Bayesian Deployment Approval for Learned Landing Controllers under Finite Rollout Validation
Pith reviewed 2026-06-29 18:34 UTC · model grok-4.3
The pith
Bayesian posterior inference provides uncertainty-calibrated deployment approval for learned landing controllers from finite rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
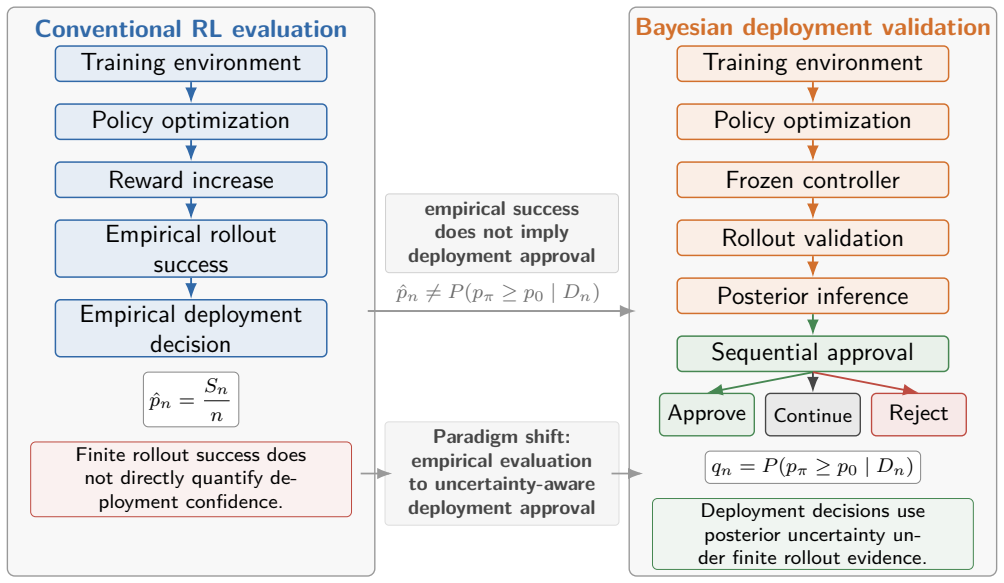
Posterior approval inference on a probabilistic landing capability model offers a more uncertainty-calibrated assessment of deployment readiness than empirical success frequency or reward optimization under limited validation evidence.
What carries the argument
Bayesian posterior inference applied to a probabilistic landing capability model based on touchdown safety satisfaction under uncertain operating conditions.
Load-bearing premise
A probabilistic model of landing capability based on safety satisfaction can be reliably inferred from finite rollout trajectories.
What would settle it
An experiment in which the Bayesian approval probability approves a policy that then fails consistently in additional unseen rollouts while empirical success rates remain high.
Figures


read the original abstract
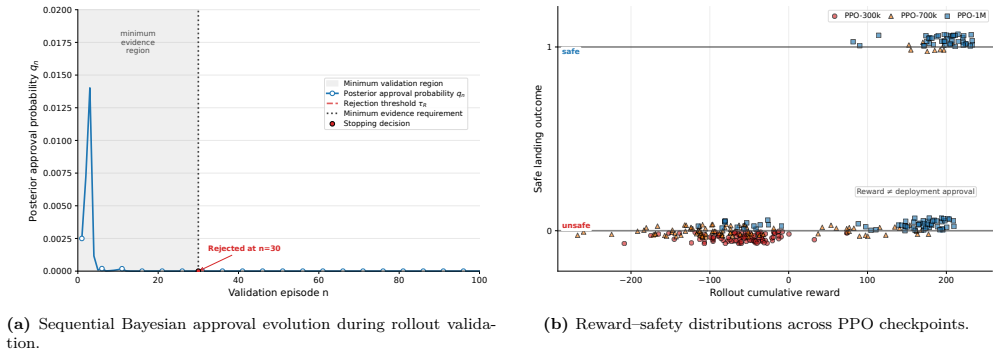
Reinforcement learning and data-driven autonomous controllers are commonly evaluated using cumulative reward and empirical success frequency under finite simulation trajectories. However, such empirical metrics do not necessarily provide sufficient statistical evidence regarding deployment readiness under uncertainty. This work develops a Bayesian approval framework for learned autonomous landing controllers under finite rollout evidence. A probabilistic landing capability formulation is introduced based on touchdown safety satisfaction under uncertain operating conditions, while Bayesian posterior inference is used to quantify uncertainty regarding the true deployment capability of learned policies. Posterior approval probability and posterior deployment risk are further introduced for deployment-oriented evaluation, together with a sequential validation framework supporting approve/reject/continue decisions during progressive rollout testing. Simulation experiments using PPO and SAC controllers demonstrate that empirical success and reward optimization may produce overconfident deployment interpretation under limited validation evidence, whereas posterior approval inference provides a more uncertainty-calibrated assessment of deployment readiness. The proposed framework provides a practical statistical connection between conventional reinforcement-learning evaluation and deployment-oriented validation under uncertainty and may be generalized to broader classes of learned autonomous systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Bayesian deployment approval framework for learned autonomous landing controllers evaluated under finite rollout trajectories. It defines a probabilistic landing capability model based on touchdown safety satisfaction under uncertain operating conditions, performs posterior inference over this capability from simulation data, and defines posterior approval probability and posterior deployment risk metrics. A sequential validation procedure is proposed to support approve/reject/continue decisions. Simulation experiments on PPO and SAC policies are used to show that empirical success frequency and reward optimization can yield overconfident deployment interpretations under small rollout budgets, while the Bayesian quantities provide more uncertainty-calibrated assessments.
