LRanker: LLM Ranker for Massive Candidates
Pith reviewed 2026-06-29 10:28 UTC · model grok-4.3
The pith
LRanker enables LLMs to rank millions of candidates by clustering them for global structure and ensembling multiple query embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
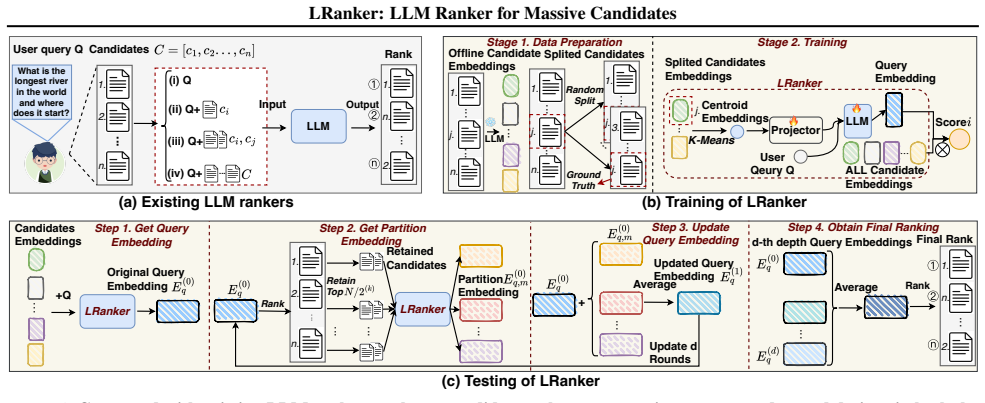
LRanker incorporates a candidate aggregation encoder that leverages K-means clustering to explicitly model global candidate information, and a graph-based test-time scaling mechanism that partitions candidates into subsets, generates multiple query embeddings, and integrates them through an ensemble procedure, producing more accurate ranking over massive candidate pools.
What carries the argument
Graph-based test-time scaling mechanism that partitions candidates, generates multiple query embeddings, and integrates results via ensemble, paired with K-means candidate aggregation.
If this is right
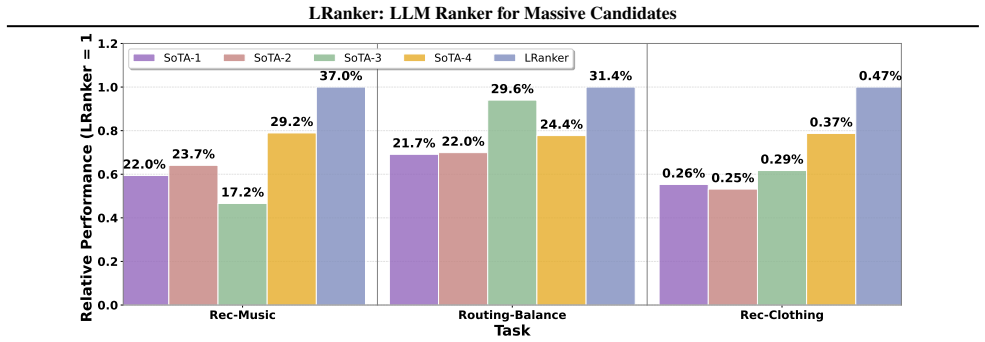
- Ranking accuracy rises by more than 30 percent when candidate pools are small.
- MRR improves between 3 and 9 percent on large-scale tasks.
