Hierarchical Prompt-Domain Control and Learning for Resource-Constrained Agentic Language Models
Pith reviewed 2026-06-29 17:04 UTC · model grok-4.3
The pith
A hierarchical control framework separates schema learning from semantic adaptation in compact agentic language models to raise reliability and cut costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
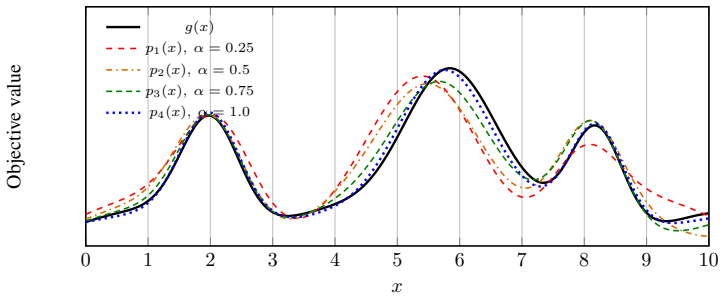
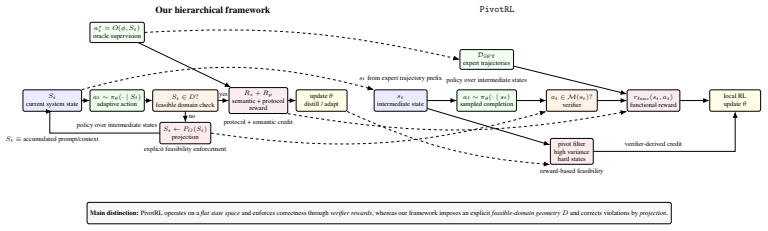
The paper claims that formalizing prompt-domain feasibility and attention saturation shows why nominal context length is not enough; instead, an oracle-controller must project histories into a feasible domain and trigger lightweight fine-tuning only under detected drift, thereby separating schema learning for compatibility from semantic adaptation for task correction and producing higher reliability at lower cost than non-hierarchical or distillation-only methods.
What carries the argument
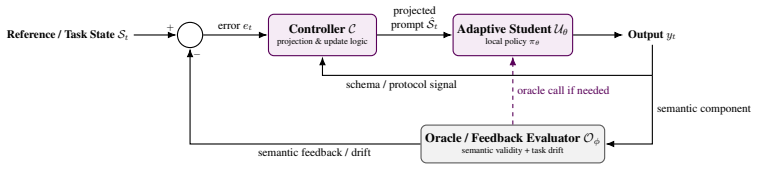
The oracle-controller loop that monitors protocol validity and semantic performance, projects accumulated histories into a feasible prompt domain, and selectively triggers oracle-supervised fine-tuning.
If this is right
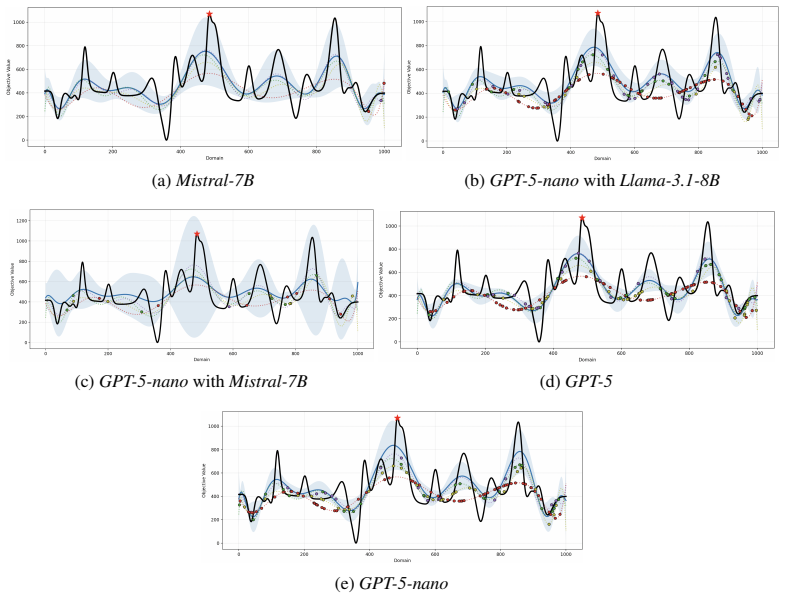
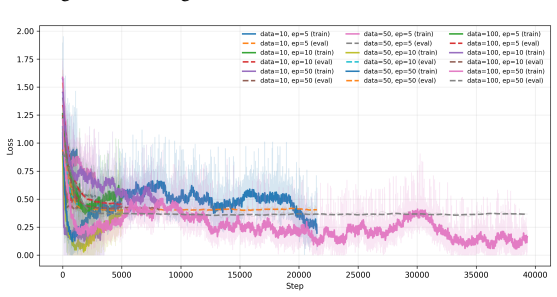
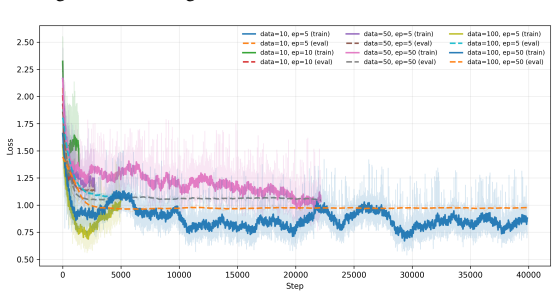
- The framework improves reliability over non-hierarchical, distillation-only, and non-distilled baselines in the Multi-Fidelity Bayesian Optimization testbed.
- Cost-efficiency rises because fine-tuning occurs only under detected drift rather than continuously.
- Prompt-domain feasibility formalization explains why growing context alone fails for compact models.
