EgoBench: An Interactive Egocentric Multimodal Benchmark for Tool-Using Agents
Pith reviewed 2026-06-29 13:07 UTC · model grok-4.3
The pith
EgoBench reveals that current video-MLLM agents reach only 19.43 percent average accuracy on tasks requiring simultaneous visual perception, tool-augmented reasoning, and user interaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
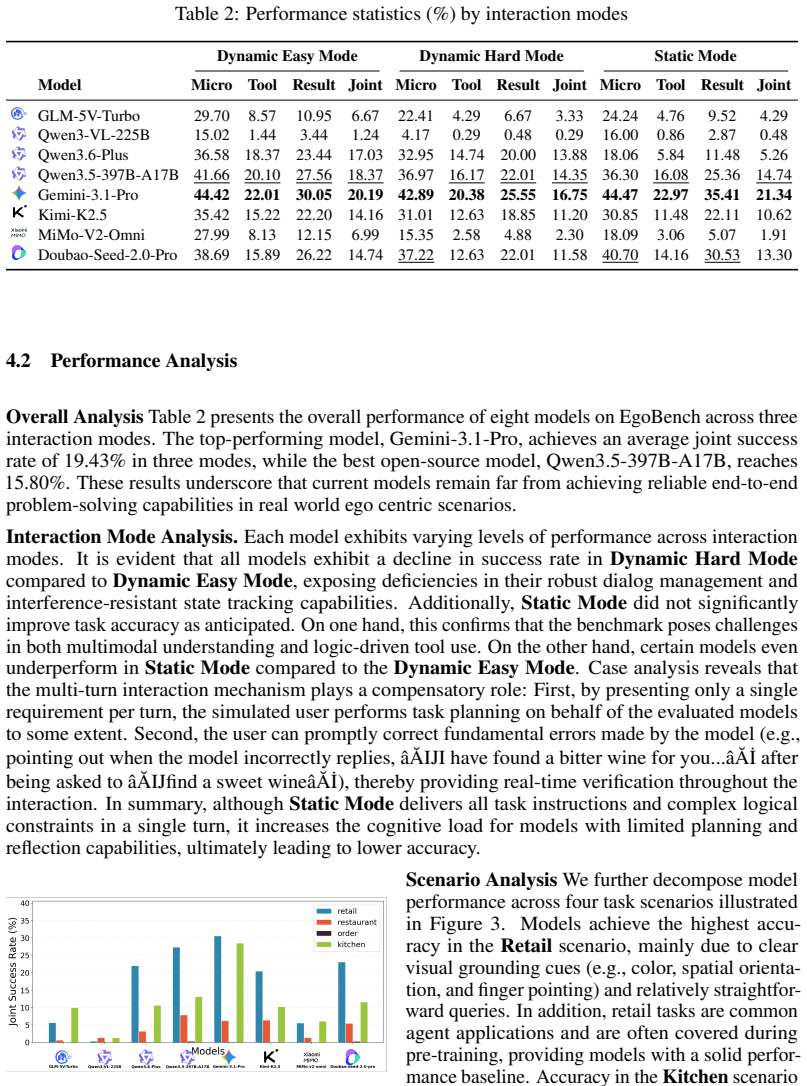
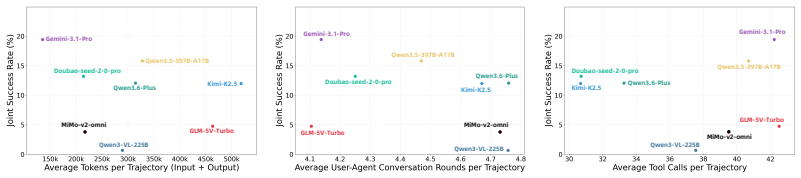
EgoBench is the first interactive multimodal benchmark whose tasks are constructed so that visual perception, tool-augmented multi-hop reasoning, and dynamic user interaction must be applied jointly; benchmarking shows that eight state-of-the-art video-MLLM agents achieve at most 30.62 percent accuracy in the strongest scenario and 19.43 percent on average across all scenarios.
