Reasoning Matters: Mitigate Hallucination in Multimodal Large Reasoning Models via Reasoning-Conditioned Preference Optimization
Pith reviewed 2026-06-29 13:01 UTC · model grok-4.3
The pith
Modeling the reasoning chain as a condition for the answer lets preference optimization align supportive reasoning and reduce hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
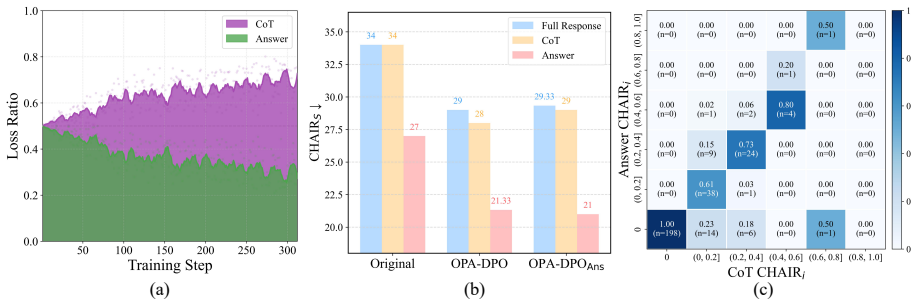
The central claim is that standard response-level DPO performs similarly to answer-only optimization and therefore fails to exploit CoT-level supervision; RC-DPO corrects this by modeling the CoT as a condition for answer generation and contrasting preference for the identical preferred answer under different CoT conditions, thereby promoting answer-supportive reasoning chain alignment, with the effect strengthened by Monte Carlo Tree Search positive samples and attention-guided negative samples.
What carries the argument
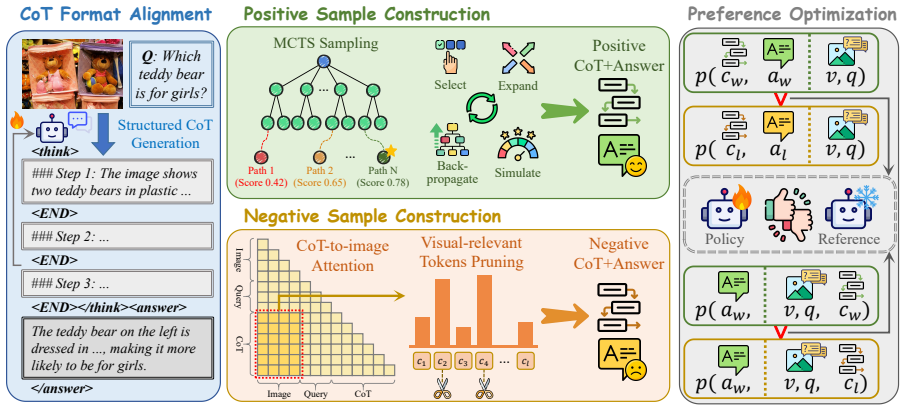
Reasoning-Conditioned Direct Preference Optimization (RC-DPO), which treats the Chain-of-Thought as a conditioning variable on answer generation and contrasts preferences across different CoTs for the same answer.
If this is right
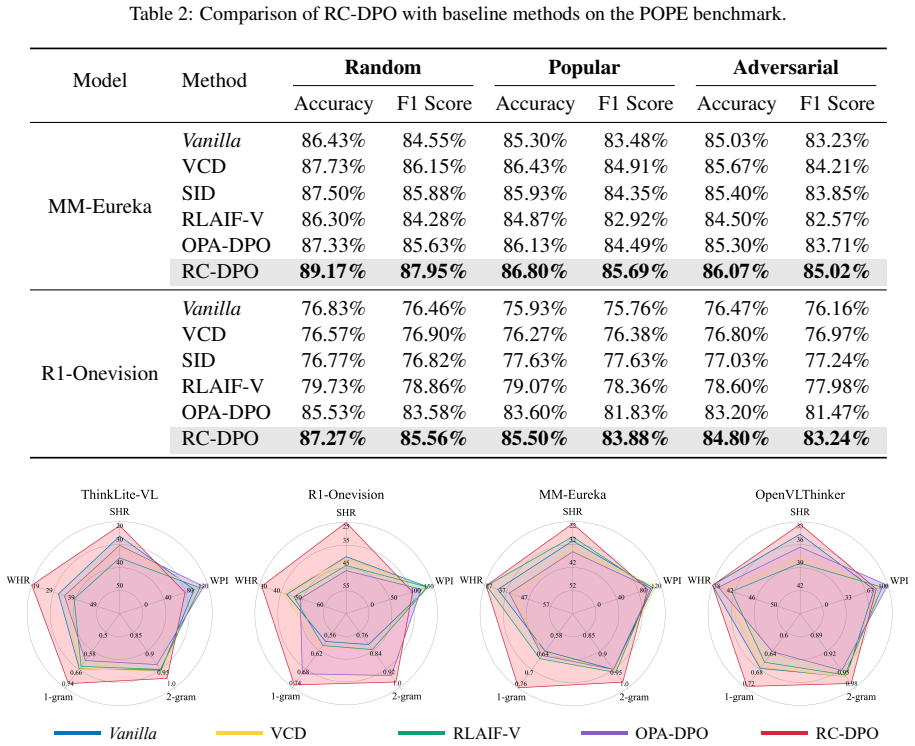
- RC-DPO produces measurable reductions in hallucinations compared with response-level DPO on the same models and benchmarks.
