Escape the Language Prior: Mitigating Late-Stage Modality Collapse in Audio Reasoning via Modality-Aware Policy Optimization
Pith reviewed 2026-06-29 17:42 UTC · model grok-4.3
The pith
Modality-Aware Policy Optimization concentrates RL gradients on audio-dependent tokens using differential entropy to block language-prior takeover in long reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
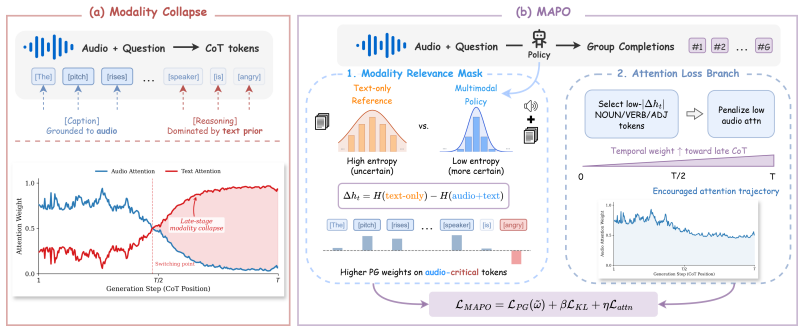
MAPO is a dual-branch reinforcement learning method that derives a modality relevance mask from cross-modal differential entropy between an audio-ablated reference and the multimodal policy to concentrate policy gradients on modality-critical tokens, while an auxiliary attention loss branch applies a targeted, temporally scaled penalty to sustain cross-modal attention and thereby reduce late-stage modality collapse.
What carries the argument
Modality relevance mask computed from cross-modal differential entropy between audio-ablated reference and multimodal policy, which selects tokens for concentrated policy gradients.
If this is right
- Long-horizon audio reasoning fidelity improves because gradients no longer reinforce text-only shortcuts.
- Multimodal instruction following strengthens as attention is actively kept on the non-text modality.
- State-of-the-art results appear on several key benchmarks among open-weight models.
- Confident but ungrounded hallucinations decrease in extended chain-of-thought traces.
Where Pith is reading between the lines
- The same entropy-difference mask could be tested on vision-language models to check whether modality collapse is prevented there as well.
- If the mask remains stable across different base models, it offers a domain-agnostic way to handle unequal modality dependence in any multimodal RL setup.
- Combining the mask with existing length penalties might further control when grounding is enforced.
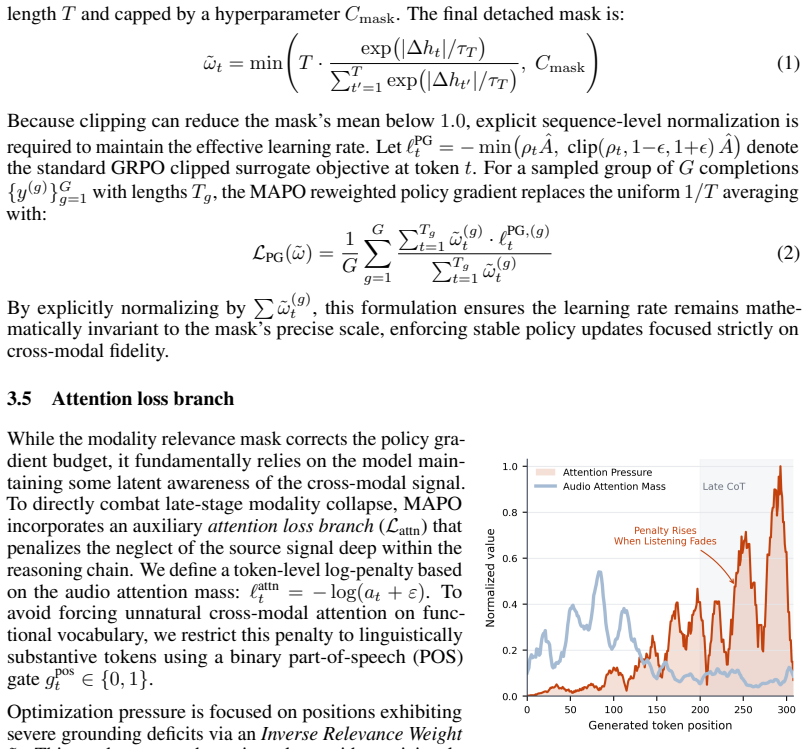
Load-bearing premise
The entropy-derived mask correctly flags tokens whose outputs depend on the audio input without injecting bias or training instability.
