Skill-as-Pseudocode: Refactoring Skill Libraries to Pseudocode for LLM Agents
Pith reviewed 2026-06-29 09:39 UTC · model grok-4.3
The pith
Refactoring markdown skill libraries into typed pseudocode with deterministic verification improves LLM agent success rates on unseen tasks while reducing token consumption and API calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
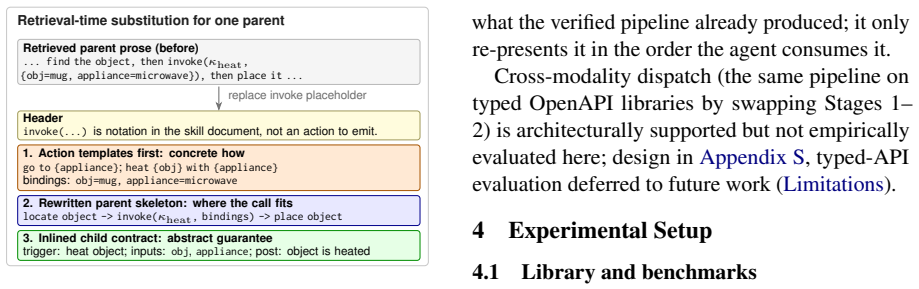
Skill-as-Pseudocode (SaP) automatically converts markdown skill libraries into typed pseudocode by clustering similar procedural passages, extracting typed contracts, and filtering them through a four-check deterministic verifier (coverage, binding, replacement, risk). Promoted contracts are inlined into rewritten skill skeletons together with restored concrete action templates. This supplies the agent with complementary signals of a typed signature and a concrete template, breaking the confused-re-retrieve cycle and yielding higher success on the 134-game ALFWorld unseen split.
What carries the argument
The four-check deterministic verifier (coverage, binding, replacement, risk) applied to clustered procedural passages to produce complete typed contracts that are inlined with concrete action templates.
If this is right
- Agents receive both a typed signature for skill purpose and a concrete invocation template on every retrieval.
- The confused-re-retrieve loop is reduced because input schema and syntax no longer need re-derivation.
- Success rate rises on the ALFWorld unseen split with statistical significance across seeds.
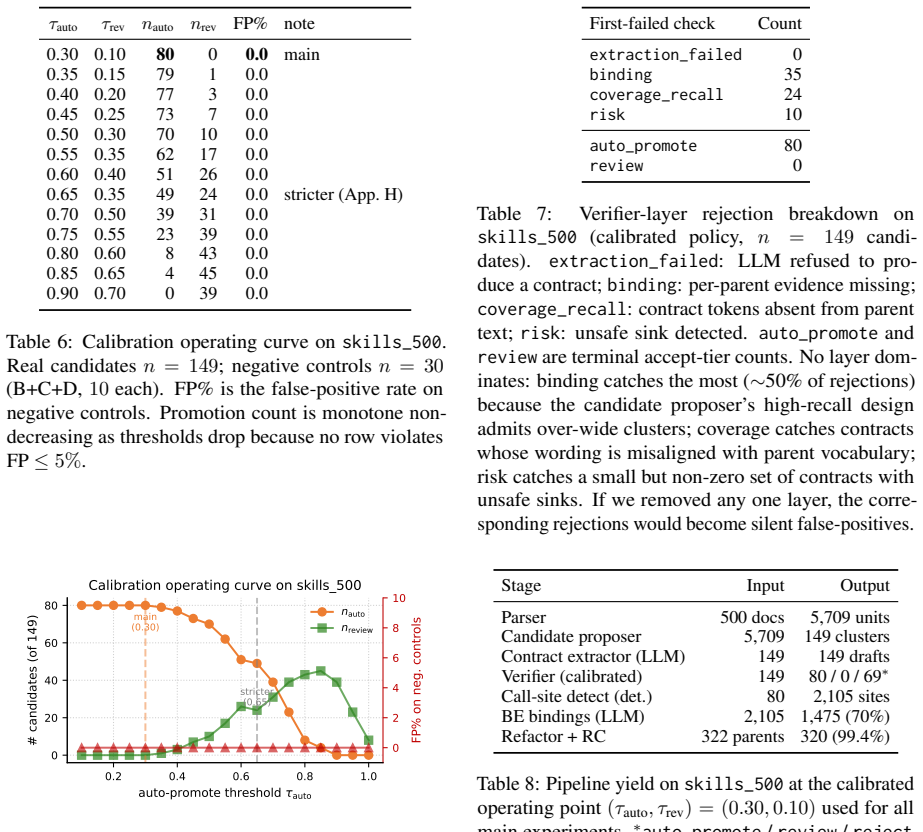
- Input token count drops by roughly 23 percent and LLM calls by roughly 14 percent per game.
Where Pith is reading between the lines
- The same extraction-plus-verifier pipeline could be tested on other agent benchmarks to check whether the token and success gains hold outside ALFWorld.
- Embedding the refactoring step inside an online skill-update loop might let agents maintain and improve their own libraries without human intervention.
