Soft Specialists: α-R\'enyi Ensembles for Uncertainty-Aware LLM Post-Training
Pith reviewed 2026-06-29 15:11 UTC · model grok-4.3
The pith
An α-Rényi variational framework learns distributions over LLM post-training parameters to represent uncertainty from conflicting data as epistemic spread.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
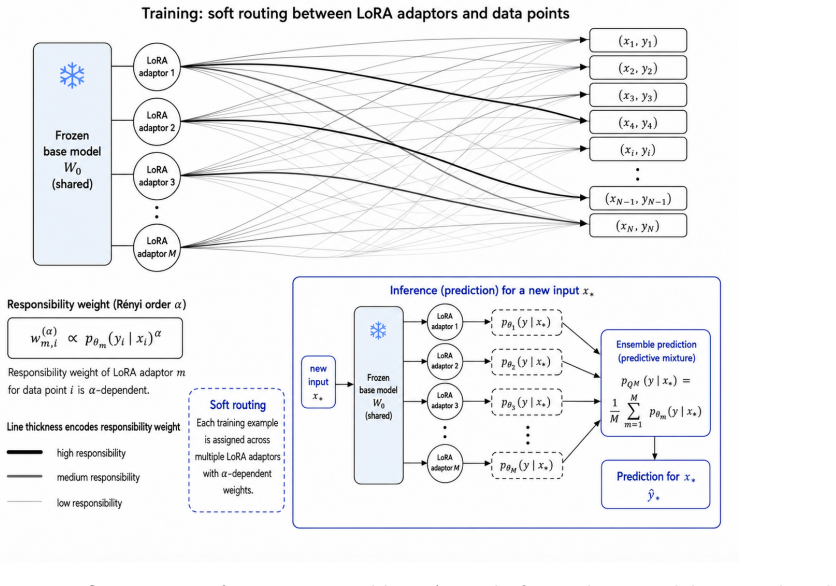
We propose an α-Rényi variational framework for learning distributions over post-training parameters, offering an uncertainty-aware alternative to deep ensemble approaches. The resulting variational objective interpolates between classical variational Bayes and predictively oriented posterior learning, balancing between globally plausible individual models against systems of complementary specialists. We identify local stability criteria, demonstrating how model misspecification can make non-degenerate posterior spread locally favourable, manifesting contradictory or conflicting data as epistemic uncertainty. We apply our framework to LLM post-training, learning an ensemble of LoRA adapters
What carries the argument
The α-Rényi variational objective, which interpolates between classical variational Bayes and predictively oriented posterior learning to balance individual model plausibility against complementary specialists.
If this is right
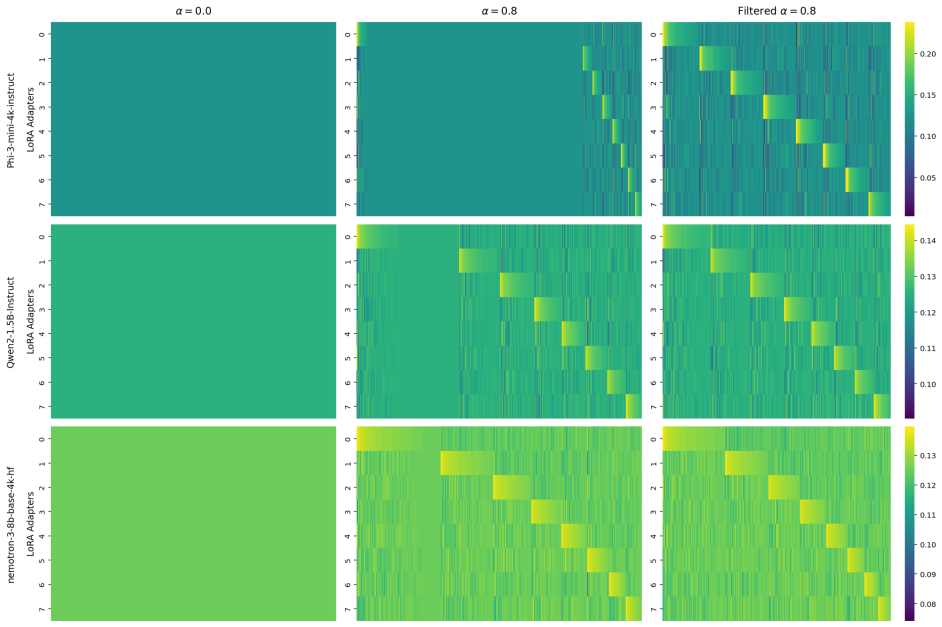
- Enables soft routing of training examples across ensemble members.