What would settle it
Ablation runs on the same audio reasoning benchmarks that remove either the relevance mask or the attention loss branch and measure whether the reported gains in long-horizon fidelity and reduction in hallucinations disappear.
Figures

read the original abstract
Audio and omni-modal large language models exhibit impressive cross-modal reasoning capabilities. However, applying standard reinforcement learning post-training algorithms to these models exposes a critical structural vulnerability: methods like GRPO apply uniform policy gradients across all tokens, ignoring their unequal dependence on the non-text source modality. This exacerbates late-stage modality collapse during extended chain-of-thought generation, where models progressively abandon the primary source signal in favor of compressed textual priors, leading to confident but ungrounded hallucinations. To address this, we introduce Modality-Aware Policy Optimization (MAPO), a novel dual-branch reinforcement learning framework. First, MAPO dynamically concentrates the policy gradient on modality-critical tokens using a modality relevance mask, which is derived from the cross-modal differential entropy between an audio-ablated reference and the multimodal policy. Second, it integrates an auxiliary attention loss branch that applies a targeted, temporally scaled penalty to the model's internal attention distributions. This ensures the model actively sustains cross-modal grounding deep into the reasoning trace. Evaluations on complex audio reasoning benchmarks demonstrate that MAPO substantially improves long-horizon reasoning fidelity and multimodal instruction following, achieving highly competitive performance and setting new state-of-the-art results on several key benchmarks among open-weight models. By relying strictly on native statistical signals rather than domain-specific inductive biases, MAPO offers a promising foundation for mitigating epistemic collapse across diverse multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Modality-Aware Policy Optimization (MAPO), a dual-branch RL post-training method for audio/omni-modal LLMs. It derives a modality relevance mask from cross-modal differential entropy between an audio-ablated reference policy and the multimodal policy to concentrate policy gradients on modality-critical tokens, and adds an auxiliary attention loss with temporal scaling to prevent late-stage modality collapse during long CoT. The abstract claims this yields substantial gains in long-horizon reasoning fidelity and sets new SOTA results on complex audio reasoning benchmarks among open-weight models, relying only on native statistical signals.
Significance. If the central mechanism is shown to work without introducing bias from reference-model distribution shift, the approach would be significant for multimodal RL by providing a targeted, bias-light way to sustain cross-modal grounding. The emphasis on native signals rather than hand-crafted inductive biases is a conceptual strength that could generalize beyond audio.
major comments (1)
- [Abstract / method (modality relevance mask derivation)] Abstract and method description: The modality relevance mask is defined via cross-modal differential entropy between the audio-ablated reference and the multimodal policy. This construction assumes the ablated reference differs from the multimodal policy only in its dependence on the audio signal. However, removing the audio encoder input typically induces large, non-local changes to hidden states and next-token distributions (especially over long CoT traces), so the entropy difference conflates modality dependence with general distribution mismatch. This directly undermines the claim that gradients are concentrated on modality-critical tokens rather than via incidental regularization.
Simulated Author's Rebuttal
We thank the referee for the detailed comment on the modality relevance mask. We respond point-by-point below.
read point-by-point responses
-
Referee: Abstract and method description: The modality relevance mask is defined via cross-modal differential entropy between the audio-ablated reference and the multimodal policy. This construction assumes the ablated reference differs from the multimodal policy only in its dependence on the audio signal. However, removing the audio encoder input typically induces large, non-local changes to hidden states and next-token distributions (especially over long CoT traces), so the entropy difference conflates modality dependence with general distribution mismatch. This directly undermines the claim that gradients are concentrated on modality-critical tokens rather than via incidental regularization.
