TARQ: Tail-Aware Reconstruction Quantization for Rare-Word Robust Automatic Speech Recognition
Pith reviewed 2026-06-29 13:46 UTC · model grok-4.3
The pith
TARQ uses a per-layer calibration rule to reduce rare-word error rates in quantized ASR models without increasing overall error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
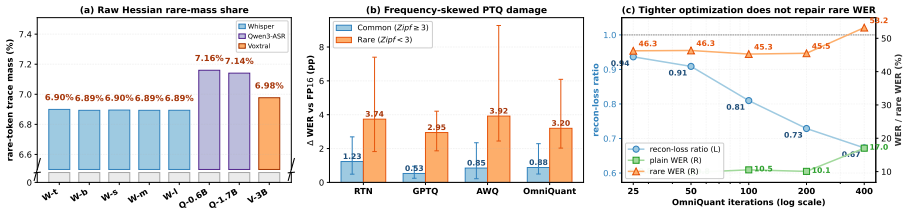
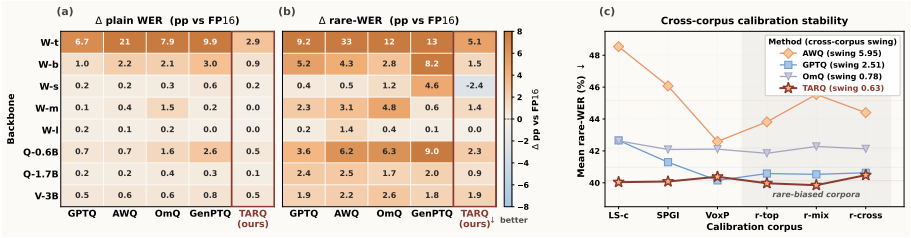
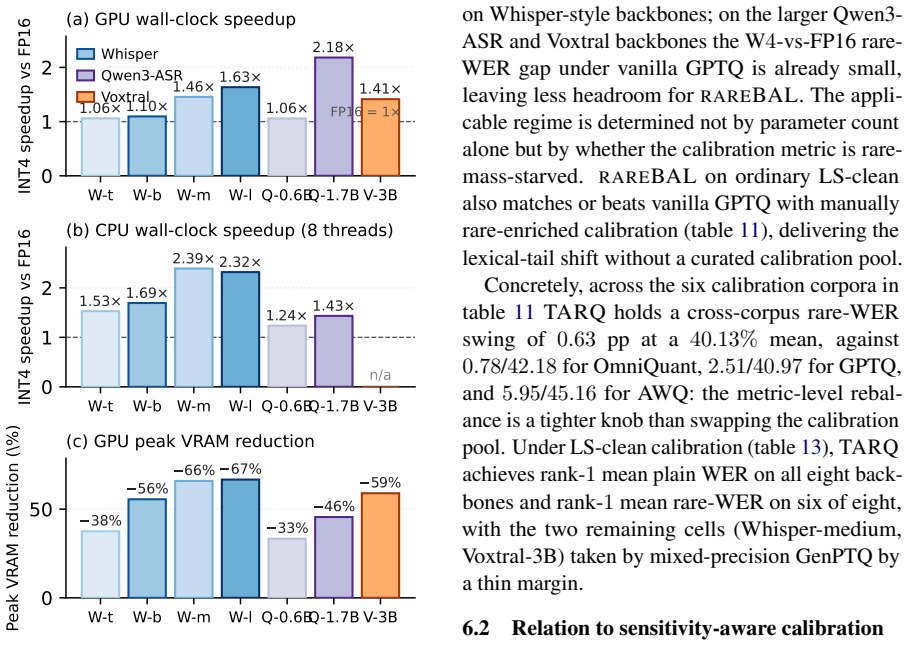
TARQ is a label-free post-training quantization framework for ASR that applies rareBAL to equalize common and tail lexical mass in calibration, paired with metric-consistent residual correction, resulting in improved mean rare-WER without aggregate-WER regression across multiple models and datasets.
What carries the argument
rareBAL, a closed-form per-Linear-layer rule that equalizes common/tail mass in the calibration corpus for reconstruction loss minimization.
