Iterative Causal Discovery: Per-Edge Impossibility Certificates, Tier-Aware Oracle Queries, and the 1+K Lower Bound
Pith reviewed 2026-06-29 15:56 UTC · model grok-4.3
The pith
Causal discovery recovers any DAG with at most 1 plus the number of non-leaf vertices expert queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
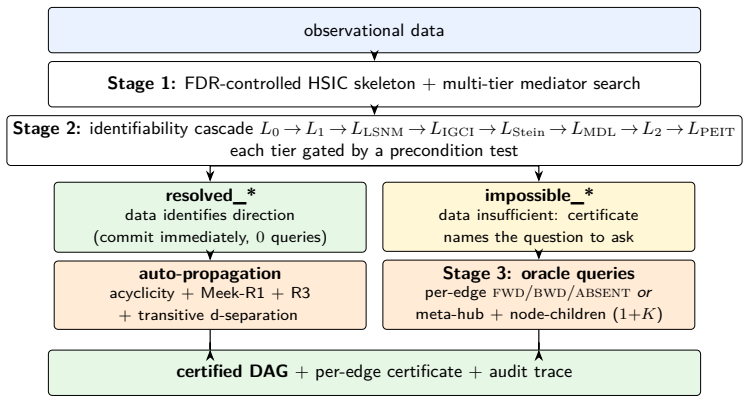
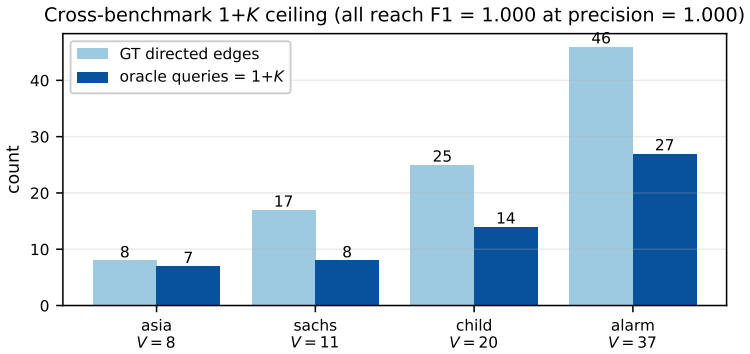
Observational data under Markov and faithfulness conditions identifies only a Markov equivalence class, leaving some edge directions undetermined by the joint distribution. The protocol records per edge whether its orientation follows from one of the five identifiability tiers or requires external resolution. The meta-hub and node-children oracle primitives jointly establish that 1+K interactions recover the full DAG for any graph with K non-leaf vertices, and this count is achieved exactly on the listed benchmarks when every query returns the needed information without error.
What carries the argument
Per-edge impossibility certificates (RESOLVED and IMPOSSIBLE codes) together with the meta-hub query and node-children query primitives.
If this is right
- Any DAG is recoverable with at most 1+K oracle interactions.
- The bound is attained exactly on the asia, sachs, child, and alarm benchmarks under ideal oracle responses.
- The five gated tiers abstain on edges whose preconditions fail, preventing incorrect commitments.
- Certificates distinguish directions fixed by data from those assigned by untested assumptions.
- The protocol works on continuous data and attaches a discrete question to each unresolved edge.
Where Pith is reading between the lines
- The per-edge certificates could be attached to outputs of existing causal discovery algorithms to flag which edges still need external validation.
- The 1+K bound suggests a minimal expert budget that scales with graph structure rather than total edges.
- Testing the same protocol on graphs with known ground truth but different sparsity patterns would show whether the bound remains tight.
- Integration with active learning loops could prioritize which IMPOSSIBLE certificates to submit first.
Load-bearing premise
Every oracle query returns exactly the information needed to resolve the impossibility certificate without error or additional cost.
What would settle it
A concrete DAG on which recovering the complete orientation requires strictly more than 1+K ideal responses to the meta-hub and node-children queries.
