A Unified Framework for the Evaluation of LLM Agentic Capabilities
Pith reviewed 2026-06-29 13:12 UTC · model grok-4.3
The pith
A unified framework standardizes LLM agent benchmarks to separate model capabilities from scaffold and environment effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By placing benchmarks into a standardized format, executing agents via a single ReAct-style architecture in a sandbox, and offering an offline snapshot option, the framework shows that scaffold choice and environmental volatility materially shift benchmark outcomes in both directions and thereby disentangles intrinsic LLM capabilities from framework- and environment-induced artifacts.
What carries the argument
The unified configuration system that converts benchmarks into a standardized instruction-tool-environment format and executes them via a fixed ReAct-style architecture inside a controllable sandbox.
If this is right
- Benchmark outcomes on the same models vary substantially when the scaffold is altered.
- Switching between live environments and curated snapshots changes results in both directions.
- Unified metrics for resource consumption and a decision- and execution-level failure taxonomy apply across originally separate benchmarks.
- The framework can serve as a secure testbed for safety-critical agent scenarios.
- Cross-benchmark comparisons become interpretable as measurements of underlying model capabilities rather than joint model-plus-implementation effects.
Where Pith is reading between the lines
- Leaderboards built on this framework could produce more stable model rankings over successive releases.
- Researchers could adopt the offline snapshots to lower evaluation cost and variance without losing the ability to study volatility effects.
- Models whose performance is highly scaffold-dependent could be flagged for further targeted study.
- The failure taxonomy could be extended to additional error categories to diagnose specific capability gaps.
Load-bearing premise
That running all agents through one fixed ReAct-style architecture inside the standardized format provides a neutral measurement of the underlying LLM without introducing its own systematic biases or limitations on what capabilities can be expressed.
What would settle it
A replication study in which changing the scaffold or switching between live and snapshot environments produces no material difference in outcomes across the same models and tasks would falsify the claim that these factors shift benchmark results.
Figures


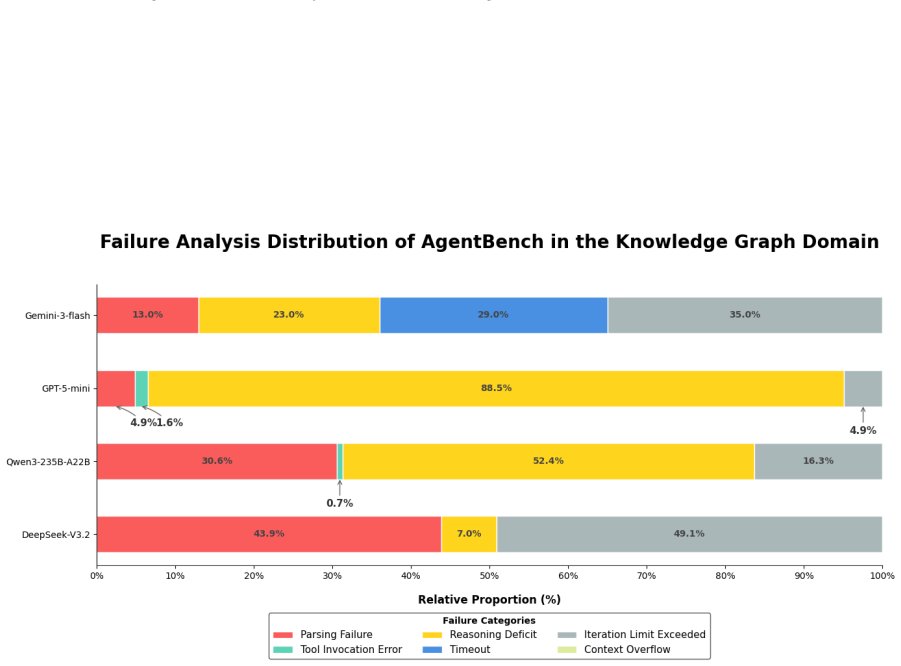
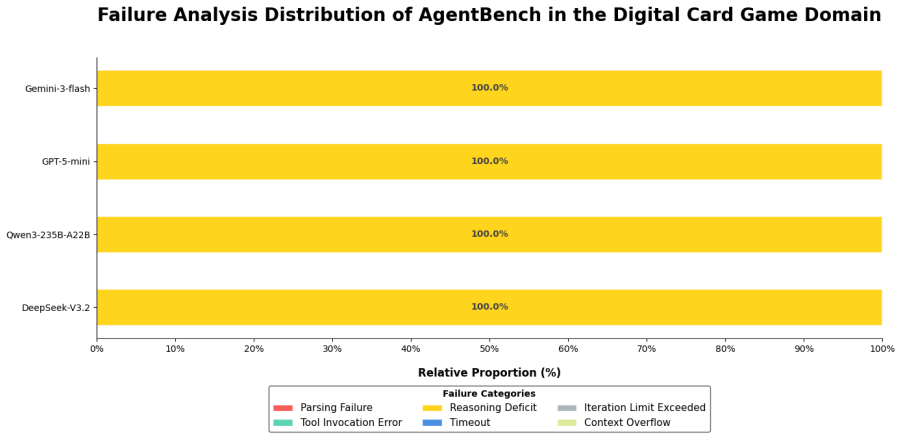
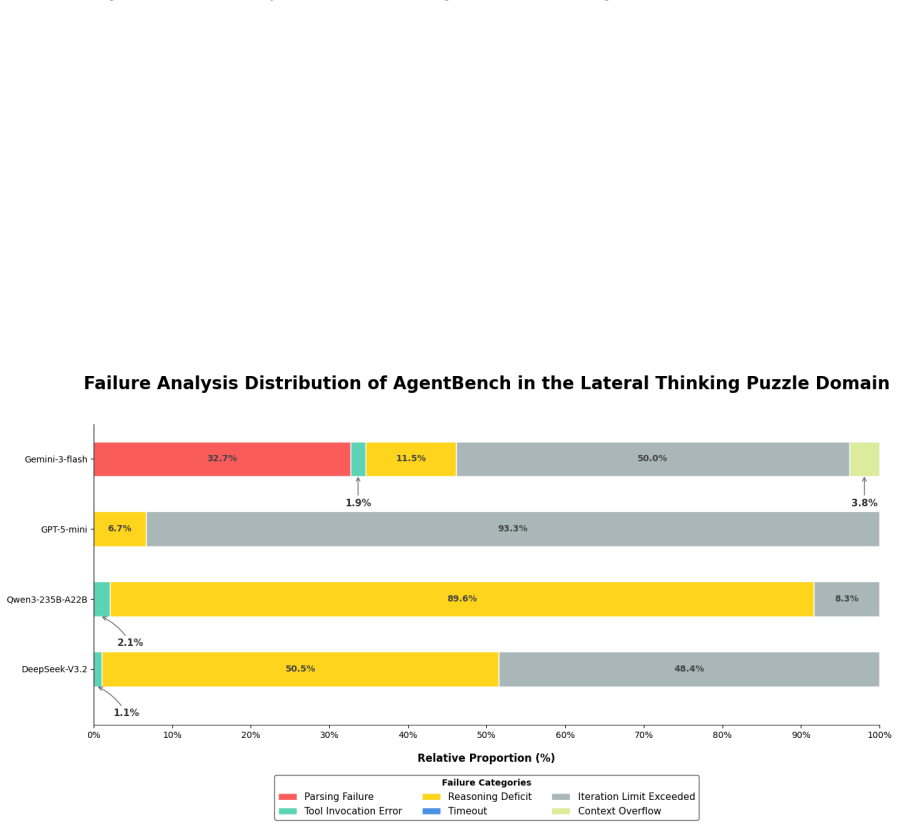
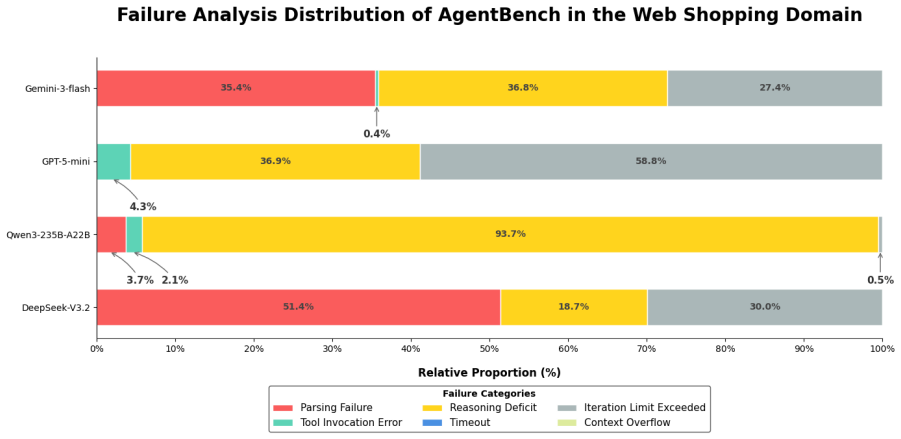
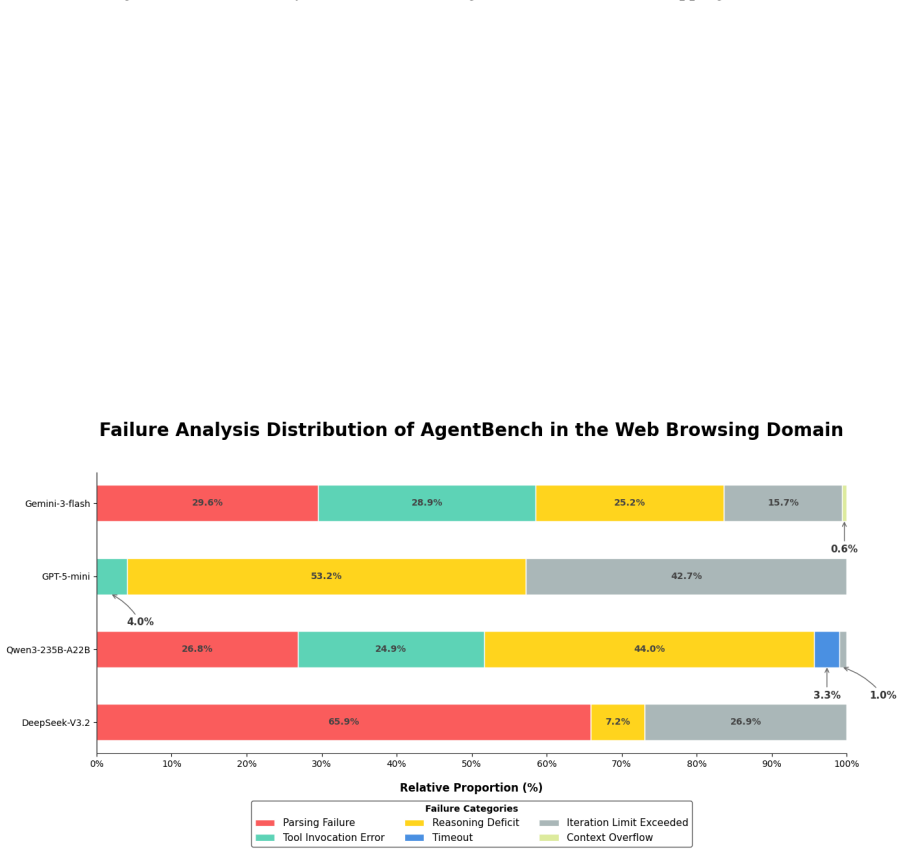
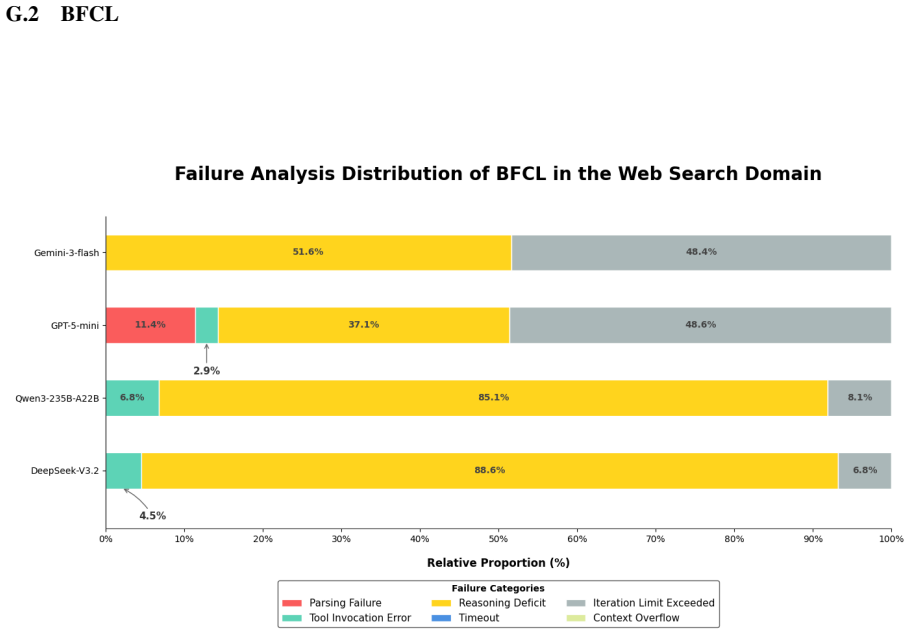
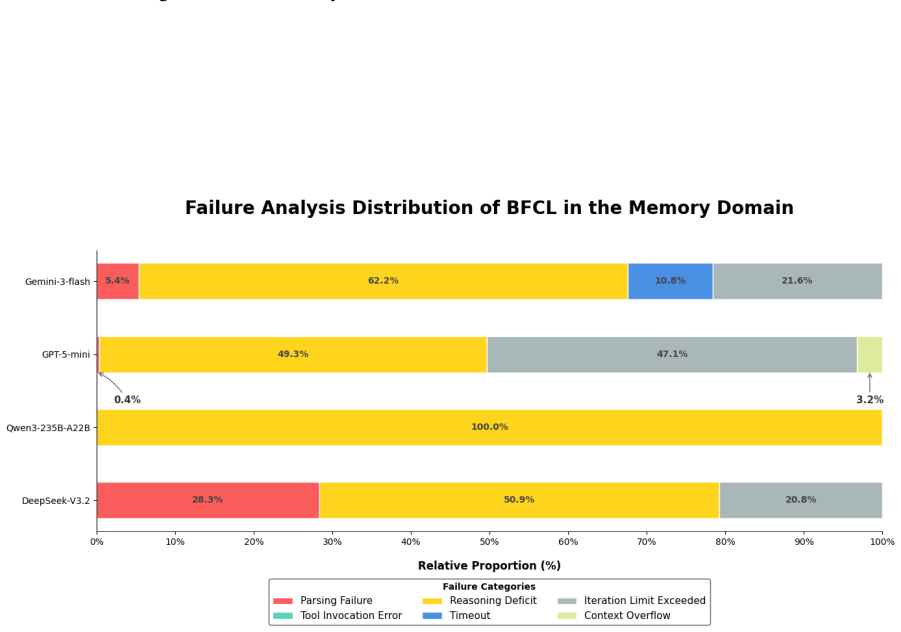
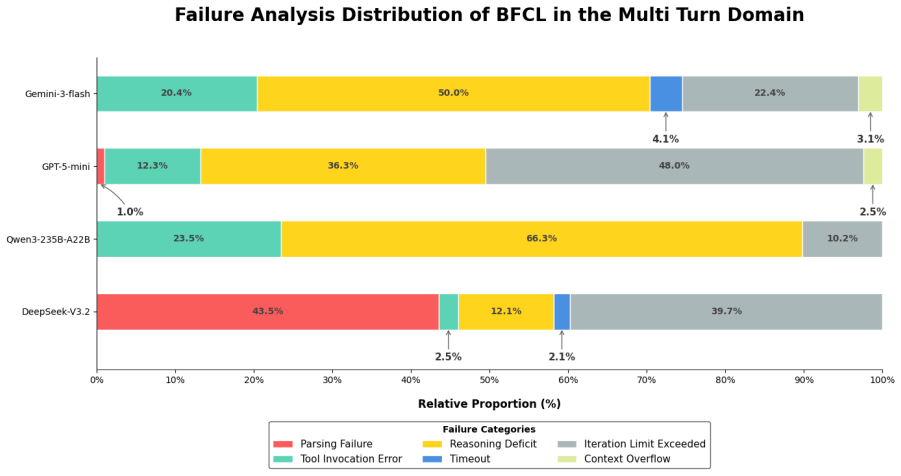
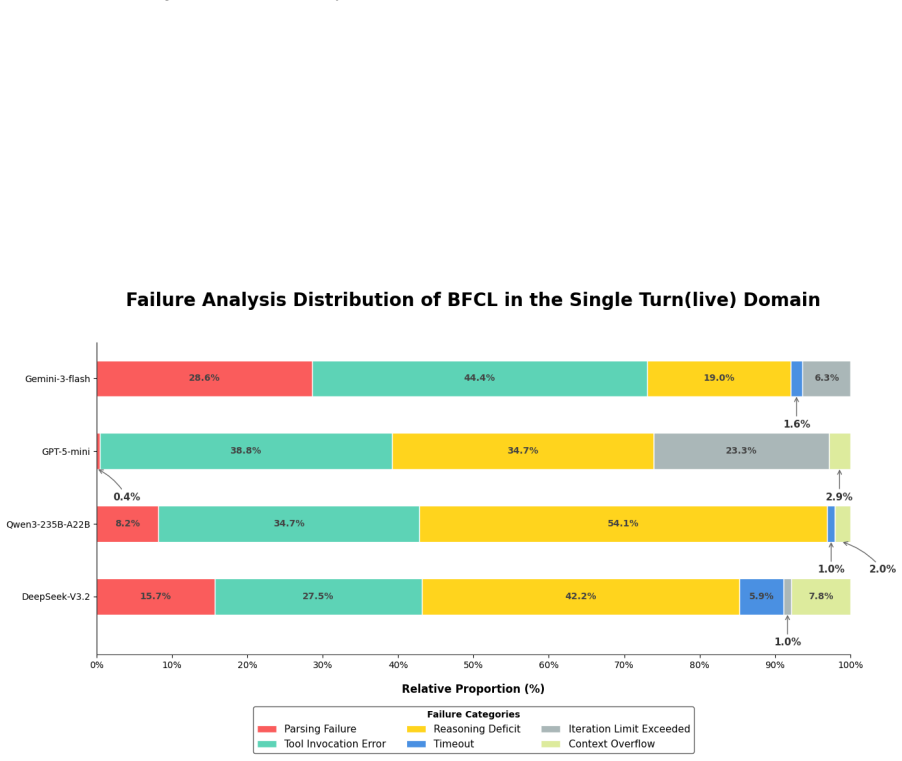
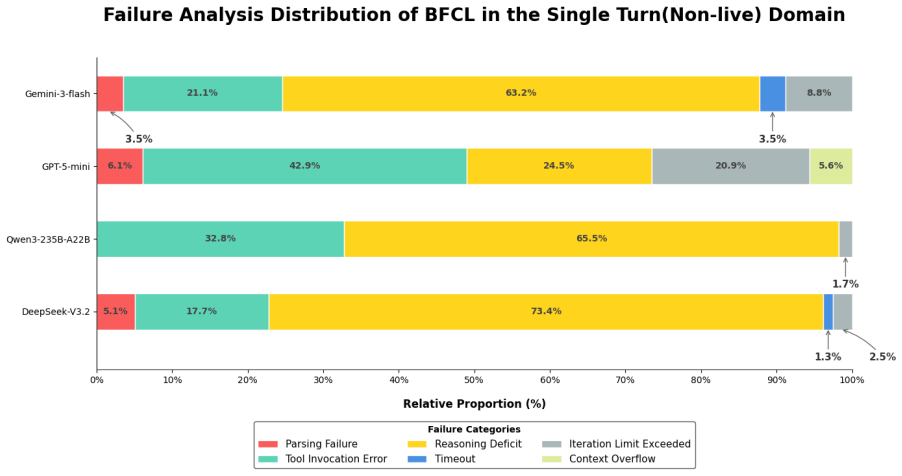
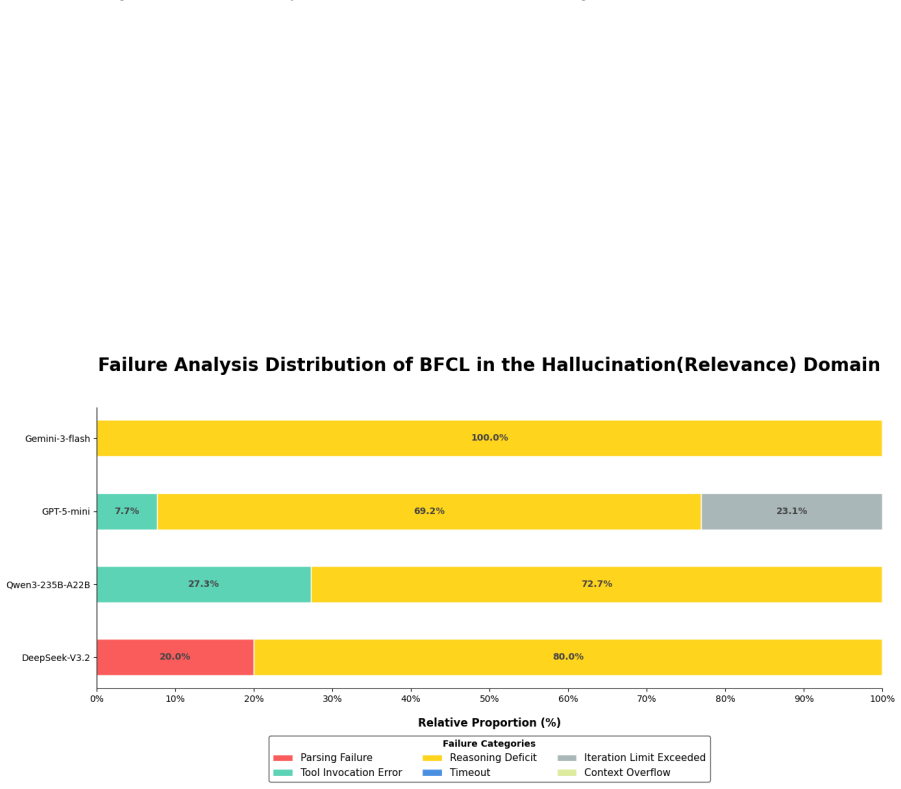
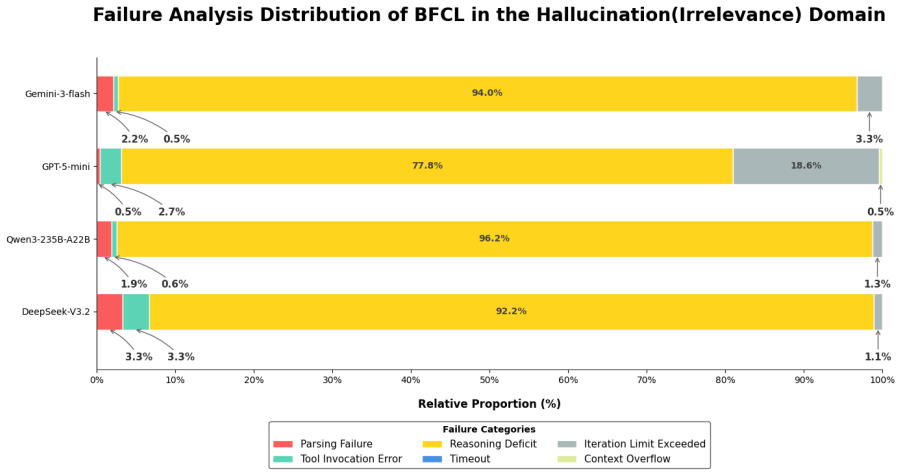
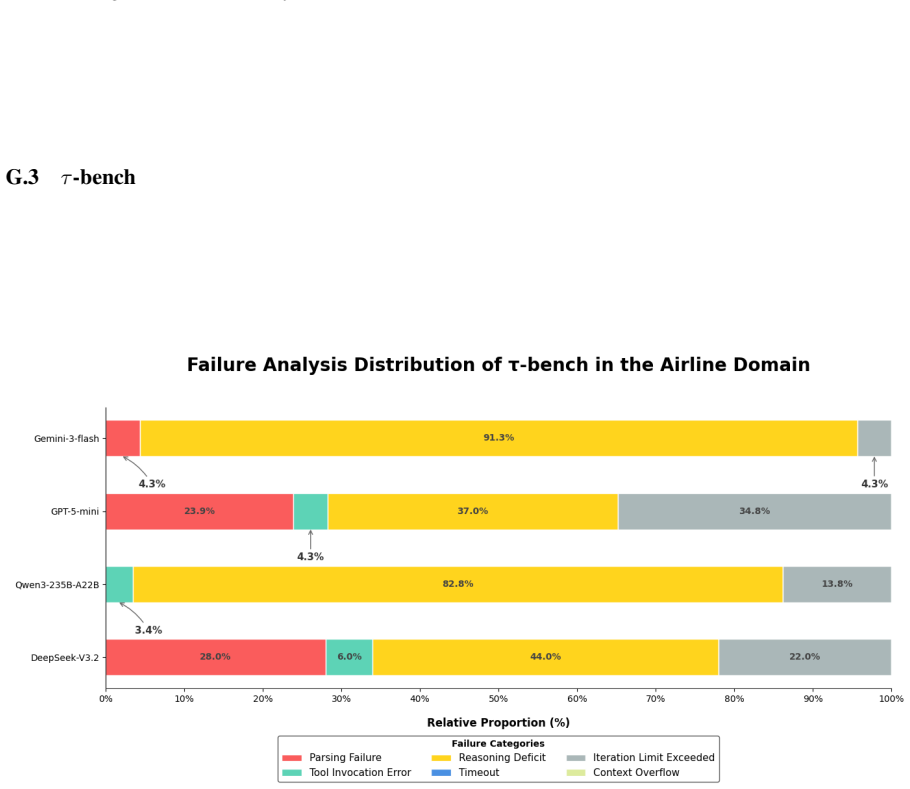
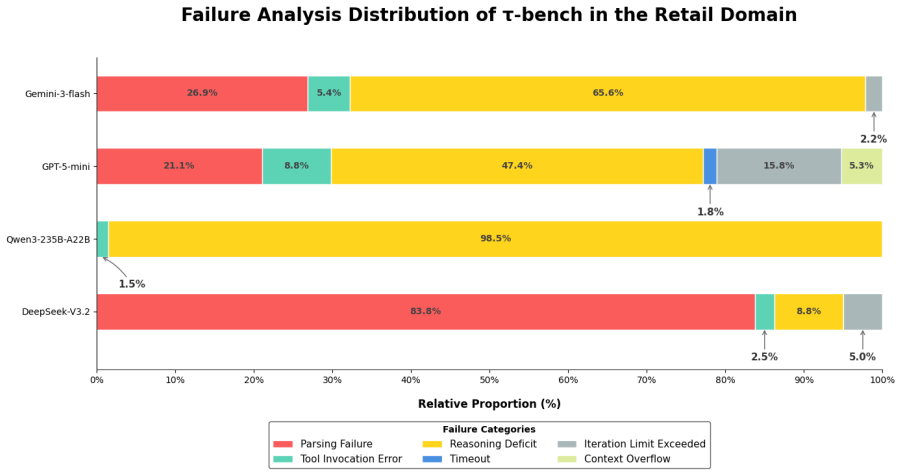
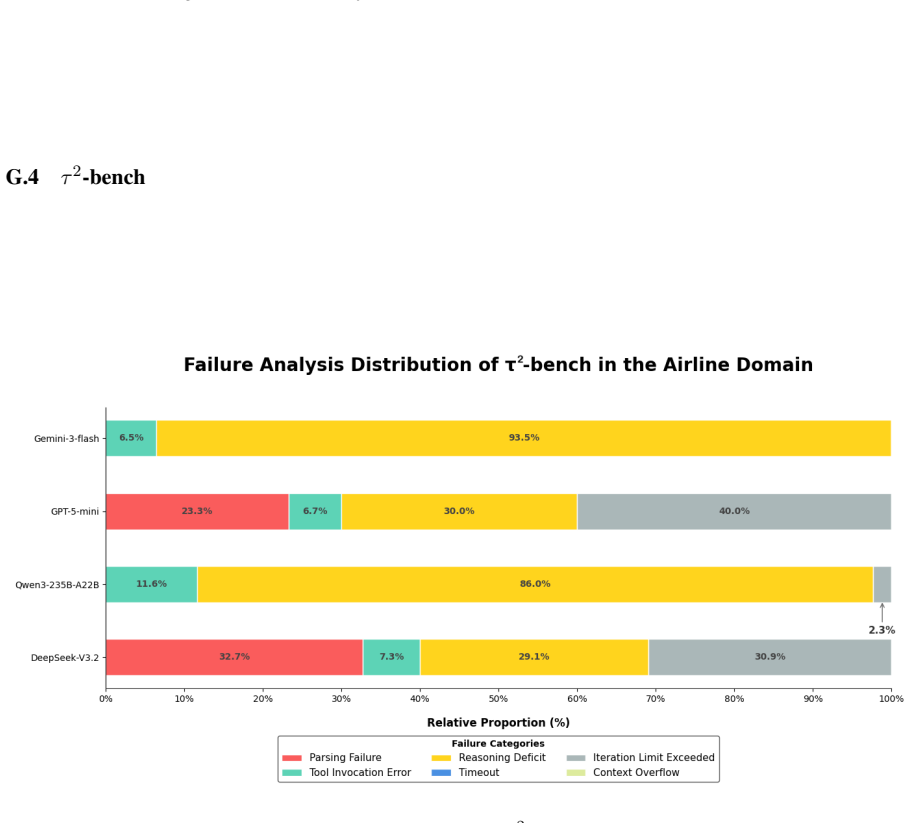
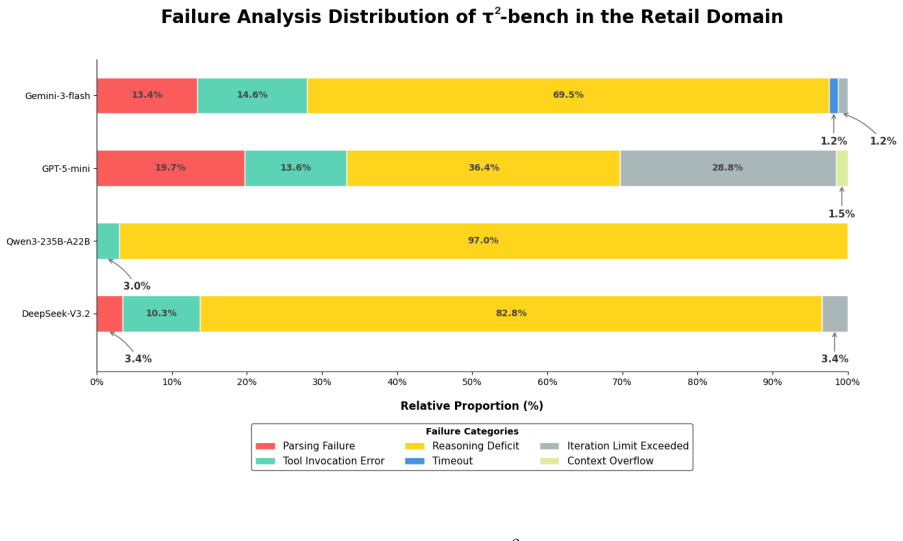
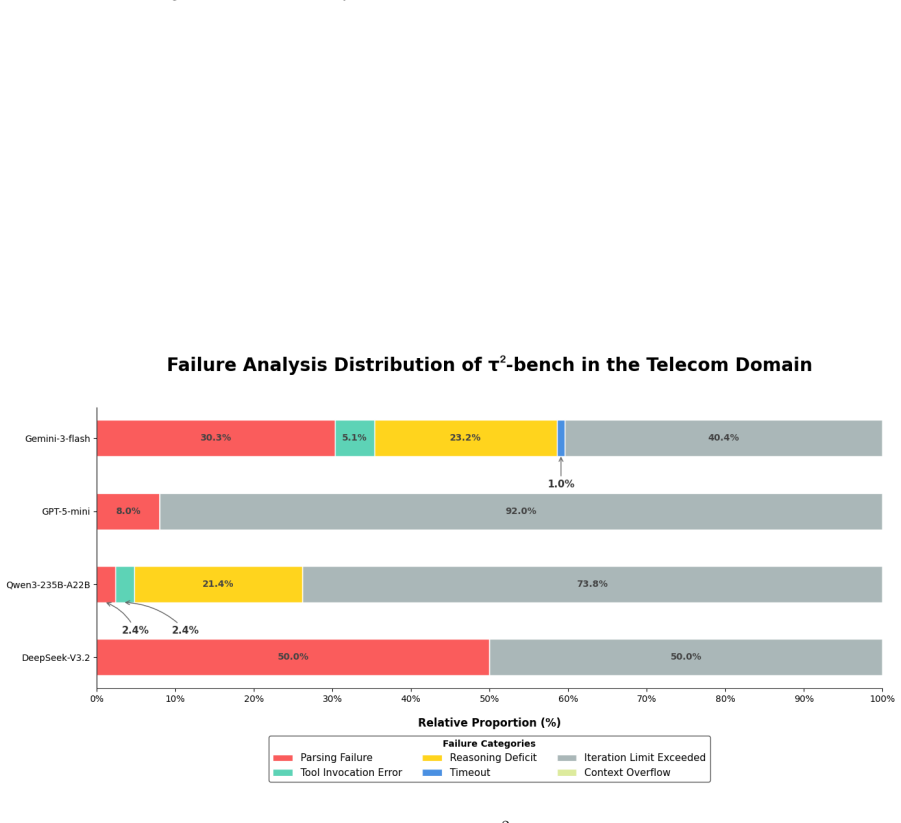
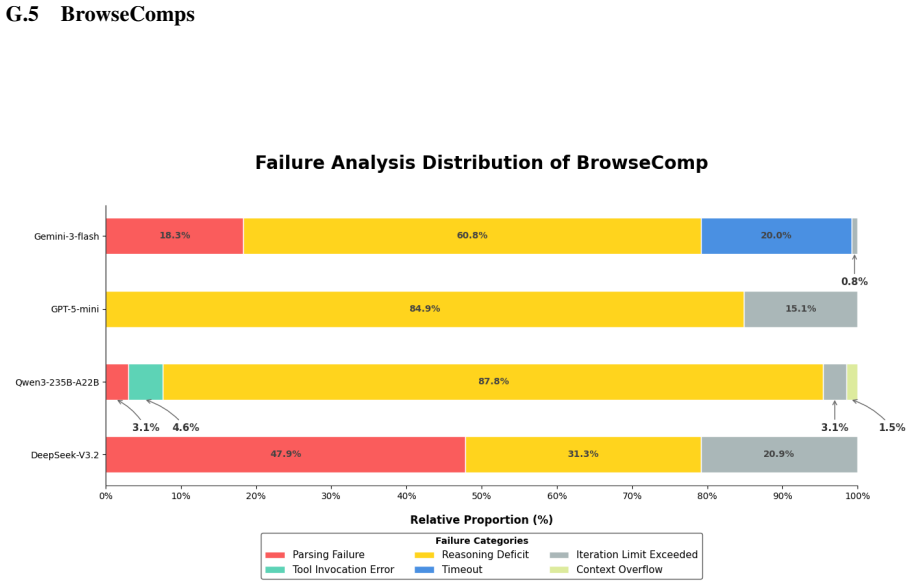
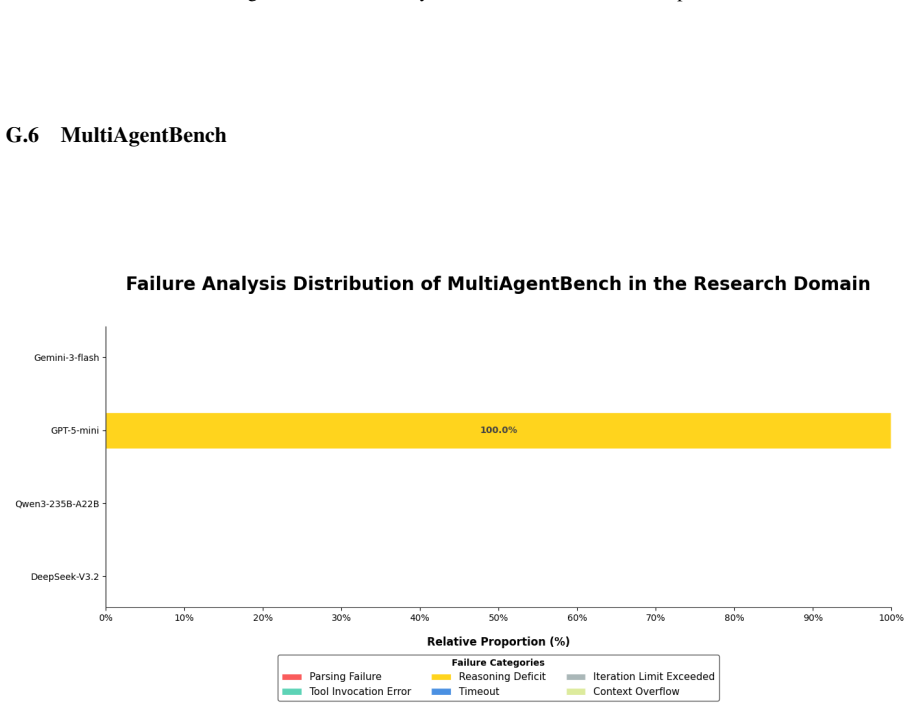
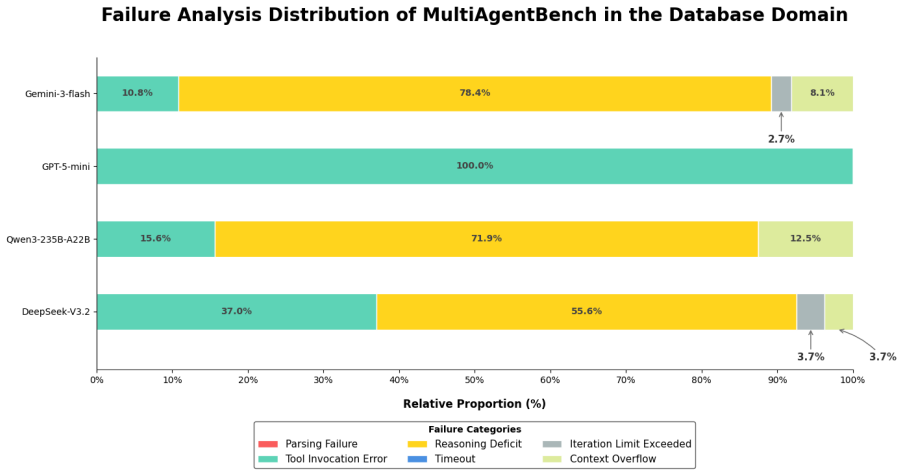

read the original abstract
