Addressing Variable Heterogeneity in Distributed Multimodal Training with Entrain
Pith reviewed 2026-06-29 10:17 UTC · model grok-4.3
The pith
A single static model-parallel configuration suffices for optimal load balancing in multimodal LLM training when profiling shifts to macroscopic batches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
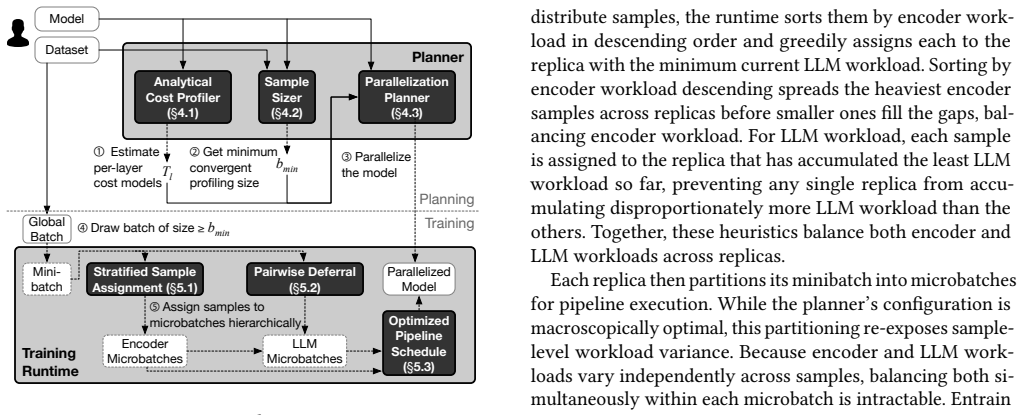
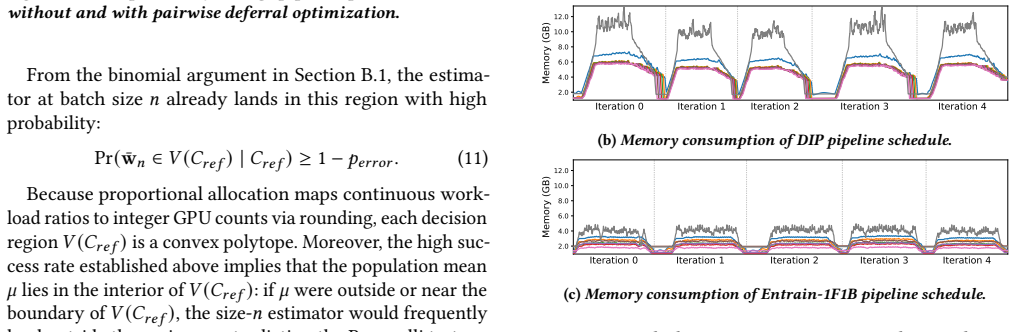
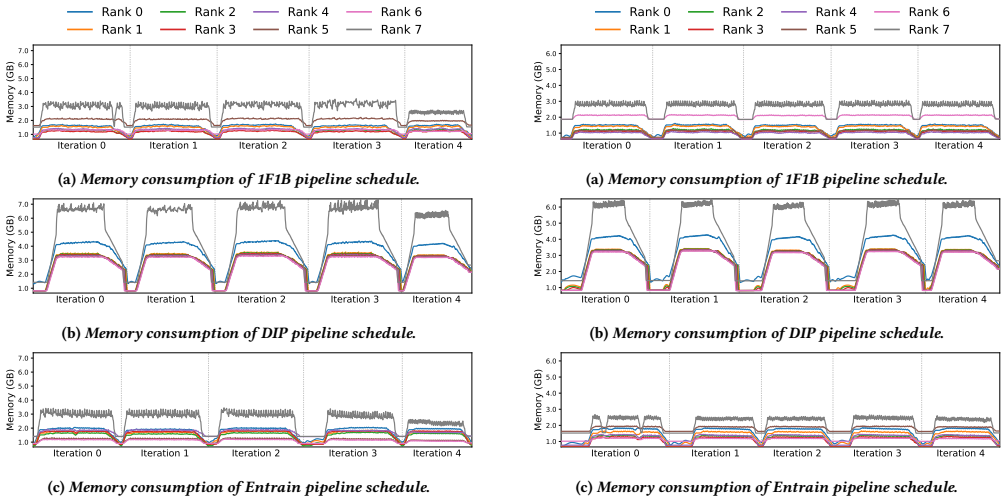
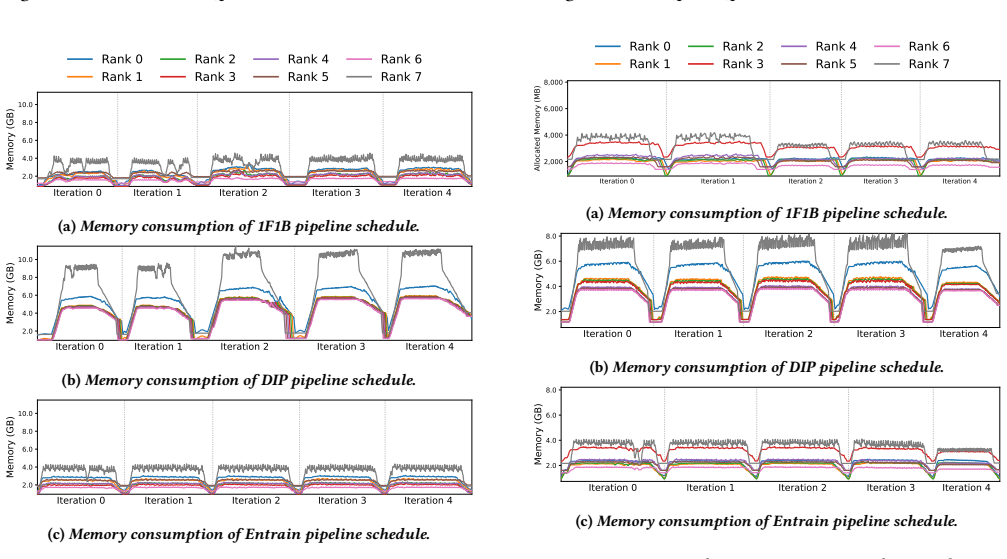
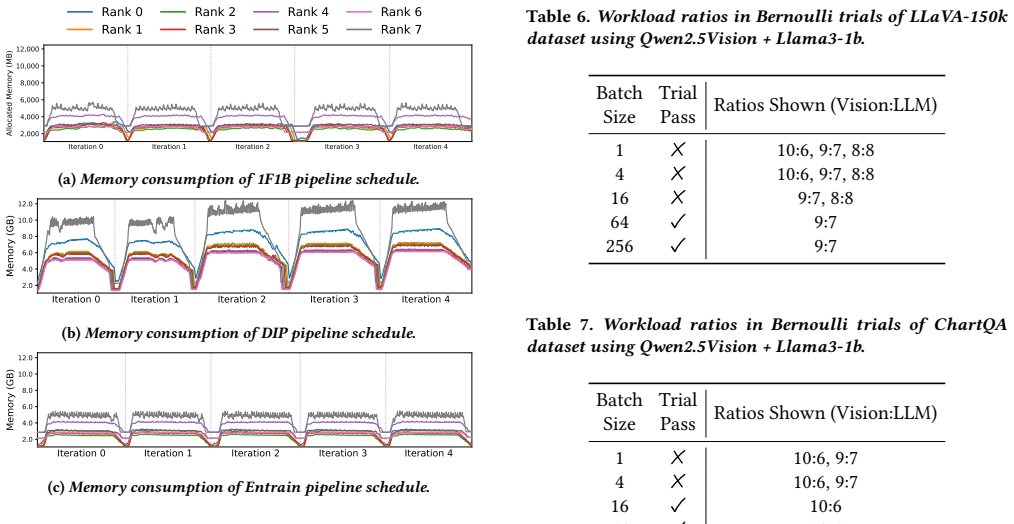
The paper establishes that under a macroscopic batch profiling paradigm, a single static model-parallel configuration is sufficient for optimal load balancing despite data variability and sample-level entanglement in multimodal datasets. It further introduces a hierarchical microbatch assignment algorithm that defers excess workload within each iteration to reduce variability across microbatches.
What carries the argument
The shift to macroscopic batch-level profiling that enables static model parallelism, paired with the hierarchical microbatch assignment algorithm.
If this is right
- A single fixed model-parallel setup can replace dynamic reconfiguration for load balancing.
