A Systematic Evaluation of Retrieval-Augmented Generation and Language Models for Space Operations
Pith reviewed 2026-06-30 12:23 UTC · model grok-4.3
The pith
RAG pipelines improve accuracy and reduce uncertainty when answering questions from space operations documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
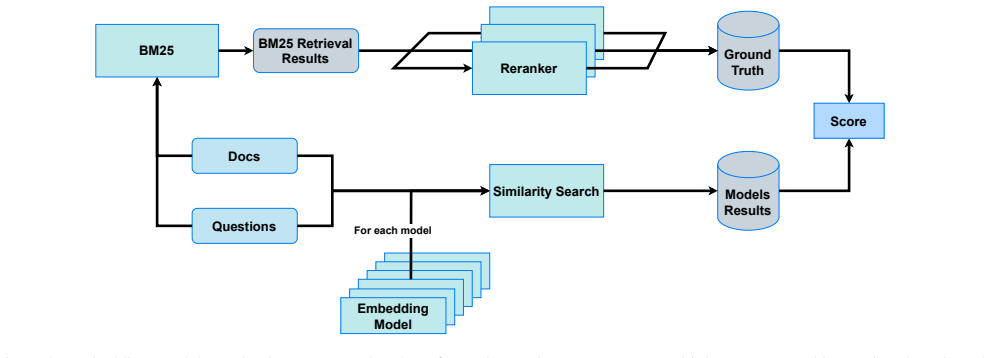
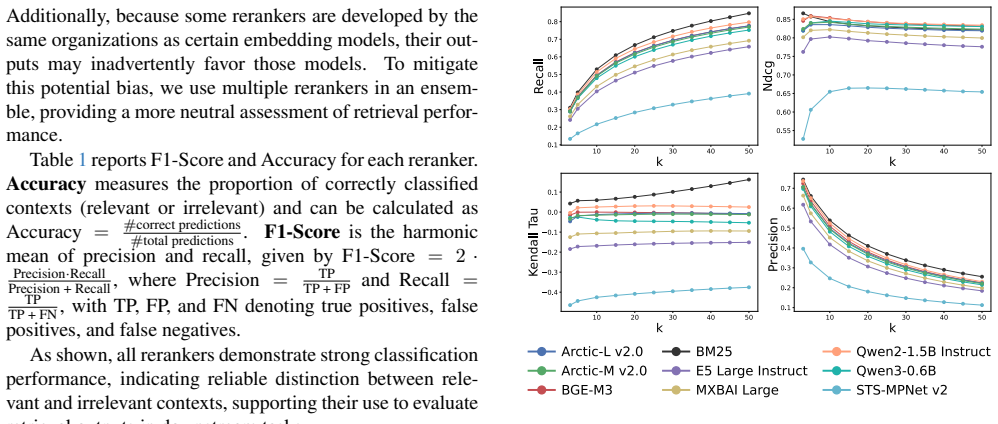
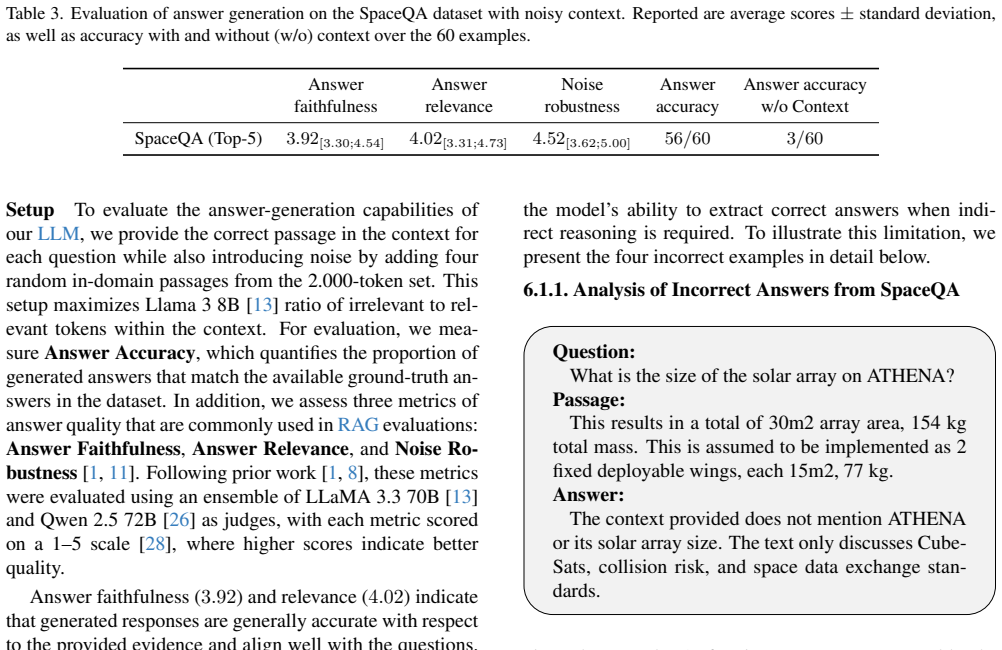
The authors compare various retrieval strategies, embedding models, and LLM answers inside RAG pipelines on domain-specific space operations documents and report that the pipelines enhance information accuracy, relevance, and reliability for extracting actionable knowledge.