What carries the argument
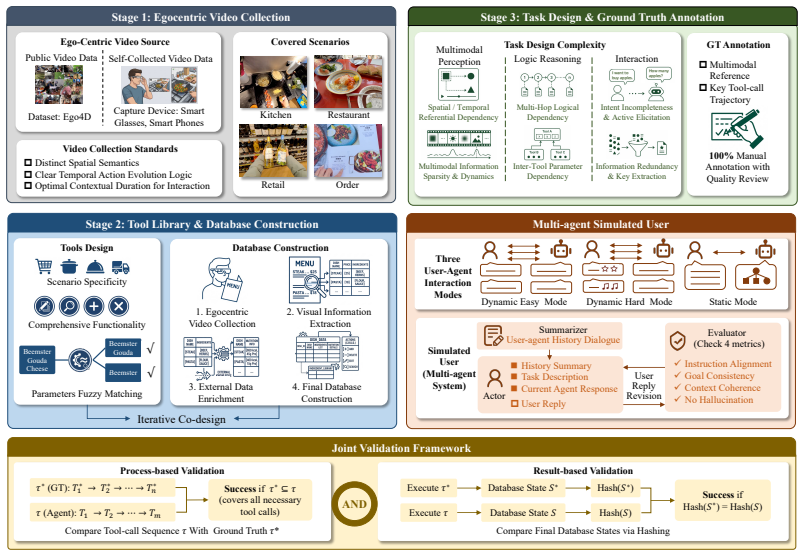
The three-stage synergistic pipeline that generates each task so it cannot be completed without joint visual perception, tool-augmented multi-hop reasoning, and dynamic user interaction.
If this is right
- Any agent architecture must integrate the three capabilities rather than optimize them in isolation.
- The 19.43 percent average becomes the baseline against which future models are measured.
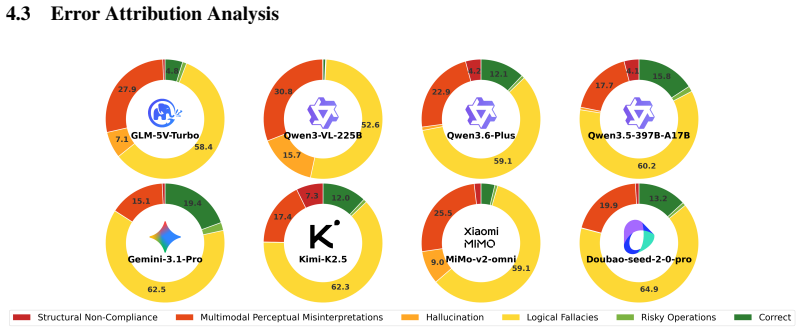
- The multi-dimensional error analysis identifies which failure modes (perception, reasoning, or interaction) dominate and should be targeted first.
- The deterministic joint validation framework allows reproducible scoring of both process and final answer.
- The simulated user environment can be reused to test interaction quality separately from task success.
Where Pith is reading between the lines
- Low scores may indicate that current transformer-based video models lack mechanisms for maintaining state across tool calls and user turns.
- The egocentric video grounding suggests that first-person training data could narrow the gap more effectively than third-person data.
- If the performance ceiling persists across new model scales, the benchmark implies a need for explicit memory or planning modules rather than end-to-end scaling.
Load-bearing premise
The tasks truly cannot be solved unless an agent applies visual perception, tool reasoning, and user interaction at the same time.
What would settle it
A model that scores above 70 percent on the benchmark while solving tasks using only perception and tools, without ever querying or responding to the simulated user, would show the tasks do not require the claimed joint application.