- Schema learning and semantic adaptation can be handled at different time scales without interfering.
Where Pith is reading between the lines
- The same separation of protocol stability from task adaptation might apply to non-language agent systems that must obey fixed message formats.
- If the controller overhead stays low, the method could be tested directly on deployed chat or tool-use agents to measure real drift rates.
- Connections to adaptive filtering or online learning in control theory could suggest ways to reduce the oracle requirement further.
Load-bearing premise
An oracle-controller can monitor protocol and semantic performance, project histories into a feasible domain, and trigger fine-tuning without adding prohibitive overhead or new failure modes.
What would settle it
A side-by-side deployment run showing that the controller's monitoring and projection steps produce higher total cost or more protocol violations than a simple distillation baseline would falsify the central claim.
Figures

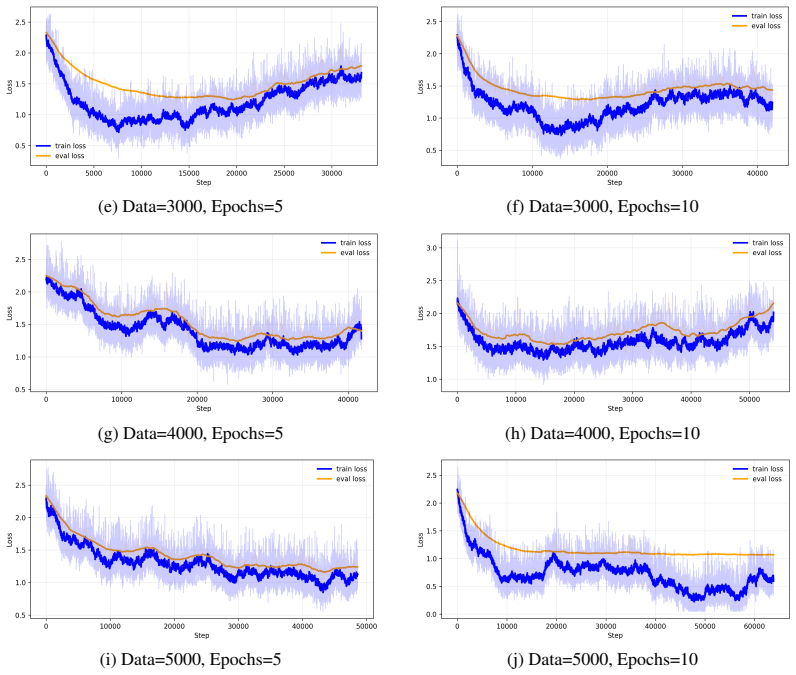
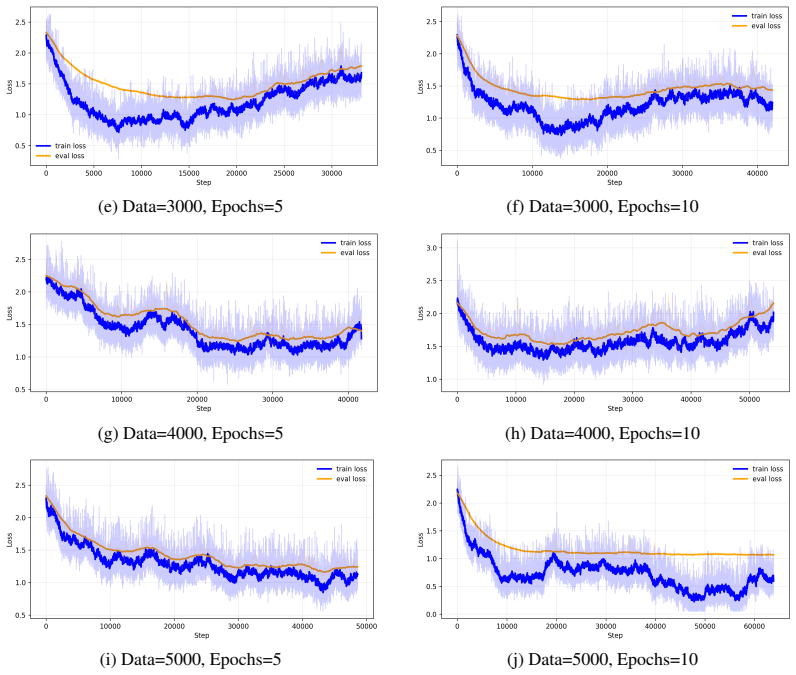
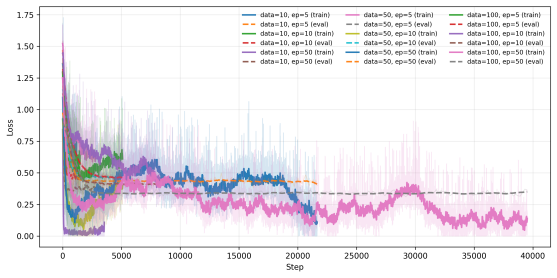
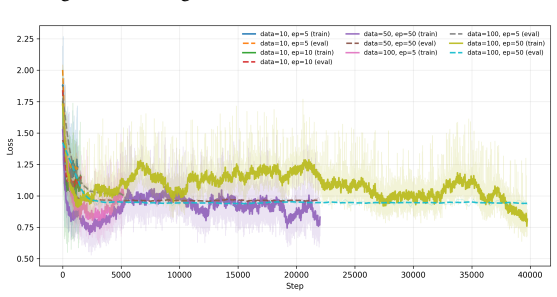
read the original abstract
Large Language Models are increasingly deployed inside agentic systems, where they must follow structured protocols, adapt to evolving states, and operate under memory, latency, and cost constraints. In such regimes, prompt extension is unreliable: growing contexts can push compact models outside their effective prompt domain, while deployment-time fine-tuning remains limited by scarce data and compute. We propose a hierarchical control-and-learning framework in which a compact model is first distilled to learn the required output schema, then supervised online by an oracle-controller loop. The controller monitors protocol validity and semantic performance, projects accumulated histories into a feasible prompt domain, and triggers lightweight oracle-supervised fine-tuning under drift. This separates schema learning for communication compatibility from semantic adaptation for task-level correction. We formalize prompt-domain feasibility and attention-induced saturation, motivating control of the effective prompt state rather than reliance on nominal context length. Using Multi-Fidelity Bayesian Optimization as a controlled sequential testbed, we characterize a core deployment failure mode and show improved reliability and cost-efficiency over non-hierarchical, distillation-only, and non-distilled baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical control-and-learning framework for resource-constrained agentic LLMs. A compact model is first distilled to learn output schemas for communication compatibility; an oracle-controller then monitors protocol validity and semantic performance, projects histories into a feasible prompt domain, and triggers lightweight fine-tuning under drift. This separation is motivated by formalizing prompt-domain feasibility and attention-induced saturation. Using Multi-Fidelity Bayesian Optimization (MFBO) as a sequential testbed, the work characterizes a core deployment failure mode and reports improved reliability and cost-efficiency over non-hierarchical, distillation-only, and non-distilled baselines.