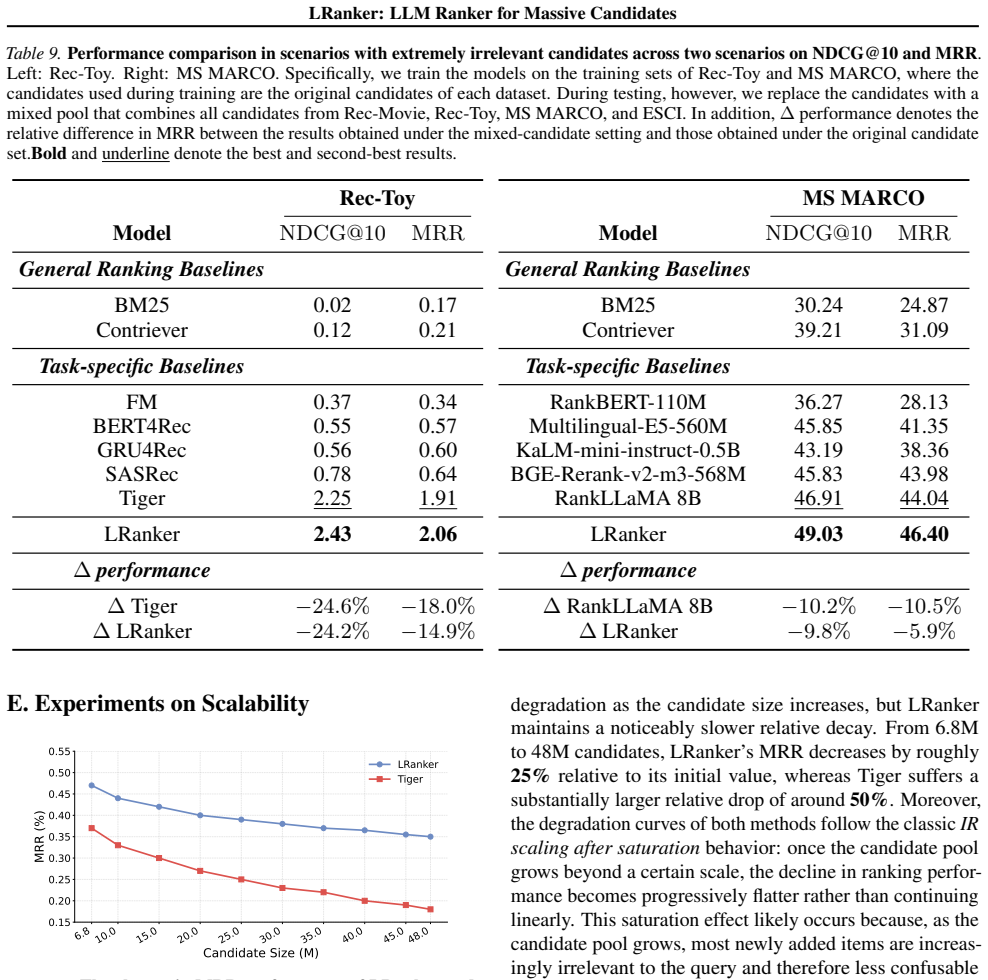
- Performance gains of 20 to 30 percent hold even when more than 6.8 million candidates are present.
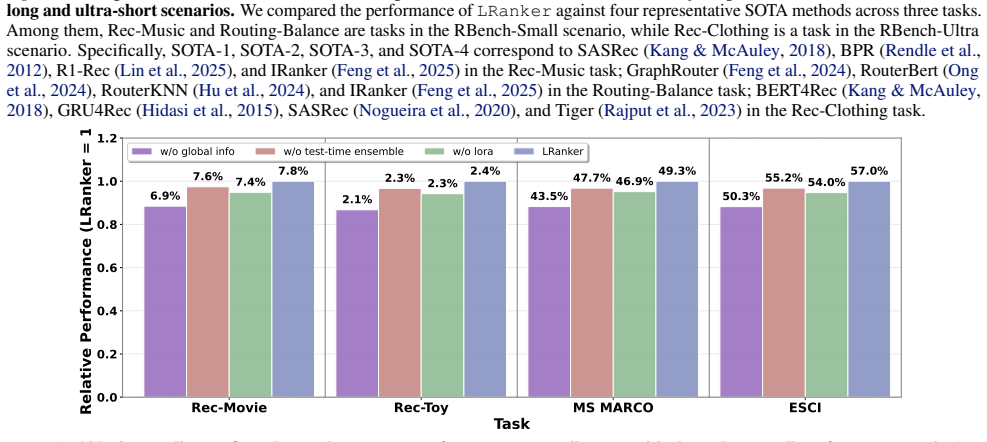
- Ablation checks confirm that both the clustering step and the ensemble step contribute to the observed gains.
Where Pith is reading between the lines
- The same partitioning-plus-ensemble idea could be tested on other selection tasks that require an LLM to choose from a large set, such as retrieval-augmented generation.
- Production systems might combine this method with approximate nearest-neighbor indexes to further cut latency.
- Repeating the experiments on streaming or time-varying candidate pools would show whether periodic re-clustering is necessary.
Load-bearing premise
That K-means clustering captures global candidate information and that partitioning plus ensembling multiple embeddings will improve ranking without losing relevant candidates or introducing systematic bias.
What would settle it
A side-by-side comparison on a dataset with known relevant items showing whether the clustered-and-ensembled method recovers the same top-ranked items as exhaustive single-embedding search.
