CuriosAI Submission to the CASTLE Challenge at EgoVis 2026
Pith reviewed 2026-06-29 14:11 UTC · model grok-4.3
The pith
Search-Verify-Answer pipeline scores 0.50 accuracy on the CASTLE 2026 egocentric video challenge
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Search-Verify-Answer pipeline, which hierarchically narrows to a primary window, verifies sub-windows with a VLM under four anti-confabulation rules, and fuses evidence with an LLM judge under an evidence-priority hierarchy, reaches a leaderboard accuracy of 0.50 on the CASTLE 2026 challenge and is the final submission; the Temporal-Multimodal-Knowledge-Graph alternative reaches 0.35.
What carries the argument
The three-stage Search-Verify-Answer pipeline that narrows search space, applies anti-confabulation verification, and fuses evidence via priority hierarchy
If this is right
- SVA outperforms the knowledge-graph baseline by 0.15 accuracy points on the leaderboard.
- The hierarchical narrowing plus verification steps enable processing of 600+ hours of multi-view video within a multiple-choice QA setting.
- The evidence-priority hierarchy produces the final answer after verification rather than direct generation.
- SVA is selected over TMKG as the challenge submission due to the measured accuracy difference.
Where Pith is reading between the lines
- The same staged verification structure might transfer to other long-video QA tasks outside this specific challenge.
- The anti-confabulation rules could be tested independently on different video lengths or camera setups to measure their isolated effect.
- Replacing the LLM judge with a different fusion method might reveal whether the accuracy gain comes mainly from the rules or from the priority ordering.
Load-bearing premise
The four anti-confabulation rules and evidence-priority hierarchy in the LLM judge will reliably prevent hallucinated answers on the hidden test distribution.
What would settle it
Accuracy falling below 0.40 on the hidden test set, or explicit cases where the rules allow hallucinated answers, would show the reliability claim does not hold.
Figures
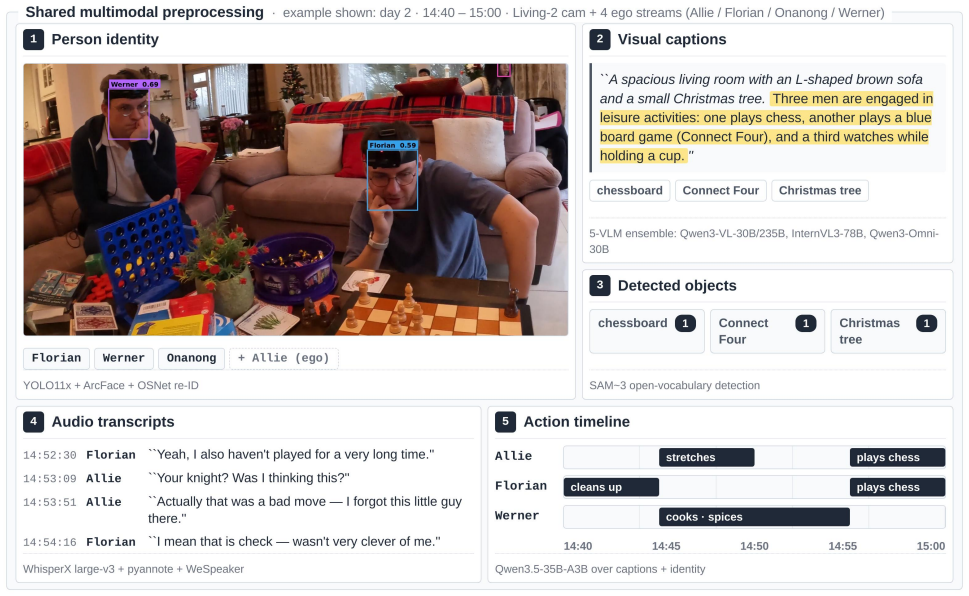
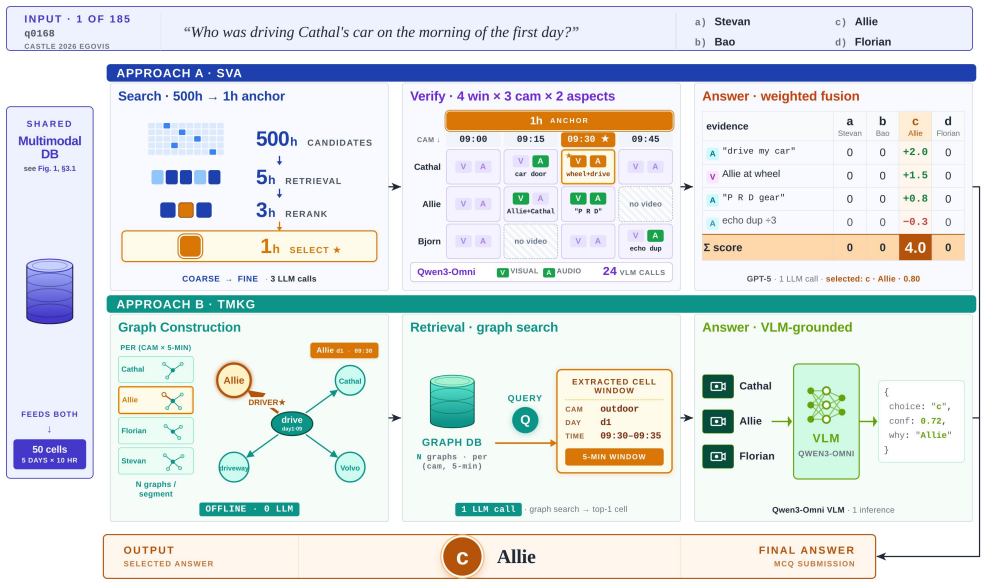
read the original abstract
CASTLE 2026 asks 185 multiple-choice questions over 600+ hours of synchronized multi-view egocentric video. We explore two approaches on top of a shared multimodal preprocessing layer, including per-person timelines, speaker-resolved transcripts, and multi-VLM caption ensembles. Approach A, SVA: Search-Verify-Answer, is a three-stage pipeline that hierarchically narrows to a primary window, verifies sub-windows with a VLM under four anti-confabulation rules, and fuses evidence with an LLM judge under an evidence-priority hierarchy. Approach B, TMKG: Temporal-Multimodal-Knowledge-Graph, is the contrast: it builds a temporal multimodal knowledge graph, locates a primary cell via graph search, and produces the final answer with a single grounded VLM. SVA reaches a leaderboard accuracy of 0.50 and is our final challenge submission; TMKG reaches 0.35.