Reflective Dialogue between Teacher and Solver Agents for Video Question Answering
Pith reviewed 2026-06-29 13:48 UTC · model grok-4.3
The pith
Reflective dialogue between teacher and solver agents generates useful context for video question answering from a small support set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
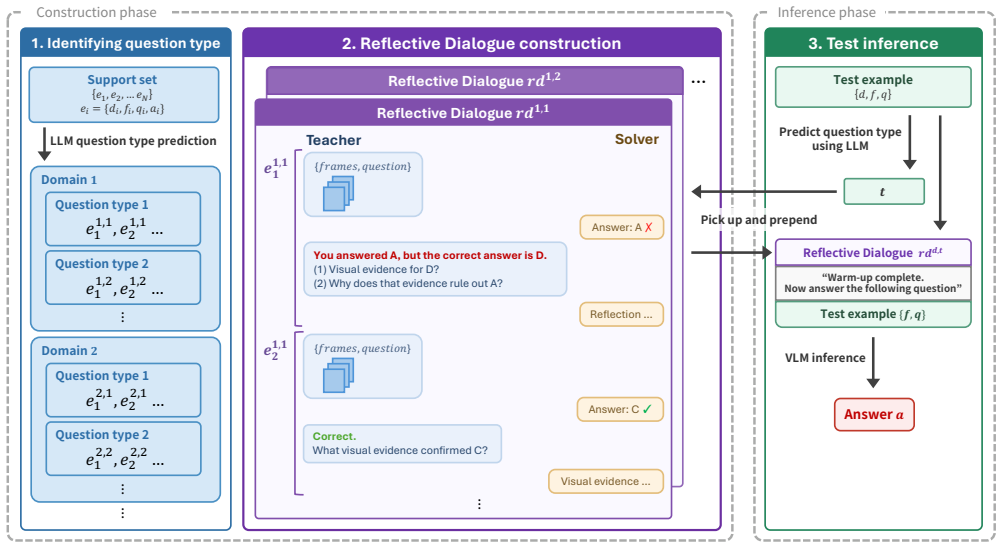
The central claim is that constructing a Reflective Dialogue (RD) from a support set, consisting of multi-turn interactions where the Teacher poses questions and gives correctness feedback and the Solver provides answers with visual explanations, supplies context that enables better performance on unseen test questions in a cross-domain setting compared to standard methods.
What carries the argument
Reflective Dialogue (RD): a multi-turn conversation between Teacher and Solver agents built from the support set, where the Teacher delivers feedback on correctness and the Solver supplies visual grounding explanations.
If this is right
- Using the RD history as inference-time context improves accuracy over zero-shot VLM use on EgoCross.
- RD outperforms passing support examples directly in in-context learning.
- The method achieves competitive results in the Open-source Track of the Cross-Domain EgoCross Challenge.
- Adaptation to specialized domains is possible solely through context injection at inference without model updates.
Where Pith is reading between the lines
- Such reflective dialogues might help in other multimodal tasks where explanations of errors aid generalization.
- Extending the dialogue to include more agent roles could further enrich the context provided.
- The approach assumes the support set is representative enough for cross-domain transfer.
Load-bearing premise
The multi-turn dialogue history generated from the support set provides generalizable context that improves performance on unseen test questions in a cross-domain setting.
What would settle it
If applying the reflective dialogue context on the EgoCross test set does not result in higher accuracy than zero-shot or standard in-context learning, the claim would be falsified.
Figures
read the original abstract
Various approaches have been proposed to adapt Vision-Language Models (VLMs) to specialized domains for Video Question Answering, including fine-tuning and in-context learning. However, acquiring task-specific knowledge at the inference phase from only a small labeled support set without fine-tuning remains a challenge. In this paper, we propose a method that achieves adaptation solely through inference-time context injection. Our method first constructs a Reflective Dialogue (RD) -- a multi-turn conversation between two agents, in which Teacher poses each support question and delivers correctness feedback, and Solver answers and provides visual grounding explanations (or reflections) for both correct and incorrect answers. This dialogue history is then used as context at the inference phase. Experiments on the EgoCross benchmark demonstrate that our method outperforms both a baseline zero-shot setting and a standard in-context learning approach that passes support set examples directly, achieving 3rd place in the Open-source Track of the 1st Cross-Domain EgoCross Challenge at the CVPR 2026 EgoVis Workshop, for which this paper also serves as a technical report.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Reflective Dialogue (RD) construction process for adapting Vision-Language Models to Video Question Answering in cross-domain settings. Two agents interact over a small labeled support set: the Teacher poses each support question and supplies correctness feedback, while the Solver generates answers together with visual-grounding reflections on both correct and incorrect responses. The resulting multi-turn dialogue history is injected as context at inference time. Experiments on the EgoCross benchmark are reported to outperform both zero-shot and standard in-context learning baselines that pass support examples directly, resulting in 3rd place in the Open-source Track of the 1st Cross-Domain EgoCross Challenge.