- Promotes model specialisation among the adapters.
- Provides actionable uncertainty estimates across different tasks.
- Offers a scalable procedure for both supervised fine-tuning and preference optimisation.
Where Pith is reading between the lines
- The soft routing mechanism could be used to diagnose which types of data trigger high uncertainty in practice.
- The framework might extend naturally to other parameter-efficient methods beyond LoRA for handling heterogeneous data.
- Uncertainty estimates from the ensemble could serve as a signal for active data collection on conflicting examples.
Load-bearing premise
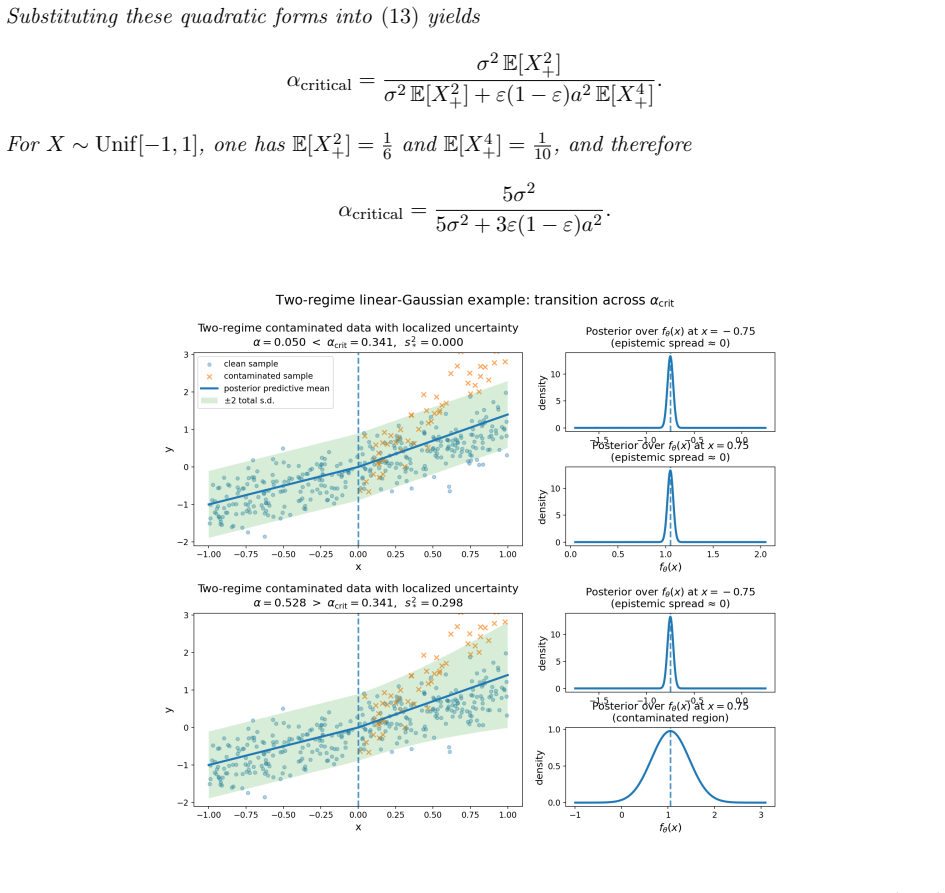
That local stability criteria demonstrate how model misspecification makes non-degenerate posterior spread locally favourable and manifests contradictory data as epistemic uncertainty in LLM post-training.
What would settle it
An experiment on a dataset with known conflicting labels where the α-Rényi ensemble fails to produce better uncertainty calibration or task performance than a single fine-tuned model or a standard deep ensemble.