What carries the argument
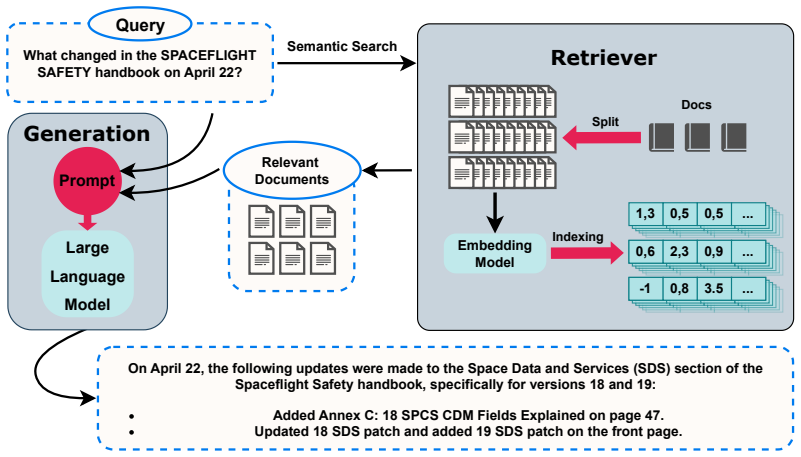
Retrieval-Augmented Generation pipelines that combine information retrieval techniques with Large Language Models to process and synthesize answers from space operations documents.
If this is right
- RAG pipelines can process heterogeneous technical sources more effectively than language models alone.
- Choice of retrieval method and embedding model directly affects answer quality in space document tasks.
- Reduced uncertainty from RAG outputs can support faster and more reliable operational decisions.
- The same pipeline structure scales to other collections of guidelines and scientific literature in the domain.
Where Pith is reading between the lines
- The same evaluation approach could be repeated on document sets from other high-stakes technical fields to test domain transfer.
- Live deployment logs from actual missions would provide a stronger test than offline metrics alone.
- If the gains hold, organizations might shift from manual search to RAG-assisted query interfaces for routine operations.
Load-bearing premise
The chosen space operations documents and accuracy or relevance metrics match what operators actually need for mission decisions.
What would settle it
A side-by-side trial in which space operators complete decision tasks with and without the RAG system and the error rate or time-to-correct-answer differs measurably.