Significance. If the modeling and inference steps hold, the framework supplies a statistically grounded bridge between standard RL evaluation metrics and deployment-oriented validation under uncertainty. The explicit construction of posterior approval probability and risk, together with the sequential procedure and the reported divergence from empirical frequency in the PPO/SAC experiments, constitute a concrete contribution that could be generalized to other learned autonomous systems. The work is strengthened by the provision of the capability model, likelihood construction, and comparative simulation evidence.
minor comments (3)
- §3 (or equivalent): the likelihood function for touchdown safety under uncertain conditions should be stated explicitly with its dependence on policy parameters and environmental variables; the current description leaves the precise form of the observation model implicit.
- Figure 4 (or equivalent simulation comparison): axis labels and legend entries should clarify whether the plotted quantities are posterior means, credible intervals, or point estimates of approval probability; the current caption is ambiguous on this point.
- The sequential validation algorithm (Algorithm 1) would benefit from an explicit statement of the decision thresholds used for approve/reject/continue and how they relate to the posterior risk metric.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the contribution, the significance statement, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces a probabilistic landing capability model and applies standard Bayesian posterior inference to finite rollout data to compute approval probabilities and risk metrics. These quantities are defined directly from the likelihood of touchdown safety under uncertainty and a prior; they do not reduce to fitted parameters renamed as predictions, nor does any central claim rest on self-citation chains or imported uniqueness theorems. The reported simulation comparisons (PPO/SAC policies) demonstrate divergence from empirical frequency under small budgets, providing an independent empirical check rather than a tautological equivalence. The derivation remains self-contained against external benchmarks with no load-bearing steps that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Rein- forcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[2]
Human-level control through deep reinforcement learning.nature, 518 (7540):529–533, 2015
Volodymyr Mnih, Koray Kavukcuoglu, David Sil- ver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidje- land, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518 (7540):529–533, 2015
2015
-
[3]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhari- wal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Soft actor-critic: Off-policy max- imum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy max- imum entropy deep reinforcement learning with a stochastic actor. InInternational conference on ma- chine learning, pages 1861–1870. Pmlr, 2018
2018
-
[5]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Reinforcement learning for uav atti- tude control.ACM Transactions on Cyber-Physical Systems, 3(2):1–21, 2019
William Koch, Renato Mancuso, Richard West, and Azer Bestavros. Reinforcement learning for uav atti- tude control.ACM Transactions on Cyber-Physical Systems, 3(2):1–21, 2019
2019
-
[7]
A deep reinforcement learning strategy for uav autonomous landing on a moving platform.Jour- nal of Intelligent & Robotic Systems, 93(1):351–366, 2019
Alejandro Rodriguez-Ramos, Carlos Sampedro, Hri- day Bavle, Paloma De La Puente, and Pascual Cam- poy. A deep reinforcement learning strategy for uav autonomous landing on a moving platform.Jour- nal of Intelligent & Robotic Systems, 93(1):351–366, 2019
2019
-
[8]
A compre- hensive survey on safe reinforcement learning.Jour- nal of Machine Learning Research, 16(1):1437–1480, 2015
Javier Garcıa and Fernando Fernández. A compre- hensive survey on safe reinforcement learning.Jour- nal of Machine Learning Research, 16(1):1437–1480, 2015
2015
-
[9]
Autonomous vehicle safety: An interdisciplinary challenge.IEEE Intelligent Transportation Systems Magazine, 9(1): 90–96, 2017
