A Query Engine for the Agents
Pith reviewed 2026-06-29 13:21 UTC · model grok-4.3
The pith
A JavaScript query engine with per-cell async execution runs LLM user-defined functions on Parquet data far faster than DuckDB-WASM while staying small enough for browser and sandbox use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
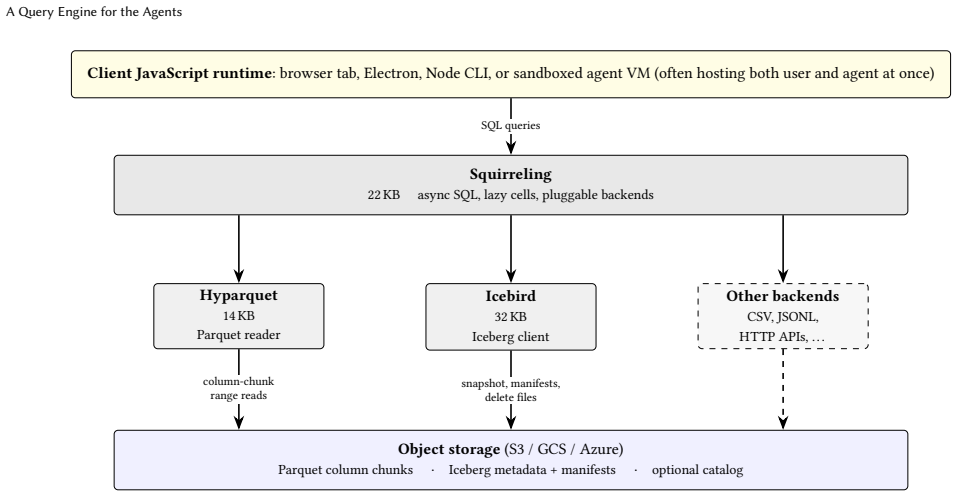
Hyperparam supplies a JS-native read path for Parquet and Iceberg together with per-cell async SQL execution so that model-based interpretation of unstructured text can be expressed as user-defined functions inside ordinary queries; the resulting engine ships under 70 KB and demonstrates order-of-magnitude gains in latency and cost on representative agent traces.
What carries the argument
per-cell, async-native SQL execution that evaluates expensive LLM cells only when downstream operators demand them
If this is right
- Client-side AI applications can now treat lakehouse files as first-class data sources without shipping heavy runtimes.
- Analytic queries on agent traces, chat logs, and reasoning chains can embed model calls directly in the query plan.
- Data engineering tooling must accommodate small, JS-only distributions that run inside per-turn sandboxes and cold browser tabs.
- Per-cell laziness becomes a practical way to control the cost of model invocations inside larger analytic pipelines.
Where Pith is reading between the lines
- The same per-cell pattern could be applied to other expensive external functions beyond LLMs, such as external API calls or on-device model inference.
- If the libraries prove stable under concurrent agent use, they could become a standard substrate for in-browser data analysis in tools that already host both users and agents.
Load-bearing premise
The reported speed and cost advantages hold on representative agent workloads and remain stable when LLM calls exhibit variable latency or when queries touch many cells.
What would settle it
Re-running the ten-task agent analyst suite on a fresh workload whose LLM calls have high and unpredictable latency, then comparing total wall-clock time and billed tokens against the DuckDB-WASM baseline.