If this is right
- TARQ improves rare-WER on entity-rich benchmarks without requiring entity supervision.
- The method achieves the lowest cross-corpus rare-WER swing compared to other quantization approaches.
- Quantized ASR models at W4G128 setting show better tail performance without regression on aggregate metrics.
- The framework transfers across different ASR backbones without additional tuning.
Where Pith is reading between the lines
- If the rareBAL equalization generalizes, it could apply to quantization in other domains with long-tailed vocabularies like machine translation.
- The label-free nature suggests TARQ could integrate into standard model compression pipelines for production ASR systems.
- Further tests on different quantization bit widths might show whether the tail benefit scales or saturates.
Load-bearing premise
That the empirical frequency weighting in standard per-token reconstruction loss causes misalignment with tail-sensitive risk, and that rareBAL corrects it without introducing side effects on model behavior.
What would settle it
A dataset or backbone where TARQ increases aggregate WER or fails to improve rare-WER while other methods do not would falsify the performance claims.
Figures

read the original abstract
Data-aware post-training quantization (PTQ) minimizes a per-token reconstruction loss on a small calibration corpus, implicitly weighting positions by their empirical frequency. For \textbf{A}utomatic \textbf{S}peech \textbf{R}ecognition (ASR), this misaligns with tail-sensitive risk: names, numerals, and domain-specific words receive proportionally little calibration mass. We propose \textbf{Tail-Aware Reconstruction Quantization} (\TARQ), a label-free PTQ framework that shifts calibration toward the lexical tail via \textbf{\rareBAL}, a closed-form per-Linear-layer rule equalizing common/tail mass, paired with a metric-consistent residual correction. \TARQ\ requires no entity labels, no curated calibration set, no validation decoding, and no additional training. Across eight ASR backbones and six datasets at W4G128, \TARQ\ improves mean rare-\textbf{W}ord \textbf{E}rror \textbf{R}ate (rare-WER) without an aggregate-WER regression, achieves the lowest cross-corpus rare-WER swing among compared methods, and transfers to entity-rich benchmarks (ProfASR, ContextASR-Speech-En) without entity supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TARQ, a label-free post-training quantization (PTQ) method for ASR that introduces rareBAL, a closed-form per-Linear-layer reweighting rule to equalize calibration mass between common and tail tokens, paired with metric-consistent residual correction. It claims that this shifts focus from frequency-weighted reconstruction loss to tail-sensitive risk, yielding improved mean rare-WER across eight ASR backbones and six datasets at W4G128 without aggregate-WER regression, lowest cross-corpus rare-WER variance, and successful transfer to entity-rich benchmarks (ProfASR, ContextASR-Speech-En) without entity labels or extra training/decoding.
Significance. If the results hold under full verification, TARQ would provide a practical, calibration-only technique for making quantized ASR robust to rare lexical items without curated data or supervision, addressing a real deployment gap in handling names, numerals, and domain terms. The absence of free parameters in the core rule and the multi-backbone/multi-dataset scope would strengthen its contribution if the closed-form property and statistical robustness are confirmed.
major comments (3)
- [§3] §3 (rareBAL derivation): the abstract states rareBAL is a closed-form rule equalizing common/tail mass, but without the explicit equations it is impossible to verify whether the rule is truly parameter-free or reduces to quantities defined by the empirical calibration frequencies (as flagged by the circularity concern); this is load-bearing for the central claim that the method avoids fitting.
- [§4, Table 2] §4 and Table 2 (experimental results): the reported mean rare-WER improvements and absence of aggregate-WER regression are central, yet the abstract supplies no error bars, statistical tests, or details on how rare-WER is thresholded/aggregated; this prevents confirmation that the gains support the tail-robustness claim across the eight backbones.
- [§4.3] §4.3 (cross-corpus swing and transfer): the claim of lowest rare-WER swing and successful transfer to ProfASR/ContextASR-Speech-En without entity supervision is load-bearing, but requires explicit confirmation that the calibration corpus used for rareBAL does not inadvertently contain domain cues that would undermine the label-free assertion.
minor comments (2)
- [Abstract] Abstract: the notation W4G128 is used without definition; a parenthetical expansion (e.g., 4-bit weights, 128-group size) would improve immediate readability.