Figures

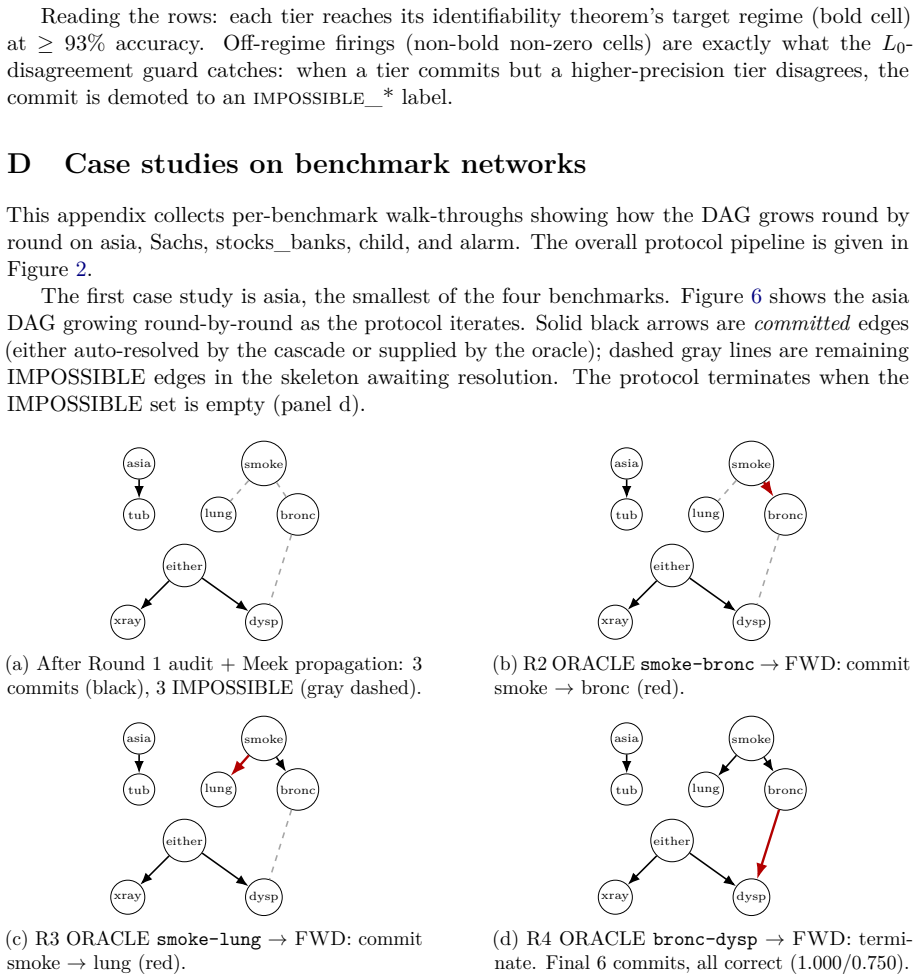
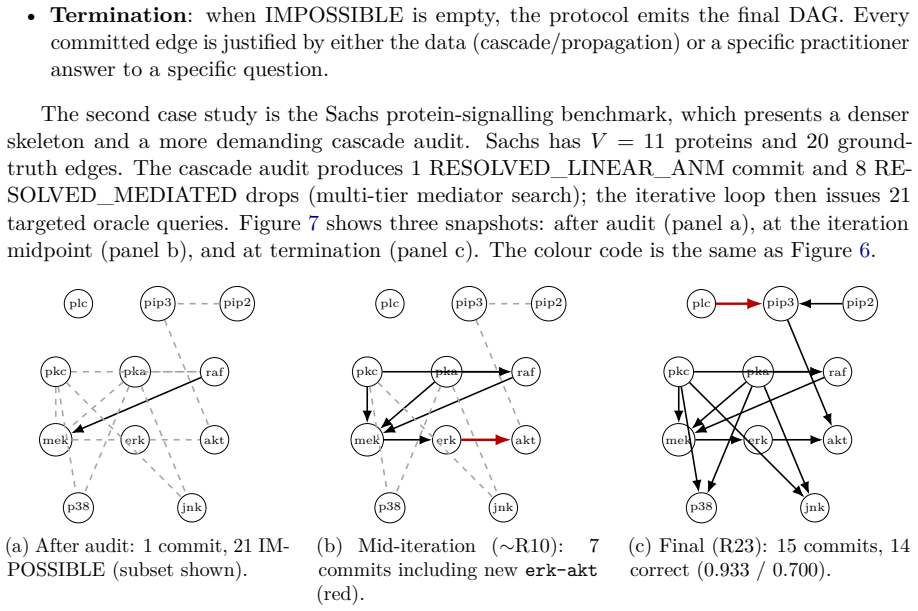
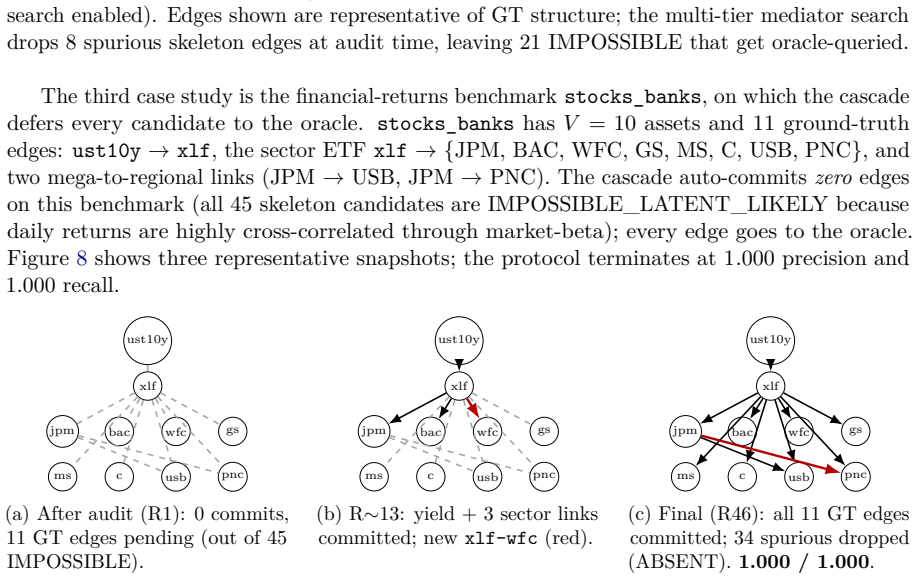
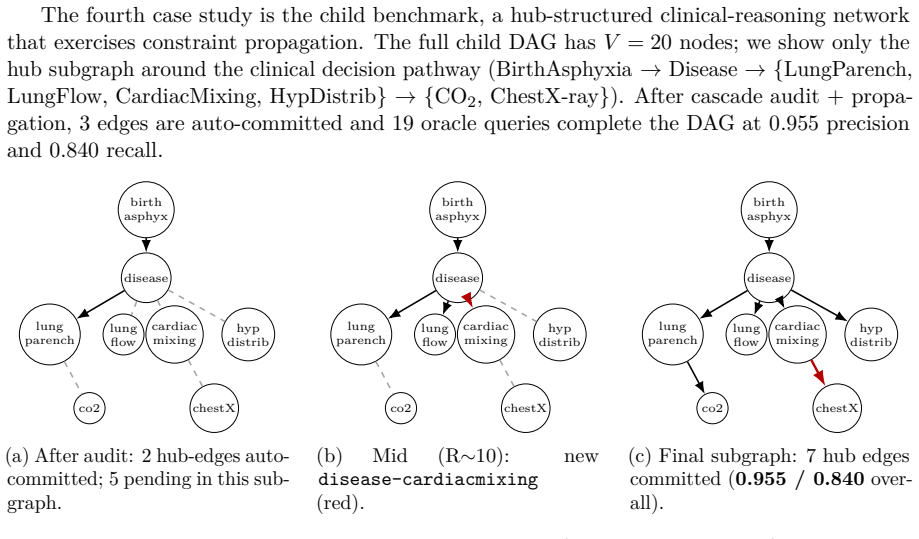

read the original abstract
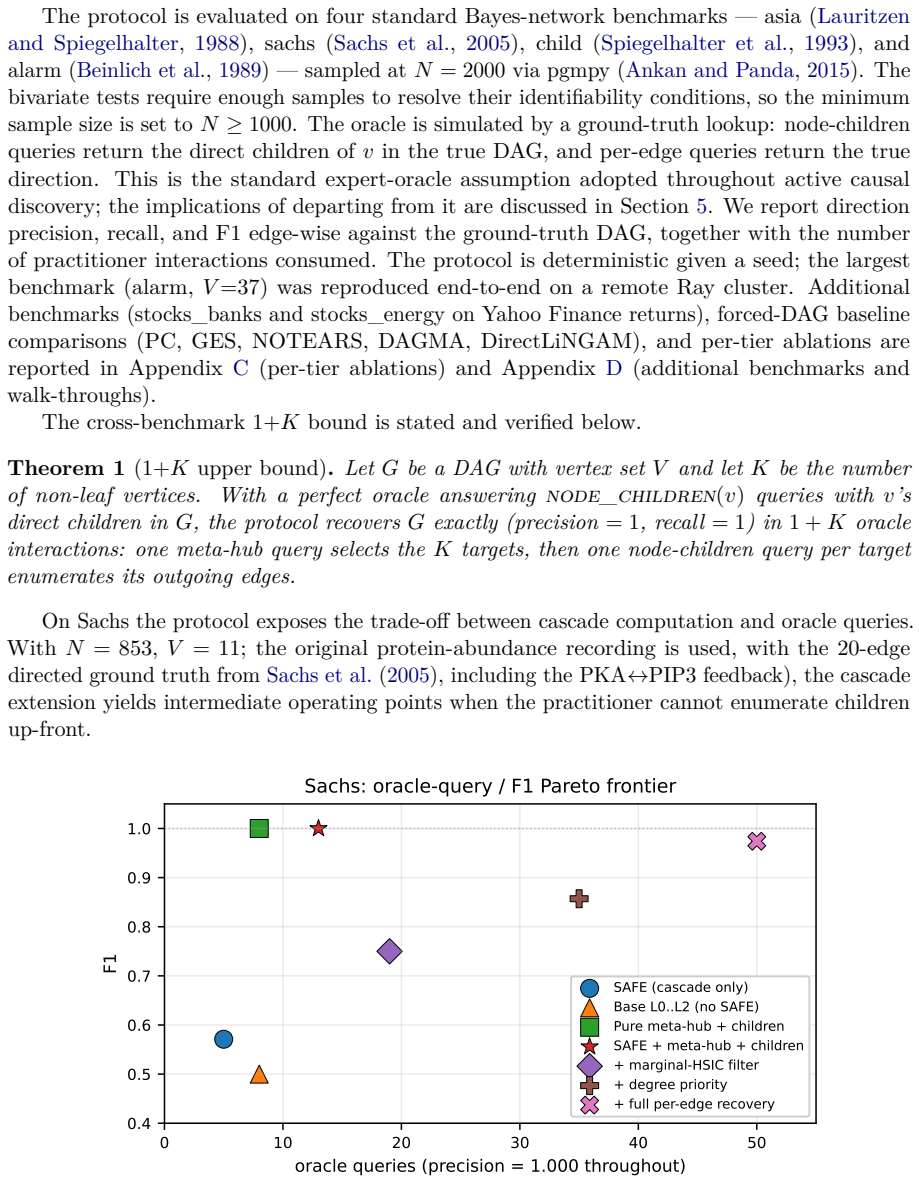
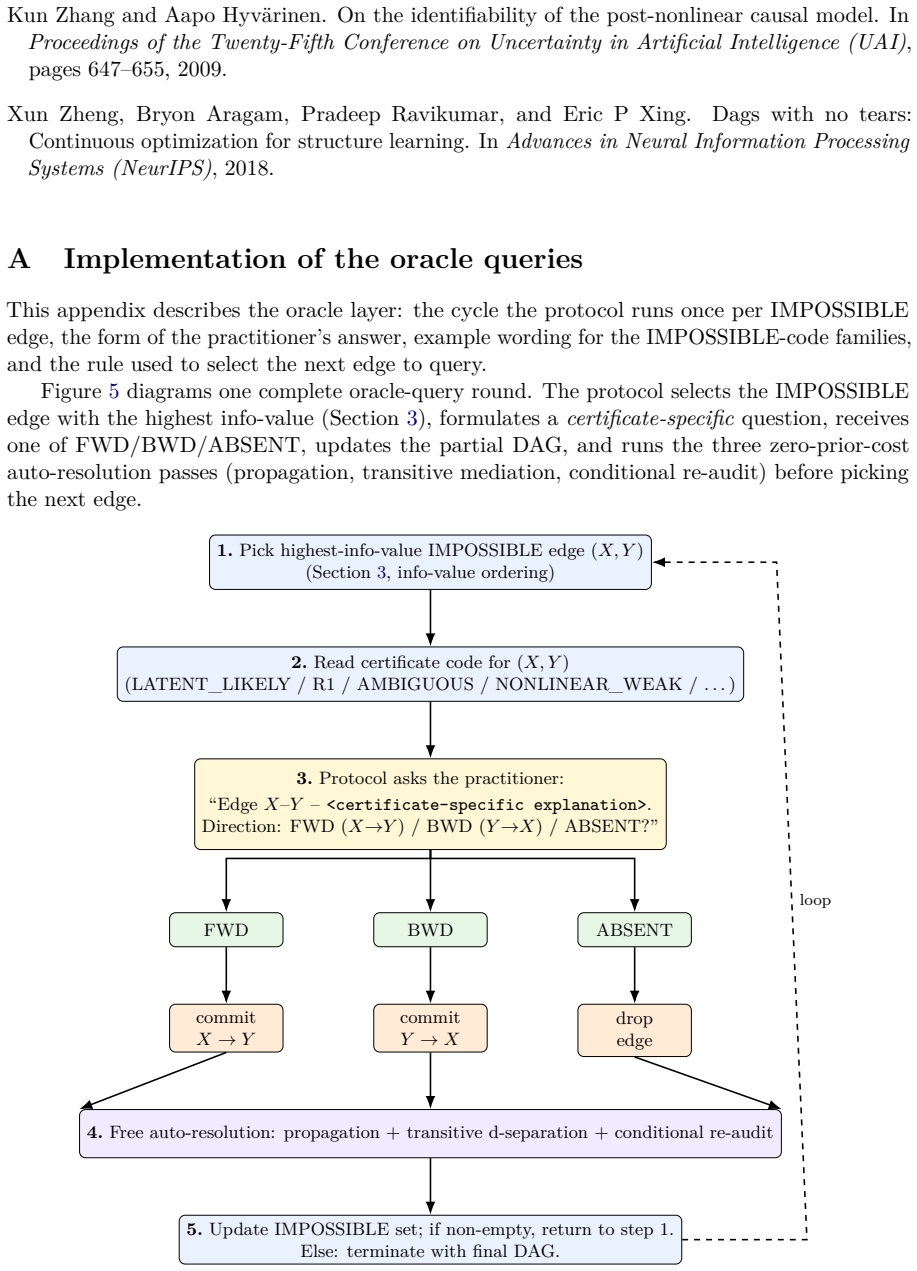
Causal-discovery algorithms return a directed graph, yet provide no principled means of distinguishing edge directions identified by the data from those assigned without an identifying assumption. Under the standard Markov and faithfulness conditions, the observational distribution identifies only a Markov equivalence class; orientations within that class are not determined by the joint distribution and cannot be recovered from additional samples alone, but require either a functional restriction or an intervention. We introduce a protocol for observational causal discovery on continuous data that attaches to each