Figures

read the original abstract
Large language models (LLMs) have recently shown strong potential for ranking by capturing semantic relevance and adapting across diverse domains, yet existing methods remain constrained by limited context length and high computational costs, restricting their applicability to real-world scenarios where candidate pools often scale to millions. To address this challenge, we propose LRanker, a framework tailored for large-candidate ranking. LRanker incorporates a candidate aggregation encoder that leverages K-means clustering to explicitly model global candidate information, and a graph-based test-time scaling mechanism that partitions candidates into subsets, generates multiple query embeddings, and integrates them through an ensemble procedure. By aggregating diverse embeddings instead of relying on a single representation, this mechanism enhances robustness and expressiveness, leading to more accurate ranking over massive candidate pools. We evaluate LRanker on seven tasks across three scenarios in RBench with different candidate scales. Experimental results show that LRanker achieves over 30% gains in the RBench-Small scenario, improves by 3-9% in MRR in the RBench-Large scenario, and sustains scalability with 20-30% improvements in the RBench-Ultra scenario with more than 6.8M candidates. Ablation studies further verify the effectiveness of its key components. Together, these findings demonstrate the robustness, scalability, and effectiveness of LRanker for massive-candidate ranking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LRanker, an LLM-based ranking framework for massive candidate pools that combines a candidate aggregation encoder (K-means clustering on candidate embeddings to capture global information) with a graph-based test-time scaling mechanism (partitioning candidates into subsets, generating multiple query embeddings, and ensemble integration). It evaluates on seven tasks across RBench-Small, RBench-Large, and RBench-Ultra scenarios (the latter with >6.8M candidates), reporting >30% gains on Small, 3-9% MRR improvement on Large, and 20-30% gains on Ultra, with ablations claimed to verify component effectiveness.
Significance. If the reported gains prove robust under full experimental scrutiny, the work would address a practical bottleneck in LLM ranking—context length and cost at million-scale candidate sets—potentially enabling broader deployment in real-world IR systems; the empirical focus on scalability across three distinct RBench regimes is a strength, though the absence of coverage guarantees limits immediate impact assessment.