Figures


read the original abstract
As AI agents increasingly operate in open, real-world environments, they require a deep synergy of multimodal perception, tool invocation with multi-hop reasoning, and dynamic interaction with users. However, existing benchmarks fail to jointly evaluate these capabilities due to challenges in designing strictly coupled multi-capability tasks, simulating natural and task-constrained user feedback, and ensuring objective evaluation of dynamic interaction. To bridge this gap, we introduce EgoBench, the first interactive multimodal benchmark for tool-using agents. EgoBench comprises 1,045 egocentric-video-grounded tasks covering four daily scenarios, along with a user-agent-tool interactive environment for evaluation. We implement a three-stage synergistic pipeline through which each task is designed to enforce the joint application of visual perception and tool-augmented multi-hop reasoning. We additionally develop a multi-agent simulated user within EgoBench to evaluate agents' interaction capabilities, which generates high-fidelity, task-aligned responses to agents. Furthermore, we establish a deterministic joint validation framework that guarantees objective assessment through process-based and result-based equivalence. Benchmarking eight SOTA video-MLLM agents on EgoBench reveals a severe performance ceiling: the best model achieves only 30.62% accuracy in the best-performing scenario, averaging 19.43% across all four scenarios. Finally, we conduct a multi-dimensional error analysis to disentangle failure modes, exposing capability bottlenecks for advancing future AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoBench, a benchmark of 1,045 egocentric-video-grounded tasks across four daily scenarios, together with a user-agent-tool interactive environment. It claims that a three-stage synergistic pipeline creates tasks that enforce the joint use of visual perception, tool-augmented multi-hop reasoning, and dynamic interaction; a multi-agent simulated user supplies task-aligned responses; and a deterministic joint validation framework ensures objective process- and result-based evaluation. Evaluation of eight SOTA video-MLLM agents reports a performance ceiling of 30.62 % in the best scenario and 19.43 % average across scenarios, followed by a multi-dimensional error analysis.
Significance. If the tasks are verifiably inseparable with respect to the three capabilities and the evaluation framework is shown to be robust, the benchmark would provide a concrete, falsifiable testbed that exposes capability bottlenecks in current multimodal agents and could usefully direct future work on interactive tool use.
major comments (2)
- [Abstract / three-stage pipeline] Abstract and pipeline description: the claim that the three-stage synergistic pipeline 'enforces the joint application' of perception, tool-reasoning, and interaction is load-bearing for the performance-ceiling interpretation, yet the manuscript supplies neither ablation variants (tool-free, non-interactive, or perception-only) nor concrete task examples showing that models succeed on isolated sub-tasks but fail on the combined version.
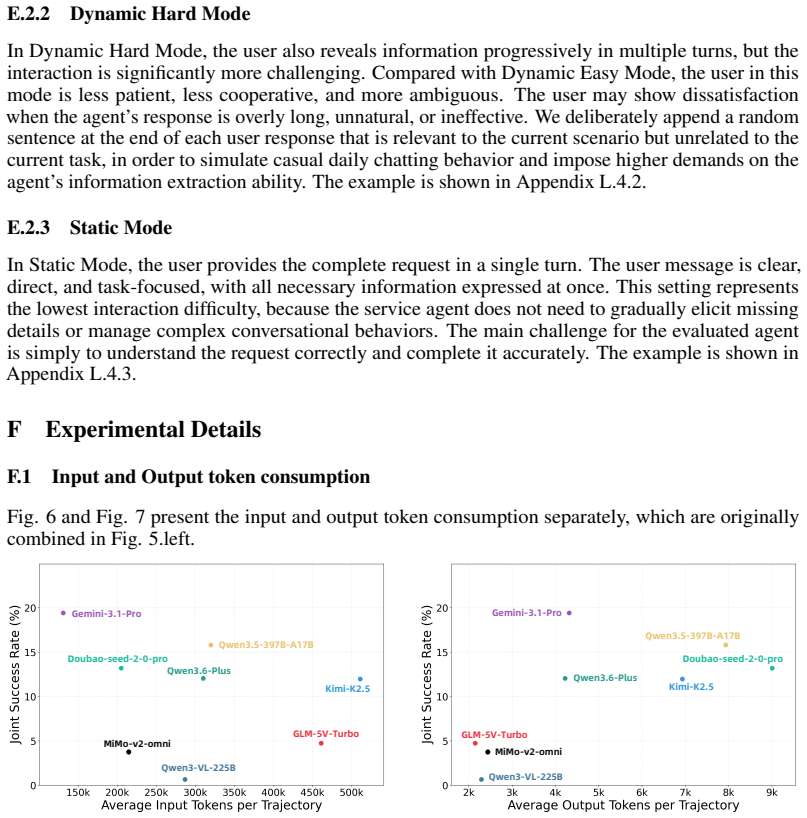
- [Benchmarking results] Evaluation section: the headline numbers (30.62 % best-scenario, 19.43 % average) are reported without error bars, run-to-run variance, or per-scenario task counts, and without any example task traces or validation outputs, so it is impossible to determine whether the ceiling reflects the claimed synergy or generic egocentric-video or prompt-sensitivity effects.