Figures
read the original abstract
Existing training approaches for large language models learn a single set of parameters, based on large volumes of data, which is typically heterogeneous, conflicting and often outright contradictory. As a result, the model is forced to compress conflicting goals, and inherent uncertainties into a single, averaged pattern of behaviour. We propose an $\alpha$-R\'{e}nyi variational framework for learning distributions over post-training parameters, offering an uncertainty-aware alternative to deep ensemble approaches. The resulting variational objective interpolates between classical variational Bayes and predictively oriented posterior learning, balancing between globally plausible individual models against systems of complementary specialists. We identify local stability criteria, demonstrating how model misspecification can make non-degenerate posterior spread locally favourable, manifesting contradictory or conflicting data as epistemic uncertainty. We apply our framework to LLM post-training, learning an ensemble of LoRA adapters attached to a shared, frozen base model, providing a scalable training procedure for both supervised fine-tuning and preference optimisation. Our approach enables training examples to be softly routed across ensemble members, promoting model specialisation and providing actionable uncertainty estimates across different tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an α-Rényi variational framework for learning distributions over post-training parameters of LLMs. It applies this to ensembles of LoRA adapters on a frozen base model for both supervised fine-tuning and preference optimization, claiming the approach enables soft routing of examples, model specialization, and actionable uncertainty estimates. The framework is said to interpolate between variational Bayes and predictive posterior learning, with local stability criteria demonstrating that model misspecification favors non-degenerate posterior spread, turning conflicting data into epistemic uncertainty.
Significance. If the stability analysis and empirical validation hold, the work could supply a scalable, uncertainty-aware alternative to deep ensembles for LLM post-training, with explicit handling of data conflicts via specialization.
major comments (2)
- [Abstract] Abstract: the local stability criteria are asserted to show that misspecification makes non-degenerate posteriors locally favourable, yet no definition of the criteria, local expansion, or explicit conditions under which the non-degenerate solution is preferred are supplied; this leaves the claimed interpolation mechanism and its application to the LoRA-ensemble setting without demonstrated derivation.
- [Abstract] Abstract: the manuscript states that the framework is applied to LLM post-training with results for SFT and preference optimisation, but supplies neither the training procedure details, objective function, nor any empirical results or validation; without these the central claims on scalability and uncertainty estimates cannot be assessed.
minor comments (1)
- Notation for the α-Rényi objective and its relation to the variational parameters should be introduced with explicit equations rather than descriptive prose.
Simulated Author's Rebuttal
We thank the referee for their detailed feedback on the abstract. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the local stability criteria are asserted to show that misspecification makes non-degenerate posteriors locally favourable, yet no definition of the criteria, local expansion, or explicit conditions under which the non-degenerate solution is preferred are supplied; this leaves the claimed interpolation mechanism and its application to the LoRA-ensemble setting without demonstrated derivation.
Authors: We agree that the abstract does not contain the full derivation. The local stability criteria, including the local expansion around the degenerate solution and the explicit conditions favoring non-degenerate spread under misspecification, are derived in Section 3.2, where the interpolation between variational Bayes and predictive posterior learning is also shown. We will revise the abstract to include a concise reference to these criteria and their implications for the LoRA ensemble, and add a short summary paragraph in the introduction linking the stability analysis directly to the claimed specialization mechanism. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states that the framework is applied to LLM post-training with results for SFT and preference optimisation, but supplies neither the training procedure details, objective function, nor any empirical results or validation; without these the central claims on scalability and uncertainty estimates cannot be assessed.
