Fine-Tuned LLM as a Complementary Predictor Improving Ads System
Pith reviewed 2026-06-29 10:25 UTC · model grok-4.3
The pith
A fine-tuned open-source LLM predicts likely advertisers from user profiles and histories to augment candidate generation and supply priors for ranking in a production ads system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
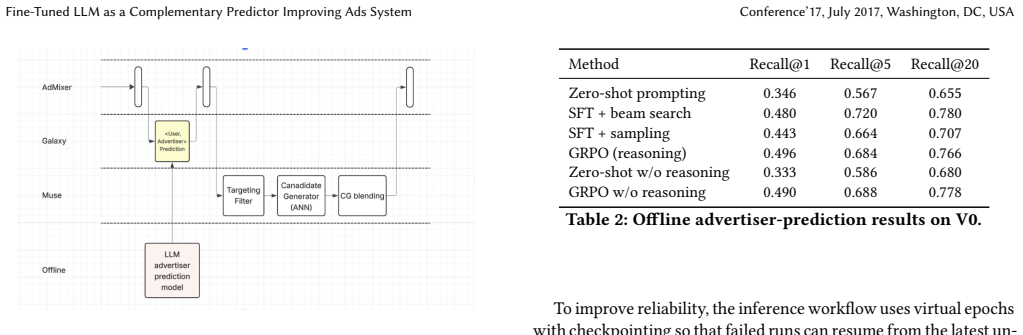
By fine-tuning an open-source LLM to forecast likely advertisers from user profiles and histories, the model serves as a complementary predictor that augments conventional candidate generation and supplies informative priors to downstream ranking stages, resulting in substantial offline improvements and measurable online business impact in a production advertising system.
What carries the argument
The fine-tuned LLM as an ads-specific ancillary predictor that outputs likely advertisers to enhance retrieval and ranking.
If this is right
- The LLM outputs improve the candidate set available to retrieval.
- The same outputs act as priors that raise performance of the downstream ranker.
- Targeted ancillary predictions can produce end-to-end gains without replacing the full pipeline.
- LLM world knowledge can be harnessed in production ads systems through this complementary role.
Where Pith is reading between the lines
- The same ancillary-prediction pattern could be tested on non-advertising recommendation domains such as content or product feeds.
- Multiple fine-tuned LLM predictors for different signals might be combined without increasing inference cost dramatically.
- The approach suggests that production teams can add LLM value incrementally rather than requiring a full generative retrieval overhaul.
Load-bearing premise
The LLM's advertiser forecasts supply priors that are informative enough to meaningfully improve the existing candidate generation and ranking stages.
What would settle it
An A/B test in the live production system that disables the LLM predictor or replaces its outputs with random values and shows no change in offline metrics or online business KPIs would falsify the claim.
Figures

read the original abstract
Recommendation systems power engagement and monetization across feeds, ads, and short-video platforms, but translating the latest advances in Large Language Models into Recommendation Systems (RecSys) gains remains rare, particularly in advertising and production-scale real-world industry setups. Prior real-world LLM successes typically fall into three buckets: (a) generative retrieval that directly predicts the next items for candidate generation, (b) late-stage re-ranking that uses LLMs, and (c) auxiliary signal enrichment with LLMs. We introduce a complementary paradigm for ads: a fine-tuned open-source LLM used not as a ranker, but as an ads-specific ancillary predictor, forecasting likely advertisers from user profiles and histories. This LLM-driven advertiser prediction augments conventional candidate generation and provides informative priors to downstream ranking. Developed in a large-scale production advertising system, our approach produces substantial offline improvements and measurable online business impact, demonstrating that LLM world knowledge and predictive capacity can be efficiently harnessed. Beyond validating LLMs for ads applications, our results show that targeted ancillary predictions can unlock end-to-end gains across both retrieval and late-stage ranking, offering a practical path to LLM-enhanced recommendation at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using a fine-tuned open-source LLM as an ancillary predictor (not a ranker) that forecasts likely advertisers from user profiles and histories. This prediction augments conventional candidate generation in a production advertising system and supplies informative priors to downstream ranking stages, yielding substantial offline metric gains and measurable online business impact.
Significance. If the central attribution to LLM world knowledge holds under controlled evaluation, the work would be significant as a practical, scalable paradigm for LLM integration into industrial RecSys that avoids replacing entire pipelines. It would demonstrate end-to-end gains from targeted ancillary predictions across retrieval and ranking.
major comments (2)
- [§4 and §5] §4 (Methods) and §5 (Experiments): The manuscript describes integration of the LLM predictor but does not report a controlled ablation that replaces the fine-tuned LLM head with an equivalent non-LLM classifier (e.g., gradient-boosted tree or neural net) trained on identical user features and histories. Without this comparison, gains cannot be attributed to LLM-specific predictive capacity rather than simply adding an extra signal; this directly undermines the central claim that the approach harnesses 'LLM world knowledge'.