candidate edge a discrete impossibility certificate: a RESOLVED code records the identifiability theorem under which the direction was committed, while an IMPOSSIBLE code records the failure mode together with the specific question a domain expert must answer to resolve it. The bivariate cascade is extended with five gated identifiability tiers LSNM, IGCI, Stein, MDL, and PEIT that abstain when their precondition test rejects. Two oracle primitives, the meta-hub query and the node-children query, jointly establish an upper bound of $1+K$ expert interactions sufficient to recover any DAG, where $K$ denotes the number of non-leaf vertices. Under an ideal-oracle assumption, the bound is met exactly on the asia, sachs, child, and alarm benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce per-edge impossibility certificates (RESOLVED and IMPOSSIBLE) for causal discovery using five gated tiers (LSNM, IGCI, Stein, MDL, PEIT) that abstain when preconditions fail. It proposes two oracle primitives (meta-hub query and node-children query) that establish an upper bound of 1+K expert interactions to recover any DAG (K = number of non-leaf vertices), with the bound achieved on asia, sachs, child, and alarm benchmarks under an ideal oracle.
Significance. Should the mapping between IMPOSSIBLE certificates and the query primitives be verified and the bound proven, this would represent a meaningful contribution to interactive causal discovery by providing a principled, low-query protocol for resolving identifiability issues on continuous data. The certificate approach adds transparency to edge orientations.
major comments (1)
- [Abstract] Abstract: the central claim that the meta-hub and node-children queries jointly establish the 1+K upper bound requires an explicit mapping or proof that every IMPOSSIBLE certificate from the five gated tiers is resolvable by exactly one invocation of one primitive without residual ambiguity; no such derivation or coverage argument is supplied.
minor comments (1)
- [Title] Title: refers to a '$1+K$ Lower Bound' while the abstract describes an upper bound of 1+K expert interactions; the terminology should be reconciled for consistency.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for recognizing the potential contribution of the certificate-based protocol to interactive causal discovery. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the meta-hub and node-children queries jointly establish the 1+K upper bound requires an explicit mapping or proof that every IMPOSSIBLE certificate from the five gated tiers is resolvable by exactly one invocation of one primitive without residual ambiguity; no such derivation or coverage argument is supplied.