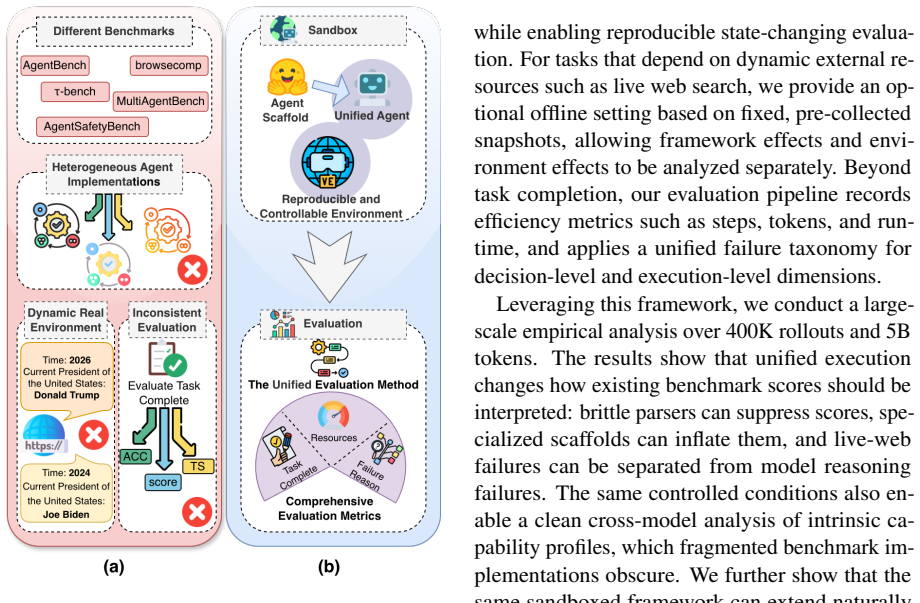
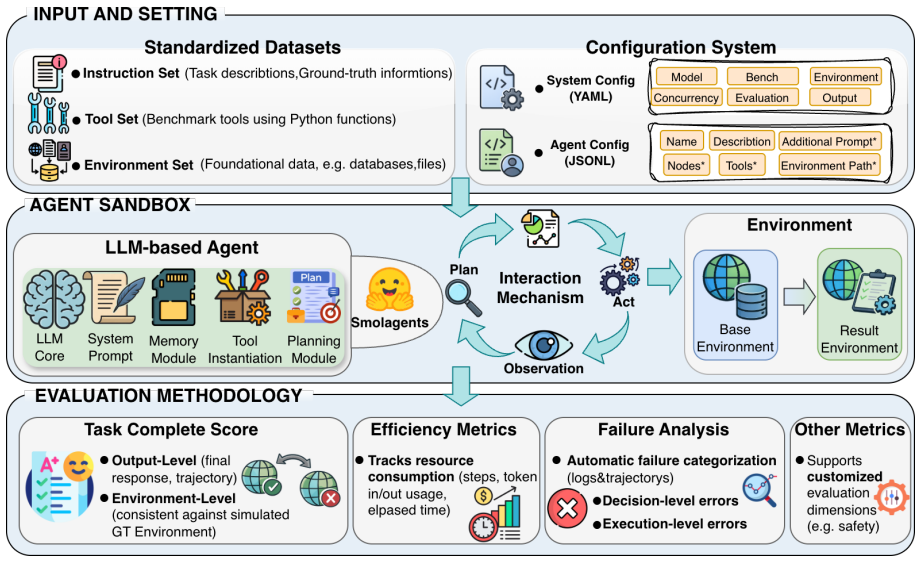
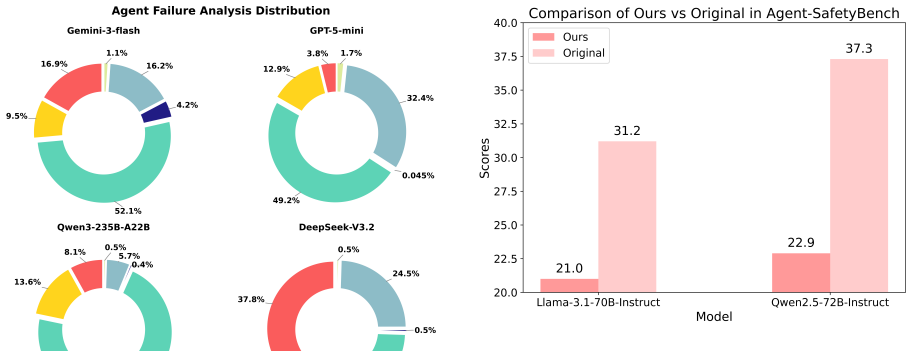
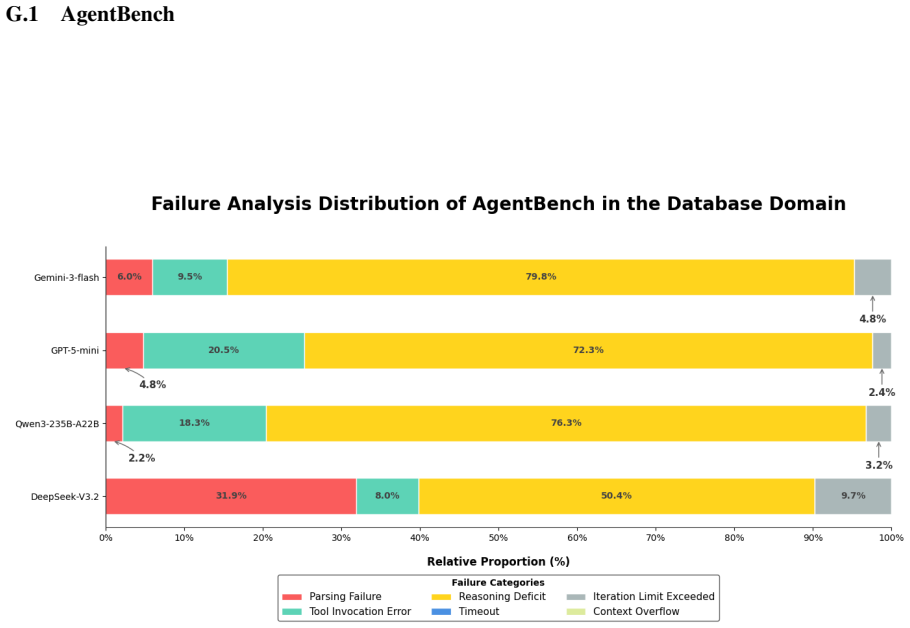
As LLMs are increasingly deployed as agents, reliable assessment of their agentic capabilities has become essential. However, reported benchmark scores often jointly reflect model capability and the implementation choices each benchmark is packaged with, making cross-benchmark results difficult to interpret as clean measurements of the underlying model. In this work, we present a unified framework for the fair evaluation of LLM agentic capabilities. Driven by a unified configuration system, the framework integrates diverse benchmarks into a standardized instruction--tool--environment format, executes agents through a fixed ReAct-style architecture within a controllable sandbox, and provides an optional offline setting that replaces volatile live environments with curated snapshots, so that framework effects and environment effects can be analyzed separately. Building on this, we unify the evaluation methodology under each benchmark's original task-success criteria, while introducing unified metrics for resource consumption and a taxonomy for decision- and execution-level failure attribution. Within this framework, we adapt 7 widely used benchmarks spanning 24 domains across single-agent, multi-agent, and safety-critical scenarios, and conduct a large-scale empirical analysis over 400K rollouts and 5B tokens on 15 models. The results show that scaffold choice and environmental volatility materially shift benchmark outcomes in both directions, allowing our framework to disentangle intrinsic LLM capabilities from