- [§5.2] §5.2 (Offline Results): No baselines, absolute metric values, error bars, or statistical significance tests are described for the reported 'substantial offline improvements' in candidate generation or ranking metrics. This makes it impossible to assess whether the deltas exceed what conventional feature-augmentation techniques already achieve in the production pipeline.
minor comments (2)
- [Abstract] The abstract and introduction use 'substantial' and 'measurable' without defining thresholds or providing context relative to prior production baselines.
- [§3] Notation for the LLM output (e.g., how advertiser probabilities are converted into priors for ranking) is introduced without an equation or pseudocode example.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Methods) and §5 (Experiments): The manuscript describes integration of the LLM predictor but does not report a controlled ablation that replaces the fine-tuned LLM head with an equivalent non-LLM classifier (e.g., gradient-boosted tree or neural net) trained on identical user features and histories. Without this comparison, gains cannot be attributed to LLM-specific predictive capacity rather than simply adding an extra signal; this directly undermines the central claim that the approach harnesses 'LLM world knowledge'.
Authors: We agree that a controlled ablation is important for attributing gains to LLM-specific capabilities. Our LLM processes natural-language user profiles and histories, enabling use of pre-trained world knowledge that standard tabular classifiers lack. To directly address the concern, we will add an ablation comparing the fine-tuned LLM to a non-LLM neural network trained on equivalent textual representations of the same user data. This revision will clarify the contribution of the LLM approach. revision: yes
-
Referee: [§5.2] §5.2 (Offline Results): No baselines, absolute metric values, error bars, or statistical significance tests are described for the reported 'substantial offline improvements' in candidate generation or ranking metrics. This makes it impossible to assess whether the deltas exceed what conventional feature-augmentation techniques already achieve in the production pipeline.
Authors: We acknowledge the need for clearer reporting. Absolute metric values and specific production baselines cannot be disclosed due to commercial confidentiality. In the revision we will report relative improvements, include error bars, and describe the statistical significance tests performed, allowing evaluation against conventional augmentation methods while preserving sensitive information. revision: partial
Circularity Check
No derivation chain or equations present; empirical claim only.
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or mathematical predictions. The central claim is an empirical report of offline/online gains from integrating a fine-tuned LLM as an ancillary advertiser predictor in a production ads system. No self-definitional steps, fitted-input predictions, or self-citation load-bearing arguments appear. The result is therefore self-contained against external benchmarks with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Beal, Eric Kim, Jinfeng Rao, Rex Wu, Dmitry Kislyuk, and Charles Rosenberg
-
[2]
InProceedings of The ACM Web Conference
PinCLIP: Large-scale Foundational Multimodal Representation at Pinterest. InProceedings of The ACM Web Conference
-
[3]
Keshavan, Lukasz Heldt, Lichan Hong, Ed H
Yuwei Cao, Nikhil Mehta, Xinyang Yi, Raghunandan H. Keshavan, Lukasz Heldt, Lichan Hong, Ed H. Chi, and Maheswaran Sathiamoorthy. 2024. Aligning Large Language Models with Recommendation Knowledge.arXiv preprint arXiv:2404.00245(2024). https://arxiv.org/abs/2404.00245
-
[4]
Zhimin Chen, Chenyu Zhao, Ka Chun Mo, Yunjiang Jiang, Jane H. Lee, Shouwei Chen, Khushhall Chandra Mahajan, Ning Jiang, Kai Ren, Jinhui Li, and Wen- Yun Yang. 2025. Massive Memorization with Hundreds of Trillions of Param- eters for Sequential Transducer Generative Recommenders.arXiv preprint arXiv:2510.22049(2025). https://arxiv.org/abs/2510.22049
-
[5]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Ro- han Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah. 2016. Wide & Deep Learning for Recommender Systems.arXiv preprint arXiv:1606.07792(2016). https://arxiv.org/abs/1606.07792
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems (RecSys). ACM, 191–198. doi:10.1145/2959100.2959190
-
[7]
Hamed Firooz, Maziar Sanjabi, Adrian Englhardt, Aman Gupta, Ben Levine, Dre Olgiati, Gungor Polatkan, Iuliia Melnychuk, Karthik Ramgopal, Kirill Talanine, Kutta Srinivasan, Luke Simon, Natesh Sivasubramoniapillai, Necip Fazil Ayan, Qingquan Song, Samira Sriram, Souvik Ghosh, Tao Song, Tejas Dharamsi, Vignesh Kothapalli, Xiaoling Zhai, Ya Xu, Yu Wang, and ...