major comments (3)
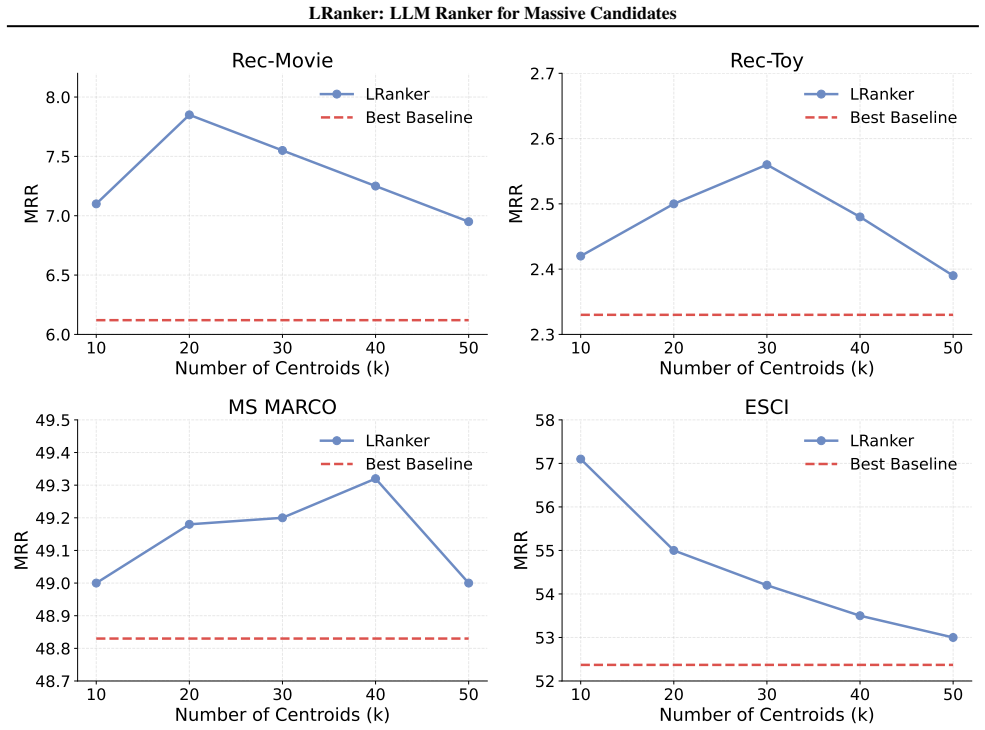
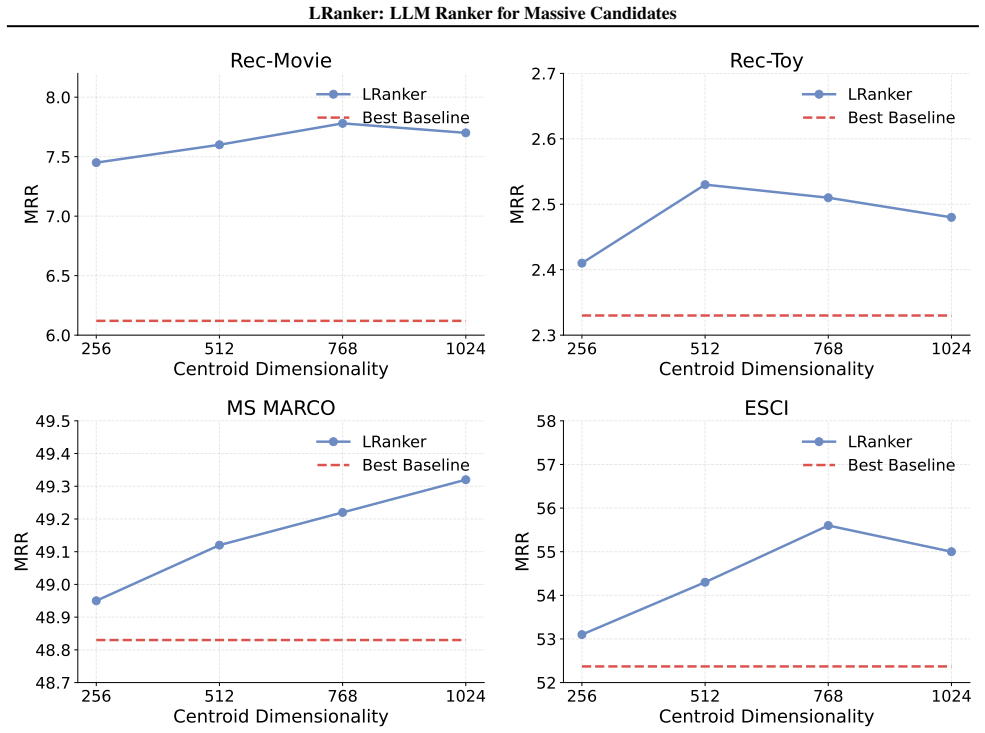
- [Experimental results and ablation studies] The scalability claims for RBench-Ultra (>6.8M candidates, 20-30% gains) rest on the partitioning-plus-ensemble procedure preserving relevant candidates, yet the manuscript provides no recall@full-set metrics, coverage analysis, or explicit guarantees that K-means clusters and subset processing do not systematically drop relevant items before ensemble integration (see the description of the graph-based test-time scaling mechanism and the RBench-Ultra results).
- [Candidate aggregation encoder description] K-means clustering is performed unsupervised solely on candidate embeddings to model 'global candidate information,' but no analysis is given of how cluster boundaries align with query-specific relevance or whether this introduces bias; this assumption is load-bearing for the candidate aggregation encoder's contribution to the headline gains.
- [Evaluation on RBench scenarios] The abstract and results sections state that ablations verify component effectiveness, but supply no statistical tests, error bars, baseline descriptions, or full experimental protocol details sufficient to confirm that the 3-9% MRR and 30%+ gains are not attributable to unstated choices in partitioning or embedding generation.
minor comments (3)
- [Method overview] Notation for the ensemble integration step could be clarified with a pseudocode listing or explicit equation showing how multiple query embeddings are combined across subsets.
- [Experimental setup] The RBench task descriptions would benefit from a table summarizing candidate counts, query types, and evaluation metrics per scenario to aid reproducibility.
- [Related work] A few citations to prior work on clustering-based retrieval or test-time scaling in IR appear missing in the related work section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental rigor and component analysis. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experimental results and ablation studies] The scalability claims for RBench-Ultra (>6.8M candidates, 20-30% gains) rest on the partitioning-plus-ensemble procedure preserving relevant candidates, yet the manuscript provides no recall@full-set metrics, coverage analysis, or explicit guarantees that K-means clusters and subset processing do not systematically drop relevant items before ensemble integration (see the description of the graph-based test-time scaling mechanism and the RBench-Ultra results).