Authors: We acknowledge that ablating the audio encoder input induces distribution shifts beyond isolated modality dependence, as hidden-state and token-distribution changes are non-local. The differential entropy is nevertheless computed between two policies that share identical parameters and training history, differing solely in audio-input availability; this supplies a native statistical proxy for modality impact rather than an exact isolation. Empirical gains on long-horizon audio-reasoning benchmarks indicate the resulting mask still concentrates gradients usefully on tokens whose probabilities are most affected by audio presence. We agree the assumption warrants explicit discussion and will revise the method section to state the approximation, note the potential conflation with general mismatch, and report any additional controls feasible in the revision. revision: yes
Circularity Check
No significant circularity; derivation uses independent native signals
full rationale
The provided abstract and description define MAPO via a modality relevance mask computed from cross-modal differential entropy (audio-ablated reference vs. multimodal policy) plus an auxiliary attention loss; these are direct constructions from model outputs rather than parameters fitted to target metrics or results that reduce to inputs by construction. No equations, self-citations, or uniqueness theorems are shown that would make any prediction equivalent to its inputs. The approach is presented as relying on native statistical signals, rendering the chain self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Charlie Nash, Antoine Caillon, Cheng- Zhi Anna Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, and et al. Musiclm: Generating music from text.arXiv preprint arXiv:2301.11325, 2023. doi: 10.48550/arXiv.2301.11325
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2301.11325 2023
-
[2]
Chang, Sungbok Lee, and Shrikanth S
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N. Chang, Sungbok Lee, and Shrikanth S. Narayanan. Iemocap: interactive emotional dyadic motion capture database.Language Resources and Evaluation, 42(4):335–359, Dec 2008. ISSN 1574-0218. doi: 10.1007/s10579-008-9076-6. URLhttps://doi.org/10.1007/s10579-008-9076-6
-
[3]
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled dataset for audio events. In2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 776–780, 2017. doi: 10.1109/icassp.2017.7952261
-
[4]
Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S. Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long-audio understand- ing and expert reasoning abilities.arXiv preprint arXiv:2503.03983, 2025. doi: 10.48550/arxiv.2503.03983
-
[5]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang gil Lee, Chao-Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models, 2025. URL https: //arxiv.org/abs/2507.08128
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Inseok Han, Jiyoung Park, and Kyogu Lee. Cochlscene: A multi-device dataset for acoustic scene classification.arXiv preprint arXiv:2111.08245, 2021. doi: 10.48550/arXiv.2111.08245
-
[7]
Xiang He, Chenxing Li, Jinting Wang, Yan Rong, Tianxin Xie, Wenfu Wang, Li Liu, and Dong Yu. Audio-deepthinker: Progressive reasoning-aware reinforcement learning for high-quality chain-of-thought emergence in audio language models, 2026. URLhttps://arxiv.org/abs/2604.18187
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token perception for multimodal reinforcement learning.arXiv preprint arXiv:2510.09285, 2025
-
[9]
Amazon nova 2: Multimodal reasoning and generation models.Amazon Technical Reports, 2025
Amazon Artificial General Intelligence. Amazon nova 2: Multimodal reasoning and generation models.Amazon Technical Reports, 2025. URL https://www.amazon.science/publications/ amazon-nova-2-multimodal-reasoning-and-generation-models
2025
-
[10]
Libritts-r: A restored multi-speaker text-to-speech corpus.arXiv preprint arXiv:2305.18802, 2023
Yuma Koizumi, Heiga Zen, Shigeki Karita, Yifan Ding, Kohei Yatabe, Nobuyuki Morioka, Michiel Bacchiani, Yu Zhang, Wei Han, and Ankur Bapna. Libritts-r: A restored multi-speaker text-to-speech corpus, 2023. URLhttps://arxiv.org/abs/2305.18802
-
[11]
Sonal Kumar, Šimon Sedláˇcek, Vaibhavi Lokegaonkar, Fernando López, Wenyi Yu, Nishit Anand, Hyeong- gon Ryu, Lichang Chen, Maxim Pliˇcka, Miroslav Hlaváˇcek, William Fineas Ellingwood, Sathvik Udupa, Siyuan Hou, Allison Ferner, Sara Barahona, Cecilia Bolaños, Satish Rahi, Laura Herrera-Alarcón, Satvik Dixit, Siddhi Patil, Soham Deshmukh, Lasha Koroshinadz...
-
[12]
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix, 2025
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, Kai Li, Keliang Li, Siyou Li, Xinfeng Li, Xiquan Li, Zheng Lian, Yuzhe Liang, Minghao Liu, Zhikang Niu, Tianrui Wang, Yuping Wang, Yuxuan Wang, Yihao Wu, Guanrou Yang, Jianwei Yu, Ruibin Yuan, Zhisheng Zheng, Ziya Zhou, Haina Zhu, Wei Xu...