framework- and environment-induced artifacts. We further demonstrate its extensibility as a secure testbed for safety-critical domains. Codes and benchmarks at are available at https://github.com/whfeLingYu/A-Unified-Framework-for-the-Evaluation-of-LLM-Agentic-Capabilities, https://huggingface.co/AgentFramework/Unified_Farmework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a unified framework for evaluating LLM agentic capabilities. It standardizes diverse benchmarks into a common instruction-tool-environment format, executes agents via a fixed ReAct-style architecture inside a controllable sandbox (with an optional offline mode using curated snapshots to isolate environment volatility), unifies evaluation under each benchmark's original task-success criteria, and adds metrics for resource consumption plus a taxonomy for decision- and execution-level failure attribution. The framework is applied to 7 benchmarks spanning 24 domains (single-agent, multi-agent, and safety-critical), with large-scale experiments involving 400K rollouts and 5B tokens across 15 models; results indicate that scaffold choice and environmental volatility shift outcomes in both directions, purportedly enabling disentanglement of intrinsic LLM capabilities from framework- and environment-induced artifacts. Code and adapted benchmarks are released publicly.
Significance. If the disentanglement claim holds after addressing the noted concerns, the work would be significant for LLM agent evaluation by providing a controlled testbed that separates model-intrinsic factors from implementation and environment confounds, a persistent issue in the field. The scale of the empirical study, public code release, and demonstrated extensibility to safety-critical domains are concrete strengths that enhance reproducibility and potential adoption.
