LLM Based Web Accessibility Repair: An Empirical Study of Detection, Remediation, and Cost
Pith reviewed 2026-06-29 15:21 UTC · model grok-4.3
The pith
LLMs achieve partial web accessibility repairs but resolve fewer than 26 percent of cases completely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
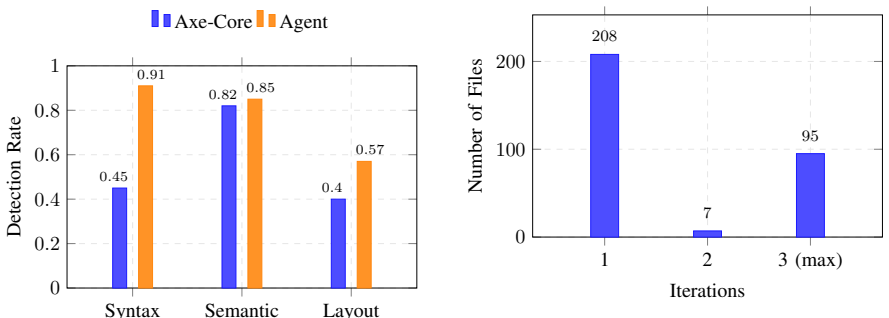
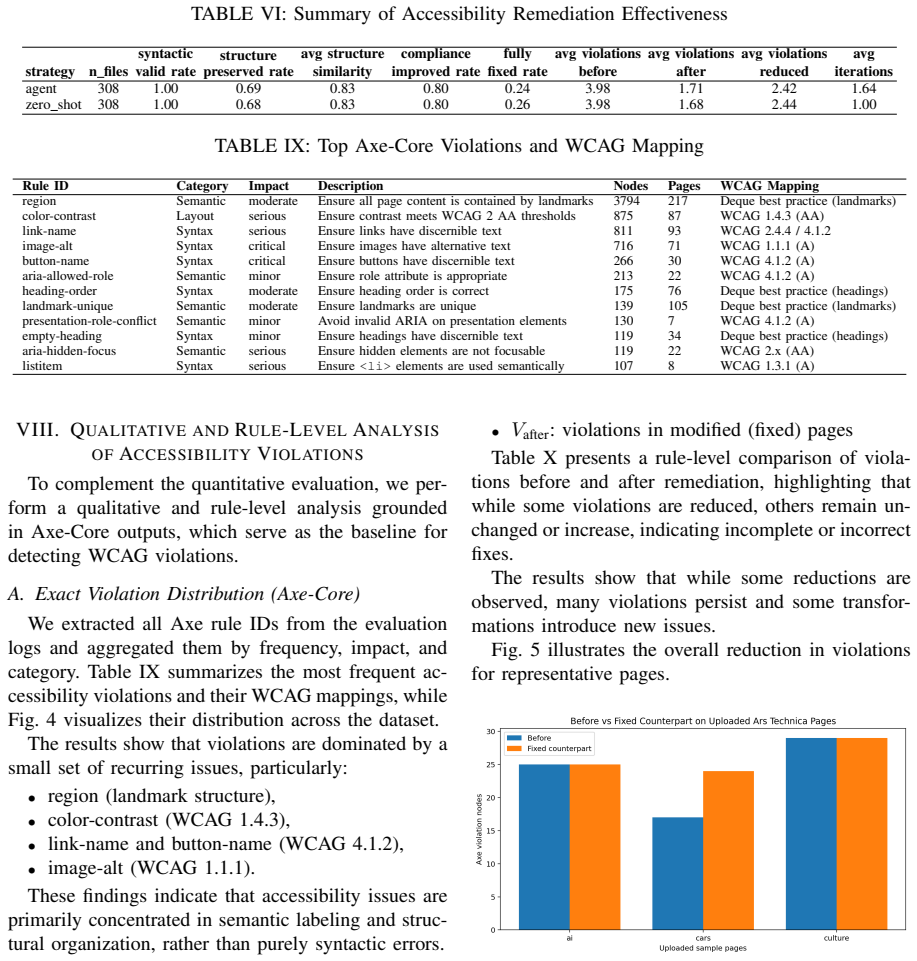
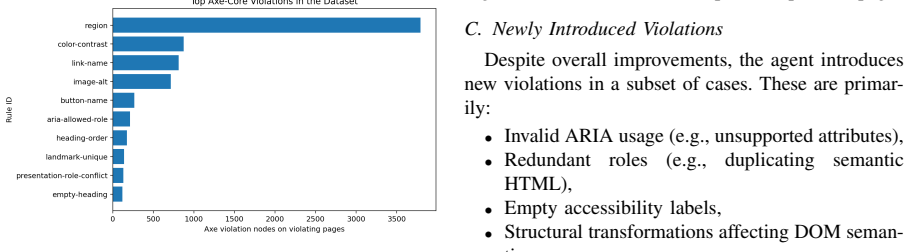
LLM-based agents detect accessibility violations with F1 scores around 0.65 overall and 0.83 for semantic issues, comparable to rule-based tools, and generate syntactically valid fixes in over 99.7 percent of cases that reduce violations from 3.98 to 1.7 per file in 80.2 percent of instances. However, full resolution occurs in fewer than 26 percent of cases, about 30 percent of patches introduce structural changes, and iterative refinement raises costs by 52 percent and API usage by 1.64 times without improving results.
What carries the argument
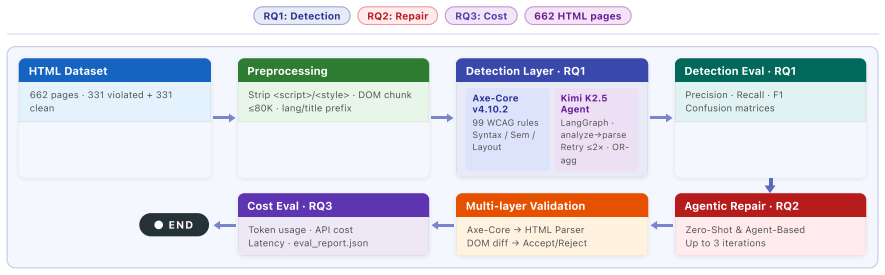
The Kimi K2.5 LLM agent applied to detection and remediation of accessibility violations in HTML files, benchmarked against rule-based tools using F1 scores, violation counts, and compliance metrics.
If this is right
- LLM detection works well for semantic violations but struggles with syntactic and layout ones.
- Generated fixes are reliable in syntax but often leave residual violations requiring further work.
- Adding iterative refinement to the agent increases expense without better repair rates.
- Scalable solutions must integrate LLM generation with rule-based validation and constraint checks.
Where Pith is reading between the lines
- Real-world testing with actual users who have disabilities would show if the partial fixes translate to better usability.
- Embedding these LLM agents into existing accessibility scanning tools could lower the cost of initial repairs.
- Models trained specifically on accessibility guidelines might handle layout violations better than general LLMs.
Load-bearing premise
The chosen web files and violation types, along with the automated metrics, accurately reflect real-world accessibility issues and that the measured improvements mean better usability for people with disabilities.
What would settle it
Observing full resolution of all violations in more than 50 percent of test files without structural changes or new violations introduced by the LLM would falsify the claim that LLMs are insufficient for complete remediation.