Authors: We acknowledge that the current version emphasizes the theoretical framework and describes the application at a high level without sufficient procedural or empirical detail. We will add a dedicated methods subsection specifying the α-Rényi variational objective for both SFT and preference optimization, the exact training procedure for the ensemble of LoRA adapters on the frozen base model, and a new experimental section with results validating scalability and uncertainty estimates on the relevant tasks. revision: yes
Circularity Check
No circularity detectable from provided text
full rationale
The abstract asserts identification of local stability criteria and an interpolation between variational Bayes and predictive posterior learning, but supplies no equations, derivations, or self-citations. No load-bearing step reduces by construction to fitted inputs or prior self-citations, as no such material is visible. The derivation chain cannot be walked for reductions; the paper is treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aitchison
J. Aitchison. Goodness of prediction fit.Biometrika, 62(3):547–554, 1975
1975
-
[2]
A. N. Angelopoulos, S. Bates, E. J. Candès, M. I. Jordan, and L. Lei. Learn then test: Calibrating predictive algorithms to achieve risk control.The Annals of Applied Statistics, 19(2):1641–1662, 2025
2025
-
[3]
Anwar, A
U. Anwar, A. Saparov, J. Rando, D. Paleka, M. Turpin, P. Hase, E. S. Lubana, E. Jenner, S. Casper, O. Sourbut, B. L. Edelman, Z. Zhang, M. Günther, A. Korinek, J. Hernandez-Orallo, L. Hammond, E. J. Bigelow, A. Pan, L. Langosco, T. Korbak, H. C. Zhang, R. Zhong, S. O. hEigeartaigh, G. Recchia, G. Corsi, A. Chan, M. Anderljung, L. Edwards, A. Petrov, C. S....
2024
-
[4]
Arbel, K
J. Arbel, K. Pitas, M. Vladimirova, and V. Fortuin. A primer on Bayesian neural networks: review and debates.Statistical Science, 41(2):316–353, 2026
2026
-
[5]
Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Bakker, M
M. Bakker, M. Chadwick, H. Sheahan, M. Tessler, L. Campbell-Gillingham, J. Balaguer, N. McAleese, A. Glaese, J. Aslanides, M. Botvinick, and C. Summerfield. Fine-tuning language models to find agreement among humans with diverse preferences.Advances in neural information processing systems, 35:38176–38189, 2022
2022
-
[7]
A. Basu, I. R. Harris, N. L. Hjort, and M. C. Jones. Robust and efficient estimation by minimising a density power divergence.Biometrika, 85(3):549–559, 1998
1998
-
[8]
T. Bayes. An essay towards solving a problem in the doctrine of chances.Biometrika, 45(3-4):296–315, 1958
1958
-
[9]
R. A. Becker. The variance drain and Jensen’s inequality.CAEPR Working Paper, No. 2012-004, 2012
2012
-
[10]
Bhattacharya, D
A. Bhattacharya, D. Pati, and Y. Yang. Bayesian fractional posteriors.The Annals of Statistics, 47(1):39–66, 2019
2019
-
[11]
P. G. Bissiri, C. C. Holmes, and S. G. Walker. A general framework for updating belief distribu- tions.Journal of the Royal Statistical Society Series B: Statistical Methodology, 78(5):1103–1130, 2016. 25
2016
-
[12]
Blundell, J
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra. Weight uncertainty in neural networks. InInternational Conference on Machine Learning, pages 1613–1622. PMLR, 2015
2015
-
[13]
R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[14]
J. A. Carrillo, R. J. McCann, and C. Villani. Contractions in the 2-wasserstein length space and thermalization of granular media.Archive for Rational Mechanics and Analysis, 179(2):217–263, 2006
2006
-
[15]
Casper, X
S. Casper, X. Davies, C. Shi, T. K. Gilbert, J. Scheurer, J. Rando, R. Freedman, T. Korbak, D. Lindner, P. Freire, T. T. Wang, S. Marks, C.-R. Segerie, M. Carroll, A. Peng, P. J. Christoffersen, M. Damani, S. Slocum, U. Anwar, A. Siththaranjan, M. Nadeau, E. J. Michaud, J. Pfau, D. Krasheninnikov, X. Chen, L. Langosco, P. Hase, E. Biyik, A. Dragan, D. Kru...