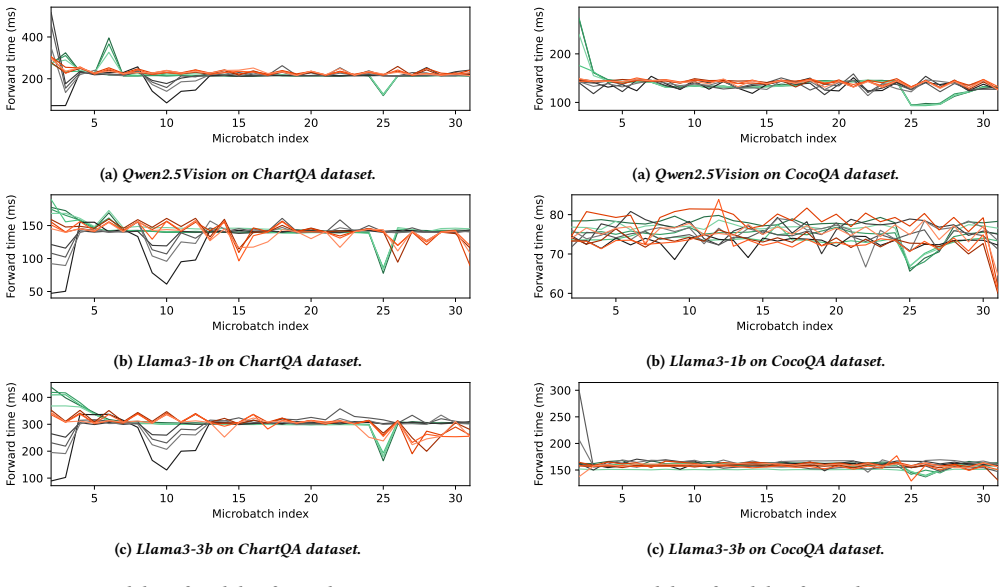
- Workload variability across microbatches is reduced by up to 10.6×.
- End-to-end training throughput improves by up to 1.40× over baselines.
- Both inter-modality and batch-level variability are addressed without dynamic changes.
Where Pith is reading between the lines
- This approach may simplify system design by avoiding runtime reconfiguration overhead in other variable workloads.
- Future systems could test if batch-level profiling generalizes to non-multimodal heterogeneous training.
- Hardware resource allocation might become more predictable with static configurations.
Load-bearing premise
Batch-level variability can be profiled accurately enough that sample-level entanglement does not require changing the model-parallel configuration dynamically.
What would settle it
Measuring workload variability when using the static configuration on datasets where sample-level effects dominate batch averages, to check if balancing fails.
Figures


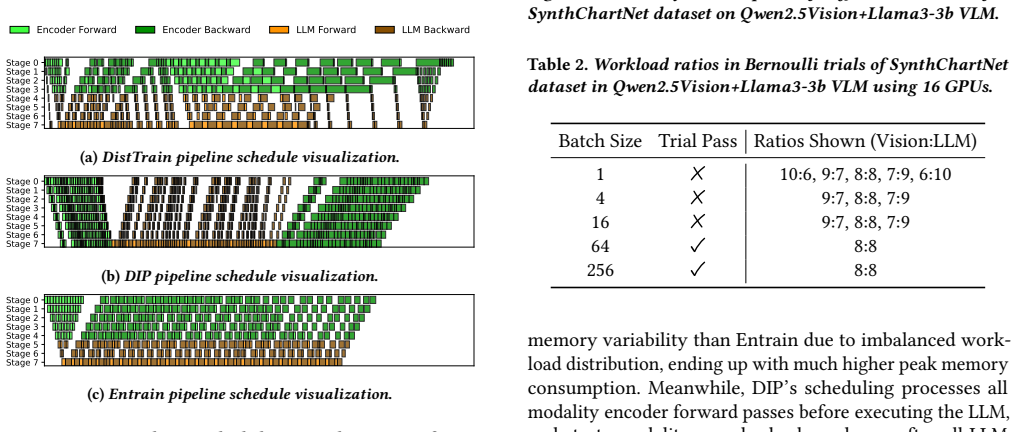
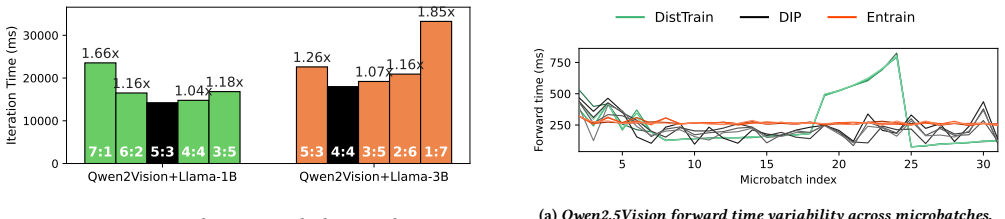
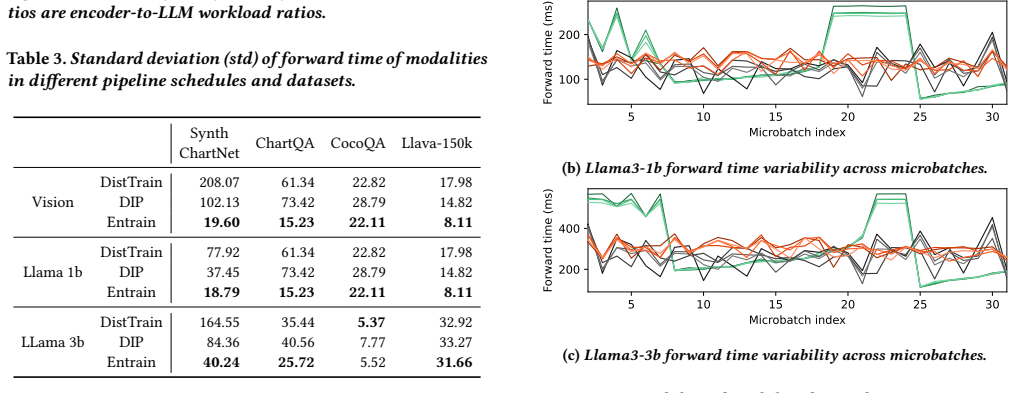
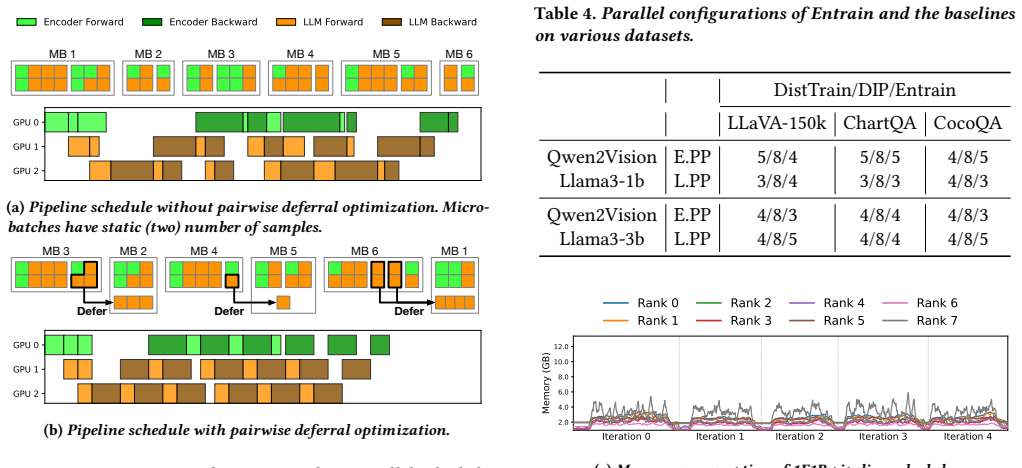
read the original abstract
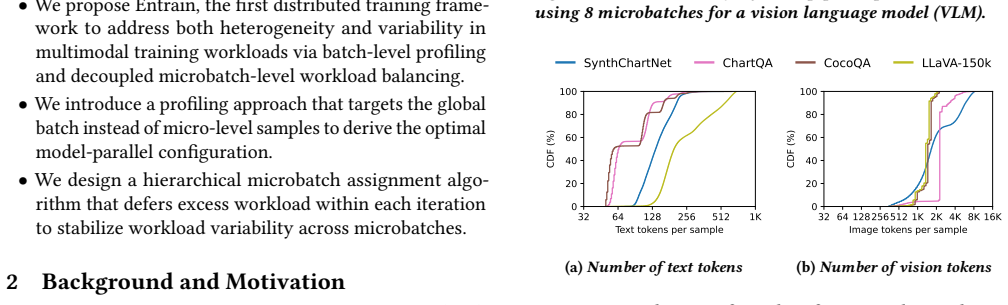
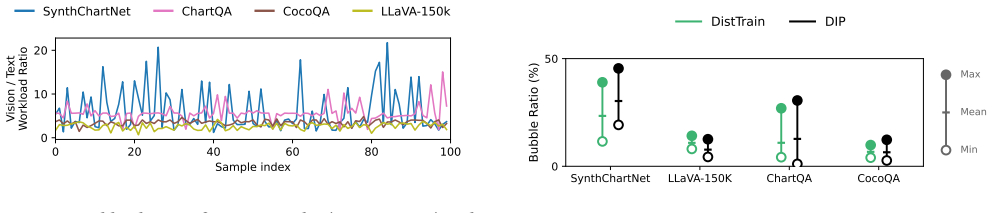
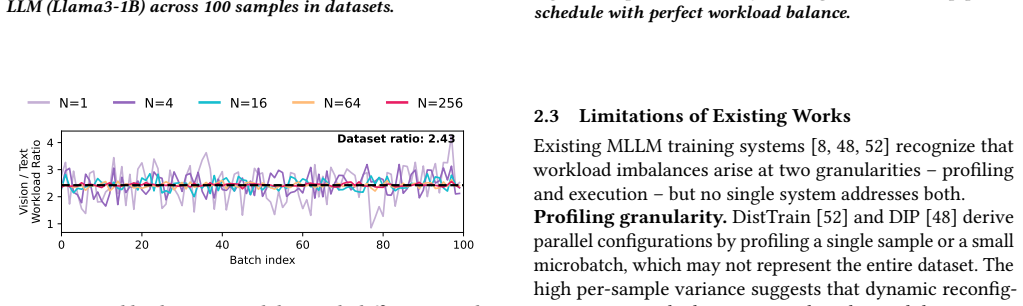