-
[8]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, Xinyang Yi, Lexi Baugher, Baykal Cakici, Ed H. Chi, Cristos Goodrow, Ningren Han, He Ma, Romer Rosales, Abby Van Soest, Devansh Tandon, Su-Lin Wu, Wei- long Yang, and Yilin Zheng. 2025. PLUM: Adapting Pre-trained L...
-
[9]
Singh, Maxime Ransan, and Sagar Jain
Wenhan Lyu, Devashish Tyagi, Yihang Yang, Ziwei Li, Ajay Somani, Karthikeyan Shanmugasundaram, Nikola Andrejevic, Ferdi Adeputra, Curtis Zeng, Arun K. Singh, Maxime Ransan, and Sagar Jain. 2025. DV365: Extremely Long User History Modeling at Instagram.arXiv preprint arXiv:2506.00450(2025). https: //arxiv.org/abs/2506.00450
-
[10]
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G. Azzolini, Dmytro Dzhulgakov, Andrey Mallevich, Ilia Cherni- avskii, Yinghai Lu, Raghuraman Krishnamoorthi, Ansha Yu, Volodymyr Kon- dratenko, Stephanie Pereira, Xianjie Chen, Wenlin Chen, Vijay Rao,...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Ming Pang, Chunyuan Yuan, Xiaoyu He, Zheng Fang, Donghao Xie, Fanyi Qu, Xue Jiang, Changping Peng, Zhangang Lin, Zheng Luo, and Jingping Shao. 2025. Generative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval.arXiv preprint arXiv:2504.01403(2025). https://arxiv.org/abs/2504.01403
-
[12]
Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan H. Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. 2023. Recommender Systems with Generative Retrieval.arXiv preprint arXiv:2305.05065(2023). https://arxiv.org/ abs/2305.05065
-
[13]
Zihua Si, Zhongxiang Sun, Jiale Chen, Guozhang Chen, Xiaoxue Zang, Kai Zheng, Yang Song, Xiao Zhang, Jun Xu, and Kun Gai. 2023. Generative Retrieval with Semantic Tree-Structured Item Identifiers via Contrastive Learning.arXiv preprint arXiv:2309.13375(2023). https://arxiv.org/abs/2309.13375 Semantic ID learning for generative retrieval
- [14]
-
[15]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Net- work for Ad Click Predictions. InProceedings of the 2017 ADKDD Workshop (ADKDD@KDD). ACM, 12:1–12:7. doi:10.1145/3124749.3124754
-
[16]
Zhang, Qing Cui, Longfei Li, Jun Zhou, and Sheng Li
Yan Wang, Zhixuan Chu, Xin Ouyang, Simeng Wang, Hongyan Hao, Yue Shen, Jinjie Gu, Siqiao Xue, James Y. Zhang, Qing Cui, Longfei Li, Jun Zhou, and Sheng Li. 2023. Enhancing Recommender Systems with Large Language Model Reasoning Graphs.arXiv preprint arXiv:2308.10835(2023). https://arxiv.org/abs/ 2308.10835
-
[17]
Ji Yang, Xinyang Yi, Derek Zhiyuan Cheng, Lichan Hong, Yang Li, Si- mon Wang, Taibai Xu, and Ed H. Chi. 2020. Mixed Negative Sam- pling for Learning Two-tower Neural Networks in Recommendations. In Companion Proceedings of the Web Conference 2020 (WWW Companion). ACM. https://research.google/pubs/mixed-negative-sampling-for-learning-two- tower-neural-netw...
2020
-
[18]
Chao Yi, Dian Chen, Gaoyang Guo, Jiakai Tang, Jian Wu, Jing Yu, Sunhao Dai, Wen Chen, Wenjun Yang, Yuning Jiang, Zhujin Gao, Bo Zheng, Chi Li, Dimin Wang, Dixuan Wang, Fan Li, Fan Zhang, Haibin Chen, Haozhuang Liu, Jialin Zhu, Jiamang Wang, Jiawei Wu, Jin Cui, Ju Huang, Kai Zhang, Kan Liu, Lang Tian, Liang Rao, Longbin Li, Lulu Zhao, Mao Zhang, Na He, Pei...
- [19]
- [20]
-
[21]
Guorui Zhou, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Qiang Luo, Qianqian Wang, Qigen Hu, Rui Huang, Shiyao Wang, Weifeng Ding, Wuchao Li, Xinchen Luo, Xingmei Wang, Zexuan Cheng, Zixing Zhang, Bin Zhang, Boxuan Wang, Chaoyi Ma, Chengru Song, Chenhui Wang, Di Wang, Dongxue Meng, Fan Yang, Fangyu Zhang, Feng Jiang, Fuxing Zhang, Gang Wang, Guowang ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.