2023
-
[16]
T. Chen, E. Fox, and C. Guestrin. Stochastic gradient hamiltonian Monte carlo. InInternational Conference on Machine Learning, pages 1683–1691. PMLR, 2014
2014
-
[17]
Z. Chen, T. Karvonen, H. Kanagawa, F.-X. Briol, and C. Oates. Stationary MMD Points for Cubature.arXiv preprint arXiv:2505.20754, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[19]
T. Cinquin, A. Immer, M. Horn, and V. Fortuin. Pathologies in priors and inference for bayesian transformers.arXiv preprint arXiv:2110.04020, 2021
-
[20]
Cui, W.-L
J. Cui, W.-L. Chiang, I. Stoica, and C.-J. Hsieh. Or-bench: An over-refusal benchmark for large language models. InInternational Conference on Machine Learning, pages 11515–11542. PMLR, 2025
2025
-
[21]
J. Dai, X. Pan, R. Sun, J. Ji, X. Xu, M. Liu, Y. Wang, and Y. Yang. Safe rlhf: Safe reinforcement learning from human feedback. InInternational Conference on Learning Representations, volume 2024, pages 50750–50777, 2024
2024
-
[22]
D’Angelo and V
F. D’Angelo and V. Fortuin. Repulsive deep ensembles are Bayesian.Advances in Neural Information Processing Systems, 34:3451–3465, 2021
2021
-
[23]
Daxberger, A
E. Daxberger, A. Kristiadi, A. Immer, R. Eschenhagen, M. Bauer, and P. Hennig. Laplace redux-effortless Bayesian deep learning.Advances in neural information processing systems, 34:20089–20103, 2021
2021
-
[24]
Z. Deng, F. Zhou, and J. Zhu. Accelerated linearized laplace approximation for bayesian deep learning.Advances in Neural Information Processing Systems, 35:2695–2708, 2022
2022
- [25]
-
[26]
B. G. Doan, A. Shamsi, X.-Y. Guo, A. Mohammadi, H. Alinejad-Rokny, D. Sejdinovic, D. Teney, D. C. Ranasinghe, and E. Abbasnejad. Bayesian low-rank learning (Bella): A practical approach to Bayesian neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39: 15, pages 16298–16307, 2025. 26
2025
-
[27]
M. D. Donsker and S. S. Varadhan. Asymptotic evaluation of certain markov process expecta- tions for large time—iii.Communications on pure and applied Mathematics, 29(4):389–461, 1976
1976
-
[28]
Duncan, N
A. Duncan, N. Nüsken, and L. Szpruch. On the geometry of Stein variational gradient descent. Journal of Machine Learning Research, 24(56):1–39, 2023
2023
-
[29]
Dusenberry, G
M. Dusenberry, G. Jerfel, Y. Wen, Y. Ma, J. Snoek, K. Heller, B. Lakshminarayanan, and D. Tran. Efficient and scalable Bayesian neural nets with rank-1 factors. InInternational Conference on Machine Learning, pages 2782–2792. PMLR, 2020
2020
-
[30]
X. Fan, S. Zhang, B. Chen, and M. Zhou. Bayesian attention modules.Advances in Neural Information Processing Systems, 33:16362–16376, 2020
2020
-
[31]
Föllmer and T
H. Föllmer and T. Knispel. Entropic risk measures: Coherence vs. convexity, model ambiguity and robust large deviations.Stochastics and Dynamics, 11(02n03):333–351, 2011
2011
- [32]
-
[33]
Fortuin, A
V. Fortuin, A. Garriga-Alonso, S. W. Ober, F. Wenzel, G. Ratsch, R. E. Turner, M. van der Wilk, and L. Aitchison. Bayesian neural network priors revisited. InInternational Conference on Learning Representations, 2022
2022
-
[34]
Gal and Z
Y. Gal and Z. Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. InInternational Conference on Machine Learning, pages 1050–
-
[35]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
D. Ganguli, L. Lovitt, J. Kernion, A. Askell, Y. Bai, S. Kadavath, B. Mann, E. Perez, N. Schiefer, K. Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Geifman and R
Y. Geifman and R. El-Yaniv. Selective classification for deep neural networks.Advances in neural information processing systems, 30, 2017
2017
-
[37]
Germain, A
P. Germain, A. Lacasse, F. Laviolette, M. March, and J.-F. Roy. Risk Bounds for the Majority Vote: From a PAC-Bayesian Analysis to a Learning Algorithm.Journal of Machine Learning Research, 16(26):787–860, 2015
2015
-
[38]
Gheshlaghi Azar, Z
M. Gheshlaghi Azar, Z. Daniel Guo, B. Piot, R. Munos, M. Rowland, M. Valko, and D. Calan- driello. A general theoretical paradigm to understand learning from human preferences. In S. Dasgupta, S. Mandt, and Y. Li, editors,Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 ofProceedings of Machine Learnin...