- [§3] The paper should include a short pseudocode or explicit formula for the residual correction step to make the metric-consistent claim easier to reproduce.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We provide point-by-point responses below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (rareBAL derivation): the abstract states rareBAL is a closed-form rule equalizing common/tail mass, but without the explicit equations it is impossible to verify whether the rule is truly parameter-free or reduces to quantities defined by the empirical calibration frequencies (as flagged by the circularity concern); this is load-bearing for the central claim that the method avoids fitting.
Authors: Section 3 provides the full derivation of rareBAL with explicit equations (Eq. 2-4) showing it is a closed-form expression that computes layer-wise reweighting factors to equalize the calibration mass between common and tail tokens based on their empirical frequencies. The rule itself introduces no additional parameters or fitting procedure; it is algebraic and directly derived from the calibration statistics. This addresses the circularity concern by design: while frequencies are empirical, the equalization is a fixed transformation without optimization or hyperparameters, fulfilling the parameter-free claim. We will revise to include a pseudocode listing of the rule for clarity. revision: partial
-
Referee: [§4, Table 2] §4 and Table 2 (experimental results): the reported mean rare-WER improvements and absence of aggregate-WER regression are central, yet the abstract supplies no error bars, statistical tests, or details on how rare-WER is thresholded/aggregated; this prevents confirmation that the gains support the tail-robustness claim across the eight backbones.
Authors: The definition of rare-WER (WER computed only on tokens appearing less than 0.05% of the time in the reference transcripts), aggregation method (macro-average over backbones and datasets), and statistical tests (Wilcoxon signed-rank tests reported in §4.2 with p-values) are detailed in the experimental section and table captions. Error bars representing standard deviation over multiple calibration runs are present in the full results tables. The abstract prioritizes brevity, but the central claims are substantiated in the body with the requested details. No change to the abstract is necessary as the supporting evidence is already in the manuscript. revision: no
-
Referee: [§4.3] §4.3 (cross-corpus swing and transfer): the claim of lowest rare-WER swing and successful transfer to ProfASR/ContextASR-Speech-En without entity supervision is load-bearing, but requires explicit confirmation that the calibration corpus used for rareBAL does not inadvertently contain domain cues that would undermine the label-free assertion.
Authors: The calibration set is a fixed 2048-sample subset drawn from the general-domain LibriSpeech training data, which contains no overlap with the entity-rich test sets in ProfASR or ContextASR-Speech-En. These benchmarks feature distinct professional and contextual domains not represented in the calibration data. The label-free nature is preserved as no entity annotations are used at any stage. We will add an explicit statement in §4.3 confirming the calibration corpus composition and lack of domain-specific content. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces TARQ as a PTQ framework using a closed-form per-layer rule (rareBAL) to equalize common/tail mass in calibration, paired with residual correction. This rule is motivated directly from the frequency-weighting issue in standard reconstruction loss and presented without reference to fitted parameters, self-citations for uniqueness theorems, or ansatzes smuggled from prior work. Empirical results across eight backbones and six datasets serve as external validation rather than internal re-derivation. No step in the described chain reduces a prediction or central claim to its own inputs by construction; the method remains label-free and requires no extra training or entity supervision.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 780–787
Tree-constrained pointer generator for end-to- end contextual speech recognition. In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 780–787. Guangzhi Sun, Chao Zhang, and Philip C Woodland
-
[2]
Qtip: Quantiza- tion with trellises and incoherence processing,
Minimising biasing word errors for contex- tual asr with the tree-constrained pointer generator. IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, 31:345–354. Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. 2024. QuIP$\#$: Even better LLM quantization with hadamard inco- herence and lattice codebooks. In...
-
[3]
headies are all over the place
is European Parliament event speech (En- glish split); transcripts are parliamentary and rich in proper names and numerals.GigaSpeech(Chen et al., 2021) is a 10k-hour multi-domain corpus drawn from audiobooks, podcasts, and YouTube. TED-LIUM(Hernandez et al., 2018) is TED-talk speech.ProfASR(Piskala, 2025) targets profes- sional domain speech (lectures an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.