UNIQUE: Universal Top-k Sparse Attention for Training-free Inference and Sparsity-aware Training
Pith reviewed 2026-06-29 17:46 UTC · model grok-4.3
The pith
A simple mean-plus-standard-deviation score on KV pages enables universal top-k sparse attention for both training-free inference and sparsity-aware training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
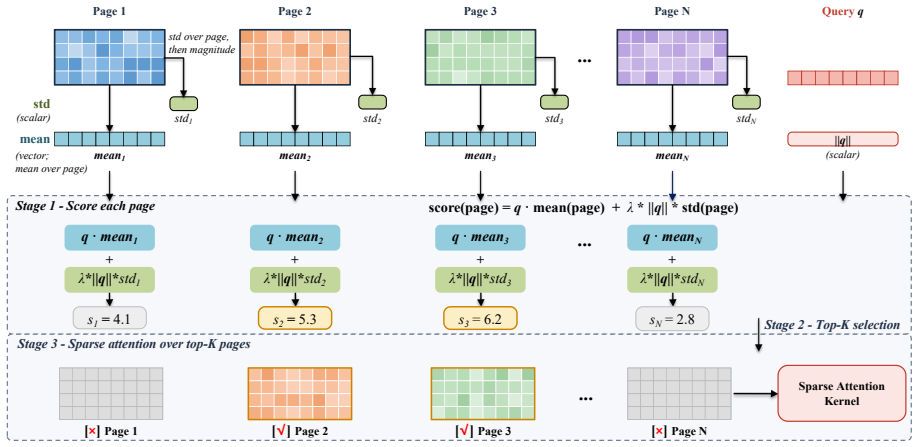
UNIQUE estimates the importance of each KV page using the mean of its keys as a representative vector plus their standard deviation as an offset, then selects the top-k pages for attention computation. For training, it applies a soft mask based on a sigmoid function around the boundary of this top-k score. This approach supports both immediate use in inference and joint training for sparsity, maintaining accuracy on benchmarks like LongBench Pro and long-form speech recognition.
What carries the argument
The per-page importance score that combines the mean of the page's keys as a representative vector with their standard deviation as an offset term, used to select top-k pages.
If this is right
- Task performance is preserved on long-context benchmarks such as LongBench Pro and long-form speech recognition.
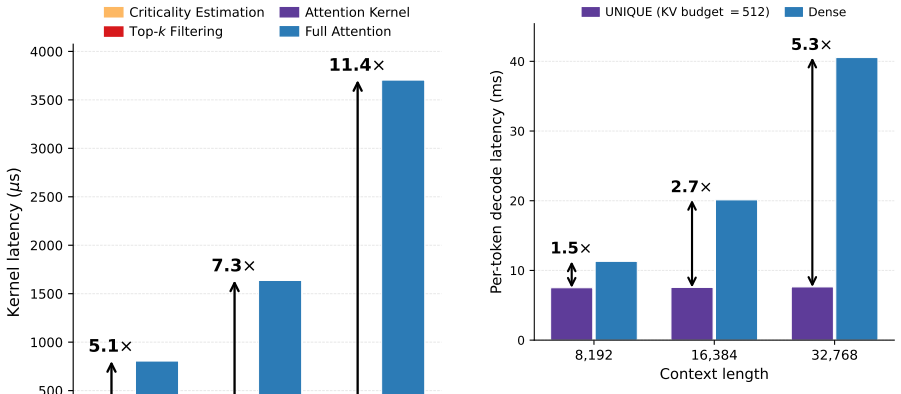
- Attention-kernel speedup reaches up to 11.4x over FlashInfer dense attention.
- End-to-end decoding speedup is at least 5.3x over a vLLM-based dense model.
- The soft-mask training scheme requires neither auxiliary losses nor architectural changes to close the train-inference gap.
- The framework remains effective across text and speech LLM modalities.
Where Pith is reading between the lines
- The score's simplicity suggests it could be adopted quickly in production LLM serving systems without per-model retuning.
- Page-level selection might interact with other memory optimizations like paging or quantization in unexpected ways.
- If the mean-std score generalizes, it could inspire similar lightweight importance estimators for other attention variants.
- Applying this during pretraining might allow even sparser models from the start.
Load-bearing premise
The mean-plus-standard-deviation score accurately captures the importance of KV pages for attention across different LLM modalities and tasks without requiring model-specific tuning.
What would settle it
Measuring task performance on LongBench Pro or speech recognition benchmarks after replacing the proposed score with random page selection or a different estimator and observing a large drop in accuracy.