Authors: We agree that an explicit mapping and coverage argument would make the central claim more transparent. In the revised manuscript we will insert a new subsection immediately after the definitions of the two oracle primitives. This subsection will contain (i) a complete enumeration of every IMPOSSIBLE code that can be emitted by the LSNM, IGCI, Stein, MDL and PEIT tiers, (ii) a table mapping each code to the single primitive (meta-hub or node-children) that resolves it, and (iii) a short proof that the chosen primitive eliminates the recorded failure mode without residual ambiguity. The argument relies only on the definitions already present in Sections 3 and 4 and does not require additional assumptions. revision: yes
Circularity Check
No significant circularity in the 1+K bound derivation
full rationale
The paper presents the 1+K upper bound as following directly from the two defined oracle primitives (meta-hub query and node-children query) under the ideal-oracle assumption, with the bound verified exactly on the listed benchmarks. No equations, fitted parameters, or self-citations are shown that would reduce the bound to a definition or input by construction. The derivation chain is self-contained against the stated primitives and external benchmarks, with no load-bearing reductions of the enumerated kinds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard Markov and faithfulness conditions
invented entities (2)
-
RESOLVED and IMPOSSIBLE per-edge certificates
no independent evidence
-
meta-hub query and node-children query
no independent evidence
Reference graph
Works this paper leans on
-
[1]
pgmpy: Probabilistic graphical models using python
Ankur Ankan and Abinash Panda. pgmpy: Probabilistic graphical models using python. In Proceedings of the 14th Python in Science Conference (SciPy), pages 6--11, 2015. doi:10.25080/Majora-7b98e3ed-001
-
[2]
Variational causal networks: Approximate B ayesian inference over causal structures
Yashas Annadani, Jonas Rothfuss, Alexandre Lacoste, Nino Scherrer, Anirudh Goyal, Yoshua Bengio, and Stefan Bauer. Variational causal networks: Approximate B ayesian inference over causal structures. arXiv preprint arXiv:2106.07635, 2021
-
[3]
The ALARM monitoring system: A case study with two probabilistic inference techniques for belief networks
Ingo A Beinlich, H Jaap Suermondt, R Martin Chavez, and Gregory F Cooper. The ALARM monitoring system: A case study with two probabilistic inference techniques for belief networks. Proceedings of the Second European Conference on Artificial Intelligence in Medicine, pages 247--256, 1989. Origin of the ``alarm'' Bayesian-network benchmark
1989
-
[4]
Dagma: Learning dags via m-matrices and a log-determinant acyclicity characterization
Kevin Bello, Bryon Aragam, and Pradeep Ravikumar. Dagma: Learning dags via m-matrices and a log-determinant acyclicity characterization. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[5]
Controlling the false discovery rate: a practical and powerful approach to multiple testing
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B (Methodological), 57 0 (1): 0 289--300, 1995
1995
-
[6]
Optimal structure identification with greedy search
David Maxwell Chickering. Optimal structure identification with greedy search. Journal of Machine Learning Research, 3: 0 507--554, 2002
2002
-
[7]
Learning high-dimensional directed acyclic graphs with latent and selection variables
Diego Colombo, Marloes H Maathuis, Markus Kalisch, and Thomas S Richardson. Learning high-dimensional directed acyclic graphs with latent and selection variables. The Annals of Statistics, 40 0 (1): 0 294--321, 2012
2012
-
[8]
BCD nets: Scalable variational approaches for B ayesian causal discovery
Chris Cundy, Aditya Grover, and Stefano Ermon. BCD nets: Scalable variational approaches for B ayesian causal discovery. In Advances in Neural Information Processing Systems 34 (NeurIPS), 2021
2021
-
[9]
Frederick Eberhardt, Clark Glymour, and Richard Scheines. On the number of experiments sufficient and in the worst case necessary to identify all causal relations among N variables. arXiv preprint arXiv:1207.1389, 2005
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[10]
Review of causal discovery methods based on graphical models
Clark Glymour, Kun Zhang, and Peter Spirtes. Review of causal discovery methods based on graphical models. Frontiers in Genetics, 10: 0 524, 2019. doi:10.3389/fgene.2019.00524
-
[11]
A kernel statistical test of independence
Arthur Gretton, Kenji Fukumizu, Choon Hui Teo, Le Song, Bernhard Sch \"o lkopf, and Alex Smola. A kernel statistical test of independence. In Advances in Neural Information Processing Systems (NeurIPS), 2007
2007
-
[12]
Two optimal strategies for active learning of causal models from interventional data
Alain Hauser and Peter B \"u hlmann. Two optimal strategies for active learning of causal models from interventional data. International Journal of Approximate Reasoning, 55 0 (4): 0 926--939, 2014. doi:10.1016/j.ijar.2013.11.007