Authors: We acknowledge that the current manuscript lacks explicit recall@full-set metrics, coverage analysis, or quantitative guarantees regarding preservation of relevant candidates under partitioning. The graph-based test-time scaling is designed to enhance coverage via multiple query embeddings and ensemble integration across subsets, but we agree this requires empirical validation. In the revised version, we will add recall metrics computed against the full candidate set and a dedicated coverage analysis section for the RBench-Ultra experiments. revision: yes
-
Referee: [Candidate aggregation encoder description] K-means clustering is performed unsupervised solely on candidate embeddings to model 'global candidate information,' but no analysis is given of how cluster boundaries align with query-specific relevance or whether this introduces bias; this assumption is load-bearing for the candidate aggregation encoder's contribution to the headline gains.
Authors: The unsupervised K-means on candidate embeddings is intentionally query-independent to capture the global distribution of the candidate pool, complementing the query-specific components. Ablation results in the manuscript indicate its contribution to performance, but we agree that analysis of cluster-query alignment and potential bias is absent. We will add a discussion of this design choice, including any observed biases or alignment considerations, in the revised manuscript. revision: partial
-
Referee: [Evaluation on RBench scenarios] The abstract and results sections state that ablations verify component effectiveness, but supply no statistical tests, error bars, baseline descriptions, or full experimental protocol details sufficient to confirm that the 3-9% MRR and 30%+ gains are not attributable to unstated choices in partitioning or embedding generation.
Authors: The reported gains follow the experimental protocol described in the paper, with ablations isolating component contributions. However, we recognize the need for additional statistical support. The revised manuscript will include error bars from repeated runs, statistical significance tests, expanded baseline details, and a fuller experimental protocol appendix to enable independent verification. revision: yes
Circularity Check
No circularity; empirical framework with no derivation chain
full rationale
The paper describes an empirical method (K-means candidate aggregation encoder plus graph-based test-time scaling with subset partitioning and ensemble) evaluated on RBench tasks across scales. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. Performance claims rest on experimental results rather than any reduction of outputs to inputs by construction, satisfying the self-contained benchmark criterion for a score of 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption K-means clustering explicitly models global candidate information when used as a candidate aggregation encoder
- domain assumption Partitioning candidates and ensembling multiple query embeddings improves robustness and expressiveness for ranking
Reference graph
Works this paper leans on
-
[1]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Bajaj, P., Campos, D., Craswell, N., Deng, L., Gao, J., Liu, X., Majumder, R., McNamara, A., Mitra, B., Nguyen, T., et al. Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, Y ., Liu, Q., Zhang, Y ., Sun, W., Ma, X., Yang, W., Shi, D., Mao, J., and Yin, D. Tourrank: Utilizing large lan- guage models for documents ranking with a tournament- inspired strategy. InProceedings of the ACM on Web Conference 2025, pp. 1638–1652, 2025a. Chen, Y ., Zhang, M., Wu, Y ., and Liu, Y . Rank-r1: Enhanc- ing reasoning in llm-based docum...
-
[3]
GraphRouter: A Graph-based Router for LLM Selections, 2025
Feng, T., Shen, Y ., and You, J. Graphrouter: A graph-based router for llm selections.arXiv preprint arXiv:2410.03834,
-
[4]
Iranker: Towards ranking foundation model
Feng, T., Hua, Z., Lei, Z., Xie, Y ., Yang, S., Long, B., and You, J. Iranker: Towards ranking foundation model. arXiv preprint arXiv:2506.21638,
-
[5]
Session-based Recommendations with Recurrent Neural Networks
Hidasi, B., Karatzoglou, A., Baltrunas, L., and Tikk, D. Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Hou, Y ., Li, J., He, Z., Yan, A., Chen, X., and McAuley, J. Bridging language and items for retrieval and recommen- dation.arXiv preprint arXiv:2403.03952, 2024a. Hou, Y ., Zhang, J., Lin, Z., Lu, H., Xie, R., McAuley, J., and Zhao, W. X. Large language models are zero-shot rankers for recommender systems. InEuropean Conference on Information Retrieval, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-031-56060-6 2024
- [7]
-
[8]
Kalm-embedding: Superior training data brings a stronger embedding model
Hu, X., Shan, Z., Zhao, X., Sun, Z., Liu, Z., Li, D., Ye, S., Wei, X., Chen, Q., Hu, B., et al. Kalm-embedding: Superior training data brings a stronger embedding model. arXiv preprint arXiv:2501.01028,
-
[9]
Unsupervised Dense Information Retrieval with Contrastive Learning
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., and Grave, E. Unsupervised dense infor- mation retrieval with contrastive learning.arXiv preprint arXiv:2112.09118,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
9 LRanker: LLM Ranker for Massive Candidates Li, J., Zhang, W., Wang, T., Xiong, G., Lu, A., and Medioni, G. Gpt4rec: A generative framework for personalized recommendation and user interests interpretation.arXiv preprint arXiv:2304.03879, 2023a. Li, L., Zhang, Y ., and Chen, L. Prompt distillation for efficient llm-based recommendation. InProceedings of ...
