Cross-Entropy Games and Frost Training
Pith reviewed 2026-06-29 17:08 UTC · model grok-4.3
The pith
Frost Training adds the embedding gradient of the reward to GRPO updates to raise maximum scores and speed convergence in Cross-Entropy Games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frost Training improves the model's ability to generate high-scoring outputs, reaching higher maximum scores in a best-of-k setting, and does so at an increased speed by exploiting the gradient of the reward function in embedding space inside Monte Carlo-based policy optimization for Cross-Entropy Games.
What carries the argument
The gradient of the reward function in embedding space, added as an extra training signal to GRPO.
Load-bearing premise
The embedding-space gradient of the reward supplies a stable, useful training signal that can be added to GRPO without destabilizing optimization.
What would settle it
Train two identical GRPO runs on the same infilling task, one with and one without the embedding gradient term, then measure whether the version with the term produces strictly higher best-of-k maximum scores and reaches its peak in fewer steps.
Figures
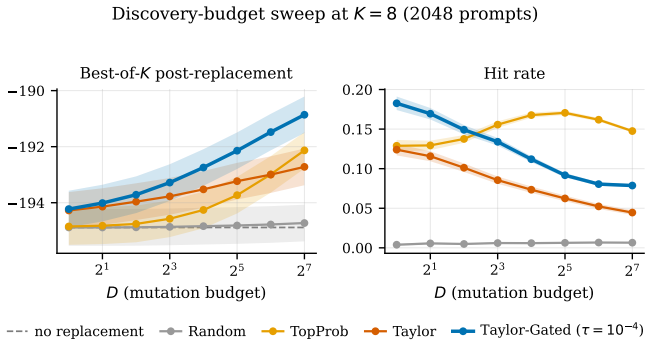
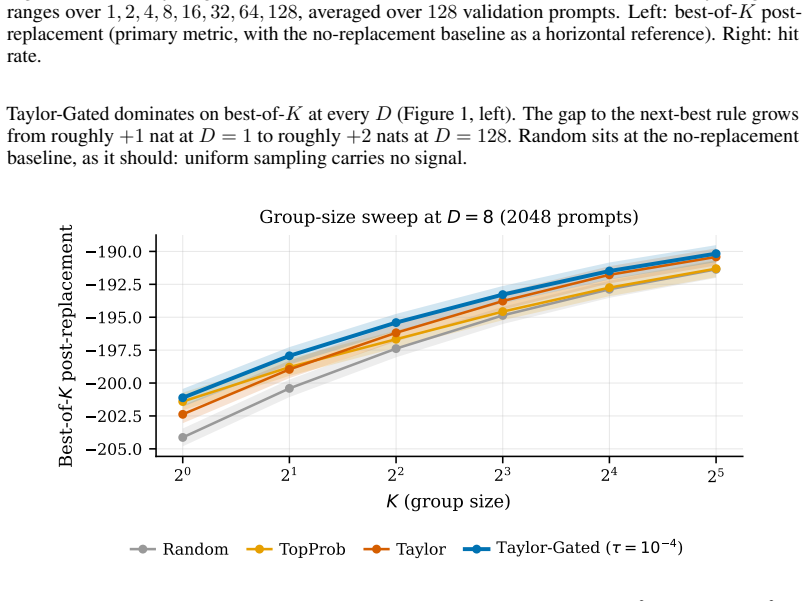
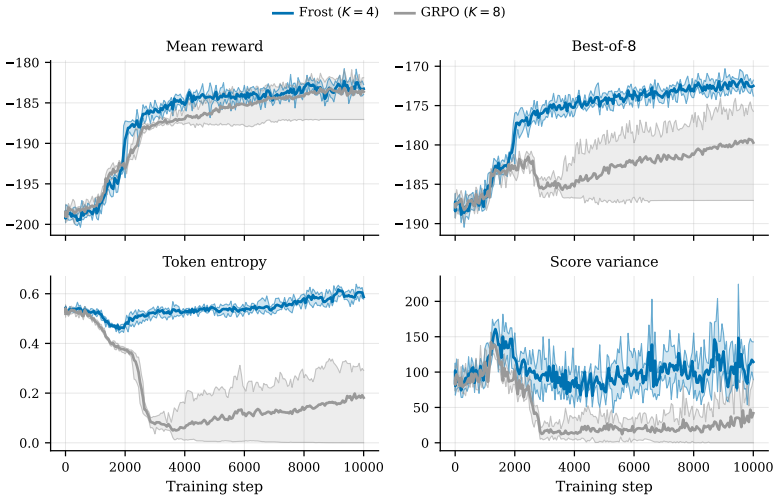
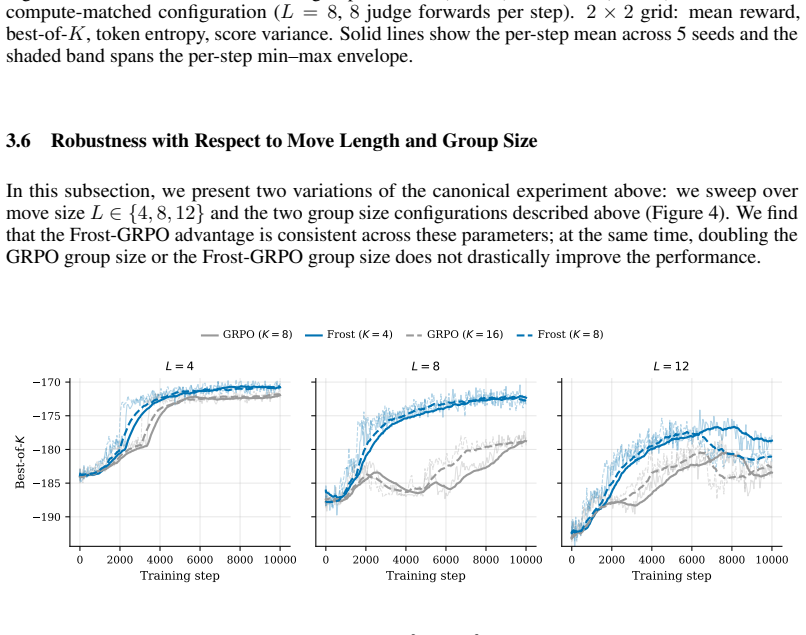
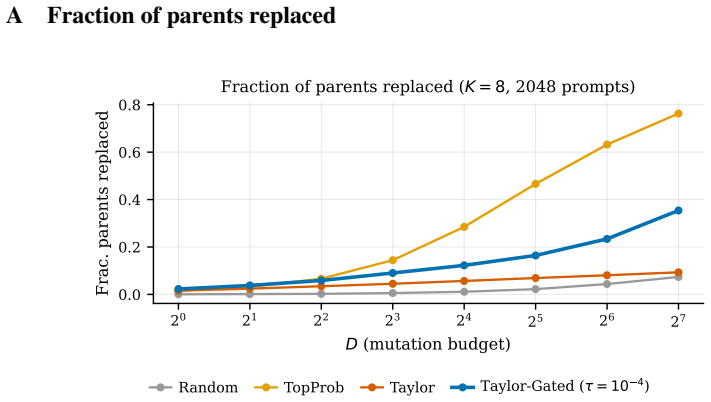
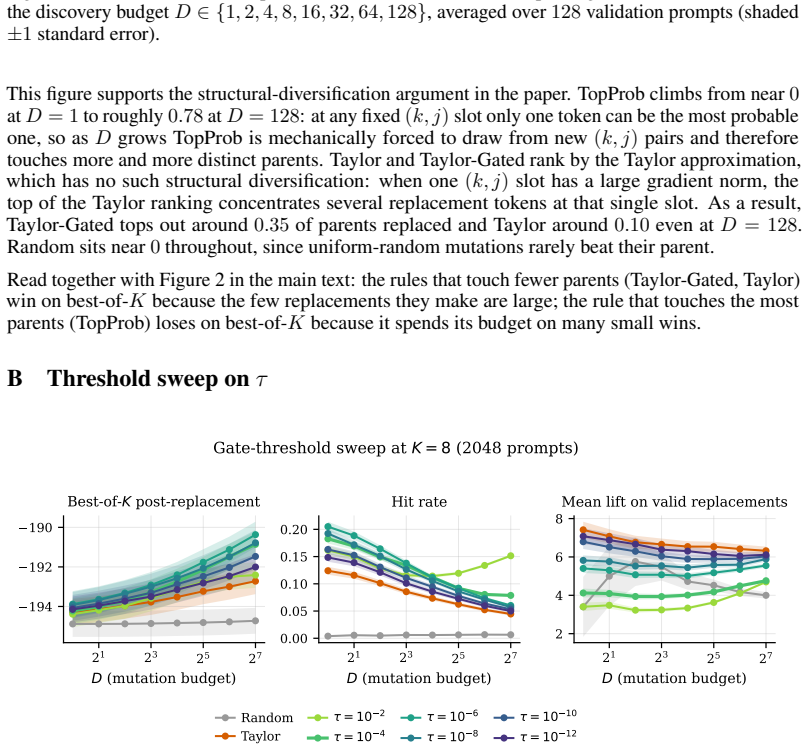
read the original abstract