-
[13]
Active learning of causal networks with intervention experiments and optimal designs
Yang-Bo He and Zhi Geng. Active learning of causal networks with intervention experiments and optimal designs. Journal of Machine Learning Research, 9: 0 2523--2547, 2008
2008
-
[14]
David Heckerman, Dan Geiger, and David M. Chickering. Learning B ayesian networks: The combination of knowledge and statistical data. Machine Learning, 20 0 (3): 0 197--243, 1995. doi:10.1023/A:1022623210503
-
[15]
Nonlinear causal discovery with additive noise models
Patrik O Hoyer, Dominik Janzing, Joris M Mooij, Jonas Peters, and Bernhard Sch \"o lkopf. Nonlinear causal discovery with additive noise models. In Advances in Neural Information Processing Systems (NeurIPS), 2008
2008
-
[16]
Pairwise likelihood ratios for estimation of non- G aussian structural equation models
Aapo Hyv \"a rinen and Stephen M Smith. Pairwise likelihood ratios for estimation of non- G aussian structural equation models. Journal of Machine Learning Research, 14: 0 111--152, 2013
2013
-
[17]
o lkopf, Peter B \
Alexander Immer, Christoph Schultheiss, Julia E. Vogt, Bernhard Sch \"o lkopf, Peter B \"u hlmann, and Alexander Marx. On the identifiability and estimation of causal location-scale noise models. In Proceedings of the 40th International Conference on Machine Learning (ICML), volume 202 of PMLR, pages 14316--14332, 2023
2023
-
[18]
Causal inference using the algorithmic markov condition
Dominik Janzing and Bernhard Sch \"o lkopf. Causal inference using the algorithmic markov condition. IEEE Transactions on Information Theory, 56 0 (10): 0 5168--5194, 2010. doi:10.1109/TIT.2010.2060095. Information-theoretic / MDL-style basis for compression-based causal direction
-
[19]
Information-geometric approach to inferring causal directions
Dominik Janzing, Joris Mooij, Kun Zhang, Jan Lemeire, Jakob Zscheischler, Povilas Daniu s is, Bastian Steudel, and Bernhard Sch \"o lkopf. Information-geometric approach to inferring causal directions. Artificial Intelligence, 182--183: 0 1--31, 2012
2012
-
[20]
Tearing apart NOTEARS : Controlling the graph prediction via variance manipulation
Marcus Kaiser and Maksym Sipos. Tearing apart NOTEARS : Controlling the graph prediction via variance manipulation. arXiv preprint arXiv:2206.07195, 2022
-
[21]
Estimating high-dimensional directed acyclic graphs with the pc-algorithm
Markus Kalisch and Peter B \"u hlmann. Estimating high-dimensional directed acyclic graphs with the pc-algorithm. Journal of Machine Learning Research, 8: 0 613--636, 2007
2007
-
[22]
Local computations with probabilities on graphical structures and their application to expert systems
Steffen L Lauritzen and David J Spiegelhalter. Local computations with probabilities on graphical structures and their application to expert systems. Journal of the Royal Statistical Society: Series B (Methodological), 50 0 (2): 0 157--194, 1988. Origin of the ``asia'' Bayesian-network benchmark
1988
-
[23]
DiBS : Differentiable B ayesian structure learning
Lars Lorch, Jonas Rothfuss, Bernhard Sch \"o lkopf, and Andreas Krause. DiBS : Differentiable B ayesian structure learning. In Advances in Neural Information Processing Systems 34 (NeurIPS), 2021
2021
-
[24]
Amortized inference for causal structure learning
Lars Lorch, Scott Sussex, Jonas Rothfuss, Andreas Krause, and Bernhard Sch \"o lkopf. Amortized inference for causal structure learning. In Advances in Neural Information Processing Systems 35 (NeurIPS), 2022
2022
-
[25]
Mooij, Jonas Peters, Dominik Janzing, Jakob Zscheischler, and Bernhard Sch \"o lkopf
Joris M. Mooij, Jonas Peters, Dominik Janzing, Jakob Zscheischler, and Bernhard Sch \"o lkopf. Distinguishing cause from effect using observational data: methods and benchmarks. Journal of Machine Learning Research, 17 0 (32): 0 1--102, 2016
2016
-
[26]
Causality: Models, Reasoning, and Inference
Judea Pearl. Causality: Models, Reasoning, and Inference. Cambridge University Press, 2nd edition, 2009
2009
-
[27]
Elements of Causal Inference: Foundations and Learning Algorithms
Jonas Peters, Dominik Janzing, and Bernhard Sch \"o lkopf. Elements of Causal Inference: Foundations and Learning Algorithms. Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, 2017
2017
-
[28]
Beware of the simulated dag! causal discovery benchmarks may be easy to game
Alexander Reisach, Christof Seiler, and Sebastian Weichwald. Beware of the simulated dag! causal discovery benchmarks may be easy to game. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[29]
a us Kleindessner, Chris Russell, Dominik Janzing, Bernhard Sch \
Paul Rolland, Volkan Cevher, Matth \"a us Kleindessner, Chris Russell, Dominik Janzing, Bernhard Sch \"o lkopf, and Francesco Locatello. Score matching enables causal discovery of nonlinear additive noise models. In Proceedings of the 39th International Conference on Machine Learning (ICML), volume 162 of PMLR, pages 18741--18753, 2022. Leaf-node identifi...