-
[13]
OpenAI. Gpt-4o system card, 2024. URLhttps://arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Tacos: Temporally-aligned audio captions for language-audio pretraining, 2025
Paul Primus, Florian Schmid, and Gerhard Widmer. Tacos: Temporally-aligned audio captions for language-audio pretraining, 2025. URLhttps://arxiv.org/abs/2505.07609
-
[15]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2024. URL https://arxiv.org/abs/2305.18290. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Omni-R1: Do you really need audio to fine-tune your audio LLM?arXiv preprint arXiv:2505.09439, 2025
Andrew Rouditchenko, Saurabhchand Bhati, Edson Araujo, Samuel Thomas, Hilde Kuehne, Rogerio Feris, and James Glass. Omni-r1: Do you really need audio to fine-tune your audio llm?, 2025. URL https://arxiv.org/abs/2505.09439
-
[17]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark, 2024. URLhttps://arxiv.org/abs/2410.19168
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
-
[21]
URLhttps://arxiv.org/abs/2403.05530
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Mimo-audio: Audio language models are few-shot learners, 2025
MiMo Core Team. Mimo-audio: Audio language models are few-shot learners, 2025. URL https: //arxiv.org/abs/2512.23808
-
[24]
StepAudio Team. Step-audio 2 technical report, 2025. URLhttps://arxiv.org/abs/2507.16632
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Dingdong Wang, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark, 2026. URL https://arxiv.org/abs/2506.04779
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Covo-audio technical report, 2026
Wenfu Wang, Chenxing Li, Liqiang Zhang, Yiyang Zhao, Yuxiang Zou, Hanzhao Li, Mingyu Cui, Hao Zhang, Kun Wei, Le Xu, Zikang Huang, Jiajun Xu, Jiliang Hu, Xiang He, Zeyu Xie, Jiawen Kang, Youjun Chen, Meng Yu, Dong Yu, Rilin Chen, Linlin Di, Shulin Feng, Na Hu, Yang Liu, Bang Wang, and Shan Yang. Covo-audio technical report, 2026. URLhttps://arxiv.org/abs/...
-
[27]
Visually-Guided Policy Optimization for Multimodal Reasoning
Zengbin Wang, Feng Xiong, Liang Lin, Xuecai Hu, Yong Wang, Yanlin Wang, Man Zhang, and Xiangxiang Chu. Visually-guided policy optimization for multimodal reasoning.arXiv preprint arXiv:2604.09349, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Perception-Aware Policy Optimization for Multimodal Reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, and Heng Ji. Perception-aware policy optimization for multimodal reasoning, 2026. URLhttps://arxiv.org/abs/2507.06448
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URL https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Audio- Thinker: Guiding audio language model when and how to think via reinforcement learning
Shu Wu, Chenxing Li, Wenfu Wang, Hao Zhang, Hualei Wang, Meng Yu, and Dong Yu. Audio-thinker: Guiding audio language model when and how to think via reinforcement learning, 2025. URL https: //arxiv.org/abs/2508.08039
-
[31]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025. URLhttps://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Avqa: A dataset for audio-visual question answering on videos
Pinci Yang, Xin Wang, Xuguang Duan, Hong Chen, Runze Hou, Cong Jin, and Wenwu Zhu. Avqa: A dataset for audio-visual question answering on videos. InProceedings of the 30th ACM International Conference on Multimedia, pages 3480–3491, 2022
2022
-
[34]
specialized
Xu Zhongxing, Wang Zhonghua, Qian Zhe, Shi Dachuan, Tang Feilong, Hu Ming, Su Shiyan, Zou Xiaocheng, Feng Wei, Mahapatra Dwarikanath, Peng Yifan, Lin Mingquan, and Ge Zongyuan. Thinking in uncertainty: Mitigating hallucinations in mlrms with latent entropy-aware decoding. InProceedings of the Computer Vision and Pattern Recognition Conference, 2026. 11 A ...
