiawei Han. 2024. Automated mining of structured knowledge from text in the era of large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6644–6654
2024
-
[44]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. arXiv:2306.05685 [cs.CL] doi:10.48550/arXiv.2306.05685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685 2023
-
[45]
Simiao Zuo, Pengfei Tang, Xinyu Hu, Qiang Lou, Jian Jiao, and Denis Charles
-
[46]
retain auxiliary capabilities
Deeptagger: Knowledge enhanced named entity recognition for web- based ads queries. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 5002–5009. Appendix A. Multi-task Fine-tuning as Capability Retention We include a brief interpretation of multi-task fine-tuning that motivates its use as a practical regulariz...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.