Multimodal LLM datasets are inherently heterogeneous, with significant data variability. Although each modality exhibits independent variability, sample-level entanglement makes it difficult to balance workloads across both modalities and batches. We present Entrain, a distributed MLLM training framework that addresses both heterogeneity and variability in multimodal training workloads. Entrain challenges the intuition that dynamic data variability requires dynamic model parallelism by shifting the profiling paradigm from micro-level samples to macroscopic batches. We prove that a single, static model-parallel configuration suffices for optimal load balancing under this paradigm. At the microscopic scale, Entrain introduces a hierarchical microbatch assignment algorithm that defers excess workload within each iteration to stabilize variability across microbatches. Evaluations show that Entrain reduces workload variability across microbatches by up to 10.6$\times$, improving end-to-end training throughput by up to 1.40$\times$ over existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Entrain, a distributed training framework for multimodal LLMs that addresses data heterogeneity and variability across modalities and batches. It shifts profiling from micro-level samples to macroscopic batches and proves that a single static model-parallel configuration suffices for optimal load balancing. At the micro scale, it uses a hierarchical microbatch assignment algorithm to defer excess workload and stabilize variability within iterations. Evaluations claim up to 10.6× reduction in workload variability across microbatches and up to 1.40× end-to-end throughput improvement over baselines.
Significance. If the proof holds and the batch-level profiling assumption is valid despite sample entanglement, the result would be significant for distributed systems in multimodal training: it offers a simpler alternative to dynamic model parallelism, with the provided proof and quantitative gains as explicit strengths. This could reduce reconfiguration overhead in large-scale heterogeneous workloads.
major comments (1)
- [theoretical analysis section] The central proof that a single static model-parallel configuration suffices (theoretical analysis section) rests on the modeling choice that batch-level aggregates capture variability without sample-level entanglement dominating. No explicit bounds, assumptions, or conditions on entanglement effects at batch scale are provided to support that the static choice remains optimal across batches with high intra-batch variance, which directly undermines the optimality claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer assumptions in the theoretical analysis. We address the concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [theoretical analysis section] The central proof that a single static model-parallel configuration suffices (theoretical analysis section) rests on the modeling choice that batch-level aggregates capture variability without sample-level entanglement dominating. No explicit bounds, assumptions, or conditions on entanglement effects at batch scale are provided to support that the static choice remains optimal across batches with high intra-batch variance, which directly undermines the optimality claim.