2026
-
[35]
The conclusion reached in the thinking process does not agree with or contradicts the final answer
-
[36]
both speakers show sadness
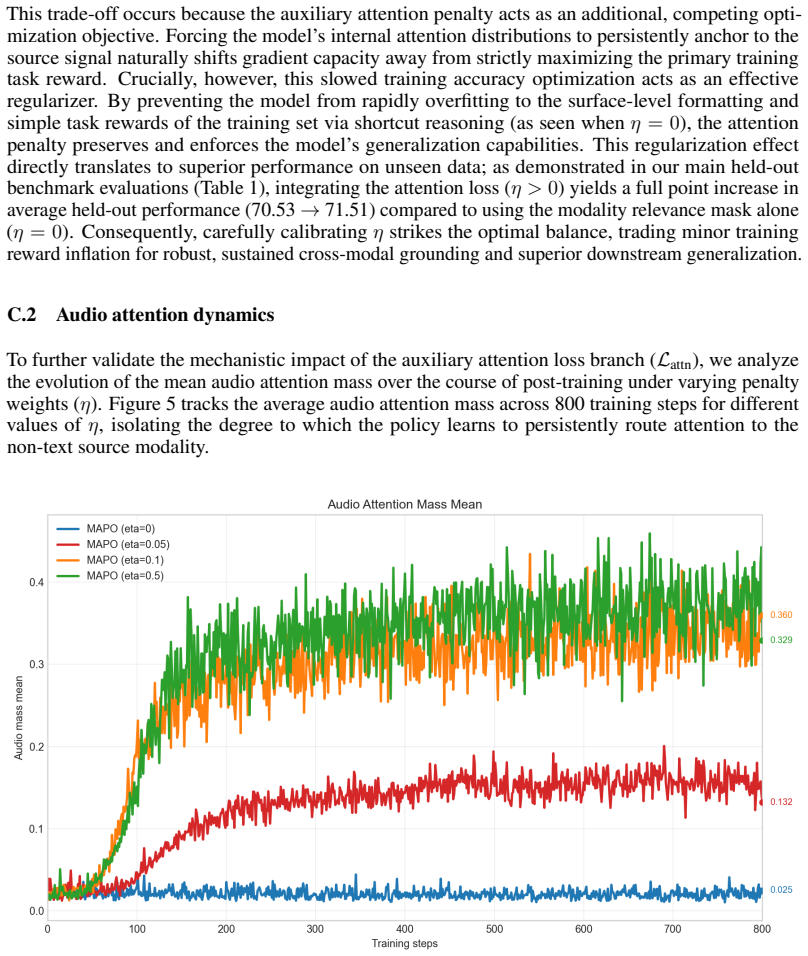
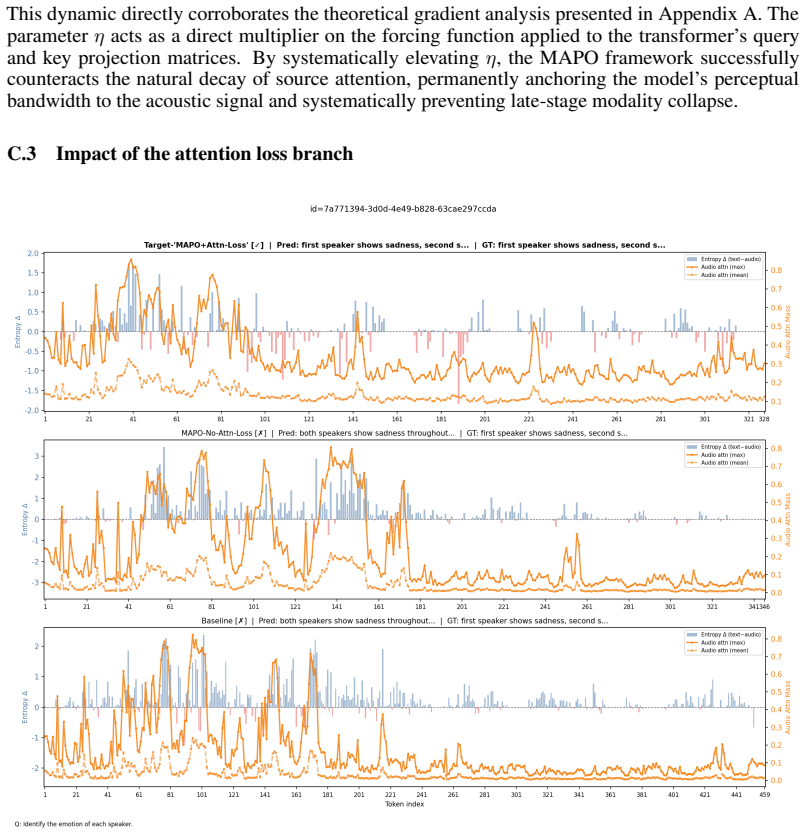
The thinking process is visibly incomplete or cut off prematurely. If neither of these failure modes is present, respond“YES”. Only output YES or NO. C Ablation analysis C.1 General training dynamics (a) Training Accuracy (b) Completion Length Figure 4: Training dynamics over 800 steps, comparing standard GRPO with MAPO across various attention loss weigh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.