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes CuriosAI's submission to the CASTLE 2026 challenge, which poses 185 multiple-choice questions over 600+ hours of synchronized multi-view egocentric video. It introduces a shared multimodal preprocessing layer (per-person timelines, speaker-resolved transcripts, multi-VLM caption ensembles) and contrasts two approaches: Approach A (SVA: Search-Verify-Answer), a three-stage pipeline that narrows to a primary window, verifies sub-windows with a VLM under four anti-confabulation rules, and fuses evidence via an LLM judge with an evidence-priority hierarchy; and Approach B (TMKG: Temporal-Multimodal-Knowledge-Graph), which constructs a temporal multimodal knowledge graph, locates a primary cell via graph search, and answers with a single grounded VLM. SVA achieves 0.50 leaderboard accuracy and is the final submission; TMKG achieves 0.35.
Significance. If the reported leaderboard accuracy holds, the work supplies a concrete empirical data point showing that a hierarchical search-verify pipeline can outperform a knowledge-graph baseline on long-form egocentric video QA. The explicit reference to anti-confabulation rules and evidence-priority hierarchy supplies a replicable methodological template for mitigating confabulation in VLM-based video systems.
major comments (1)
- [Abstract] Abstract: the central performance claim (SVA leaderboard accuracy of 0.50) is presented without error bars, ablation results, or any description of how the 185 questions were sampled or how the hidden test set was constructed, rendering the claim unverifiable from the manuscript text alone.
minor comments (1)
- [Approach A description] Approach A description: the four anti-confabulation rules and the evidence-priority hierarchy are invoked but not enumerated or illustrated with examples; explicit listing would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript describing the CuriosAI submission to the CASTLE 2026 challenge. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (SVA leaderboard accuracy of 0.50) is presented without error bars, ablation results, or any description of how the 185 questions were sampled or how the hidden test set was constructed, rendering the claim unverifiable from the manuscript text alone.