2022
-
[30]
Argumentation for interactive causal discovery
Fabrizio Russo and Francesca Toni. Argumentation for interactive causal discovery. In Proceedings of the 32nd International Joint Conference on Artificial Intelligence (IJCAI), pages 7374--7382, 2023. doi:10.24963/ijcai.2023/820
-
[31]
Causal protein-signaling networks derived from multiparameter single-cell data
Karen Sachs, Omar Perez, Dana Pe'er, Douglas A Lauffenburger, and Garry P Nolan. Causal protein-signaling networks derived from multiparameter single-cell data. Science, 308 0 (5721): 0 523--529, 2005
2005
-
[32]
Bernhard Sch \"o lkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning. Proceedings of the IEEE, 109 0 (5): 0 612--634, 2021. doi:10.1109/JPROC.2021.3058954
-
[33]
Dimakis, and Sriram Vishwanath
Karthikeyan Shanmugam, Murat Kocaoglu, Alexandros G. Dimakis, and Sriram Vishwanath. Learning causal graphs with small interventions. In Advances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[34]
A linear non-gaussian acyclic model for causal discovery
Shohei Shimizu, Patrik O Hoyer, Aapo Hyv \"a rinen, and Antti Kerminen. A linear non-gaussian acyclic model for causal discovery. Journal of Machine Learning Research, 7: 0 2003--2030, 2006
2003
-
[35]
Directlingam: a direct method for learning a linear non- G aussian structural equation model
Shohei Shimizu, Takanori Inazumi, Yasuhiro Sogawa, Aapo Hyv \"a rinen, Yoshinobu Kawahara, Takashi Washio, Patrik O Hoyer, and Kenneth Bollen. Directlingam: a direct method for learning a linear non- G aussian structural equation model. Journal of Machine Learning Research, 12: 0 1225--1248, 2011
2011
-
[36]
B ayesian analysis in expert systems
David J Spiegelhalter, A Philip Dawid, Steffen L Lauritzen, and Robert G Cowell. B ayesian analysis in expert systems. Statistical Science, 8 0 (3): 0 219--247, 1993. Origin of the ``child'' Bayesian-network benchmark
1993
-
[37]
Causation, Prediction, and Search
Peter Spirtes, Clark Glymour, and Richard Scheines. Causation, Prediction, and Search. MIT Press, 2nd edition, 2000
2000
-
[38]
Eric V. Strobl and Thomas A. Lasko. Identifying patient-specific root causes with the heteroscedastic noise model. Journal of Computational Science, 72: 0 102099, 2023. doi:10.1016/j.jocs.2023.102099. Establishes bivariate identifiability of the location-scale noise model; preprint arXiv:2205.13085 (2022)
-
[39]
Interventions, where and how? E xperimental design for causal models at scale
Panagiotis Tigas, Yashas Annadani, Andrew Jesson, Bernhard Sch \"o lkopf, Yarin Gal, and Stefan Bauer. Interventions, where and how? E xperimental design for causal models at scale. In Advances in Neural Information Processing Systems 35 (NeurIPS), 2022
2022
-
[40]
On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias
Jiji Zhang. On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias. Artificial Intelligence, 172 0 (16-17): 0 1873--1896, 2008
2008
-
[41]
On the identifiability of the post-nonlinear causal model
Kun Zhang and Aapo Hyv \"a rinen. On the identifiability of the post-nonlinear causal model. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI), pages 647--655, 2009
2009
-
[42]
Dags with no tears: Continuous optimization for structure learning
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P Xing. Dags with no tears: Continuous optimization for structure learning. In Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.