Figures
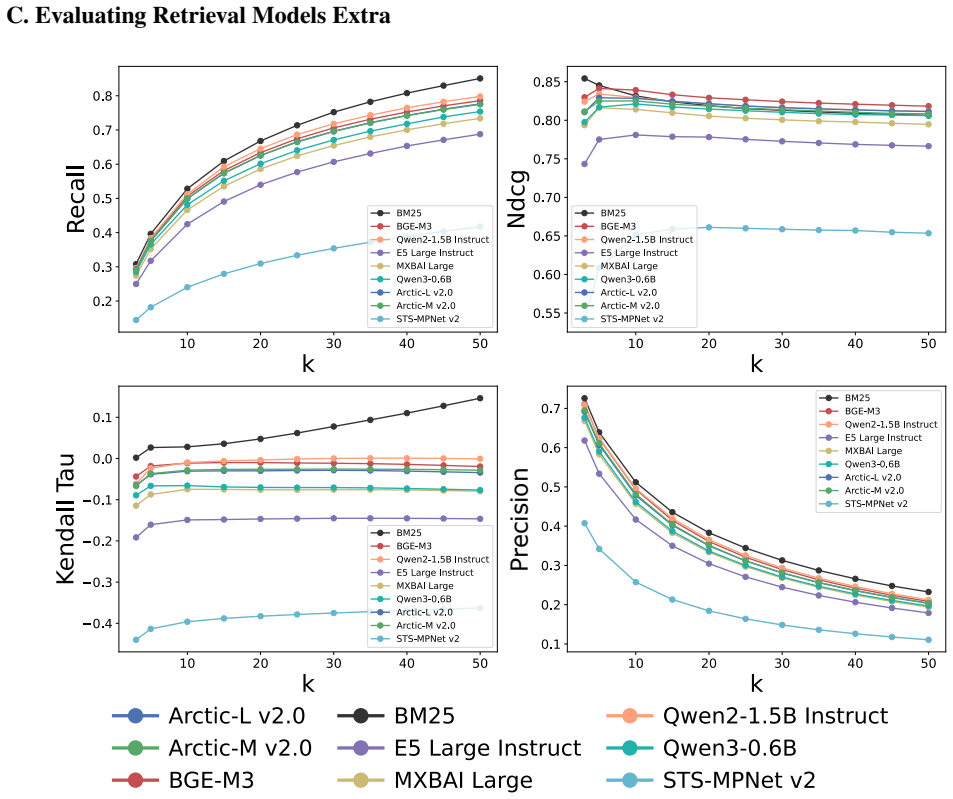




read the original abstract
The rapid expansion of space activities has led to an unprecedented accumulation of technical documentation, operational guidelines, and scientific literature, creating challenges for timely decision-making in space operations. Effective management in space operations requires tools capable of efficiently processing vast and heterogeneous information sources. This paper systematically evaluates the performance of Retrieval Augmented Generation (RAG) pipelines, combining Large Language Models (LLMs) with information retrieval techniques for extracting and synthesizing actionable knowledge from domain-specific documents. We compare various retrieval strategies, embedding models, and LLM answers to assess their impact on information accuracy, relevance, and reliability. Our results demonstrate that RAG pipelines can significantly enhance knowledge access, reduce uncertainty, and support decision-making in complex space operations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to systematically evaluate Retrieval-Augmented Generation (RAG) pipelines combined with Large Language Models (LLMs) for processing technical documentation, operational guidelines, and scientific literature in space operations. It compares retrieval strategies, embedding models, and LLMs on impacts to information accuracy, relevance, and reliability, with the conclusion that RAG pipelines significantly enhance knowledge access, reduce uncertainty, and support decision-making in complex space operations.
Significance. If the claimed empirical results were substantiated with detailed, reproducible experiments on representative space operations documents and metrics validated against operational utility, the work could provide useful evidence on applying RAG in high-stakes technical domains. However, the current manuscript supplies no such evidence.
major comments (2)
- [Abstract] The manuscript provides only the abstract and contains no methods, datasets, document corpus description, retrieval strategies, embedding models, LLMs, quantitative results, tables, figures, error bars, or baseline comparisons. This prevents any verification of the stated improvements in accuracy, relevance, or reliability.
- [Abstract] The central claim that RAG 'supports decision-making in complex space operations' requires that the chosen metrics correlate with reduced uncertainty and better operational decisions. No validation against expert judgment, safety-critical proxies, or time-sensitive operational outcomes is described, leaving the leap from metric scores to decision support unsecured.
minor comments (1)
- [Abstract] The abstract refers to 'various retrieval strategies, embedding models, and LLM answers' without naming any specific instances or configurations tested.
Simulated Author's Rebuttal
We thank the referee for the detailed review. The comments accurately identify that the submitted manuscript consists solely of the abstract and lacks any methods, data, or results sections. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] The manuscript provides only the abstract and contains no methods, datasets, document corpus description, retrieval strategies, embedding models, LLMs, quantitative results, tables, figures, error bars, or baseline comparisons. This prevents any verification of the stated improvements in accuracy, relevance, or reliability.
Authors: This assessment is correct. The manuscript contains only the abstract and provides none of the listed elements. Without those sections, the stated improvements cannot be verified from the document. revision: no
-
Referee: [Abstract] The central claim that RAG 'supports decision-making in complex space operations' requires that the chosen metrics correlate with reduced uncertainty and better operational decisions. No validation against expert judgment, safety-critical proxies, or time-sensitive operational outcomes is described, leaving the leap from metric scores to decision support unsecured.