2024
-
[39]
Grünwald
P. Grünwald. The safe Bayesian: learning the learning rate via the mixability gap. In International Conference on Algorithmic Learning Theory, pages 169–183. Springer, 2012
2012
-
[40]
Grünwald and J
P. Grünwald and J. Langford. Suboptimal behavior of Bayes and MDL in classification under misspecification.Machine Learning, 66(2):119–149, 2007
2007
-
[41]
Grünwald and T
P. Grünwald and T. van Ommen. Inconsistency of Bayesian Inference for Misspecified Linear Models, and a Proposal for Repairing It.Bayesian Analysis, 12(4):1069 – 1103, 2017. 27
2017
-
[42]
Guilmeau, E
T. Guilmeau, E. Chouzenoux, and V. Elvira. Regularized Rényi divergence minimization through Bregman proximal gradient algorithms.Journal of Machine Learning Research, 26(157):1–56, 2025
2025
-
[43]
D. Guo, A. M. Rush, and Y. Kim. Parameter-efficient transfer learning with diff pruning. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: Long papers), pages 4884–4896, 2021
2021
-
[44]
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.Transactions on Machine Learning Research, 2024
2024
-
[45]
Harrison, J
J. Harrison, J. Willes, and J. Snoek. Variational Bayesian Last Layers. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[46]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Mea- suring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
2021
-
[47]
Hernandez-Lobato, Y
J. Hernandez-Lobato, Y. Li, M. Rowland, T. Bui, D. Hernández-Lobato, and R. Turner. Black-box alpha divergence minimization. InInternational Conference on Machine Learning, pages 1511–1520. PMLR, 2016
2016
-
[48]
Houlsby, A
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. At- tariyan, and S. Gelly. Parameter-efficient transfer learning for NLP. InInternational Conference on Machine Learning, pages 2790–2799. PMLR, 2019
2019
-
[49]
Bayesian Active Learning for Classification and Preference Learning
N. Houlsby, F. Huszár, Z. Ghahramani, and M. Lengyel. Bayesian active learning for classifica- tion and preference learning.arXiv preprint arXiv:1112.5745, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[50]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
2022
-
[51]
Z. Hu, L. Shen, Z. Wang, Y. Wei, and D. Tao. Adaptive defense against harmful fine-tuning for large language models via Bayesian data scheduler.Advances in Neural Information Processing Systems, 38:52131–52174, 2026
2026
-
[52]
Huber.Robust statistics
P. Huber.Robust statistics. Wiley New York, 1981
1981
-
[53]
J. Jia, X. Cao, and N. Z. Gong. Intrinsic certified robustness of bagging against data poisoning attacks.Proceedings of the AAAI Conference on Artificial Intelligence, 35(9):7961–7969, 2021
2021
-
[54]
Jiang and M
W. Jiang and M. A. Tanner. Gibbs posterior for variable selection in high-dimensional classification and data mining.The Annals of Statistics, 36(5):2207 – 2231, 2008
2008
-
[55]
Jiang, J
Z. Jiang, J. Araki, H. Ding, and G. Neubig. How can we know when language models know? on the calibration of language models for question answering.Transactions of the Association for Computational Linguistics, 9:962–977, 2021
2021
-
[56]
Kendall and Y
A. Kendall and Y. Gal. What uncertainties do we need in Bayesian deep learning for computer vision?Advances in neural information processing systems, 30, 2017
2017
-
[57]
D. P. Kingma, T. Salimans, and M. Welling. Variational dropout and the local reparameteri- zation trick.Advances in neural information processing systems, 28, 2015. 28
2015
-
[58]
Auto-Encoding Variational Bayes
D.P.KingmaandM.Welling. Auto-encodingvariationalBayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[59]
Knoblauch, J