Figures

read the original abstract
Ensuring web accessibility at scale remains challenging because rule-based tools provide limited coverage while manual remediation is costly and error-prone. This paper evaluates large language model based agents, specifically Kimi K2.5, for automated accessibility detection and repair compared with rule-based approaches. For detection, the LLM achieves performance comparable to rule-based tools, with F1 around 0.65, strong semantic understanding with F1 of 0.83, but lower reliability for syntactic and layout-related violations. For remediation, LLM-generated fixes are syntactically valid in over 99.7 percent of cases and improve accessibility compliance in 80.2 percent of instances, reducing violations from 3.98 to 1.7 per file. However, fewer than 26 percent of cases are fully resolved, and about 30 percent of patches introduce structural changes. We also find that iterative agent-based refinement increases computational cost by 52 percent and API usage by 1.64 times without improving remediation outcomes. These findings indicate that while LLMs are effective for partial accessibility repair, they are insufficient for complete and reliable remediation. Scalable accessibility solutions require hybrid approaches that combine LLM capabilities with rule-based validation and constraint-aware correction mechanisms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates the LLM Kimi K2.5 for web accessibility violation detection and remediation on web files, reporting F1 scores of ~0.65 overall (0.83 on semantic issues) comparable to rule-based tools, with remediation fixes being syntactically valid in >99.7% of cases, improving compliance in 80.2% of instances (reducing violations from 3.98 to 1.7 per file), but fully resolving <26% of cases. Iterative refinement increases cost by 52% and API usage by 1.64x without outcome gains. The central claim is that LLMs enable partial repair but are insufficient for complete/reliable remediation, necessitating hybrid LLM + rule-based systems.
Significance. If the empirical measurements hold, the work supplies concrete before-and-after violation counts, validity rates, and cost multipliers that quantify LLM limitations in accessibility repair, supporting the case for hybrid approaches. The direct reporting of percentages (80.2% improvement, <26% full resolution) and the comparison of single vs. iterative agent use are strengths that could inform tool design, though generalizability depends on unstated dataset details.
major comments (2)
- [Abstract / Methods] Abstract and Methods (dataset description): The central claim that LLMs are 'insufficient for complete and reliable remediation' rests on the observed drop to 1.7 violations/file and <26% full resolution, yet the abstract and reported experiments provide no dataset size, file selection criteria, number of violation types, or statistical tests; this leaves the 80.2% improvement rate vulnerable to selection bias and undermines the empirical grounding for requiring hybrid systems.
- [Evaluation / Remediation results] Evaluation section (remediation metrics): The conclusion that automated fixes do not achieve reliable remediation relies exclusively on rule-based checker outputs (violation counts, F1); no user study, task-performance measure, or correlation analysis with actual usability for screen-reader or low-vision users is reported, so the claim that <26% full resolution indicates insufficiency for real accessibility gains lacks direct evidence.
minor comments (2)
- [Abstract] Abstract: 'F1 around 0.65' and 'F1 of 0.83' should be replaced with exact values and the number of instances or files evaluated to improve precision.
- [Methods] The paper should clarify the prompting strategy and model version details (Kimi K2.5) in the methods to allow replication of the detection and remediation agents.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical evaluation of LLM-based accessibility repair. The comments highlight important areas for improving transparency and acknowledging limitations. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (dataset description): The central claim that LLMs are 'insufficient for complete and reliable remediation' rests on the observed drop to 1.7 violations/file and <26% full resolution, yet the abstract and reported experiments provide no dataset size, file selection criteria, number of violation types, or statistical tests; this leaves the 80.2% improvement rate vulnerable to selection bias and undermines the empirical grounding for requiring hybrid systems.
Authors: We agree that the abstract and Methods section would benefit from more explicit reporting of dataset characteristics to allow readers to assess potential selection bias. The full manuscript describes the experimental files and violation types in the Evaluation section, but we will revise the abstract to note the dataset scale and expand Methods with a dedicated paragraph on file selection criteria, the specific violation types covered, and any statistical tests applied. These additions will be incorporated in the next version. revision: yes
-
Referee: [Evaluation / Remediation results] Evaluation section (remediation metrics): The conclusion that automated fixes do not achieve reliable remediation relies exclusively on rule-based checker outputs (violation counts, F1); no user study, task-performance measure, or correlation analysis with actual usability for screen-reader or low-vision users is reported, so the claim that <26% full resolution indicates insufficiency for real accessibility gains lacks direct evidence.