Philip Koopman and Michael Wagner. Autonomous vehicle safety: An interdisciplinary challenge.IEEE Intelligent Transportation Systems Magazine, 9(1): 90–96, 2017. 15
2017
-
[10]
Uncertainty-Aware Reinforcement Learning for Collision Avoidance
Gregory Kahn, Adam Villaflor, Vitchyr Pong, Pieter Abbeel, and Sergey Levine. Uncertainty-aware re- inforcement learning for collision avoidance.arXiv preprint arXiv:1702.01182, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Safe reinforcement learning via shielding
Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk Topcu. Safe reinforcement learning via shielding. In Proceedings of the AAAI conference on artificial in- telligence, volume 32, 2018
2018
-
[12]
On calibration of modern neural net- works
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural net- works. InInternational conference on machine learn- ing, pages 1321–1330. PMLR, 2017
2017
-
[13]
Simple and scalable predictive un- certainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive un- certainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
2017
-
[14]
Can you trust your model’s uncertainty? evaluating pre- dictive uncertainty under dataset shift.Advances in neural information processing systems, 32, 2019
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshminarayanan, and Jasper Snoek. Can you trust your model’s uncertainty? evaluating pre- dictive uncertainty under dataset shift.Advances in neural information processing systems, 32, 2019
2019
-
[15]
Finite-sample decision insta- bility in threshold-based process capability approval
Fei Jiang and Lei Yang. Finite-sample decision insta- bility in threshold-based process capability approval. arXiv:2603.11315, 2026
-
[16]
Risk-Calibrated Process Capability Approval with Finite Samples
Fei Jiang and Lei Yang. Risk-calibrated process capability approval with finite samples.Interna- tional Journal of Advanced Manufacturing Tech- nology, 2026. doi: 10.1007/s00170-026-18284-2. Preprint available at arXiv:2603.14479
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s00170-026-18284-2 2026
-
[17]
A Machine Learning Framework for Uncertainty-Calibrated Capability Decision under Finite Samples
Fei Jiang and Lei Yang. A machine learning frame- work for uncertainty-calibrated capability decision under finite samples.arXiv:2604.13352, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Sequential tests of statistical hy- potheses
Abraham Wald. Sequential tests of statistical hy- potheses. InBreakthroughs in statistics: Foun- dations and basic theory, pages 256–298. Springer, 1992
1992
-
[19]
Chapman and Hall/CRC, 1995
Andrew Gelman, John B Carlin, Hal S Stern, and Donald B Rubin.Bayesian data analysis. Chapman and Hall/CRC, 1995
1995
-
[20]
Springer Science & Business Me- dia, 2013
James O Berger.Statistical decision theory and Bayesian analysis. Springer Science & Business Me- dia, 2013
2013
-
[21]
CRC press, 2014
Alexander Tartakovsky, Igor Nikiforov, and Michele Basseville.Sequential analysis: Hypothesis testing and changepoint detection. CRC press, 2014
2014
-
[22]
Using measurement uncer- tainty in decision-making and conformity assess- ment.Metrologia, 51(4):S206–S218, 2014
Leslie R Pendrill. Using measurement uncer- tainty in decision-making and conformity assess- ment.Metrologia, 51(4):S206–S218, 2014
2014
-
[23]
CRC press, 2016
Mohammad Modarres, Mark P Kaminskiy, and Vasiliy Krivtsov.Reliability engineering and risk analysis: a practical guide. CRC press, 2016
2016
-
[24]
Evaluation of measurement data — the role of measurement uncertainty in conformity assessment,
Joint Committee for Guides in Metrology (JCGM). Evaluation of measurement data — the role of measurement uncertainty in conformity assessment,
-
[25]
JCGM 106:2012
URLhttps://www.bipm.org/documents/ 20126/2071204/JCGM_106_2012_E.pdf. JCGM 106:2012
2012
-
[26]
Springer, 2008
Albert N Shiryaev.Optimal stopping rules. Springer, 2008
2008
-
[27]
Sim-to-real transfer in deep reinforce- ment learning for robotics: a survey
Wenshuai Zhao, Jorge Peña Queralta, and Tomi Westerlund. Sim-to-real transfer in deep reinforce- ment learning for robotics: a survey. In2020 IEEE symposium series on computational intelli- gence (SSCI), pages 737–744. IEEE, 2020. 16
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.