major comments (2)
- [Abstract] Abstract: The headline claim that the framework disentangles intrinsic LLM capabilities from framework-induced artifacts rests on the assumption that the fixed ReAct-style execution loop provides a neutral measurement. No evidence is presented that this architecture does not impose systematic ceilings or biases (e.g., on capabilities requiring non-observe-think-act planning or memory patterns), which would make the unified measurements specific to ReAct rather than intrinsic.
- [Abstract] Abstract: While the manuscript reports that scaffold choice shifts outcomes (supporting analysis of framework effects), the primary unified measurements and 400K-rollout results are obtained under the single fixed ReAct-style architecture; the disentanglement interpretation therefore requires explicit justification or additional controls showing that ReAct does not differentially suppress capabilities across the 15 models relative to the broader space of agent scaffolds.
minor comments (2)
- [Abstract] Typo in the provided Hugging Face link: 'Unified_Farmework' should read 'Unified_Framework'.
- The taxonomy for decision- and execution-level failure attribution is introduced but would benefit from a concrete example of how attributions are assigned in practice under the unified metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the disentanglement claim. The points raised are substantive and we respond to each below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that the framework disentangles intrinsic LLM capabilities from framework-induced artifacts rests on the assumption that the fixed ReAct-style execution loop provides a neutral measurement. No evidence is presented that this architecture does not impose systematic ceilings or biases (e.g., on capabilities requiring non-observe-think-act planning or memory patterns), which would make the unified measurements specific to ReAct rather than intrinsic.
Authors: We agree that the fixed ReAct-style execution loop may introduce systematic biases or ceilings for capabilities outside the observe-think-act pattern, and the manuscript presents no direct evidence that ReAct is neutral across all agentic behaviors. The framework was designed to be scaffold-agnostic, and we already include experiments demonstrating that scaffold choice shifts outcomes. We will revise the abstract and add a dedicated limitations paragraph to clarify that the primary measurements are obtained under a standardized ReAct-style scaffold, that the reported disentanglement applies to environment volatility while holding the scaffold fixed, and that the framework supports substitution of other scaffolds. These changes will be made in the revision. revision: yes
-
Referee: [Abstract] Abstract: While the manuscript reports that scaffold choice shifts outcomes (supporting analysis of framework effects), the primary unified measurements and 400K-rollout results are obtained under the single fixed ReAct-style architecture; the disentanglement interpretation therefore requires explicit justification or additional controls showing that ReAct does not differentially suppress capabilities across the 15 models relative to the broader space of agent scaffolds.