We present Frost Training, a method for improving Monte Carlo-based policy optimization for a large family of LLM-as-a-judge tasks called Cross-Entropy Games. The key idea is to exploit the gradient of the reward function in embedding space. This signal is used in the Greedy Coordinate Gradient (GCG) jailbreaking technique; we demonstrate for the first time that it can also be used to boost model training. We validate our method using GRPO training for maximum-likelihood infilling. Frost Training improves the model's ability to generate high-scoring outputs, reaching higher maximum scores in a best-of-k setting, and does so at an increased speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Frost Training, a method that applies the gradient of the reward function in embedding space (inspired by GCG jailbreaking) as an additive signal to GRPO for Monte Carlo policy optimization in Cross-Entropy Games. The central claim is that this yields higher maximum scores in best-of-k sampling and faster convergence for maximum-likelihood infilling tasks with LLM-as-a-judge rewards.
Significance. If the embedding-space gradient supplies a stable, non-destructive training signal, the approach could extend existing policy-gradient methods with a new, potentially low-cost auxiliary objective. The absence of any reported numbers, ablations, or protocol details, however, prevents assessment of whether the claimed gains are real or reproducible.
major comments (2)
- [Abstract] Abstract: the performance claims (higher best-of-k scores and increased speed) are stated without any quantitative results, baselines, statistical tests, or experimental protocol, rendering it impossible to evaluate whether the data support the central claim.
- [Method] Method (Frost Training description): no information is given on the relative magnitude of the embedding-space reward gradient versus the GRPO policy gradient, its batch-wise variance, or any ablation isolating its contribution from hyperparameter changes; this directly bears on the stability assumption required for the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the current draft lacks sufficient quantitative support and methodological specifics to allow proper evaluation of the claims, and we will revise the manuscript accordingly to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (higher best-of-k scores and increased speed) are stated without any quantitative results, baselines, statistical tests, or experimental protocol, rendering it impossible to evaluate whether the data support the central claim.
Authors: We agree that the abstract does not currently include quantitative results or protocol details. In the revised version we will add specific metrics (e.g., best-of-k score deltas and wall-clock improvements versus GRPO baselines), reference the experimental protocol, and note any statistical tests performed. revision: yes
-
Referee: [Method] Method (Frost Training description): no information is given on the relative magnitude of the embedding-space reward gradient versus the GRPO policy gradient, its batch-wise variance, or any ablation isolating its contribution from hyperparameter changes; this directly bears on the stability assumption required for the reported improvements.