Significance. If the empirical results hold, the work demonstrates a reproducible, parameter-free inference-time adaptation technique that converts a support set into structured dialogue context rather than raw examples. This is a concrete strength for settings where fine-tuning is unavailable. The explicit agent-interaction protocol and direct baseline comparison are also positive features that could be reused in other VLM adaptation tasks.
major comments (1)
- [Abstract] Abstract: the central empirical claim of outperformance and 3rd-place ranking is stated without any numerical scores, error bars, support-set size, test-set statistics, or ablation results. Because the claim is purely empirical, the absence of these load-bearing details prevents evaluation of effect size or robustness.
Simulated Author's Rebuttal
We thank the referee for their review and constructive feedback on the abstract. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of outperformance and 3rd-place ranking is stated without any numerical scores, error bars, support-set size, test-set statistics, or ablation results. Because the claim is purely empirical, the absence of these load-bearing details prevents evaluation of effect size or robustness.
Authors: We agree that the abstract should contain the key numerical results to allow readers to assess the empirical claims directly. In the revised manuscript we will expand the abstract to report the main accuracy figures on EgoCross (including the improvement over zero-shot and standard in-context learning baselines), the size of the support set, basic test-set statistics, and a brief reference to the ablation studies. These quantities already appear with error bars and full tables in Section 4; the revision will simply surface the most salient numbers in the abstract itself. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a purely empirical method: a reproducible construction of multi-turn Reflective Dialogue from the labeled support set (Teacher feedback + Solver reflections) that is then injected as inference-time context. The central claim is direct benchmark outperformance versus zero-shot and standard in-context baselines on EgoCross, with no equations, fitted parameters, derivations, or load-bearing self-citations. The result is an observed empirical outcome of the described construction process and does not reduce to its inputs by definition or by any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs are capable of generating meaningful visual grounding explanations for both correct and incorrect answers when prompted as the Solver agent.
invented entities (1)
-
Reflective Dialogue (RD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[2]
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma˜nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, M...
-
[3]
Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020. 1, 2
1901
-
[4]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceed- ings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128, 2024. 1
2024
-
[5]
Gemini 3.1 Flash Image Preview, 2025.https:// docs.cloud.google.com/gemini-enterprise- agent-platform/models/gemini/3-1-flash- image
Google. Gemini 3.1 Flash Image Preview, 2025.https:// docs.cloud.google.com/gemini-enterprise- agent-platform/models/gemini/3-1-flash- image. 5
2025
-
[6]
Gemini 3.1 Pro Preview, 2025.https : / / docs.cloud.google.com/gemini-enterprise- agent-platform/models/gemini/3-1-pro
Google. Gemini 3.1 Pro Preview, 2025.https : / / docs.cloud.google.com/gemini-enterprise- agent-platform/models/gemini/3-1-pro. 4
2025
-
[7]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 2 6
2022
-
[8]
Lora: Low-rankadaptationoflargelanguagemodels
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rankadaptationoflargelanguagemodels. InInter- national conference on learning representations, 2021. 5
2021
-
[9]
Videoicl: Confidence-based iter- ative in-context learning for out-of-distribution video under- standing
Kangsan Kim, Geon Park, Youngwan Lee, Woongyeong Yeo, and Sung Ju Hwang. Videoicl: Confidence-based iter- ative in-context learning for out-of-distribution video under- standing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3295–3305, 2025. 2
2025
-
[10]
An image grid can be worth a video: Zero-shot video question answering using a vlm.IEEE Access, 12:193057– 193075, 2024
Wonkyun Kim, Changin Choi, Wonseok Lee, and Wonjong Rhee. An image grid can be worth a video: Zero-shot video question answering using a vlm.IEEE Access, 12:193057– 193075, 2024. 1
2024
-
[11]
Egocross: Benchmarking multimodal large language mod- els for cross-domain egocentric video question answering
Yanjun Li, Yuqian Fu, Tianwen Qian, Qi’Ao Xu, Silong Dai, Danda Pani Paudel, Luc Van Gool, and Xiaoling Wang. Egocross: Benchmarking multimodal large language mod- els for cross-domain egocentric video question answering. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 6592–6600, 2026. 2, 3, 4
2026
-
[12]
Self-refine: It- erative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hal- linan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: It- erative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023. 1, 2
2023
-
[13]
Self-reflection in large language model agents: Effects on problem-solving perfor- mance
Matthew Renze and Erhan Guven. Self-reflection in large language model agents: Effects on problem-solving perfor- mance. In2nd International Conference on Foundation and Large Language Models, FLLM 2024, Dubai, United Arab Emirates, November 26-29, 2024, pages 516–525. IEEE,
2024
-
[14]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural in- formation processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural in- formation processing systems, 36:8634–8652, 2023. 1, 2
2023
-
[15]
Qwen Team. Qwen3-vl technical report.CoRR, abs/2511.21631, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chau- mond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art ...
2020
-
[17]
Activitynet-qa: A dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yuet- ing Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. InProceedings of the AAAI conference on artificial intelli- gence, pages 9127–9134, 2019. 1
2019
-
[18]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15134–15186,
-
[19]
Llamafac- tory: Unified efficient fine-tuning of 100+ language mod- els
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafac- tory: Unified efficient fine-tuning of 100+ language mod- els. InProceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Lin...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.