Authors: We agree that the abstract would benefit from additional context to improve verifiability. The 185 questions are those supplied by the CASTLE challenge organizers, and the hidden test set is constructed and held by the organizers without disclosure of sampling details to participants. We will revise the abstract to state explicitly that the 0.50 figure is the official leaderboard accuracy on the challenge-provided questions and to note the direct comparison with the TMKG baseline (0.35) described in the body of the paper. However, as this manuscript reports results from a single challenge submission rather than a multi-run experimental study, error bars from repeated trials and comprehensive ablation studies are not available and fall outside the scope of this report. revision: partial
- Specific details on how the hidden test set was constructed or how the 185 questions were sampled, as this information is not disclosed by the challenge organizers.
Circularity Check
No significant circularity
full rationale
The manuscript is an empirical system report describing two challenge submissions (SVA and TMKG) and their leaderboard accuracies (0.50 and 0.35). No equations, parameter fits, or derivations appear in the text; the central claim is a direct factual report of platform-observed accuracy rather than a generalization or prediction derived from internal quantities. Methodological details such as anti-confabulation rules and evidence hierarchies are design choices, not self-referential steps that reduce to the reported scores by construction. No self-citation load-bearing or uniqueness claims are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Whisperx: Time-accurate speech transcription of long-form audio
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. Whisperx: Time-accurate speech transcription of long-form audio. InProceedings of INTERSPEECH, 2023. 2
2023
-
[3]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Reciprocal rank fusion outperforms Condorcet and individual rank learning methods
Gordon V Cormack, Charles L A Clarke, and Stefan Büttcher. Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. InProceedings of the 32nd Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval, pages 758–759, 2009. 3 3 Figure 2. Walk-through of both pipelines on a sample question (q0168), re...
2009
-
[6]
Arcface: Additive angular margin loss for deep face recogni- tion
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recogni- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 4690– 4699, 2019. 1
2019
-
[7]
Gpt-5 system card, 2025
OpenAI. Gpt-5 system card, 2025. 2
2025
-
[8]
Powerset multi-class cross entropy loss for neural speaker diarization
Alexis Plaquet and Hervé Bredin. Powerset multi-class cross entropy loss for neural speaker diarization. InProceedings of INTERSPEECH, 2023. 2
2023
-
[9]
Qwen3.5: Towards native multimodal agents,
Qwen Team. Qwen3.5: Towards native multimodal agents,
-
[10]
Robust speech recog- nition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recog- nition via large-scale weak supervision. InProceedings of the International Conference on Machine Learning (ICML),
-
[11]
The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009
Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009. 2
2009
-
[12]
The castle 2024 dataset: Advancing the art of multimodal understanding
Luca Rossetto, Werner Bailer, Duc-Tien Dang-Nguyen, Gra- ham Healy, Björn Þór Jónsson, Onanong Kongmeesub, Hoang-Bao Le, Stevan Rudinac, Klaus Schöffmann, Florian Spiess, et al. The castle 2024 dataset: Advancing the art of multimodal understanding. InProceedings of the 33rd ACM International Conference on Multimedia, pages 12629–12635,
2024
-
[13]
Wespeaker: A research and production oriented speaker embedding learning toolkit
Hongji Wang, Chengdong Liang, Shuai Wang, Zhengyang Chen, Binbin Zhang, Xu Xiang, Yanlei Deng, and Yanmin Qian. Wespeaker: A research and production oriented speaker embedding learning toolkit. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023. 2
2023
-
[14]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Lin- jun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Omni-scale feature learning for person re-identification
Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, and Tao Xi- ang. Omni-scale feature learning for person re-identification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 1
2019
-
[17]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 2 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.