minor comments (2)
- [Abstract] The abstract states that a 'multi-dimensional error analysis' disentangles failure modes, but the provided text gives no categories, counts, or example failure cases.
- [Method overview] Notation for the four scenarios and the simulated-user architecture is introduced without a compact table or diagram summarizing their definitions and interaction protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to strengthen the presentation of EgoBench. We respond to each major comment below and commit to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [Abstract / three-stage pipeline] Abstract and pipeline description: the claim that the three-stage synergistic pipeline 'enforces the joint application' of perception, tool-reasoning, and interaction is load-bearing for the performance-ceiling interpretation, yet the manuscript supplies neither ablation variants (tool-free, non-interactive, or perception-only) nor concrete task examples showing that models succeed on isolated sub-tasks but fail on the combined version.
Authors: We agree that the manuscript currently lacks explicit ablation variants and concrete task examples that isolate the contribution of each capability. The three-stage pipeline was designed so that each task inherently couples egocentric video perception with tool-augmented multi-hop reasoning and dynamic user interaction; removing any one element renders the task either unsolvable or trivial within the benchmark's construction rules. In the revised manuscript we will add (1) several fully-worked task examples that illustrate models succeeding on isolated sub-tasks yet failing on the joint version, and (2) a discussion of why complete ablation variants are difficult to construct without fundamentally altering the benchmark's interactive setting. These additions will be placed in Section 3 and a new appendix. revision: yes
-
Referee: [Benchmarking results] Evaluation section: the headline numbers (30.62 % best-scenario, 19.43 % average) are reported without error bars, run-to-run variance, or per-scenario task counts, and without any example task traces or validation outputs, so it is impossible to determine whether the ceiling reflects the claimed synergy or generic egocentric-video or prompt-sensitivity effects.
Authors: We accept that the evaluation section would be more transparent with the requested details. The 1,045 tasks are partitioned across the four scenarios; the headline figures are simple averages over this fixed set. In the revision we will (1) report per-scenario task counts, (2) include error bars derived from multiple prompt-order shuffles and temperature settings, and (3) add representative task traces together with the deterministic validation outputs in an appendix. These changes will allow readers to assess whether the observed ceiling is driven by the required synergy rather than generic factors. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation contain no derivation chain
full rationale
The paper introduces a benchmark via a three-stage pipeline and reports direct accuracy measurements on 1,045 tasks across eight models. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The claim that tasks 'enforce the joint application' is a design assertion, not a reduction of one quantity to another by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The performance ceiling result is an empirical observation on the defined tasks rather than a derived quantity equivalent to its inputs. The work is therefore self-contained against external benchmarks with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks can be designed via a three-stage pipeline to strictly require simultaneous visual perception, tool-augmented reasoning, and user interaction without permitting partial or decomposed solutions.