Authors: We acknowledge the absence of these details. The revision will include explicit comparisons of gradient magnitudes, batch-wise variance statistics, and ablation experiments that isolate the embedding-space term from hyperparameter effects, thereby clarifying the stability of the combined signal. revision: yes
Circularity Check
No equations or fitted quantities described; no circularity detectable from available text
full rationale
The abstract and provided context introduce Frost Training as an empirical method that adds an embedding-space reward gradient to GRPO for Cross-Entropy Games, with claims of improved best-of-k scores and speed. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations are present. The reader's assessment of score 2.0 is consistent: the central claim is an empirical statement about training stability and performance rather than a mathematical reduction to its own inputs. No steps meet the criteria for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Model-predictive control via cross- entropy and gradient-based optimization
Homanga Bharadhwaj, Kevin Xie, and Florian Shkurti. Model-predictive control via cross- entropy and gradient-based optimization. InConference on Learning for Dynamics and Control, Proceedings of Machine Learning Research. PMLR, 2020
2020
-
[2]
Hadi Amini, and Yanzhao Wu
Badhan Chandra Das, M. Hadi Amini, and Yanzhao Wu. Security and privacy challenges of large language models: A survey.ACM Computing Surveys, 2025. 9
2025
-
[3]
HotFlip: White-box adversarial examples for text classification
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. HotFlip: White-box adversarial examples for text classification. InAnnual Meeting of the Association for Computational Linguistics, pages 31–36. Association for Computational Linguistics, 2018
2018
-
[4]
RLP: Reinforcement as a pretraining objective
Ali Hatamizadeh, Syeda Nahida Akter, Shrimai Prabhumoye, Jan Kautz, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, and Yejin Choi. RLP: Reinforcement as a pretraining objective. InInternational Conference on Learning Representations, 2026
2026
-
[5]
Cross-entropy games for language models: From implicit knowledge to general capability measures, 2025
Clément Hongler and Andrew Emil. Cross-entropy games for language models: From implicit knowledge to general capability measures, 2025
2025
-
[6]
Cognitive training for language models: Towards general capabilities via cross-entropy games, 2026
Clément Hongler, Franck Gabriel, Valentin Hartmann, Arthur Renard, and Andrew Emil. Cognitive training for language models: Towards general capabilities via cross-entropy games, 2026
2026
-
[7]
Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin
Edward J. Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin. Amortizing intractable inference in large language models. In International Conference on Learning Representations, 2024
2024
-
[8]
CEM-GD: Cross-entropy method with gradient descent planner for model-based reinforcement learning, 2021
Kevin Huang, Sahin Lale, Ugo Rosolia, Yuanyuan Shi, and Anima Anandkumar. CEM-GD: Cross-entropy method with gradient descent planner for model-based reinforcement learning, 2021
2021
-
[9]
Cosmopedia
Hugging FaceTB. Cosmopedia. https://huggingface.co/datasets/HuggingFaceTB/ cosmopedia, 2024. Apache License 2.0. Accessed: 2026-05-07
2024
-
[10]
Gradient-based constrained sampling from language models
Sachin Kumar, Biswajit Paria, and Yulia Tsvetkov. Gradient-based constrained sampling from language models. InConference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022
2022
-
[11]
TaylorGAN: Neighbor- augmented policy update towards sample-efficient natural language generation
Chun-Hsing Lin, Siang-Ruei Wu, Hung-Yi Lee, and Yun-Nung Chen. TaylorGAN: Neighbor- augmented policy update towards sample-efficient natural language generation. InAdvances in Neural Information Processing Systems, 2020
2020
-
[12]
COLD decoding: Energy- based constrained text generation with langevin dynamics
Lianhui Qin, Sean Welleck, Daniel Khashabi, and Yejin Choi. COLD decoding: Energy- based constrained text generation with langevin dynamics. InAdvances in Neural Information Processing Systems, 2022
2022
-
[13]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[14]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Logan, Eric Wallace, and Sameer Singh
Taylor Shin, Yasaman Razeghi, Robert L. Logan, Eric Wallace, and Sameer Singh. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. InCon- ference on Empirical Methods in Natural Language Processing, pages 4222–4235. Association for Computational Linguistics, 2020
2020
-
[17]
Sutton, David McAllester, Satinder Singh, and Yishay Mansour
Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. InAdvances in Neural Information Processing Systems. MIT Press, 1999
1999
-
[18]
Williams
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine Learning, 1992
1992
-
[19]
role": "user
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023. 10 A Fraction of parents replaced 20 21 22 23 24 25 26 27 D (mutation budget) 0.0 0.2 0.4 0.6 0.8Frac. parents replaced Fraction of parents replaced (K = 8, 2048 prompts) Random TopProb T...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.