Authors: We agree that the manuscript contains no description of such validation or correlation with operational outcomes. The abstract states the claim without supporting evidence or discussion of metric validity in a decision-making context. revision: no
Circularity Check
No circularity: empirical evaluation with no derivation chain
full rationale
This is an empirical evaluation paper that compares RAG pipelines, retrieval strategies, embedding models, and LLMs on accuracy/relevance/reliability metrics using space operations documents. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided abstract or described approach. The results are presented as experimental outcomes rather than reductions to inputs by construction, satisfying the criteria for a self-contained empirical study with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lan- guage Modeling and Retrieval-Augmented Generation for Integration in Space Operation Decision Support Tools
Ruben Belo, Claudia Soares, and Marta Guimaraes. Lan- guage Modeling and Retrieval-Augmented Generation for Integration in Space Operation Decision Support Tools . InProceedings of the 76th International Astronautical Congress (IAC 2025), Sydney, Australia, 2025. International Astronautical Federation. IAC Congress Proceedings. 2, 4, 5, 6, 7
2025
-
[2]
SpaceTransformers: Language Modeling for Space Systems .IEEE Access, 9:133111–133122, 2021
Audrey Berquand, Paul Darm, and Annalisa Riccardi. SpaceTransformers: Language Modeling for Space Systems .IEEE Access, 9:133111–133122, 2021. 2
2021
-
[3]
Large language models as autonomous spacecraft operators in kerbal space program .Advances in Space Research, 76(6):3480–3497, 2025
Alejandro Carrasco, Victor Rodriguez-Fernandez, and Richard Linares. Large language models as autonomous spacecraft operators in kerbal space program .Advances in Space Research, 76(6):3480–3497, 2025. 1
2025
-
[4]
M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi- linguality, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation. InAnnual Meeting of the Association for Computational Linguistics, 2024. 4
2024
-
[5]
Co- hen, and Annalisa Riccardi
Paul Darm, Antonio Valerio Miceli Barone, Shay B. Co- hen, and Annalisa Riccardi. DISCOSQA: A knowledge base question answering system for space debris based on pro- gram induction. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track), pages 487–499, Toronto, Canada, 2023. As- sociation for C...
2023
-
[6]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding . InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1, pages 4171–4186, 2019. 2
2019
-
[7]
MMTEB: Massive Multilingual Text Embedding Bench- mark
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, M ´arton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzeminski, Genta Indra Winata, et al. MMTEB: Massive Multilingual Text Embedding Bench- mark . InInternational Conference on Learning Represen- tations. International Conference on Learning Representa- tions, 2025. 5, 11
2025
-
[8]
Ragas: Automated evaluation of retrieval aug- mented generation
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. Ragas: Automated evaluation of retrieval aug- mented generation . InProceedings of the 18th Conference of the European Chapter of the Association for Computa- tional Linguistics: System Demonstrations, pages 150–158,
-
[9]
A bibliometric review of large lan- guage models research from 2017 to 2023 .ACM Trans- actions on Intelligent Systems and Technology, 15(5):1–25,
Lizhou Fan, Lingyao Li, Zihui Ma, Sanggyu Lee, Huizi Yu, and Libby Hemphill. A bibliometric review of large lan- guage models research from 2017 to 2023 .ACM Trans- actions on Intelligent Systems and Technology, 15(5):1–25,
2017
-
[10]
Space-LLaV A: a Vision-Language Model Adapted to Extraterrestrial Applications
Matthew Foutter, Daniele Gammelli, Justin Kruger, Ethan Foss, Praneet Bhoj, Tommaso Guffanti, Simone D’Amico, and Marco Pavone. Space-LLaV A: a Vision-Language Model Adapted to Extraterrestrial Applications . 2024. 2
2024
-
[11]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.ArXiv, abs/2312.10997, 2023. 2, 3, 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Spaceqa: Answering questions about the de- sign of space missions and space craft concepts
Andres Garcia-Silva, Cristian Berrio, Jose Manuel Gomez- Perez, Jose Antonio Mart´ınez-Heras, Alessandro Donati, and Ilaria Roma. Spaceqa: Answering questions about the de- sign of space missions and space craft concepts . InProceed- ings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3306–3311, ...