Authors: We acknowledge that the evaluation relies solely on automated rule-based metrics and does not include user studies measuring actual usability for screen-reader or low-vision users. Violation counts and F1 scores are standard proxies in accessibility literature, but we agree this does not directly demonstrate real-world accessibility gains. We will add a new paragraph in the Discussion section that explicitly states this limitation, qualifies the insufficiency claim as based on automated metrics, and suggests future user studies to validate practical impact. This constitutes a partial revision as we cannot add new empirical user data at this stage. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivations or fitted predictions
full rationale
The paper reports direct experimental outcomes from running LLMs on web files: F1 scores for detection, violation counts before/after remediation, syntactic validity rates, and cost metrics. No equations, parameters fitted to subsets then re-predicted, self-citation chains, or ansatzes appear in the abstract or described full text. All claims rest on observed counts and percentages from the chosen checkers and files, which are external to any model defined inside the paper. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption F1 score and per-file violation counts are valid proxies for accessibility detection and remediation quality
- domain assumption The evaluated web files are representative of typical accessibility issues encountered in practice
Reference graph
Works this paper leans on
-
[1]
Santos, J., et al. (2024). AccessGuru: Leveraging LLMs to detect and correct web accessibility violations in HTML code. arXiv
2024
-
[2]
Kumar, R., et al. (2024). AI-enhanced web form development: Tackling accessibility barriers with generative technologies. IEEE
2024
-
[3]
Williams, J., et al. (2024). Improving web accessibility with an LLM-based tool: A preliminary evaluation for STEM images. ACM CHI
2024
-
[4]
Zhang, Y ., et al. (2024). Designing for inclusion: Human- centered multi-agent accessibility repair in modern web ap- plications. ACM CHI
2024
-
[5]
Garcia, M., et al. (2024). How an LLM can improve automatic web accessibility validation? arXiv
2024
-
[6]
Chen, L., et al. (2024). An assessment of LLM-based auditing and validation for web accessibility. arXiv
2024
-
[7]
Garc ´ıa, S., et al. (2021). Wrappers for web access logs feature selection. World Wide Web, 24, 1875–1898
2021
-
[8]
S., & Zettlemoyer, L
Wu, J., Ross, A. S., & Zettlemoyer, L. (2024).Large Language Models as Accessibility Auditors: Evaluating LLMs for WCAG Compliance Detection
2024
-
[9]
P., & Ladner, R
Li, Y ., Bigham, J. P., & Ladner, R. E. (2023).AI-Assisted Web Accessibility Repair: Generating Accessible Code with Language Models
2023
-
[10]
(2024).Automatic Alt-Text Generation for Web Images Using Vision-Language Models
Sunkara, S., Gurari, D., & Grauman, K. (2024).Automatic Alt-Text Generation for Web Images Using Vision-Language Models
2024
-
[11]
T. B. Brown, B. Mann, N. Ryder, et al., ”Language Models are Few-Shot Learners,”Advances in Neural In- formation Processing Systems (NeurIPS), 2020. Available: https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[12]
OpenAI, ”GPT-4 Technical Report,” 2023. Available: https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
M. Chen, J. Tworek, H. Jun, et al., ”Evaluating Large Language Models Trained on Code,” 2021. Available: https://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Li et al., ”Competition-Level Code Gen- eration with AlphaCode,”Science, vol
Y . Li et al., ”Competition-Level Code Gen- eration with AlphaCode,”Science, vol. 378, no. 6624, pp. 1092–1097, 2022. Available: https://www.science.org/doi/10.1126/science.abq1158
-
[15]
S. Yao, J. Zhao, D. Yu, et al., ”ReAct: Synergizing Rea- soning and Acting in Language Models,” 2023. Available: https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schick, J. Dwivedi-Yu, R. Dess `ı, et al., ”Toolformer: Lan- guage Models Can Teach Themselves to Use Tools,” 2023. Available: https://arxiv.org/abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.