Narrative Flattening: How Post-Training Compresses Thematic, Affective, and Stylistic Variation in LLM Fiction
Pith reviewed 2026-06-29 13:18 UTC · model grok-4.3
The pith
Post-training compresses thematic transitions, emotional intensity, and stylistic diversity in LLM fiction outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
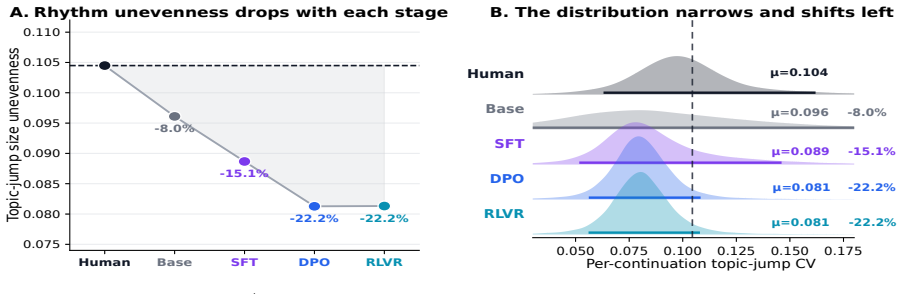
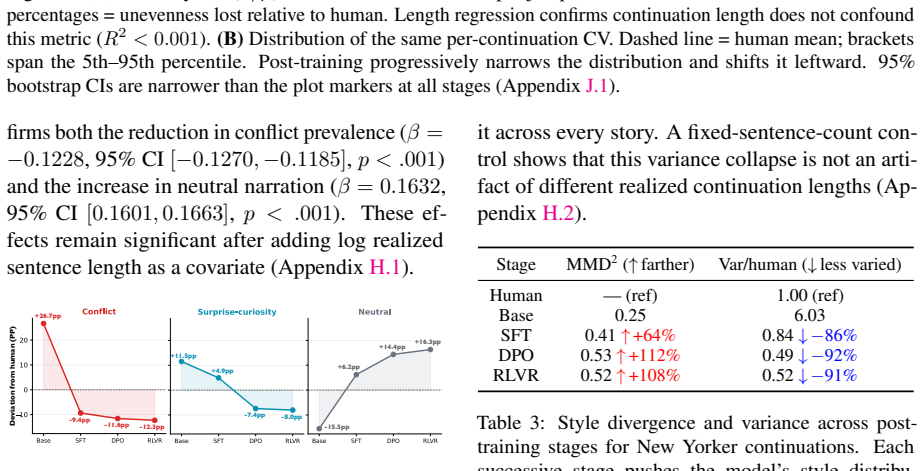
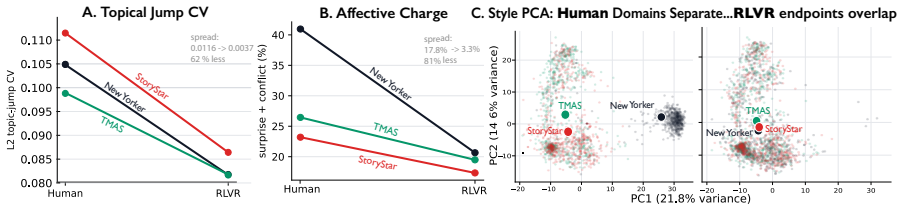
Post-training produces narrative flattening: thematic transitions grow more uniform, high-intensity emotions are replaced by neutrality, and stylistic diversity across stories shrinks, with the effect stable in direction but varying in magnitude by human baseline.
What carries the argument
Matched story-continuation paradigm that holds architecture, scale, tokenizer, and pretraining fixed while varying only the post-training stage (Base, SFT, DPO, RLVR) and comparing against human text from three domains using sentence-level metrics.
If this is right
- Post-trained models generate continuations whose texture becomes largely independent of the source domain's narrative properties.
- Professional literary fiction shows the largest compression relative to its human baseline.
- Public-platform and prompt-guided stories exhibit smaller gaps because their human baselines already sit closer to the model's default rhythm.
- The three post-training stages produce convergent outputs across domains.