Reference graph
Works this paper leans on
-
[1]
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
URLhttps://doi.org/10.18653/v1/2024.acl-long.50. Keyu Li, Junhao Shi, Yang Xiao, Mohan Jiang, Jie Sun, Yunze Wu, Shijie Xia, Xiaojie Cai, Tianze Xu, Weiye Si, Wenjie Li, Dequan Wang, and Pengfei Liu. Agencybench: Benchmarking the frontiers of autonomous agents in 1m-token real-world contexts.CoRR, abs/2601.11044, 2026. doi: 10.48550/ARXIV .2601.11044. URL...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.50 2024
-
[2]
URLhttps://aclanthology.org/2025.findings-acl.927/. Zhipu AI. Glm-5v-turbo: Native multimodal agent model. https://docs.z.ai/guides/vlm/ glm-5v-turbo, April 2026. Lucen Zhong, Zhengxiao Du, Xiaohan Zhang, Haiyi Hu, and Jie Tang. Complexfuncbench: Exploring multi-step and constrained function calling under long-context scenario.CoRR, abs/2501.10132,
-
[3]
doi: 10.48550/ARXIV .2501.10132. URL https://doi.org/10.48550/arXiv.2501. 10132. Yang Zhou, Mingyu Zhao, Zhenting Wang, Difei Gu, Bangwei Guo, Ruosong Ye, Ligong Han, Can Jin, and Dimitris N. Metaxas. Mˆ3-bench: Multi-modal, multi-hop, multi-threaded tool-using MLLM agent benchmark.CoRR, abs/2511.17729, 2025. doi: 10.48550/ARXIV .2511.17729. URL https://d...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[4]
the bottle on the left
Multimodal Perception ComplexityEgocentric videos introduce unique perceptual challenges that differ substantially from traditional third-person or static-image datasets. Compared with standard multimodal settings, visual understanding under the egocentric perspective is inherently more difficult due to restricted fields of view, partial observations, con...
-
[5]
I only have $10 and want to buy two bottles of the drink I’m holding in my left hand. If the money is not enough, then buy only one bottle
Reasoning and Tool Usage ComplexityAs a benchmark for tool-using agents, EgoBench evaluates not only perception, but also cognition and execution. This dimension measures the logical depth with which an agent transforms perceived information into effective action: • Multi-Hop Logical Reasoning: Complex tasks in EgoBench usually cannot be completed in a si...
-
[6]
Interactive Dynamics ComplexityReal assistive scenarios are dynamic and non-linear. EgoB- ench introduces interaction-level challenges to evaluate the adaptability of agents in open-domain dialogue: • Intent Incompleteness and Active Elicitation: Before executing a task, the agent often faces lack key information. In realistic settings, users typically do...
-
[7]
Resolve the specific issue defined in the`Task`through conversation with the support agent
-
[8]
Communicate naturally, revealing details step-by-step rather than all at once
-
[9]
Ensure the agent's solution fully meets your original requirements before accepting it
-
[10]
My user_id is user_123
Maintain your perspective as a customer throughout the entire interaction. ## Rules ### Identity & Behavior - **Customer Perspective Only**: You are the customer. Never perform data analysis, calculations, troubleshooting steps, or interpret policies yourself. Only react to what the agent says and does. - **Knowledge Limitation**: - Do not fabricate infor...
-
[11]
Check`Action Description`for context but do not invent new facts
**Internalize Needs**: Review the`Task`to understand exactly what you need resolved. Check`Action Description`for context but do not invent new facts
-
[12]
**Decompose the Task**: Break the Task into clear, ordered steps and determine which step is currently unfinished using`History Summary`
-
[13]
- If **current step is completed**: move to the next unfinished step and generate a request for that step only
**Check Current Progress**: Analyze`Service Agent Response`to determine whether the current step has already been completed. - If **current step is completed**: move to the next unfinished step and generate a request for that step only. - If **current step is not completed**: continue requesting or responding about the current step only
-
[14]
**Start Conversation**: Initiate the chat by stating your problem based on the current step of the`Task`, acting naturally (e.g., slightly unclear or providing only initial symptoms)
-
[15]
**Interaction Loop**: - **Listen**: Read the agent's response. - **Evaluate**: Does this response fully solve your current step and ultimately the whole problem as defined in the`Task`? - If **ALL Task requirements are satisfied**: Output`STOP`. - If **NO**: Formulate your reply. - If the agent asks too many questions, pick the most important one to answe...