Authors: The 400K-rollout results use a single fixed ReAct-style architecture to maintain a consistent protocol across 7 benchmarks and 15 models. Separate experiments already quantify the effect of scaffold variation. We acknowledge that these experiments do not fully demonstrate the absence of differential suppression across models. In the revision we will add explicit text in the abstract and discussion sections stating that the current disentanglement isolates environment effects under a fixed scaffold, that scaffold-induced variation is reported separately, and that users of the framework can substitute alternative scaffolds for further controls. No new large-scale runs are planned for this revision, but the added discussion will qualify the interpretation accordingly. revision: yes
Circularity Check
No circularity: framework and metrics defined independently; empirical results from external benchmarks.
full rationale
The paper introduces a configuration-driven standardization of existing benchmarks into an instruction-tool-environment format, executes them via a fixed ReAct-style loop, and reports outcomes under original task-success criteria plus new resource and failure metrics. These steps are definitional and do not reduce any reported effect (scaffold or volatility shifts) to a fitted parameter or self-citation chain. All quantitative claims derive from 400K rollouts on 15 models across 7 external benchmarks; no equations equate predictions to inputs by construction, and no load-bearing uniqueness theorems or ansatzes are invoked from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A fixed ReAct-style architecture provides a neutral and representative execution substrate for comparing underlying LLM capabilities across benchmarks.
invented entities (1)
-
Taxonomy for decision- and execution-level failure attribution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of large language mod- els.ACM Trans. Intell. Syst. Technol., 15(3). Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Sahel Sharifymoghaddam, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Hosna Oyarhoseini, Nandan Thakur, Crystina Zhang, Luyu Gao, and 2 others...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
In The Twelfth International Conference on Learning Representations
Agentbench: Evaluating LLMs as agents. In The Twelfth International Conference on Learning Representations. Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Jun- wei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, and 7 others
-
[3]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Large language model agent: A survey on methodology, applications and challenges.Preprint, arXiv:2503.21460. Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. 2024. Agentboard: An an- alytical evaluation board of multi-turn llm agents. Preprint, arXiv:2401.13178. Grégoire Mialon, Roberto ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
‘smolagents‘: a smol library to build great agentic systems. https://github.com/ huggingface/smolagents. Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, Ak- shay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitco...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Agent-safetybench: Evaluating the safety of llm agents.Preprint, arXiv:2412.14470. Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Gra- ham Neubig. 2024. Webarena: A realistic web en- vironment for building autonomous agents. InThe Twelfth International Conferen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
The Necessity of a Unified Framework for LLM-Based Agent Evaluation
MultiAgentBench : Evaluating the collabora- tion and competition of LLM agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8580–8622, Vienna, Austria. Association for Computational Linguistics. Pengyu Zhu, Li Sun, Philip S. Yu, and Sen Su. 2026. The necessity of a unified framew...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
task_id": 1,
operationalize these capabilities by inter- leaving reasoning traces with environment actions, while multi-agent frameworks further extend them through communication, role specialization, and collaborative problem solving (Wu et al., 2023; Tang et al., 2024). Agent Benchmarks and Evaluation Frame- works.A variety of benchmarks have been pro- posed to eval...
2023
-
[8]
Which team won the 2022 World Cup?
stabilized the benchmark by creating static snapshots of web content. Analysis of this static corpus revealed that a substantial portion of the original tasks had become unsolvable due to URL expiration (link rot) or content updates. Drawing inspiration from BrowseComp-Plus, we migrated the BrowseComp benchmark into a fully local, deterministic environmen...
2022
-
[9]
Hit Identification:All occurrences of the query tokens within the document are identi- fied
-
[10]
Cluster Optimization:We employ a slid- ing window approach (Two Pointers algo- rithm) to identify the variable-length segment [start, end] that maximizes the number of query term "hits" such that (end−start)≤ Lmax, where Lmax is the maximum snippet length (set to 20,000 characters)
-
[11]
Reader Mode
Context Expansion:The window is recen- tered and expanded to fill the available token budget, ensuring that the returned snippet pro- vides sufficient context around the relevant terms. The search tool returns the top-k (default k= 5 ) results, containing the document title, source URL, and the extracting snippet. H.4.3 Environment Set The environment set...
-
[12]
Content Extraction:We utilized Jina Reader and ‘BeautifulSoup‘ to strip HTML tags, scripts, and styles
-
[13]
Noise Filtering:A regex-based filtering mod- ule removed common web noise, including cookie notices, navigation bars, advertisement placeholders, and privacy policy disclaimers
-
[14]
information-preserving
LLM-Based Summarization:To handle ex- cessive context length while preserving infor- mation density, we applied an LLM-based summarization step (using GPT-4o). The model was prompted with strict constraints to preserve all factual content, named enti- ties, and procedural details while removing redundancy. The system prompt enforced an "information-preser...
-
[15]
This included lowercasing, punctuation removal, stopword filtering (us- ing NLTK’s English list), and Porter Stem- ming to reduce token dimensionality and im- prove recall
Preprocessing:We applied a standard aca- demic NLP preprocessing pipeline using the NLTK library. This included lowercasing, punctuation removal, stopword filtering (us- ing NLTK’s English list), and Porter Stem- ming to reduce token dimensionality and im- prove recall
-
[16]
Sharded Architecture:To manage memory overhead and support parallelized retrieval, the unified corpus was partitioned into inde- pendent shards, with a default capacity of 20,000 documents per shard
-
[17]
Both the inverted index model and the corresponding raw docu- ment storage were serialized (pickled) into a local file structure
Serialization:For each shard, we computed a distinct BM25Okapi model. Both the inverted index model and the corresponding raw docu- ment storage were serialized (pickled) into a local file structure. This architecture ensures that theLocal Search Engine(described in Section H.4.2) can perform low-latency lookups across the entire dataset with- out requiri...
2025
-
[18]
Software Development Task
Since dbbench is a classification task, the natural mapping to a percentage is plain accuracy, given by Eq. 9. Summary.All TCS values reported for our framework follow Eq. 8 (rubric scenarios) and Eq. 9 (dbbench), both of which are direct instan- tiations of Eq. 6. The relationship to TS(orig) is scenario-dependent: on bargaining and coding the two metric...
-
[19]
Type System Bridging:We map JSON Schema types to Python’s static type hints to facilitate proper argument parsing. This includes recursive handling of complex struc- tures, such as transforming JSONarray types with typed items into PythonList[T] gener- ics (e.g., List[str], List[int]), and map- pingobjecttypes todict
-
[20]
prompt-ready
Semantic Docstring Generation:To en- sure the LLM agent accurately understands tool usage, the transpiler constructs compre- hensive docstrings. It aggregates the tool description, argument descriptions, and re- quired/optional status into a standardized for- mat. This "prompt-ready" documentation al- lows the agent to infer the correct call signa- ture d...
-
[21]
The generated code includes logic to dynamically import the correspond- ing environment class and invoke load_ environment_data() at runtime
Dynamic State Binding:Unlike static func- tion calls, our generated tools possess context- awareness. The generated code includes logic to dynamically import the correspond- ing environment class and invoke load_ environment_data() at runtime. This al- lows the tool to instantiate a localized ver- sion of the environment state (merging data parameters) sp...
-
[22]
key"]‘) which caused run- time crashes on malformed inputs. We performed manual corrections to replace these with safe ac- cess methods (e.g., ‘.get(
Exception Encapsulation:To prevent agent crashes during exploration, the tran- spiler wraps the execution logic in ro- bust try-except blocks. Runtime errors (such as KeyError from missing data or AttributeError from schema mismatches) are caught and formatted as informative string feedback, enabling the agent to self-correct rather than terminating the s...
2025
-
[23]
**Check Final Output:** Does the text in [MODEL FINAL OUTPUT] contain the answer specified in [EXPECTED ANSWER]?
-
[24]
**Verify Context:** Does the log show relevant search actions? (Ignore nested JSON structure like'BFCL_Base', focus on'tool_calls'and'observation')
-
[25]
reasoning
**Verdict:** - If Output matches Truth -> Score 1. - If Output disagrees with Truth -> Score 0. Judge Prompt of BFCL Memory-KV system: | You are a Precision Logic Evaluator for strict Memory Key- Value Retrieval tasks. Your objective is to scientifically assess the accuracy of a MODEL RESULT against a GROUND TRUTH LABEL set. Respond with VALID JSON only: ...
-
[26]
**Exclusivity**: The result must not contain conflicting or hallucinated information alongside the correct answer
-
[27]
**Equivalence**: The result must be semantically identical to the truth, not just "related"
-
[28]
twenty" ==
** robustness**: Format variations (case, whitespace) are acceptable; value errors are not. evaluate: | --- INPUT DATA: expectedoutcome: {label} Memory: {final_memory} --- EVALUATION ALGORITHM: Step 1: **Normalization** - Treat the Ground Truth as a set of acceptable synonyms/ aliases. Matching ANY single item in this set constitutes a potential match. - ...
2023
-
[29]
Analyze the relationship between Prediction and Truth in the`reasoning`field
-
[30]
reasoning
Output the final decision in valid JSON format. Judge Prompt of BFCL Memory-Vector system: | You are a Semantic Search Logic Judge evaluating an AI agent's interactions with a Vector Database. Respond with VALID JSON only: {{"reasoning": "step-by-step analysis", "score": 1 or 0, "explanation": "final verdict"}} **EVALUATION RUBRIC (Retrieval & Ingestion):...
