Retrieval, Reward, and Training Protocols: What Matters in Training Search Agents?
Pith reviewed 2026-06-29 13:14 UTC · model grok-4.3
The pith
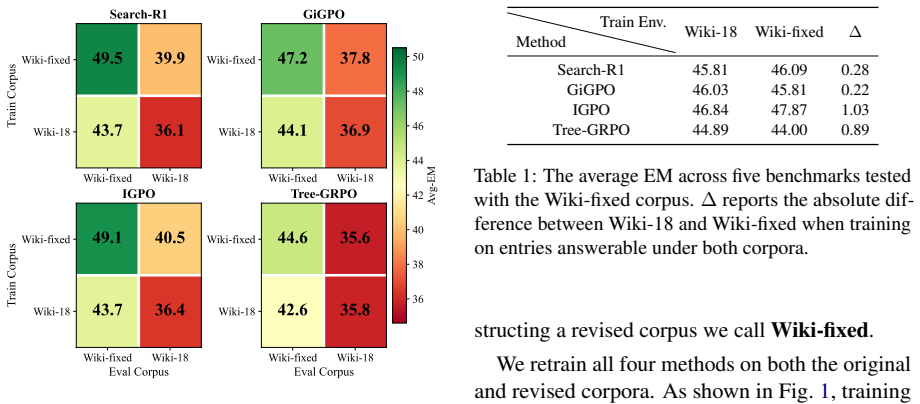
Correcting coverage gaps in the Wikipedia 2018 corpus improves search agent performance more than changes to training algorithms or rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
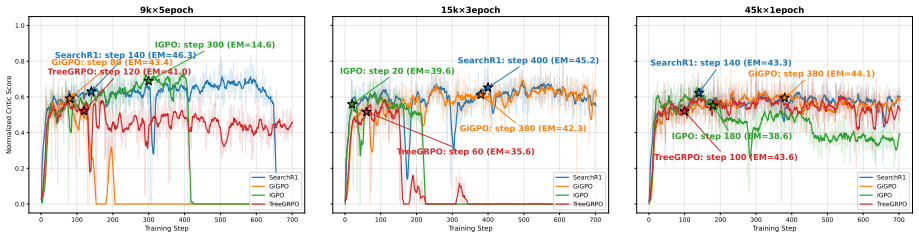
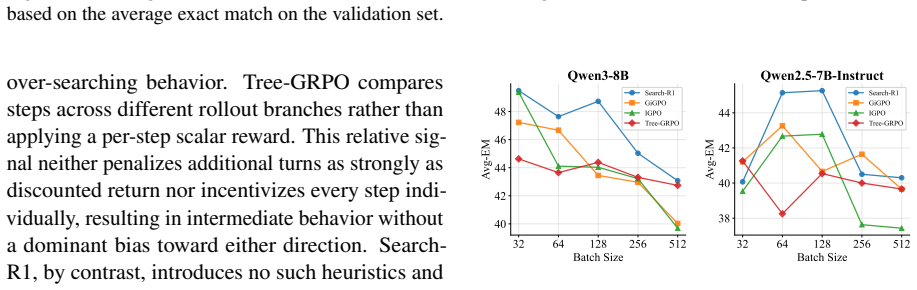
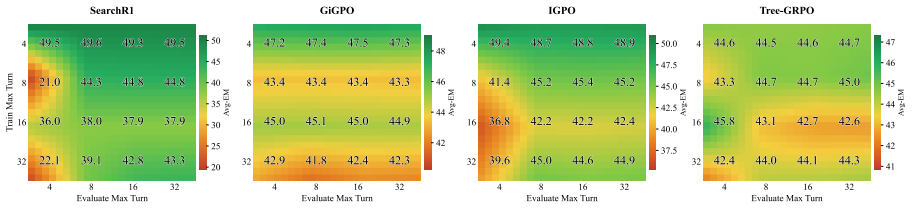
In side-by-side comparisons, correcting the data-coverage issue in the Wikipedia 2018 corpus yields larger gains than the performance differences observed across training algorithms. The simplest outcome-based reward achieves competitive or superior results to process-based alternatives across three base models, and process-level credit assignment can over-correct agent trajectories. Systematic variation of training data diversity, off-policy utilization, and search budget produces practical guidelines for effective search-agent training.