Figures
read the original abstract
The fastest-growing data in production today is unstructured text: agent traces, chat logs, reasoning chains, model outputs. People want to analyze it, and the questions worth asking ("show me where the agent got confused") cannot be answered by SQL alone, since text is not queryable without a model in the query path. The natural place this analysis is happening is the new class of AI applications (Claude Code, Cursor, Claude Desktop, in-browser agents) that run client-side and host both a human user and an LLM agent in the same process. These applications increasingly want to work with data, but the lakehouse read path has been hard to use from a JS runtime: Spark, Trino, and managed warehouses do not fit there. To build this new kind of AI data application, three properties of the engine become first-order: a JS-native distribution that drops into the runtime the application already runs in, a bundle small enough to ship inside a cold tab or per-turn agent sandbox, and a way to interleave analytic operators with model-based interpretation of text. We present Hyperparam, three open-source JavaScript libraries (Hyparquet, Squirreling, Icebird) totaling under 70 KB, that read Parquet and Apache Iceberg directly from object storage and meet the third property with per-cell, async-native SQL execution, so expensive cells fire only when downstream operators demand them. Squirreling runs LLM-shaped async UDFs over 300x faster than DuckDB-WASM on filter-bounded queries (and 192x on sort-bounded queries) and completes a ten-task agent analyst suite at two-thirds lower cost. We argue that data engineering as a discipline needs to update for the AI-native client applications now in production and the agents that work alongside their users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Hyperparam, three open-source JavaScript libraries (Hyparquet, Squirreling, Icebird) totaling under 70 KB that read Parquet and Apache Iceberg directly from object storage in JS runtimes. It introduces per-cell, async-native SQL execution to support interleaving analytic operators with LLM-based UDFs on unstructured text (agent traces, chat logs), claiming that Squirreling executes LLM-shaped async UDFs 300x faster than DuckDB-WASM on filter-bounded queries (192x on sort-bounded) and completes a ten-task agent analyst suite at two-thirds lower cost. The work argues for updating data engineering for AI-native client applications.
Significance. If the reported speedups and cost reductions hold under representative workloads with variable LLM latency, the contribution would be significant for enabling lightweight, client-side data analysis in browser-based and agent-sandbox AI applications where traditional warehouses do not fit. The per-cell async model addresses a practical gap in JS-native query engines for text-heavy agent data.
major comments (2)
- [Abstract] Abstract: The concrete performance claims (300x on filter-bounded queries, 192x on sort-bounded queries, two-thirds lower cost for the ten-task suite) are presented without any description of the measurement protocol, dataset, query workloads, hardware, LLM model, latency distribution, or error bars. This is load-bearing for the central claim because the abstract states these factors as direct results rather than derivations.
- [Abstract] The per-cell async execution model is asserted to fire expensive LLM cells only on demand with negligible overhead, but no scaling data or synchronization-cost measurements are supplied for cases with high cell cardinality or heavy-tailed LLM latencies. If downstream operators force many cells, the reported factors would not hold.
minor comments (1)
- [Abstract] The abstract introduces three libraries but does not clarify their individual responsibilities or how they compose (e.g., which provides the async UDF execution).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and evaluation claims. We agree that additional context is needed to support the performance assertions and will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: The concrete performance claims (300x on filter-bounded queries, 192x on sort-bounded queries, two-thirds lower cost for the ten-task suite) are presented without any description of the measurement protocol, dataset, query workloads, hardware, LLM model, latency distribution, or error bars. This is load-bearing for the central claim because the abstract states these factors as direct results rather than derivations.
Authors: We agree the abstract would be strengthened by briefly indicating the evaluation setup. In the revision we will add one sentence to the abstract noting the datasets (synthetic agent traces plus real chat logs), workloads (filter- and sort-bounded queries plus the ten-task suite), environment (browser on commodity client hardware), model (Claude 3.5 Sonnet), and that figures report means over five runs. Full protocol, latency distributions, and error bars remain in Section 5. revision: yes
-
Referee: [Abstract] The per-cell async execution model is asserted to fire expensive LLM cells only on demand with negligible overhead, but no scaling data or synchronization-cost measurements are supplied for cases with high cell cardinality or heavy-tailed LLM latencies. If downstream operators force many cells, the reported factors would not hold.