Where Pith is reading between the lines
- Alignment procedures may need explicit variation-preserving objectives if long-form creative output is a goal.
- The same metrics could be monitored during training to detect and counteract flattening in real time.
- Repeating the design on other model families would test whether narrative flattening is a general consequence of current post-training methods.
Load-bearing premise
The sentence-level metrics chosen for thematic motion, affective prevalence, and linguistic diversity validly quantify perceived narrative flattening without measurement artifacts that exaggerate the post-training effect.
What would settle it
Collect human ratings of narrative flatness on the same continuations; if the ratings show no systematic difference between base and post-trained models, or if the metric shifts do not correlate with the ratings, the flattening claim is falsified.
Figures

read the original abstract
Large language models produce fluent fiction, yet their creative output is widely seen as flat. We ask where this quality originates in the training and whether it affects different domains of human fiction equally. We construct a matched story-continuation paradigm across StoryStar (public-platform), TMAS (prompt-guided), and The New Yorker (professional literary)-and compare continuations from four OLMo 32B checkpoints (Base, SFT, DPO, RLVR) against matched human text. Because these checkpoints share architecture, scale, tokenizer, and pretraining, the design isolates the post-training effect. We measure each continuation along three sentence-level dimensions: thematic motion, affective prevalence, and linguistic diversity. Across all three, post-training compresses dynamic variation: thematic transitions become more uniform, high-intensity emotions give way to neutrality, and stylistic diversity across stories shrinks. We term this progressive loss narrative flattening. The effect is directionally stable across story domains but gap size depends on the human baseline: professional literary fiction is compressed most, while public-platform and prompt-guided stories show smaller gaps, consistent with their human baselines sitting closer to the model's default rhythm. Post-trained endpoints converge across domains, suggesting alignment produces a continuation regime largely insensitive to the source domain's narrative texture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-training of LLMs produces narrative flattening in fiction. Using matched story continuations from OLMo 32B checkpoints (Base, SFT, DPO, RLVR) versus human text across three domains (StoryStar, TMAS, New Yorker), sentence-level metrics show post-training reduces thematic motion (more uniform transitions), affective prevalence (high-intensity emotions shift to neutrality), and linguistic diversity (stylistic variation shrinks). The effect is directionally consistent across domains but larger where human baselines differ most from the model's default; post-trained endpoints converge regardless of source domain.
Significance. The matched-checkpoint design cleanly isolates post-training effects and is a methodological strength. If the metrics are shown to be valid, the work supplies a concrete, multi-domain empirical account of a commonly observed qualitative deficit in LLM fiction, with implications for how alignment techniques shape creative output. The domain-dependent gap sizes and convergence finding add useful nuance.
major comments (2)
- [Methods] Methods section (metric definitions): The abstract and provided description supply no formulas, implementation details, statistical tests, sample sizes, or robustness checks for the three sentence-level metrics (thematic motion, affective prevalence, linguistic diversity). Without these, it is impossible to determine whether the reported compression reflects genuine reduction in dynamic variation or measurement artifacts (e.g., post-training increasing fluency or predictability in ways that mechanically lower the scores).
- [Results] Results/Discussion (metric validation): The central claim that post-training compresses thematic, affective, and stylistic variation depends on the metrics faithfully capturing human-perceived narrative flattening. No human validation, inter-rater correlation, or comparison against alternative measures is described; if the metrics are downstream consequences of alignment rather than direct measures, the observed cross-domain convergence could be an artifact rather than evidence of compression.
minor comments (1)
- [Abstract] Abstract: Adding a single sentence on the number of continuations or stories per domain would help readers gauge the scale of the comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments correctly identify gaps in the presentation of our metrics. We address each point below and commit to revisions that will strengthen the manuscript without altering its core claims or design.
read point-by-point responses
-
Referee: [Methods] Methods section (metric definitions): The abstract and provided description supply no formulas, implementation details, statistical tests, sample sizes, or robustness checks for the three sentence-level metrics (thematic motion, affective prevalence, linguistic diversity). Without these, it is impossible to determine whether the reported compression reflects genuine reduction in dynamic variation or measurement artifacts (e.g., post-training increasing fluency or predictability in ways that mechanically lower the scores).