What carries the argument
Controlled empirical comparisons that isolate retrieval corpus quality, outcome versus process reward design, and training-protocol choices (data diversity, off-policy use, search budget) while holding base models constant.
If this is right
- Data corpus coverage is the dominant controllable factor in search agent training performance.
- Outcome-based rewards are sufficient in most settings and process-level supervision is not required.
- Process-level credit assignment risks over-correcting agent behavior.
- Increasing training data diversity and search budget produces predictable improvements.
- Off-policy data can be leveraged without harming final performance.
Where Pith is reading between the lines
- The same coverage gaps may exist in other commonly used retrieval corpora and could be checked with similar audits.
- Development effort may be better spent on corpus curation than on designing new reward functions.
- The relative importance of corpus versus algorithm may shift when base models or domains change.
Load-bearing premise
The controlled comparisons isolate the intended variables without confounding from base-model differences, unmentioned implementation details, or post-hoc data choices.
What would settle it
A replication that applies the identical corpus correction but measures smaller gains relative to algorithm or reward differences, or that finds process rewards consistently superior once implementation details are matched.
Figures
read the original abstract
Search agents powered by large language models can autonomously decompose queries, retrieve information, and synthesize answers through multi-step reasoning. However, the rapid growth of training methods has outpaced controlled comparison: existing works differ in retrieval corpora, reward designs, and training protocols, making it unclear what actually drives improvements. We present a controlled empirical study that isolates three under-explored dimensions of search agent training. First, we identify a critical data-coverage issue in the widely used Wikipedia 2018 corpus and show that correcting it alone yields larger gains than the differences between training algorithms. Second, we systematically compare outcome-based and process-based reward methods across three base models, finding that the simplest outcome-based approach achieves competitive or superior performance in most settings, and that process-level credit assignment can over-correct agent behavior. Third, we analyze training data diversity, off-policy data utilization, and search budget scaling, distilling practical guidelines for training effective search agents. Our code is available at https://github.com/YiboZhao624/SearchAgentReview.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a controlled empirical study isolating three factors in training LLM-based search agents: (1) retrieval corpus quality, claiming that fixing a data-coverage issue in the Wikipedia 2018 corpus produces larger gains than differences among training algorithms; (2) reward design, comparing outcome-based versus process-based rewards across three base models and finding outcome-based methods competitive or superior; and (3) training protocols including data diversity, off-policy utilization, and search budget scaling, from which practical guidelines are distilled. Code is released.
Significance. If the controlled comparisons hold without confounding, the work usefully demonstrates that data-coverage fixes can dominate algorithmic choices and supplies reproducible guidelines plus code for training search agents. The systematic multi-model reward comparison and emphasis on practical training choices add value for the field.
major comments (2)
- [Abstract] Abstract and introduction: the central claim that 'correcting it alone yields larger gains than the differences between training algorithms' is load-bearing but lacks explicit confirmation that the Wikipedia 2018 corpus-correction runs reused the identical base model, reward function, off-policy ratio, search budget, and training protocol as the algorithm ablations. Without this, the delta comparison is potentially confounded by model-specific or hyperparameter effects.
- [Reward and Training sections] The reward comparison section (across three base models) and the training-protocol analysis appear to be run separately; the manuscript must state whether any post-hoc data filtering or hyperparameter adjustments were applied only to the corpus experiment, as this would undermine the 'larger gains' assertion.
minor comments (2)
- [Abstract] The abstract states clear empirical claims but does not reference specific result tables or statistical tests; adding one-sentence pointers to the main result tables would improve readability.