- The method improves the reliability of the multimodal reasoning process by aligning reasoning chains with correct answers.
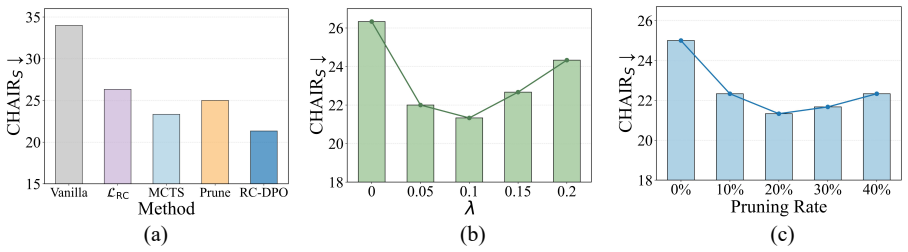
- The Monte Carlo Tree Search and attention-pruning procedure generates training pairs that further strengthen the optimization.
- Gains hold across multiple base models and multiple vision-language benchmarks.
Where Pith is reading between the lines
- The same conditioning idea could be inserted into other preference-based alignment algorithms beyond DPO.
- The separation of reasoning and answer optimization stages suggests a route for diagnosing which parts of a chain cause hallucinations.
- The search-and-pruning data pipeline could be reused to build larger, higher-quality reasoning datasets for any multimodal model.
Load-bearing premise
Standard response-level DPO performs similarly to answer-only optimization and therefore leaves CoT-level supervision insufficiently exploited.
What would settle it
A controlled ablation in which standard response-level DPO is shown to produce measurably different hallucination rates than pure answer-only optimization on the same benchmarks would falsify the motivation for introducing the conditioning term.
Figures

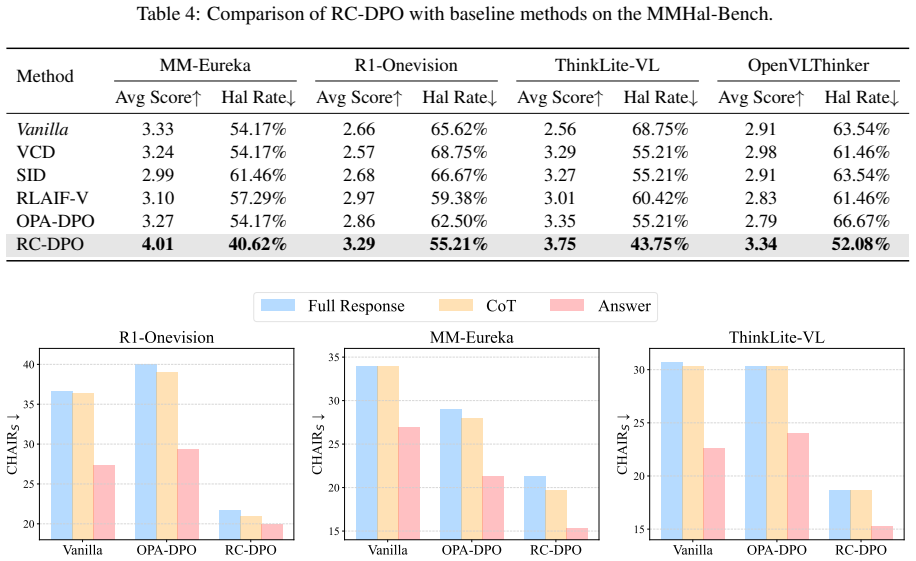
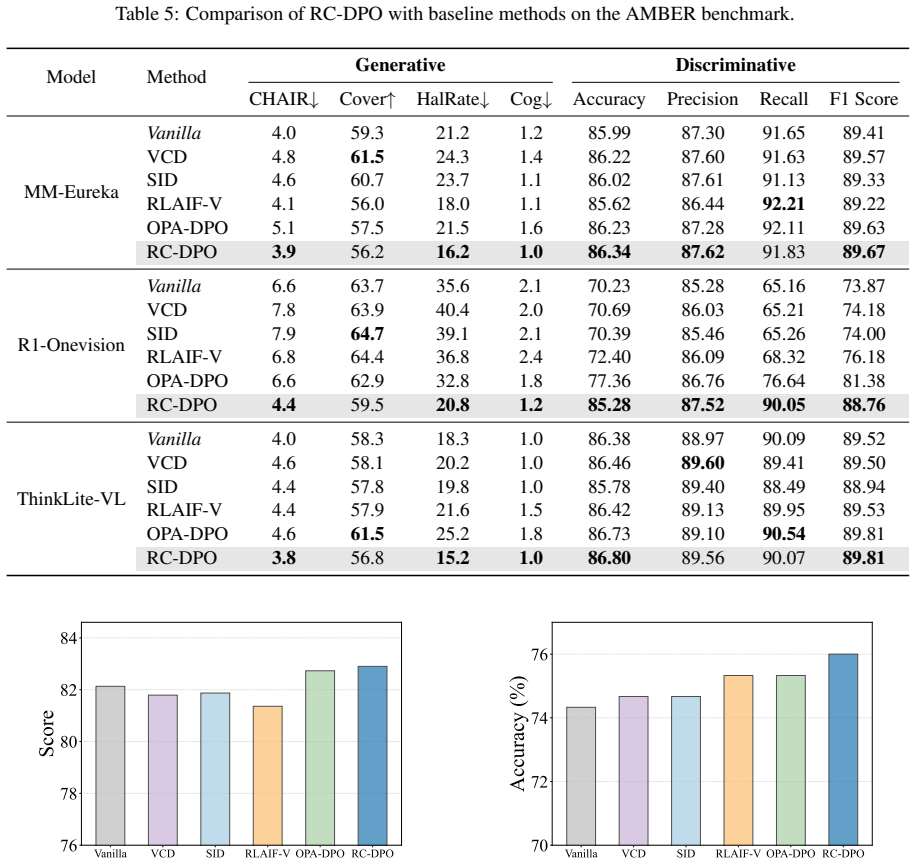



read the original abstract
Multimodal Large Reasoning Models introduce the reasoning paradigm, demonstrating strong capabilities on complex vision-language tasks. However, they still suffer from severe hallucinations. Existing training-based methods typically mitigate hallucinations through response-level direct preference optimization (DPO), where the Chain-of-Thought (CoT) and the final answer are treated as a monolithic output and optimized jointly. We reveal that this formulation performs similarly to answer-only optimization, suggesting that it primarily learns answer-level preference, while leaving CoT-level supervision insufficiently exploited. To address this issue, we explicitly formulate a CoT-oriented preference term and derive Reasoning-Conditioned Direct Preference Optimization (RC-DPO), which models the CoT as a condition for answer generation and contrasts the preference for the same preferred answer under different CoT conditions, promoting answer-supportive