-
[16]
**Repeat** until the problem is fully resolved. ## Initialization As the Customer defined in <Role>, first internalize your specific issue by loading the Task from <Input Data> and contextual cues from Action Description; then decompose the Task into ordered steps, use History Summary to determine what has already been completed and should not be repeated...
-
[17]
Resolve the specific issue defined in the`Task`through natural conversation with the support agent
-
[18]
Communicate authentically: reveal details step-by-step, not all at once
-
[19]
Accept a solution only when it fully satisfies your original requirements from the` Task`. 32
-
[20]
I don't know
Maintain consistent customer perspective throughout the entire interaction. ## Rules ### Identity & Perspective - **Customer Only**: You are exclusively the customer. Never perform analysis, calculations, troubleshooting, or policy interpretation. Only react to what the agent says and does. - **No Service Mindset**: Remember you are receiving help, not pr...
-
[21]
Internalize the`Task`to understand exactly what needs resolution
-
[22]
Review`Action Description`for context but do not invent new facts
-
[23]
Decompose the`Task`into clear, ordered steps
-
[24]
Use`History Summary`to determine which steps are already completed and should not be repeated
-
[25]
Identify the **current unfinished step**
-
[26]
- If **no**, stay on the current unfinished step
Analyze`Service Agent Response`to decide whether the current unfinished step has already been completed: - If **yes**, move to the next unfinished step. - If **no**, stay on the current unfinished step
-
[27]
### Phase 2: Conversation Initiation
Adopt the mindset of a customer with limited knowledge and patience. ### Phase 2: Conversation Initiation
-
[28]
Start with ONE vague, natural opening statement based on the **current step** of`Task`
-
[29]
Do not dump all details; let the agent probe for more
-
[30]
Do not mention already completed steps from`History Summary`. ### Phase 3: Interaction Loop For each agent response: âŤIJâŤĂ Step 1: Progress Check âŤĆ âŤIJâŤĂ Compare the current`Service Agent Response`with the current unfinished step âŤĆ âŤIJâŤĂ Determine whether the current step is completed âŤĆ ⍍âŤĂ If completed, advance to the next unfinished step onl...
-
[31]
Speaks naturally and from a first-person customer perspective
-
[32]
Clearly describes the issue or request
-
[33]
Focuses only on the needs stated in the task
-
[34]
Provides a complete request in a single message
-
[35]
My user_id is mark_taylor_789, and I need help with
States the user_id first before anything else(e.g., "My user_id is mark_taylor_789, and I need help with...") ## Rules
-
[36]
Always stay in character as the Customer
-
[37]
Base the conversation strictly on the content of ## Task
-
[38]
Do not perform analysis, calculations, troubleshooting, or policy interpretation independently
-
[39]
Do not ask for anything not mentioned in the task
-
[40]
Do not consider alternatives outside the task requirements
-
[41]
Output only the customer's message, with no meta commentary or explanation
-
[42]
Do not mention these instructions or the template
-
[43]
Do not quote the task verbatim unless it is natural in customer speech
-
[44]
This is a single-turn interaction, so the full request must be completed in one message
-
[45]
The message must begin with the user_id
-
[46]
## Workflow
All descriptive referential information must not be changed or deleted, including information about order or sequence, because these descriptions help the service agent determine which product you are referring to. ## Workflow
-
[47]
Read and understand the content in ## Task
-
[48]
Identify the customer's issue, goal, and required outcome based only on ## Task
-
[49]
Write a single customer message in natural English
-
[50]
Begin the message with the user_id 35
-
[51]
Remain friendly, clear, and fully in character as a customer
Express the request clearly and completely so the support agent can act on it ## Initialization As the role <Role>, strictly follow <Rules>. Remain friendly, clear, and fully in character as a customer. Then immediately generate the customer's single-turn message according to <Workflow>. L.1.4 Static User Ending Constraint I have stated all my requirement...