Authors: The proof models workload at the batch level, where aggregate statistics across modalities allow a single static model-parallel partition to minimize expected imbalance; the hierarchical microbatch assignment then defers excess work within an iteration to bound realized variance. Sample entanglement is acknowledged in the manuscript but treated as a second-order effect once batch aggregates are fixed. We agree that the current text lacks explicit bounds or conditions on when entanglement could invalidate the static optimum. In revision we will add a dedicated subsection stating the modeling assumptions (e.g., bounded per-sample variance relative to batch size, Lipschitz continuity of modality workloads) and deriving a simple concentration bound showing that the static configuration remains within a constant factor of optimal with high probability when batch size exceeds a threshold derived from the variance model. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper claims a proof that shifting profiling to macroscopic batches makes a single static model-parallel configuration optimal for load balancing, with a hierarchical microbatch assignment algorithm to stabilize variability. No equations, definitions, or steps in the abstract or claims reduce this optimality result to fitted parameters, self-definitions, or self-citation chains by construction. The result is presented as an independent mathematical argument based on the paradigm shift, not as a renaming or prediction forced by inputs. The derivation is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Meta AI. 2024. The Llama 3 Herd of Models.https://arxiv.org/abs/ 2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Meta AI. 2025. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation.https://ai.meta.com/blog/llama-4- multimodal-intelligence/. [Accessed Feb 08, 2026]
2025
-
[4]
Yushi Bai, Xin Lv, Jiajie Zhang, Yuze He, Ji Qi, Lei Hou, Jie Tang, Yuxiao Dong, and Juanzi Li. 2024. LongAlign: A Recipe for Long Context Alignment of Large Language Models. InEMNLP 24.https: //aclanthology.org/2024.findings-emnlp.74/
2024
-
[5]
Brian Chmiel, Maxim Fishman, Ron Banner, and Daniel Soudry. 2025. FP4 All the Way: Fully Quantized Training of Large Language Models. InNeurIPS 25.https://neurips.cc/virtual/2025/loc/san-diego/poster/ 116331
2025
-
[6]
Weiwei Chu, Xinfeng Xie, Jiecao Yu, Jie Wang, Amar Phanishayee, Chunqiang Tang, Yuchen Hao, Jianyu Huang, Mustafa Ozdal, Jun Wang, Vedanuj Goswami, Naman Goyal, Abhishek Kadian, Andrew Gu, Chris Cai, Feng Tian, Xiaodong Wang, Min Si, Pavan Balaji, Ching- Hsiang Chu, and Jongsoo Park. 2025. Scaling Llama 3 Training with Ef- ficient Parallelism Strategies. ...
-
[7]
Higham, Theo Mary, and Mantas Mikaitis
Matteo Croci, Massimiliano Fasi, Nicholas J. Higham, Theo Mary, and Mantas Mikaitis. [n. d.]. Stochastic Rounding: implementa- tion, error analysis and applications.Royal Society Open Sci- ence([n. d.]). arXiv:https://royalsocietypublishing.org/rsos/article- pdf/doi/10.1098/rsos.211631/998073/rsos.211631.pdf doi:10.1098/rsos. 211631
-
[8]
Weiqi Feng, Yangrui Chen, Shaoyu Wang, Yanghua Peng, Haibin Lin, and Minlan Yu. 2025. Optimus: Accelerating Large-Scale Multi-Modal LLM Training by Bubble Exploitation. InATC 25
2025
-
[9]
Hao Ge, Junda Feng, Qi Huang, Fangcheng Fu, Xiaonan Nie, Lei Zuo, Haibin Lin, Bin Cui, and Xin Liu. 2025. ByteScale: Communication- Efficient Scaling of LLM Training with a 2048K Context Length on 16384 GPUs. InSIGCOMM 25.https://doi.org/10.1145/3718958.3754352
-
[10]
Hao Ge, Fangcheng Fu, Haoyang Li, Xuanyu Wang, Sheng Lin, Yujie Wang, Xiaonan Nie, Hailin Zhang, Xupeng Miao, and Bin Cui. 2024. Enabling Parallelism Hot Switching for Efficient Training of Large Language Models. InSOSP 24. doi:10.1145/3694715.3695969
-
[11]
Google. 2023. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 [cs.CL]https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Ronald Lewis Graham. 1969. Bounds on Multiprocessing Timing Anomalies.SIAM J. Appl. Math.17, 2 (1969), 416–429.https://doi.org/ 10.1137/0117039
-
[13]
Diandian Gu, Peng Sun, Qinghao Hu, Ting Huang, Xun Chen, Ying- tong Xiong, Guoteng Wang, Qiaoling Chen, Shangchun Zhao, Jiarui Fang, Yonggang Wen, Tianwei Zhang, Xin Jin, and Xuanzhe Liu. 2024. LoongTrain: Efficient Training of Long-Sequence LLMs with Head- Context Parallelism.https://arxiv.org/abs/2406.18485
-
[14]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Henni- gan, Eric Noland, Katie Millican, George van den Driessche, Bog- dan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent S...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Jun Huang, Zhen Zhang, Shuai Zheng, Feng Qin, and Yida Wang. 2024. DISTMM: Accelerating Distributed Multimodal Model Training. In NSDI 24.https://www.usenix.org/conference/nsdi24/presentation/ huang
