Towards Unified Vision-Language Models with Incomplete Multi-Modal Inputs
Pith reviewed 2026-06-29 13:37 UTC · model grok-4.3
The pith
A unified model processes video and language inputs even when one modality is missing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
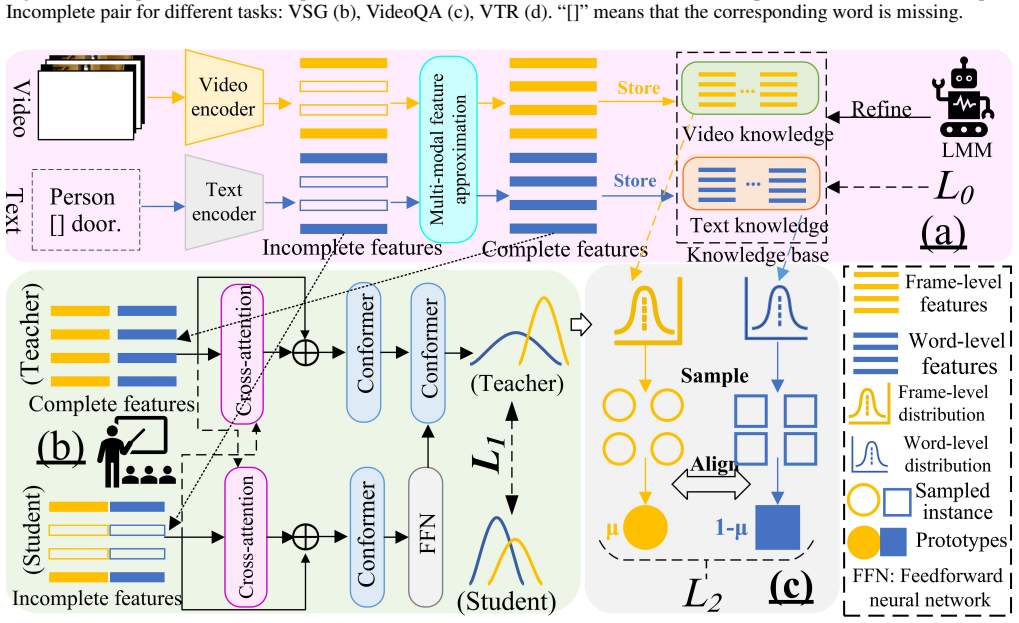
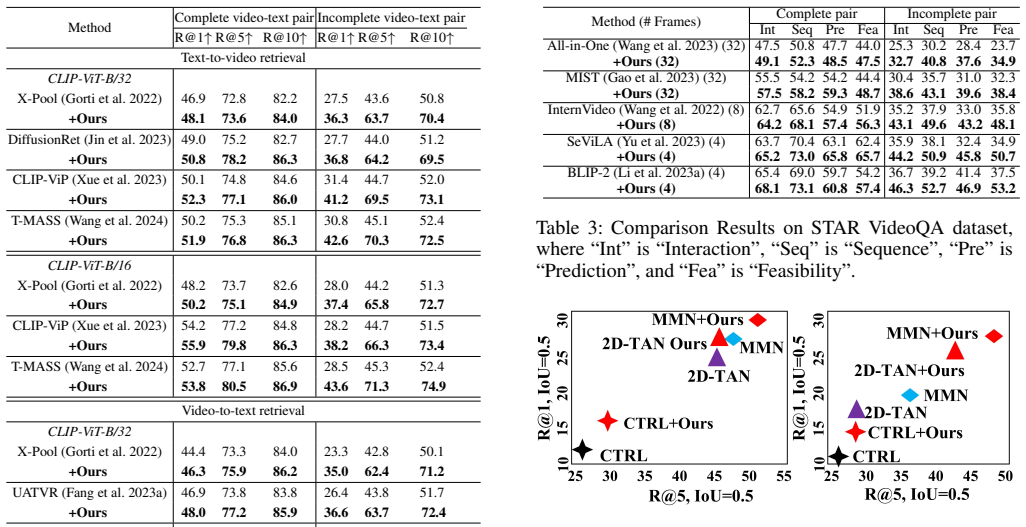
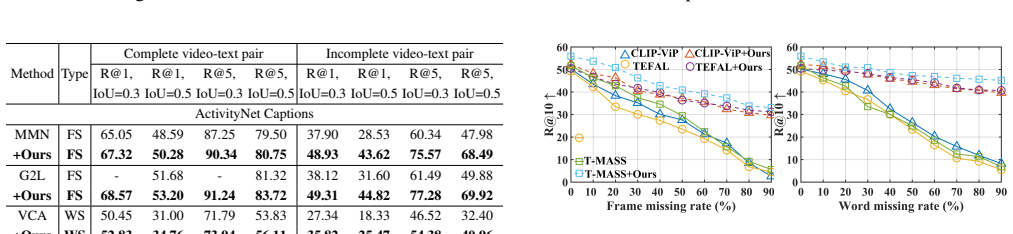
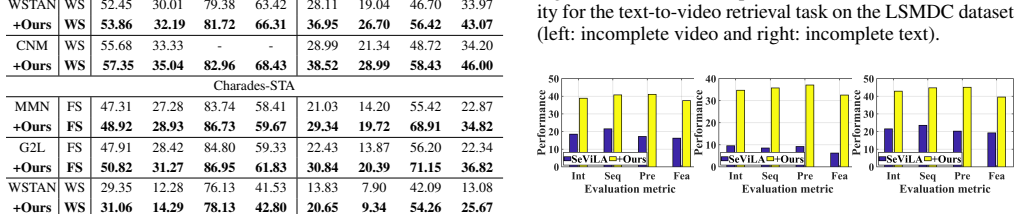
We make the first attempt to propose a unified incomplete video-language model to process the incomplete multi-modal inputs. Extensive experimental results show that our method can serve as a plug-and-play module for previous works to improve their performance in various multi-modal tasks.