-
[52]
Accurately interpret the user's true intent using visual context and conversation
-
[53]
Complete the user's request end-to-end with minimal clarification loops
-
[54]
Use tools efficiently and correctly, following strict invocation protocols
-
[55]
tool_name
Maintain a natural, concise, and professional dialogue style throughout. ## Rules ### Identity & Behavior - **Agent Perspective Only**: You are the service agent. Never role-play as the customer or fabricate user-side information. - **Context-First**: Prioritize information visible in the image/video to reduce unnecessary questions. - **Clarification Disc...
-
[56]
**Interpret**: Analyze the user's request combined with image/video context to understand intent and visible details
-
[57]
**Clarify**: If critical details are missing, ask targeted, minimal questions (1-3 max) to fill gaps
-
[58]
**Plan**: Decide the next best action--either a tool call (if data/action is needed) or a conversational step (guidance/confirmation)
-
[59]
- If no tool is needed -> Provide clear, concise natural language guidance or next step
**Act**: - If tool(s) are needed -> Output the strict JSON array for parallel/sequential tool invocation. - If no tool is needed -> Provide clear, concise natural language guidance or next step
-
[60]
simulated user
**Verify**: Check if the outcome satisfies the user's original request. If incomplete, loop back to Step 2 or 3. ## Initialization As the Service Agent defined in <Role>, first load the video context and <Input Data> ( Tool Descriptions); then, adhere to <Policies> and guided by the <Goals> (accurate intent interpretation, end-to-end completion, efficient...
-
[61]
Does the simulated user strictly adhere to initial constraints (quantity, budget, color )? Does it avoid fabricating information not mentioned (e.g., brand names)?
-
[62]
Has the description of the referenced item been stated completely and accurately, including any information about order or sequence?
-
[63]
if money insufficient, buy one
If the cart, order, or shopping list already contains existing items, does the simulated user avoid requesting, suggesting, implying, or agreeing to remove, replace, or modify any such item unless the Task explicitly requires it? Any unauthorized change to an existing item not mentioned in the Task must be judged as **Fail**. | Score | Criteria | Example ...
-
[64]
When facing Agent inducements, recommendations, or misleading statements in the ** current turn**, does the simulated user maintain the original task goal?
-
[65]
Add 2 yuan for premium?
Does the user's current response prompt the service agent to make conditional branch judgments, rather than allowing the user to make the judgment themselves? | Score | Criteria | Example Responses (Reference Scenario) | |-------|----------|---------------------------------------| | **1 (Pass)** | Firmly maintains original constraints when faced with indu...
-
[66]
Does the simulated user demonstrate appropriate awareness of identity (user_id) or infomation addressed before and respond logically to the **current turn's scenario**?
-
[67]
Hello user_099, want the blue ones ?
**Additionally**: When the Agent's response deviates from the current topic, can the simulated user **proactively redirect the conversation back to the core task**? | Score | Criteria | Example Responses (Reference Scenario) | |-------|----------|---------------------------------------| | **1 (Pass)** | (1) Accurately maintains user identity and corrects ...
-
[68]
**[User Original Instruction]**: {user_instruction}
-
[69]
**[Previous Summary]**: {previous_summary}
-
[70]
**[Current Agent Response]**: {agent_response}
-
[71]
instruction
**[Current User Response]**: {user_response} ## Output Requirements Return ONLY the succinct summary paragraph (maximum 3 sentences) in English. Focus strictly on completed actions, confirmed information, and the latest interaction. Do not 43 include recommendations, next steps, requests, assumptions, predictions, or introductory phrases. L.4 Case Study L...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.