reasoning chain alignment. To further improve optimization, we introduce a reasoning-enhanced preference data generation strategy that employs Monte Carlo Tree Search to discover visually grounded and logically consistent CoTs as positive samples, and attention-guided CoT token pruning to construct negative ones. Extensive experiments across various models and benchmarks show that RC-DPO effectively mitigates hallucinations and improves the reliability of the multimodal reasoning process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard response-level DPO on (CoT + answer) pairs behaves similarly to answer-only optimization, leaving CoT-level supervision unexploited and failing to mitigate hallucinations effectively in multimodal large reasoning models. It introduces Reasoning-Conditioned DPO (RC-DPO), which treats the CoT as a conditioning variable and contrasts preferences for the same answer under different CoT conditions to promote answer-supportive reasoning alignment. A data-generation pipeline using MCTS for positive (visually grounded) CoTs and attention-guided pruning for negatives is proposed, with experiments across models and benchmarks reported to show reduced hallucinations and improved reasoning reliability.
Significance. If the central empirical claim holds and the motivation is substantiated, RC-DPO would represent a targeted improvement over monolithic DPO for reasoning models by explicitly aligning CoT with answers. The MCTS-based positive sampling and pruning strategy could be reusable for other preference-based reasoning alignment tasks. The work directly addresses a practical failure mode (hallucinations) in an active area of multimodal LLM research.
major comments (2)
- [Abstract, §3] Abstract and §3 (method motivation): The claim that 'this formulation performs similarly to answer-only optimization' is presented as an empirical observation but is not accompanied by any quantitative comparison, ablation table, loss decomposition, or statistical test in the provided text. This equivalence is load-bearing for the motivation of the RC-DPO conditioning term; without evidence that standard DPO leaves CoT supervision unexploited, the new contrastive term may not address a genuine gap rather than an incremental reparameterization.