What carries the argument
The unified incomplete video-language model, an architecture built to accept and reason over missing video or language inputs by design.
If this is right
- Existing video-language models gain improved results on multi-modal tasks when the proposed module is added.
- Training and testing remain consistent even when sensors are unavailable.
- Safety and trustworthiness risks from modality-incomplete data are reduced.
- The same model can be reused across different video-language applications without task-specific redesign.
Where Pith is reading between the lines
- The same design pattern could be tested on other modality pairs such as audio-text or image-text to check if incompleteness handling generalizes.
- Deployment in privacy-sensitive settings would benefit from explicit checks that the model does not leak information from the available modality.
- Future models might be trained from the start with random modality dropout to make robustness the default rather than an add-on.
Load-bearing premise
A single unified architecture can be trained on incomplete inputs without causing generalization failure or inconsistency between training and testing distributions.
What would settle it
Running the proposed module on existing video-language models with real or simulated missing modalities and finding no performance gain on downstream tasks would falsify the central claim.
Figures

read the original abstract
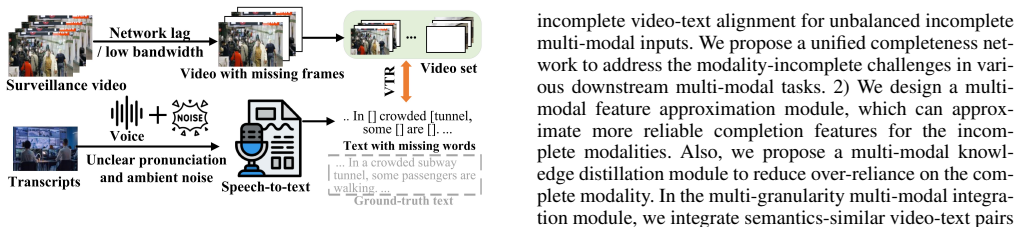
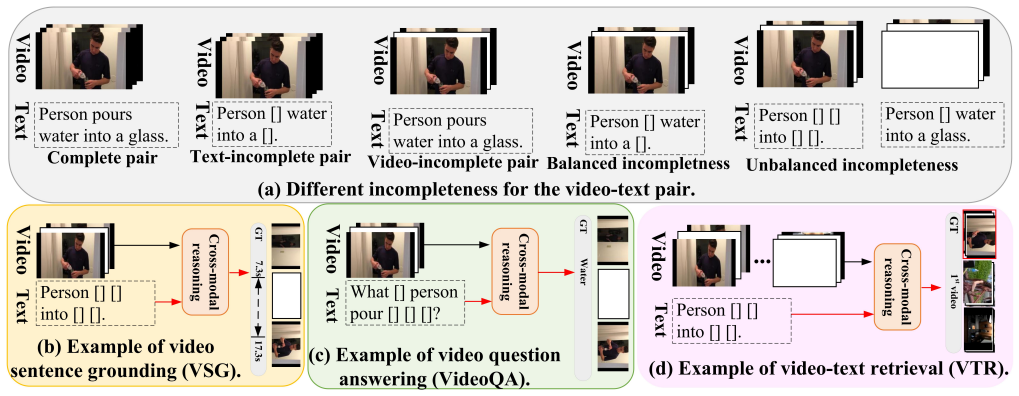
Video-Language Models (VLMs) have demonstrated impressive multi-modal reasoning capabilities across diverse computer vision applications. However, these VLMs are task-specific and assume that both video and language inputs are complete. However, real-world VLM applications might face challenges due to deactivated sensors (e.g., cameras are unavailable due to data privacy), yielding modality-incomplete data and leading to inconsistency between training and testing data. While straightforward incomplete input can boast training generalization-ability and lead to training failure, its potential risks to VLMs regarding safety and trustworthiness have been largely neglected. To this end, we make the first attempt to propose a unified incomplete video-language model to process the incomplete multi-modal inputs. Extensive experimental results show that our method can serve as a plug-and-play module for previous works to improve their performance in various multi-modal tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to make the first attempt at a unified incomplete video-language model (VLM) that processes modality-incomplete inputs (e.g., due to deactivated sensors), addressing training-testing inconsistency and safety risks in existing task-specific VLMs. It further asserts that extensive experimental results demonstrate the method can act as a plug-and-play module to improve prior works across various multi-modal tasks.