2024
-
[16]
Insu Jang, Runyu Lu, Nikhil Bansal, Ang Chen, and Mosharaf Chowd- hury. 2025. Efficient Distributed MLLM Training with Cornstarch. 13 arXiv:2503.11367 [cs.DC]https://arxiv.org/abs/2503.11367
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Insu Jang, Zhenning Yang, Zhen Zhang, Xin Jin, and Mosharaf Chowd- hury. 2023. Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates. InSOSP 23. doi:10.1145/3600006.3613152
-
[18]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Ben- jamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Mod- els. arXiv:2001.08361 [cs.LG]https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Perez, and Andrew Fitzgib- bon
Matej Kosec, Mario Michael Krell, Sergio P. Perez, and Andrew Fitzgib- bon. 2022. Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance. https://arxiv.org/abs/2107.02027
-
[20]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2025. LLaVA-OneVision: Easy Visual Task Transfer.TMLR 25(2025). https://openreview.net/forum?id=zKv8qULV6n
2025
-
[21]
Shenggui Li, Hongxin Liu, Zhengda Bian, Jiarui Fang, Haichen Huang, Yuliang Liu, Boxiang Wang, and Yang You. 2023. Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training. InICPP 23. doi:10.1145/3605573.3605613
-
[22]
Shenggui Li, Fuzhao Xue, Chaitanya Baranwal, Yongbin Li, and Yang You. 2023. Sequence Parallelism: Long Sequence Training from System Perspective. InACL 23. doi:10.18653/v1/2023.acl-long.134
-
[23]
Wanchao Liang, Tianyu Liu, Less Wright, Will Constable, Andrew Gu, Chien-Chin Huang, Iris Zhang, Wei Feng, Howard Huang, Junjie Wang, Sanket Purandare, Gokul Nadathur, and Stratos Idreos. 2025. TorchTi- tan: One-stop PyTorch native solution for production ready LLM pre- training. InICLR 25.https://openreview.net/forum?id=SFN6Wm7YBI
2025
-
[24]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Im- proved Baselines with Visual Instruction Tuning. InCVPR 24. 26296– 26306
2024
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction Tuning. InNIPS 23.https://proceedings.neurips. cc/paper_files/paper/2023/file/6dcf277ea32ce3288914faf369fe6de0- Paper-Conference.pdf
2023
- [26]
-
[27]
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, and Chong Ruan. 2024. DeepSeek-VL: Towards Real-World Vision-Language Understanding. arXiv:2403.05525 [cs.AI]https://arxiv.org/abs/2403.05525
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Ena- mul Hoque. 2022. ChartQA: A Benchmark for Question Answer- ing about Charts with Visual and Logical Reasoning. InACL 22. https://aclanthology.org/2022.findings-acl.177/
2022
-
[29]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: generalized pipeline parallelism for DNN training. InSOSP 19. doi:10.1145/3341301.3359646
-
[30]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. InSC 21. doi:10.1145/3458817. 3476209
-
[31]
Said Gurbuz, Michele Dolfi, and Peter W
Ahmed Nassar, Matteo Omenetti, Maksym Lysak, Nikolaos Livathinos, Christoph Auer, Lucas Morin, Rafael Teixeira de Lima, Yusik Kim, A. Said Gurbuz, Michele Dolfi, and Peter W. J. Staar. 2025. SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion. InICCV 25. 21972–21983
2025
-
[32]
OpenAI. 2024. GPT-4o System Card. arXiv:2410.21276 [cs.CL]https: //arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
OpenAI. 2026. OpenAI GPT-5 System Card. arXiv:2601.03267 [cs.CL] https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Houwen Peng, Kan Wu, Yixuan Wei, Guoshuai Zhao, Yuxiang Yang, Ze Liu, Yifan Xiong, Ziyue Yang, Bolin Ni, Jingcheng Hu, Ruihang Li, Miaosen Zhang, Chen Li, Jia Ning, Ruizhe Wang, Zheng Zhang, Shuguang Liu, Joe Chau, Han Hu, and Peng Cheng. 2023. FP8-LM: Training FP8 Large Language Models. arXiv:2310.18313 [cs.LG]https: //arxiv.org/abs/2310.18313
-
[35]
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. 2024. Zero Bubble (Almost) Pipeline Parallelism. InICLR 24.https://openreview. net/forum?id=tuzTN0eIO5
2024
-
[36]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He
- [37]
-
[38]
Mengye Ren, Ryan Kiros, and Richard Zemel. 2015. Explor- ing Models and Data for Image Question Answering. InNIPS 15.https://proceedings.neurips.cc/paper_files/paper/2015/file/ 831c2f88a604a07ca94314b56a4921b8-Paper.pdf
2015
-
[39]
Xiao Sun, Jungwook Choi, Chia-Yu Chen, Naigang Wang, Swagath Venkataramani, Vijayalakshmi (Viji) Srinivasan, Xiaodong Cui, Wei Zhang, and Kailash Gopalakrishnan. 2019. Hybrid 8-bit Floating Point (HFP8) Training and Inference for Deep Neural Networks. In NeurIPS 19.https://proceedings.neurips.cc/paper_files/paper/2019/ file/65fc9fb4897a89789352e211ca2d398...