- [§4] §4 (experiments): While 'extensive experiments' are asserted to demonstrate mitigation of hallucinations, the abstract supplies no numbers, baselines, or ablation results (e.g., RC-DPO vs. standard DPO on the same data, or vs. answer-only DPO). The central claim that RC-DPO 'effectively mitigates hallucinations' therefore rests on unshown results; a table or figure quantifying the improvement attributable to the conditioning term is required to support the contribution.
minor comments (1)
- [§3] Notation: The distinction between the standard DPO loss and the proposed RC-DPO loss should be written explicitly with equations early in §3 to make the conditioning term immediately comparable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support of our motivation and clearer presentation of results. We will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method motivation): The claim that 'this formulation performs similarly to answer-only optimization' is presented as an empirical observation but is not accompanied by any quantitative comparison, ablation table, loss decomposition, or statistical test in the provided text. This equivalence is load-bearing for the motivation of the RC-DPO conditioning term; without evidence that standard DPO leaves CoT supervision unexploited, the new contrastive term may not address a genuine gap rather than an incremental reparameterization.
Authors: We agree the motivation requires explicit quantitative backing, which is absent from the current text. Preliminary internal experiments showed the similarity, but these were not reported. In revision, we will add a new ablation subsection (likely in §3) with tables comparing standard DPO on (CoT+answer) pairs vs. answer-only DPO across hallucination rate, accuracy, and reasoning metrics on multimodal benchmarks. This will demonstrate under-exploitation of CoT supervision and justify the conditioning term. revision: yes
-
Referee: [§4] §4 (experiments): While 'extensive experiments' are asserted to demonstrate mitigation of hallucinations, the abstract supplies no numbers, baselines, or ablation results (e.g., RC-DPO vs. standard DPO on the same data, or vs. answer-only DPO). The central claim that RC-DPO 'effectively mitigates hallucinations' therefore rests on unshown results; a table or figure quantifying the improvement attributable to the conditioning term is required to support the contribution.
Authors: We concur that key quantitative results and ablations must be more prominently featured. We will update the abstract with specific improvement numbers (e.g., hallucination reduction percentages) and add a dedicated results table in §4 showing RC-DPO vs. standard DPO and answer-only baselines on identical data. This will isolate the contribution of the CoT-conditioning term and the MCTS/pruning pipeline. revision: yes
Circularity Check
No circularity: RC-DPO is an explicit non-tautological extension of DPO
full rationale
The paper defines RC-DPO by explicitly adding a CoT-conditioning term to the standard DPO loss and contrasts preferences for the same answer under different CoT conditions. No equations are shown that reduce this new term to a fitted input, a self-citation, or a renaming of the original DPO objective. The motivating observation that response-level DPO behaves like answer-only optimization is stated as an empirical claim without any demonstrated algebraic equivalence or self-referential construction. Data generation via MCTS and attention pruning are standard external techniques, not internal to the loss derivation. The method therefore remains self-contained against the DPO baseline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pairwise human or model preferences can be modeled by a latent reward function via the Bradley-Terry model
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930. Hyeong Soo Chang, Michael C Fu, Jiaqiao Hu, and Steven I Marcus. 2005. An adaptive sampling algo- rithm for solving markov decision processes.Opera- tions research, 53(1):126–139. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, ...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[3]
A Survey on Hallucination in Large Vision-Language Models
Mitigating object hallucinations in large vision- language models through visual contrastive decod- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023. Evaluating object hallucination in large vision-language models. In Pro...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Aligning large multimodal models with factu- ally augmented rlhf. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13088–13110. Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. 2024. Eyes wide shut? exploring the visual shortcomings of multi- modal llms. InProceedings of the IEEE/CVF con- ference o...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Multimodal Chain-of-Thought Reasoning in Language Models
Automated generation of challenging multiple- choice questions for vision language model evalua- tion. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 29580–29590. Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023. Multi- modal chain-of-thought reasoning in language mod- els.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
is designed to evaluate hallucinations in open-ended multimodal responses. It contains chal- lenging image-question pairs that require models to generate visually grounded answers rather than re- lying on language priors. The benchmark evaluates both response quality and hallucination severity, making it suitable for assessing whether a model can produce ...
-
[7]
Think step by step using explicit reasoning
-
[8]
RLAIF-V:
Each reasoning step MUST: - Describe exactly ONE logical step - Be directly grounded in clearly observable visual evidence - Avoid unsupported assumptions or speculation - End with the special token <END> =========== FINAL ANSWER FORMAT (INSIDE <answer>) =========== After completing all reasoning steps, provide the final answer. The final answer MUST: - B...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.