Significance. If substantiated, the work would address a practical gap in VLM deployment under real-world incomplete data conditions. However, the manuscript supplies no architecture, training objective, datasets, baselines, or quantitative results, so the significance cannot be evaluated from the provided text.
major comments (1)
- Abstract: The central claim that 'extensive experimental results show that our method can serve as a plug-and-play module... to improve their performance' is unsupported, as the manuscript contains no methods section, no datasets, no baselines, no tables/figures with metrics, and no quantitative evidence whatsoever. This renders the performance-improvement assertion unverifiable and load-bearing for the paper's contribution.
Simulated Author's Rebuttal
We thank the referee for identifying the critical gap in our submission. We acknowledge that the current manuscript text does not contain the required methods, datasets, baselines, or results sections to support the abstract's claims.
read point-by-point responses
-
Referee: Abstract: The central claim that 'extensive experimental results show that our method can serve as a plug-and-play module... to improve their performance' is unsupported, as the manuscript contains no methods section, no datasets, no baselines, no tables/figures with metrics, and no quantitative evidence whatsoever. This renders the performance-improvement assertion unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the referee's observation is accurate: the submitted manuscript provides only the abstract and lacks any architecture description, training objectives, datasets, baselines, or quantitative results. The claim of 'extensive experimental results' is therefore unsupported in the current version. We will revise the manuscript to include a complete methods section, experimental setup, datasets, baselines, and results tables/figures before resubmission. revision: yes
Circularity Check
No significant circularity: no equations, derivations, or fitted quantities present
full rationale
The provided abstract and description contain no mathematical derivations, equations, parameters fitted to data, or self-citations that could form a load-bearing chain. The paper proposes a unified model for incomplete multi-modal inputs and claims experimental gains as a plug-and-play module, but supplies no technical steps (e.g., training objectives, architecture equations, or uniqueness theorems) that could reduce to their own inputs by construction. This matches the default expectation of no circularity when the work is self-contained against external benchmarks and lacks any derivation chain to inspect.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Double Self-weighted Multi-view Clustering via Adaptive View Fusion
Imperceptible Beam-Sensitive Adversarial Attacks for LiDAR-based Object Detection in Autonomous Driving. In2025 IEEE International Conference on Multimedia and Expo (ICME), 1–6. IEEE. Cai, X.; Liu, D.; Qu, X.; Fang, X.; Dong, J.; Tang, K.; Zhou, P.; Sun, L.; and Hu, W. 2026. Towards building model/prompt-transferable attackers against large vision- langua...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14773–14783
MIST: Multi-modal Iterative Spatial-Temporal Trans- former for Long-form Video Question Answering. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14773–14783. Gao, J.; Sun, C.; Yang, Z.; and Nevatia, R. 2017. Tall: Tem- poral activity localization via language query. InProceed- ings of the IEEE International Confere...
-
[3]
Dynamic Graph-enhanced Event Refinement for Tem- poral Sentence Grounding of Micro-moments.IEEE Trans- actions on Multimedia. Lei, H.; Cai, X.; Liu, D.; Fang, X.; Qu, X.; Dong, J.; Yu, J.; and Jin, K. 2025. Exploring Disentangled Appearance- Motion Contexts for Temporal Activity Localization. In 2025 International Joint Conference on Neural Networks (IJCN...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Ma, M.; Ren, J.; Zhao, L.; Testuggine, D.; and Peng, X
Use what you have: Video retrieval using rep- resentations from collaborative experts.arXiv preprint arXiv:1907.13487. Ma, M.; Ren, J.; Zhao, L.; Testuggine, D.; and Peng, X
-
[5]
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Are Multimodal Transformers Robust to Missing Modality? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18177–18186. McKinzie, B.; Shankar, V .; Cheng, J. Y .; Yang, Y .; Shlens, J.; and Toshev, A. T. 2023. Robustness in multimodal learning under train-test modality mismatch. InInternational Con- ference on Machine Lea...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Star: A benchmark for situated reasoning in real- world videos. InThirty-fifth Conference on Neural Infor- mation Processing Systems Datasets and Benchmarks Track (Round 2). Xiao, J.; Shang, X.; Yao, A.; and Chua, T.-S. 2021. Next- qa: Next phase of question-answering to explaining tempo- ral actions. InProceedings of the IEEE/CVF conference on computer v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.