2019
-
[40]
Colin Unger, Zhihao Jia, Wei Wu, Sina Lin, Mandeep Baines, Carlos Efrain Quintero Narvaez, Vinay Ramakrishnaiah, Nirmal Prajapati, Pat McCormick, Jamaludin Mohd-Yusof, Xi Luo, Dheevatsa Mudigere, Jongsoo Park, Misha Smelyanskiy, and Alex Aiken. 2022. Unity: Ac- celerating DNN Training Through Joint Optimization of Algebraic Transformations and Paralleliza...
2022
-
[41]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InNIPS 17
2017
-
[42]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv:2409.12191 [cs.CV]https://a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, and Bin Cui. 2025. FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism. InASPLOS 25. doi:10.1145/3676641.3715998
-
[44]
Zheng Wang, Anna Cai, Xinfeng Xie, Zaifeng Pan, Yue Guan, Weiwei Chu, Jie Wang, Shikai Li, Jianyu Huang, Chris Cai, Yuchen Hao, and Yufei Ding. 2025. WLB-LLM: workload-balanced 4D parallelism for large language model training. InOSDI 25.https://www.usenix.org/ conference/osdi25/presentation/wang-zheng
2025
-
[45]
Luis Wiedmann, Orr Zohar, Amir Mahla, Xiaohan Wang, Rui Li, Thibaud Frere, Leandro von Werra, Aritra Roy Gosthipaty, and An- drés Marafioti. 2025. FineVision: Open Data Is All You Need.https: //arxiv.org/abs/2510.17269
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Syl- vain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush
-
[47]
In EMNLP 20
Transformers: State-of-the-Art Natural Language Processing. In EMNLP 20. 14
-
[48]
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Jiawei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan, Aixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, and Chong Ruan. 2024. DeepSeek-VL2: Mixture-of-Experts...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Zhenliang Xue, Hanpeng Hu, Xing Chen, Yimin Jiang, Yixin Song, Zeyu Mi, Yibo Zhu, Daxin Jiang, Yubin Xia, and Haibo Chen. 2026. DIP: Efficient Large Multimodal Model Training with Dynamic Interleaved Pipeline. InASPLOS 26. doi:10.1145/3779212.3790154
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Yongqiang Yao, Jingru Tan, Kaihuan Liang, Feizhao Zhang, Jiahao Hu, Shuo Wu, Yazhe Niu, Ruihao Gong, Dahua Lin, and Ningyi Xu
-
[53]
InNeurIPS 25.https://openreview.net/ forum?id=6BHDre6WQW
Hierachical Balance Packing: Towards Efficient Supervised Fine- tuning for Long-Context LLM. InNeurIPS 25.https://openreview.net/ forum?id=6BHDre6WQW
-
[54]
Jinbin Zhang, Nasib Ullah, Erik Schultheis, and Rohit Babbar. 2025. ELMO : Efficiency via Low-precision and Peak Memory Optimization in Large Output Spaces. InICML 25.https://openreview.net/forum? id=d6CTIPrTTC
2025
-
[55]
Zili Zhang, Yinmin Zhong, Yimin Jiang, Hanpeng Hu, Jianjian Sun, Zheng Ge, Yibo Zhu, Daxin Jiang, and Xin Jin. 2025. DistTrain: Ad- dressing Model and Data Heterogeneity with Disaggregated Training for Multimodal Large Language Models. InSIGCOMM 25.https: //doi.org/10.1145/3718958.3750472
-
[56]
Siyan Zhao, Daniel Mingyi Israel, Guy Van den Broeck, and Aditya Grover. 2025. Prepacking: A Simple Method for Fast Prefilling and Increased Throughput in Large Language Models. InAISTATS 25.https: //openreview.net/forum?id=LBVD4krAq2
2025
-
[57]
Xing, Joseph E
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Au- tomating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. InOSDI 22.https://www.usenix.org/conference/osdi22/ presentation/zheng-lianmin 15 A Termina...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.