Significance. If the empirical claims hold after accounting for controller overhead, the framework would offer a practical route to reliable deployment of compact models in agentic systems by controlling effective prompt state rather than nominal context length. The separation of schema learning from semantic adaptation, together with the MFBO testbed for controlled failure-mode characterization, could influence prompt-engineering and online-adaptation research in resource-limited settings.
major comments (1)
- [Abstract (paragraph 3) and MFBO testbed setup] Abstract (paragraph 3) and MFBO testbed setup: The central claim that the hierarchical separation yields improved reliability and cost-efficiency rests on the oracle-controller being able to monitor, project, and trigger fine-tuning without prohibitive overhead or new failure modes. No explicit accounting of oracle compute, latency, or controller-induced errors appears in the testbed description or baseline comparisons; if the oracle is treated as perfect and free, the reported gains may not survive in truly resource-constrained regimes where controller costs are included.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding the need to account for oracle-controller overhead. We agree that this is a substantive point for validating the framework's claims under resource constraints and will revise the manuscript to address it.
read point-by-point responses
-
Referee: [Abstract (paragraph 3) and MFBO testbed setup] Abstract (paragraph 3) and MFBO testbed setup: The central claim that the hierarchical separation yields improved reliability and cost-efficiency rests on the oracle-controller being able to monitor, project, and trigger fine-tuning without prohibitive overhead or new failure modes. No explicit accounting of oracle compute, latency, or controller-induced errors appears in the testbed description or baseline comparisons; if the oracle is treated as perfect and free, the reported gains may not survive in truly resource-constrained regimes where controller costs are included.
Authors: We agree that the current description of the MFBO testbed does not include explicit accounting of oracle compute, latency, or controller-induced errors, and that this omission weakens the central claim when the setting is strictly resource-constrained. In the framework the oracle is an external high-fidelity supervisor invoked only on detected drift, while the controller performs lightweight monitoring and projection; however, these operations still incur costs that are not quantified in the reported baselines. We will revise the testbed section and add a dedicated paragraph (or short subsection) that (i) states the modeling assumption that the oracle lies outside the agent's resource budget, (ii) provides a qualitative breakdown of controller overhead relative to the distilled model, and (iii) includes a sensitivity discussion showing how the reported reliability and cost-efficiency gains change when a non-zero controller cost is folded into the total. This revision will be textual and analytical rather than requiring new experimental runs. revision: partial
Circularity Check
No circularity; framework proposal lacks derivations or self-referential reductions
full rationale
The manuscript proposes a hierarchical prompt-domain control framework separating schema distillation from oracle-supervised semantic adaptation, formalized around prompt-domain feasibility and attention saturation. However, the provided text contains no equations, parameter fits, predictions, or uniqueness theorems that could reduce by construction to inputs. Claims rest on empirical MFBO testbed comparisons against baselines rather than any self-definitional or self-citation load-bearing chain. The oracle-controller is presented as an external component without internal mathematical closure that would trigger the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2502.03450. Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. How abilities in large language models are affected by supervised fine-tuning data composition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (...
-
[2]
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Version 2, 5 Jul 2023. Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, page 13358–13376. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.emn...
-
[3]
Scaling Laws for Neural Language Models
URLhttps://arxiv.org/abs/2001.08361. Bernhard Korte and László Lovász. Mathematical structures underlying greedy algorithms. In Ferenc Gecseg, editor,Fundamentals of Computation Theory, volume 117 ofLecture Notes in Computer Science, pages 205–209, Berlin, 1981. Springer. Andreas Krause and Jonas Hübotter. Probabilistic artificial intelligence, 2025. URL ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41524-019-0153-8 2001
-
[4]
doi: 10.1016/j.jmsy.2025.08.017
ISSN 0278-6125. doi: 10.1016/j.jmsy.2025.08.017. URL http://dx.doi.org/10.1016/ j.jmsy.2025.08.017. Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications,
-
[5]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
URLhttps://arxiv.org/abs/2402.07927. Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2016. doi: 10.18653/v1/p16-1162. URLhttp://dx.doi.o...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/p16-1162 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.