Figures
read the original abstract
Long-context inference in large language models (LLMs) is bottlenecked by the linear growth of the self-attention key-value (KV) cache. Top-k sparse attention alleviates this by loading only a small fraction of the KV cache, but accurately and cheaply estimating cache importance, for both training-free use and sparsity-aware training, remains challenging. This paper proposes UNIQUE, a universal top-k sparse attention framework that addresses both requirements and stays consistently effective across LLM modalities. UNIQUE operates at the granularity of KV pages and estimates per-page importance with a simple yet accurate score combining the mean of the page's keys as a representative vector with their standard deviation as an offset term. To further close the train-inference gap, this paper introduces a soft-mask sparsity-aware training scheme that uses the top-k score boundary as a per-query threshold and a sigmoid soft mask around it, requiring neither auxiliary losses nor architectural changes. Experiments on text and speech LLMs show that UNIQUE preserves task performance on long-context benchmarks such as LongBench Pro and on long-form speech recognition, while delivering up to 11.4x attention-kernel speedup over FlashInfer dense attention and at least 5.3x end-to-end decoding speedup over a vLLM-based dense model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UNIQUE, a universal top-k sparse attention framework for LLMs operating at KV-page granularity. Page importance is estimated via a fixed heuristic that combines the mean of the page's key vectors as a representative with their standard deviation as an offset. This enables training-free sparse inference and a soft-mask sparsity-aware training scheme that uses the top-k score boundary as a per-query threshold with a sigmoid mask, requiring no auxiliary losses or architecture changes. Experiments claim preserved performance on LongBench Pro and long-form speech recognition alongside up to 11.4x attention-kernel speedup over FlashInfer and 5.3x end-to-end decoding speedup over vLLM dense baselines.
Significance. If the mean-plus-std page score generalizes without model-specific tuning, the work would meaningfully advance efficient long-context inference and training across text and speech modalities by reducing KV-cache overhead while avoiding extra parameters or losses. The parameter-free heuristic and closed train-inference gap via soft masking are clear strengths that distinguish it from tuned or auxiliary-loss approaches.
major comments (2)
- [§3.1] §3.1 (page-score definition): the central universality claim rests on the fixed mean+std estimator accurately ranking KV pages across modalities, yet no ablation against alternatives (max-norm, attention-weighted, or learned) or analysis of key-vector distributional assumptions is provided; this directly bears on whether the observed performance preservation is score-specific or model-specific.
- [§4.2–4.3] §4.2–4.3 (LongBench Pro and speech results): performance is reported as preserved, but without per-task variance, failure-case analysis, or cross-model transfer tests of the same score, the evidence does not yet establish that the heuristic works reliably outside the evaluated models and attention patterns.
minor comments (2)
- [§3.2] Notation for page-level mean and std is introduced without an explicit equation number, making it hard to trace through the soft-mask derivation.
- [Table 4] Speedup tables report kernel vs. end-to-end numbers but do not list the exact batch size, sequence length, and hardware configuration for each entry.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on our methodological choices and experimental evidence.
read point-by-point responses
-
Referee: [§3.1] §3.1 (page-score definition): the central universality claim rests on the fixed mean+std estimator accurately ranking KV pages across modalities, yet no ablation against alternatives (max-norm, attention-weighted, or learned) or analysis of key-vector distributional assumptions is provided; this directly bears on whether the observed performance preservation is score-specific or model-specific.
Authors: The mean-plus-std heuristic is deliberately fixed and parameter-free to support the universality claim without requiring model-specific tuning or learned components. This distinguishes our approach from alternatives that would necessitate per-model adaptation. While we agree that explicit ablations against max-norm, attention-weighted, or learned scores would provide additional context, the manuscript prioritizes demonstrating that this simple estimator suffices for performance preservation across modalities. We will add a concise discussion of the design rationale, including the role of mean as representative and std as variability offset, to the revised manuscript. revision: partial
-
Referee: [§4.2–4.3] §4.2–4.3 (LongBench Pro and speech results): performance is reported as preserved, but without per-task variance, failure-case analysis, or cross-model transfer tests of the same score, the evidence does not yet establish that the heuristic works reliably outside the evaluated models and attention patterns.
Authors: The reported results show performance preservation on LongBench Pro and long-form speech recognition across text and speech LLMs. To improve transparency, we will expand the revised manuscript with per-task breakdowns and variance statistics in an appendix. The fixed heuristic and consistent cross-modality results provide evidence of reliability within the evaluated settings; however, dedicated cross-model transfer experiments beyond those presented were outside the scope of the current study. revision: partial
Circularity Check
No circularity: heuristic score and soft-mask scheme are self-contained
full rationale
The paper defines a fixed, parameter-free importance score (mean of keys plus std offset) directly from KV vectors and applies it both at inference and via a boundary-based soft mask in training. No equations reduce a claimed prediction to a fitted input by construction, no self-citations are invoked as load-bearing uniqueness theorems, and the method is presented as an empirical heuristic validated on external benchmarks rather than derived from prior author results. The derivation chain therefore contains no self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The combination of mean key vector and standard deviation provides an accurate estimate of page importance for top-k selection.
Reference graph
Works this paper leans on
-
[1]
GQA: training generalized multi-query trans- former models from multi-head checkpoints. InProc. EMNLP. Yushi Bai, Xin Lv, Jiajie Zhang, Yuze He, Ji Qi, Lei Hou, Jie Tang, Yuxiao Dong, and Juanzi Li. 2024. LongAlign: A recipe for long context alignment of large language models. InProc. EMNLP (Findings). Ziyang Chen, Xing Wu, Junlong Jia, Chaochen Gao, Qi F...
-
[2]
Vibevoice technical report.arXiv preprint arXiv:2508.19205,
VibeV oice technical report.arXiv preprint arXiv:2508.19205. Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2023. Effi- ciently scaling transformer inference. InProc. ML- Sys. Noam Shazeer. 2019. Fast transformer decoding: One write-head is all you need.arXiv prepr...
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yi- neng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. 2025. FlashInfer: Efficient and customiz- able attention engine for llm inference serving.arXiv preprint arXiv:2501.01005. Jiayi Yuan, Cameron S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.