J. Knoblauch, J. Jewson, and T. Damoulas. An Optimization-centric View on Bayes’ Rule: Reviewing and Generalizing Variational Inference.Journal of Machine Learning Research, 23:1–109, 2022
2022
-
[60]
Lacasse, F
A. Lacasse, F. Laviolette, M. Marchand, P. Germain, and N. Usunier. PAC-Bayes bounds for the risk of the majority vote and the variance of the Gibbs classifier.Advances in Neural information processing systems, 19, 2006
2006
-
[61]
Predictive variational inference: Learn the predictively optimal posterior distribution
J. Lai and Y. Yao. Predictive variational inference: Learn the predictively optimal posterior distribution.arXiv preprint arXiv:2410.14843, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
2017
-
[63]
Lawton, A
N. Lawton, A. Kumar, G. Thattai, A. Galstyan, and G. Ver Steeg. Neural architecture search for parameter-efficient fine-tuning of large pre-trained language models. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8506–8515, 2023
2023
-
[64]
Levine and S
A. Levine and S. Feizi. Deep partition aggregation: Provable defenses against general poisoning attacks. InInternational Conference on Learning Representations, 2021
2021
-
[65]
J. Li, W. Aitken, R. Bhambhoria, and X. Zhu. Prefix propagation: Parameter-efficient tuning for long sequences. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1408–1419, 2023
2023
-
[66]
T. Li, A. Beirami, M. Sanjabi, and V. Smith. Tilted Empirical Risk Minimization. In International Conference on Learning Representations, 2021
2021
-
[67]
X. L. Li and P. Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021
2021
-
[68]
Li and Y
Y. Li and Y. Gal. Dropout inference in Bayesian neural networks with alpha-divergences. In International Conference on Machine Learning, pages 2052–2061. PMLR, 2017
2052
-
[69]
Li and R
Y. Li and R. E. Turner. Rényi divergence variational inference.Advances in neural information processing systems, 29, 2016
2016
-
[70]
J. G. Liao and A. Berg. Sharpening Jensen’s inequality.The American Statistician, 2019
2019
-
[71]
Q. Liu, M. A. Fisher, Z. Shen, K. Tant, X. Zhao, A. Curtis, and C. J. Oates. Detecting Model Misspecification in Bayesian Inverse Problems via Variational Gradient Descent.arXiv preprint arXiv:2512.01667, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Liu and D
Q. Liu and D. Wang. Stein variational gradient descent: a general purpose bayesian inference algorithm. InProceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 2378–2386, Red Hook, NY, USA, 2016. Curran Associates Inc
2016
-
[73]
D. J. MacKay. A practical Bayesian framework for backpropagation networks.Neural computation, 4(3):448–472, 1992. 29
1992
-
[74]
W. J. Maddox, P. Izmailov, T. Garipov, D. P. Vetrov, and A. G. Wilson. A simple baseline for Bayesian uncertainty in deep learning.Advances in neural information processing systems, 32, 2019
2019
-
[75]
Martin and N
R. Martin and N. Syring. Direct Gibbs posterior inference on risk minimizers: Construction, concentration, and calibration. InHandbook of Statistics, volume 47, pages 1–41. Elsevier, 2022
2022
-
[76]
Masegosa
A. Masegosa. Learning under model misspecification: Applications to variational and ensemble methods.Advances in Neural Information Processing Systems, 33:5479–5491, 2020
2020
-
[77]
Y. McLatchie, B.-E. Cherief-Abdellatif, D. T. Frazier, and J. Knoblauch. Predictively oriented posteriors.arXiv preprint arXiv:2510.01915, 2025
- [78]
-
[79]
R. M. Neal.Bayesian learning for neural networks, volume 118. Springer Science & Business Media, 2012
2012
-
[80]
Ollivier, H
Y. Ollivier, H. Pajot, and C. Villani.Optimal transport: Theory and applications, volume 413. Cambridge University Press, 2014
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.