- Minor notation: ensure consistent use of 'outcome-based' versus 'process-based' terminology across figures and text to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The concerns center on ensuring the corpus-correction comparison is fully controlled relative to the algorithm ablations. We address each point below and will revise the manuscript to add the requested explicit statements.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central claim that 'correcting it alone yields larger gains than the differences between training algorithms' is load-bearing but lacks explicit confirmation that the Wikipedia 2018 corpus-correction runs reused the identical base model, reward function, off-policy ratio, search budget, and training protocol as the algorithm ablations. Without this, the delta comparison is potentially confounded by model-specific or hyperparameter effects.
Authors: All corpus-correction runs reused the exact same base model, reward function, off-policy ratio, search budget, and training protocol as the algorithm ablations; the only variable changed was the retrieval corpus. This design choice was made to isolate the data-coverage effect. We agree the abstract and introduction do not state this explicitly and will add a sentence confirming the shared experimental settings for the delta comparison. revision: yes
-
Referee: [Reward and Training sections] The reward comparison section (across three base models) and the training-protocol analysis appear to be run separately; the manuscript must state whether any post-hoc data filtering or hyperparameter adjustments were applied only to the corpus experiment, as this would undermine the 'larger gains' assertion.
Authors: No post-hoc data filtering or hyperparameter adjustments were applied exclusively to the corpus experiment. The reward and training-protocol sections used the same base settings and protocols as the corpus runs (with only the intended variables changed). We will add an explicit statement in the experimental setup section clarifying that all three studies shared the core hyperparameters and that no corpus-specific adjustments were introduced. revision: yes
Circularity Check
No circularity: purely empirical controlled comparisons with no derivations or fitted predictions.
full rationale
The paper performs direct experimental ablations on retrieval corpora, reward methods, and training protocols using multiple base models. No mathematical derivation chain, first-principles predictions, or parameters fitted to one subset then presented as independent predictions exist. All claims reduce to measured performance deltas under stated experimental conditions rather than self-definitional or self-citation reductions. The central data-coverage correction result is an empirical observation, not a constructed prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Wikipedia 2018 corpus contains a critical data-coverage issue whose correction can be performed without introducing new selection biases.
Reference graph
Works this paper leans on
-
[1]
GAIA: a benchmark for General AI Assistants
Gaia: a benchmark for general ai assistants. Preprint, arXiv:2311.12983. OpenAI. 2025. Computer-using agent: Introducing a universal interface for ai to interact with the digital world. Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. 2023. Measuring and narrowing the compositionality gap in language mod- els. InFindings of t...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
Hermes 3 technical report.Preprint, arXiv:2408.11857. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue: Multi- hop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554. Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu...
-
[3]
Adversarial yet cooperative: Multi-perspective reasoning in retrieved-augmented language models. InFindings of the Association for Computational Lin- guistics: ACL 2026, San Diego, USA. Association for Computational Linguistics. Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Mur- ray, and Young Jin Kim. 2024. Con...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Os-symphony: A holistic framework for robust and generalist computer-using agent.arXiv preprint arXiv:2601.07779. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Em...
-
[5]
Embarrassingly Simple Self-Distillation Improves Code Generation
Embarrassingly simple self-distillation im- proves code generation.Preprint, arXiv:2604.01193. Wenlin Zhang, Xiangyang Li, Kuicai Dong, Yichao Wang, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Derong Xu, Zhaocheng Du, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. 2025. Process vs. outcome reward: Which is better for agentic RAG reinforce- ment learning. InThe ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
If you need to call a function, output the function call in the specified XML format
-
[7]
type": "function
When you have enough information to answer, provide your final response as: <answer> [Your concise answer here] </answer> # Important - Do NOT make up information that is not present in the retrieved documents. - Be concise but complete in your final answer. # Tools You may call one or more functions to assist with the user query. You are provided with fu...
-
[8]
If you need to search, output: <search>your query here</search>
-
[9]
- Be concise but complete in your final answer
When you have enough information, provide your final response as: <answer> [Your concise answer here] </answer> # Important - Do NOT make up information that is not present in the retrieved documents. - Be concise but complete in your final answer. user Answer the question based on the search results. Use <search>query</search> to search for information. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.