-
[12]
Liu, Q., Wu, X., Wang, W., et al. Llmemb: Large language model can be a good embedding generator for sequen- tial recommendation.arXiv preprint arXiv:2409.19925, 2024a. Liu, T.-Y . et al. Learning to rank for information retrieval. Foundations and Trends® in Information Retrieval, 3(3): 225–331,
-
[13]
Liu, W., Ma, X., Zhu, Y ., Zhao, Z., Wang, S., Yin, D., and Dou, Z. Sliding windows are not the end: Exploring full ranking with long-context large language models.arXiv preprint arXiv:2412.14574, 2024b. Ma, X., Wang, L., Yang, N., Wei, F., and Lin, J. Fine-tuning llama for multi-stage text retrieval. InProceedings of the 47th International ACM SIGIR Conf...
-
[14]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects
Ni, J., Li, J., and McAuley, J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 conference on empirical meth- ods in natural language processing and the 9th interna- tional joint conference on natural language processing (EMNLP-IJCNLP), pp. 188–197,
2019
-
[15]
and Cho, K
Nogueira, R. and Cho, K. Passage re-ranking with bert. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL),
2019
-
[16]
URL https://arxiv. org/abs/1901.04085. Nogueira, R., Jiang, Z., and Lin, J. Document ranking with a pretrained sequence-to-sequence model.arXiv preprint arXiv:2003.06713,
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[17]
Pradeep, R., Sharifymoghaddam, S., and Lin, J. Rankvicuna: Zero-shot listwise document reranking with open-source large language models.arXiv preprint arXiv:2309.15088,
-
[18]
Qin, Z., Jagerman, R., Hui, K., Zhuang, H., Wu, J., Yan, L., Shen, J., Liu, T., Liu, J., Metzler, D., et al. Large language models are effective text rankers with pairwise ranking prompting.arXiv preprint arXiv:2306.17563,
-
[19]
Rashid, M. S., Meem, J. A., Dong, Y ., and Hristidis, V . Eco- rank: Budget-constrained text re-ranking using large lan- guage models.arXiv preprint arXiv:2402.10866,
-
[20]
Yiming Tang, Yi Fan, Chenxiao Yu, Tiankai Yang, Yue Zhao, and Xiyang Hu
Reddy, C. K., M`arquez, L., Valero, F., Rao, N., Zaragoza, H., Bandyopadhyay, S., Biswas, A., Xing, A., and Sub- bian, K. Shopping queries dataset: A large-scale esci benchmark for improving product search.arXiv preprint arXiv:2206.06588,
-
[21]
BPR: Bayesian Personalized Ranking from Implicit Feedback
Rendle, S., Freudenthaler, C., Gantner, Z., and Schmidt- Thieme, L. Bpr: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Sun, W., Yan, L., Ma, X., Wang, S., Ren, P., Chen, Z., Yin, D., and Ren, Z. Is chatgpt good at search? investigat- ing large language models as re-ranking agents.arXiv preprint arXiv:2304.09542,
-
[23]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Wang, L., Yang, N., Huang, X., Jiao, B., Yang, L., Jiang, D., Majumder, R., and Wei, F. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Listt5: List- wise reranking with fusion-in-decoder.arXiv preprint arXiv:2402.15838,
Yoon, J., Jeong, M., Kim, C., and Seo, M. Listt5: List- wise reranking with fusion-in-decoder.arXiv preprint arXiv:2402.15838,
-
[25]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Zhang, Y ., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., et al. Qwen3 embed- ding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
To further improve efficiency and stability, we en- able BF16 training, gradient checkpointing, and gradient clipping (norm = 0.5)
LoRA is applied to both attention and feed-forward layers with rank = 32, α= 64 , and dropout = 0.1. To further improve efficiency and stability, we en- able BF16 training, gradient checkpointing, and gradient clipping (norm = 0.5). For evaluation, we determine the best graph depth and width using the validation set, and fix these configurations when test...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.