Authors: The design intentionally evaluates a cell only when a downstream operator demands its value; this is the core of the per-cell async model and is why the reported speedups appear on the filter- and sort-bounded workloads. We acknowledge that explicit scaling curves for high-cardinality tables or heavy-tailed LLM latencies are not yet presented. We will add a short scaling subsection (new Figure 8) that measures synchronization overhead and end-to-end time as cell cardinality and LLM latency variance increase, confirming the overhead remains sub-linear under the workloads typical of agent traces. revision: yes
Circularity Check
No circularity: performance claims are direct measurements, not derivations
full rationale
The paper introduces three JavaScript libraries and reports measured speedups (300x on filter-bounded queries, 192x on sort-bounded) versus DuckDB-WASM, attributing them to a per-cell async execution model. No equations, fitted parameters, predictions derived from prior fits, or self-citations appear in the provided text. The central claims rest on empirical benchmarks rather than any derivation chain that reduces to its own inputs by construction. This is the expected non-finding for an engineering/systems paper whose results are externally falsifiable via reproduction of the reported timings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abadi, Daniel S
Daniel J. Abadi, Daniel S. Myers, David J. DeWitt, and Samuel R. Madden. 2007. Materialization Strategies in a Column-Oriented DBMS. InICDE
2007
-
[2]
Hearst, and Randy Katz
Sara Alspaugh, Beidi Chen, Jessica Lin, Archana Ganapathi, Marti A. Hearst, and Randy Katz. 2014. Analyzing Log Analysis: An Empirical Study of User Log Mining. InLISA. USENIX Association
2014
-
[3]
Apache Arrow. 2024. Apache Arrow JavaScript Library (arrow-js). https: //arrow.apache.org/docs/js/
2024
-
[4]
Apache Iceberg. 2024. Apache Iceberg Table Spec v2. https://iceberg.apache. org/spec/
2024
-
[5]
Xin, and Matei Zaharia
Michael Armbrust, Ali Ghodsi, Reynold S. Xin, and Matei Zaharia. 2021. Lake- house: A New Generation of Open Platforms That Unify Data Warehousing and Advanced Analytics. InCIDR
2021
- [6]
- [7]
-
[8]
Shilin He, Pinjia He, Zhuangbin Chen, Tianyi Yang, Yuxin Su, and Michael R. Lyu. 2021. A Survey on Automated Log Analysis for Reliability Engineering. Comput. Surveys54, 6, Article 130 (2021). doi:10.1145/3460345
-
[9]
Rogers Jeffrey Leo John, Dylan Bacon, Junda Chen, Ushmal Ramesh, Jiatong Li, Deepan Das, Robert Claus, Amos Kendall, and Jignesh M. Patel. 2023. DataChat: An Intuitive and Collaborative Data Analytics Platform. InSIGMOD Companion. doi:10.1145/3555041.3589678
-
[10]
André Kohn, Dominik Moritz, Mark Raasveldt, Hannes Mühleisen, and Thomas Neumann. 2022. DuckDB-Wasm: Fast Analytical Processing for the Web.Pro- ceedings of the VLDB Endowment15, 12 (2022)
2022
-
[11]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Bailis Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. 2025. Palimpzest: Optimizing AI-Powered Analytics with Declarative Query Processing. InCIDR
2025
-
[12]
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, and Aditya G. Parameswaran. 2025. Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First.arXiv:2509.00997(2025)
-
[13]
Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shiv- akumar, Matt Tolton, and Theo Vassilakis. 2010. Dremel: Interactive Analysis of Web-Scale Datasets.Proceedings of the VLDB Endowment3, 1 (2010)
2010
-
[14]
Dominik Moritz and Jeffrey Heer. 2020. Arquero: Query Processing and Trans- formation of Array-Backed Data Tables. Observable. https://observablehq.com/ @uwdata/arquero
2020
-
[15]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS. Proceedings of the VLDB Endowment(2025). doi:10.14778/3749646.3749685
-
[16]
Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: an Embeddable Analytical Database. InSIGMOD
2019
-
[17]
Zamfirescu-Pereira, Björn Hartmann, Aditya G
Shreya Shankar, J.D. Zamfirescu-Pereira, Björn Hartmann, Aditya G. Parameswaran, and Ian Arawjo. 2024. Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences. InUIST
2024
- [18]
-
[19]
The Deep View. 2026. AI’s compute crisis has reached a breaking point. https://www.thedeepview.com/articles/ai-s-compute-crisis-has-reached- a-breaking-point Accessed 2026
2026
-
[20]
Deepak Vohra. 2016. Apache Parquet. InPractical Hadoop Ecosystem. Apress
2016
-
[21]
Matei Zaharia, Omar Khattab, Lingjiao Chen, Jared Quincy Davis, Heather Miller, Chris Potts, James Zou, Michael Carbin, Jonathan Frankle, Naveen Rao, and Ali Ghodsi. 2024. The Shift from Models to Compound AI Systems. BAIR Blog. https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.