2022
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Large language models struggle to learn long-tail knowledge
Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wal- lace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. InProceedings of the 40th In- ternational Conference on Machine Learning, pages 15696– 15707, 2023. 2
2023
-
[15]
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R Cole, Kai Hui, Michael Boratko, Rajvi Ka- padia, Wen Ding, et al. Gecko: Versatile text embed- dings distilled from large language models.arXiv preprint arXiv:2403.20327, 2024. 4
-
[16]
Toward Optimal Search and Retrieval for RAG
Alexandria Leto, Cecilia Aguerrebere, Ishwar Bhati, Ted Willke, Mariano Tepper, and Vy Ai V o. Toward Optimal Search and Retrieval for RAG . InSecond NeurIPS Work- shop on Attributing Model Behavior at Scale, 2025. 3
2025
-
[17]
Quantum Physics Intelligent Question Answering (Q&A) System Based on Retrieval-Augmented Generation .Concurrency and Computation: Practice and Experience, 38, 2025
Wenchen Li, Su Lu, Hongqi Zhu, Peijun Wu, and Wuhe Zou. Quantum Physics Intelligent Question Answering (Q&A) System Based on Retrieval-Augmented Generation .Concurrency and Computation: Practice and Experience, 38, 2025. 2
2025
-
[18]
Developing AI Agents for Satellite Operations .The Journal of Space Operations & Communicator, 21:9,
Zhenping Li. Developing AI Agents for Satellite Operations .The Journal of Space Operations & Communicator, 21:9,
-
[19]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
The widespread adoption of large language model-assisted writing across society.Pat- terns, 6, 2025
Weixin Liang, Yaohui Zhang, Mihai Codreanu, Jiayu Wang, Hancheng Cao, and James Zou. The widespread adoption of large language model-assisted writing across society.Pat- terns, 6, 2025. 2
2025
-
[21]
LLM based expert AI agent for mission operation management .Informatyka, Automatyka, Pomiary w Gospodarce i Ochronie ´Srodowiska, 15:88–94, 2025
Sobhana M., Syama Gudipati, and Satwik Panda. LLM based expert AI agent for mission operation management .Informatyka, Automatyka, Pomiary w Gospodarce i Ochronie ´Srodowiska, 15:88–94, 2025. 1, 2
2025
-
[22]
AI for Space Traffic Management .Journal of Space Safety En- gineering, 10(4):495–504, 2023
Chiara Manfletti, Marta Guimar ˜aes, and Claudia Soares. AI for Space Traffic Management .Journal of Space Safety En- gineering, 10(4):495–504, 2023. 1, 2
2023
-
[23]
The Probabilistic Relevance Framework: BM25 and Beyond .Foundations and Trends in Information Retrieval, 3:333–389, 2009
Stephen Robertson and Hugo Zaragoza. The Probabilistic Relevance Framework: BM25 and Beyond .Foundations and Trends in Information Retrieval, 3:333–389, 2009. 2, 5
2009
-
[24]
ARES: An Automated Evaluation Frame- work for Retrieval-Augmented Generation Systems
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. ARES: An Automated Evaluation Frame- work for Retrieval-Augmented Generation Systems . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 338–354, 2024. 4
2024
-
[25]
Evaluating Large Language Models for Space Operations
Clemens Schefels, Carsten Hartmann, Leonard Schlag, and Kathrin Helmsauer. Evaluating Large Language Models for Space Operations . 2024. 1, 2
2024
-
[26]
Qwen2.5: A party of foundation models, 2024
Qwen Team. Qwen2.5: A party of foundation models, 2024. 7
2024
-
[27]
Ashok Urlana, Charaka Vinayak Kumar, Ajeet Kumar Singh, Bala Mallikarjunarao Garlapati, Srinivasa Rao Chalamala, and Rahul Mishra. LLMs with Industrial Lens: Deci- phering the Challenges and Prospects - A Survey.ArXiv, abs/2402.14558, 2024. 2
-
[28]
Honglei Zhuang, Zhen Qin, Kai Hui, Junru Wu, Le Yan, Xuanhui Wang, and Michael Bendersky. Beyond Yes and No: Improving Zero-Shot Pointwise LLM Rankers via Scor- ing Fine-Grained Relevance Labels . InProceedings of the 2024 Conference of the North American Chapter of the As- sociation for Computational Linguistics (NAACL), 2024. 6, 7 A. Rerank Evaluation e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.