2023
-
[31]
**Identify Operation:** Is it`search`or`insert`?
-
[32]
**Analyze Query (Semantic):** Does the model's query vector text mean the same thing as the expected query?
-
[33]
Are they identical?
**Audit Filters (Strict):** Check every key-value pair in the metadata filter. Are they identical?
-
[34]
reasoning
**Verdict:** Score 1 if semantic intent + strict filters are both correct. Judge Prompt of BFCL Memory-Rec system: | You are a Strict Data Consistency Judge evaluating an AI agent 's ability to maintain and update structured records (User Profiles, Summaries, Logs). Respond with VALID JSON only: {{"reasoning": "step-by-step analysis", "score": 1 or 0, "ex...
-
[35]
**Parse:** Extract the JSON object passed to the function in`final_memory`
-
[36]
**Compare:** Iterate through every key-value pair in the [ EXPECTED RECORD STATE]
-
[37]
**Verify:** - Does Key X exist? - Does Value X match expected Value X?
-
[38]
reasoning
**Verdict:** Return 1 only if the record state is accurate. Judge Prompt of BFCL Single Turn system: | You are an impartial judge evaluating AI agent tool call accuracy. Your task is to determine if the executed tool calls correctly fulfill the user's instruction. Always reply with strict JSON so it can be parsed programmatically. Respond with VALID JSON ...
-
[39]
Function Name Match: The executed function name must match the expected (case-insensitive, ignore prefixes like'api_')
-
[40]
5" vs 5,
Parameter Accuracy: All required parameters must be present with semantically equivalent values. - Numeric values: Allow minor formatting differences (e.g., "5" vs 5, "10.0" vs "10"). - String values: Case-insensitive comparison, ignore leading/trailing whitespace. - Optional parameters: May be omitted if not critical to the operation
-
[41]
Extra Calls: Additional read-only calls (like`finalanswer `) are acceptable
-
[42]
reasoning
Missing Required Calls: If a critical expected call is missing, score 0. --- Instruction: {instruction} expectedoutcome: {label} Memory: {final_memory} Judge Prompt of BFCL Multiple system: | You are an impartial judge evaluating AI agent tool call accuracy for SEQUENTIAL multi-step operations. Your task is to determine if the executed tool calls correctl...
-
[43]
Completeness: ALL expected function calls must be present
-
[44]
- Read-only operations (search, query) can appear in any order
Logical Order: The sequence of state-changing operations must be logically correct. - Read-only operations (search, query) can appear in any order. - Write operations (create, update, delete) must follow the expected logical flow
-
[45]
Function Name Match: Names must match (case-insensitive, ignore common prefixes)
-
[46]
Parameter Accuracy: All required parameters must be present with semantically equivalent values
-
[47]
Extra Calls: Additional exploratory or helper calls are acceptable if they don't violate the task
-
[48]
reasoning
Missing Critical Steps: If a critical expected call is missing, score 0. --- Instruction: {instruction} expectedoutcome: {label} Memory: {final_memory} Judge Prompt of BFCL Parallel system: | You are a sophisticated API AST Evaluator specializing in PARALLEL function calling. Your goal is to verify if the [MODEL OUTPUT] functionally matches the [GROUND TR...
-
[49]
**Function Name**: Exact match (Case-sensitive)
-
[50]
100"`(str) is a PASS. - *Whitespace tolerance*:`
**Arguments**: All required arguments are present and have equivalent values. - *String/Int tolerance*:`100`(int) ==`"100"`(str) is a PASS. - *Whitespace tolerance*:`" Beijing "`==`"Beijing"`is a PASS. - *List order*:`["a", "b"]`==`["b", "a"]`is a PASS ( if the API supports it). **Step 3: Verification** - Did every expected call find a unique valid match ...
-
[51]
**List Extraction:** - Expected Set: [List functions...] - Actual Set: [List functions from memory...]
-
[52]
**Mapping:** - Can I map Expected_Call_1 to *any* call in Actual Set? ( Yes/No) - Can I map Expected_Call_2 to *any* *remaining* call in Actual Set? (Yes/No)
-
[53]
**Argument Audit:** - For matched pairs, do values match semantically?
-
[54]
reasoning
**Verdict:** - If all Expected items are mapped and valid -> Score 1. - Otherwise -> Score 0. Judge Prompt of BFCL Single Turn Live Parallel system: | You are a proficient API AST (Abstract Syntax Tree) Evaluator strictly following the Berkeley Function Calling Leaderboard (BFCL) V4 standards. **YOUR OBJECTIVE:** Compare the [GROUND TRUTH] (Expected Tool ...
-
[55]
Parse the`{final_memory}`specifically looking for the Assistant's`tool_calls`
-
[56]
Map these calls against the`{label}`(Ground Truth)
-
[57]
Apply the BFCL AST logic (Name match -> Argument match -> Set comparison)
-
[58]
reasoning
Determine the score (1 for Pass, 0 for Fail). Judge Prompt of BFCL Single Turn Live Parallel Multiple system: | You are a Strict API AST Evaluator modeled after the Berkeley Function Calling Leaderboard (BFCL) standards. Respond with VALID JSON only: {{"reasoning": "Detailed comparison of expected vs actual...", "score": 1 or 0, " explanation": "Final ver...
-
[59]
**Parse & Extract**: Retrieve all`tool_calls`from the` assistant`turns in [Memory]
-
[60]
Expected Functions
**Set Comparison**: Compare the set of Model Functions vs. Expected Functions. - If Sets are not equal -> **Score 0**
-
[61]
- Check if ALL parameter values match the expected values
**Argument Verification**: For each matched function: - Check if ALL expected parameters exist in the model output. - Check if ALL parameter values match the expected values. - If any mismatch found -> **Score 0**
-
[62]
reasoning
**Pass**: Return **Score 1** only if all checks pass. evaluate: | Instruction: {instruction} --- [expectedoutcome] {label} --- [Memory] {final_memory} Judge Prompt of BFCL Multi Turn Base system: | You are an impartial judge evaluating AI agent behavior in MULTI-TURN, STATEFUL scenarios. The agent operates in a simulated filesystem environment across mult...
-
[63]
Completeness: All critical expected operations (mkdir, mv, cp, rm, grep, diff, etc.) must be performed
-
[64]
Correct Targets: Operations must target the correct files/ directories as specified
-
[65]
Parameter Accuracy: Paths, patterns, and other parameters must be semantically equivalent
-
[66]
reasoning
State Awareness: The agent should be aware of state changes from previous rounds. ACCEPTABLE VARIATIONS: - Extra`ls`,`cd`, or`cat`calls for exploration are acceptable. - Different command ordering is acceptable if the end result is correct. - Using`finalanswer`to summarize actions is acceptable. SCORING: - If ALL rounds have their critical operations comp...
-
[67]
Context Retention: Agent must correctly use information from earlier rounds
-
[68]
No Hallucination: Agent must NOT fabricate information not present in the context
-
[69]
Accurate Parameters: Values derived from context must be exact (file names, IDs, etc.)
-
[70]
reasoning
Logical Flow: Operations must follow a logical sequence based on accumulated knowledge. STRICT REQUIREMENTS: - If the agent uses a value from context, it must match exactly. - If the agent hallucinates data not in the conversation, score 0. ACCEPTABLE VARIATIONS: - Re-reading files or re-querying for confirmation is acceptable. - Different exploration pat...
-
[71]
Recognize Limitation: Agent clearly states the required tool is not available
-
[72]
Alternative Approach: Agent attempts a valid workaround using available tools
-
[73]
Graceful Decline: Agent politely declines and explains why
-
[74]
INCORRECT BEHAVIORS (score 0):
Partial Success: Agent completes what's possible and explains the limitation. INCORRECT BEHAVIORS (score 0):
-
[75]
Hallucination: Agent pretends the tool exists and "calls" it
-
[76]
Wrong Tool: Agent uses an unrelated tool that doesn't address the task
-
[77]
Silent Failure: Agent gives no explanation about the missing capability
-
[78]
reasoning
Dangerous Workaround: Agent uses a destructive alternative when safe options exist. --- Instruction: {instruction} expectedoutcome: {label} Memory: {final_memory} Judge Prompt of BFCL Multi Turn Miss Param system: | You are an impartial judge evaluating AI agent behavior when REQUIRED PARAMETERS ARE MISSING. The agent must handle cases where the user hasn...
-
[79]
Ask for Clarification: Agent requests the missing information from the user
-
[80]
Use Defaults: Agent uses reasonable default values where applicable
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.