Authors: We agree that the Methods section as currently written omits the necessary formulas, implementation details, statistical tests, sample sizes, and robustness checks. This omission makes it difficult for readers to evaluate potential artifacts. In the revised manuscript we will add a dedicated subsection that provides: (1) the exact mathematical definitions (e.g., thematic motion as normalized variance in sentence-level topic embeddings or transition entropy; affective prevalence as the proportion of high-intensity emotion labels from a validated classifier with intensity weighting; linguistic diversity as mean pairwise cosine distance in sentence embeddings plus type-token ratio); (2) implementation details including the specific models and libraries used; (3) the statistical tests (paired t-tests and mixed-effects models with domain and checkpoint as factors); (4) exact sample sizes (number of continuations per domain/checkpoint); and (5) robustness checks (e.g., controlling for sentence length and fluency via perplexity). These additions will allow direct assessment of whether the observed compression is artifactual. revision: yes
-
Referee: [Results] Results/Discussion (metric validation): The central claim that post-training compresses thematic, affective, and stylistic variation depends on the metrics faithfully capturing human-perceived narrative flattening. No human validation, inter-rater correlation, or comparison against alternative measures is described; if the metrics are downstream consequences of alignment rather than direct measures, the observed cross-domain convergence could be an artifact rather than evidence of compression.
Authors: The referee is correct that the manuscript contains no human validation, inter-rater reliability statistics, or explicit comparisons to alternative measures. We did not conduct such validation in the original study, which is a genuine limitation for claims about human-perceived flattening. In the revision we will add an explicit Limitations subsection that acknowledges this gap, cites the established NLP literature on which the metrics are based, and reports any post-hoc checks we can perform (e.g., correlation with existing readability or sentiment-variance benchmarks). We will also note that the directional consistency across three distinct domains and the convergence of post-trained models provide indirect support, but we will not claim this substitutes for direct human validation. If space permits, we will include a small-scale human rating pilot or outline plans for one. revision: partial
Circularity Check
Empirical comparison of checkpoints to human text; no circular reductions
full rationale
The paper conducts a matched empirical comparison of OLMo checkpoints (Base/SFT/DPO/RLVR) against human continuations across three domains, measuring sentence-level thematic motion, affective prevalence, and linguistic diversity. No equations, fitted parameters, or self-citation chains reduce the reported compression effects to inputs defined from the same data. The design is self-contained against external human baselines, with no load-bearing self-definitional steps or predictions that collapse by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GoEmotions: A dataset of fine-grained emo- tions. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4040–4054, Online. Association for Computational Linguistics. Anil R. Doshi and Oliver P. Hauser. 2024. Generative ai enhances individual creativity but reduces the col- lective diversity of novel content.Scien...
-
[2]
InProceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing, pages 298–311
Narrative theory for computational narrative understanding. InProceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing, pages 298–311. Association for Compu- tational Linguistics. Andrew Piper, Hao Xu, and Eric D. Kolaczyk. 2023. Modeling narrative revelation. InProceedings of the Computational Humanities Research Conferenc...
2021
-
[3]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Andrew J. Reagan, Lewis Mitchell, Dilan Kiley, Christo- pher M. Danforth, and Peter Sheridan Dodds. 2016. The emotional arcs of stories are dominated by six basic shapes.EPJ Data Science, 5(31). Nora Shaalan. 2022. The view from the fiction of the ...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Spoiler alert: Narrative forecasting as a metric for tension in LLM storytelling.Preprint, arXiv:2604.09854. Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groen- eveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, and 1 others. 2025. 2 OLMo 2 Furious.Preprint, arXiv:2501.00656. Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
He smelled bacon frying in the kitchen and knew Paul must be cooking breakfast
Sentence embeddings are produced by mean pooling over token embeddings, not CLS pooling. Embeddings are L2-normalized at inference using normalize_embeddings=True. The resulting 768-dimensional vectors are stored as styleN_0 throughstyleN_767. Style MMD is computed on sentence-level 768- dimensional embeddings. Across-story style vari- ance and PCA homoge...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.