- The typed-contract representation could be applied to non-agent retrieval settings that supply procedural text to LLMs.
- Ablating individual verifier checks would reveal which filter is most responsible for the observed performance lift.
Load-bearing premise
The four-check deterministic verifier produces contracts that are complete and free of harmful omissions or over-generalizations that would degrade agent performance.
What would settle it
Re-running the ALFWorld experiments with the verifier disabled or replaced by unfiltered extractions and checking whether the win-rate advantage over the baseline disappears.
Figures


read the original abstract
Markdown skill libraries for LLM agents ship as free-form prose, forcing the agent to re-derive both the input schema and the concrete invocation syntax on every retrieval. We observe that this often produces a "confused -> re-retrieve -> still confused" loop in which the agent issues a partially-correct action, receives uninformative environment feedback, and re-retrieves the same prose. We propose Skill-as-Pseudocode (SaP), an automatic conversion of markdown skill libraries into typed pseudocode with deterministic quality control. For each cluster of similar procedural passages drawn from one or more skills, SaP extracts a typed contract and filters it through a four-check deterministic verifier (coverage, binding, replacement, risk). Promoted contracts are inlined into a rewritten skill skeleton together with restored concrete action templates, giving the agent two complementary signals: a typed signature for what the skill does and a concrete template for how to invoke it. On the 134-game ALFWorld unseen split with gpt-4o-mini, pooled across three seeds, SaP wins 82/402 paired games versus 47/402 for the Graph-of-Skills (GoS) baseline (pooled McNemar p = 8.2e-5), at -22.8 +/- 6.4% input tokens and -14.5 +/- 4.1% LLM calls per game.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Skill-as-Pseudocode (SaP), which automatically refactors markdown skill libraries into typed pseudocode contracts by clustering procedural passages and applying a four-check deterministic verifier (coverage, binding, replacement, risk). Promoted contracts are inlined with concrete action templates. On the 134-game ALFWorld unseen split using gpt-4o-mini (pooled across three seeds), SaP achieves 82/402 wins versus 47/402 for the Graph-of-Skills baseline (McNemar p=8.2e-5), with reported reductions of -22.8% input tokens and -14.5% LLM calls per game.
Significance. If the verifier produces faithful contracts without harmful omissions, the method supplies complementary typed signatures and invocation templates that could reduce the 'confused -> re-retrieve' loop in LLM agents. The concrete head-to-head comparison on a fixed benchmark with pooled seeds and a named baseline (GoS) provides a falsifiable empirical result; the automatic, deterministic nature of the conversion is a practical strength.
major comments (2)
- [Abstract] Abstract: the headline claim of statistically significant improvement rests on the four-check verifier (coverage, binding, replacement, risk) producing complete contracts free of over-generalization; however, the manuscript supplies no implementation details, pseudocode, or decision procedure for any of the four checks, so the weakest assumption cannot be evaluated from the text.
- [Abstract] Abstract and results section: the pooled McNemar test and token/call reductions are reported without a methods subsection describing how the 402 paired games are constructed from the 134-game split across seeds, how clustering is performed, or how the verifier is applied to produce the final skill skeletons.
minor comments (1)
- [Abstract] The abstract states 'pooled across three seeds' but does not indicate whether per-seed breakdowns or variance estimates are supplied in the full results tables.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and have revised the manuscript to provide the requested methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of statistically significant improvement rests on the four-check verifier (coverage, binding, replacement, risk) producing complete contracts free of over-generalization; however, the manuscript supplies no implementation details, pseudocode, or decision procedure for any of the four checks, so the weakest assumption cannot be evaluated from the text.
Authors: We agree that the original manuscript lacked sufficient implementation details for the four checks. In the revised manuscript we have added a dedicated 'Deterministic Verifier' subsection under Methods that supplies pseudocode and explicit decision procedures for coverage, binding, replacement, and risk. These additions make the verifier's behavior fully inspectable and allow direct evaluation of the over-generalization assumption. revision: yes
-
Referee: [Abstract] Abstract and results section: the pooled McNemar test and token/call reductions are reported without a methods subsection describing how the 402 paired games are constructed from the 134-game split across seeds, how clustering is performed, or how the verifier is applied to produce the final skill skeletons.
Authors: We concur that the experimental construction and pipeline steps were under-specified. The revised manuscript now includes three new Methods subsections: 'Paired Game Construction' (detailing how the 402 paired games are formed from the 134-game unseen split across three seeds), 'Clustering Procedure' (specifying the similarity metric and clustering algorithm), and 'Verifier Application' (step-by-step description of how the verifier filters and promotes contracts into the final skill skeletons). These changes make the reported statistics and efficiency gains reproducible from the text. revision: yes
Circularity Check
No significant circularity; empirical result stands independently
full rationale
The paper's central claim is a head-to-head empirical evaluation on the fixed ALFWorld unseen split (82/402 wins for SaP vs 47/402 for GoS, McNemar p=8.2e-5, with token/LLM-call reductions). No derivation, equation, or self-citation chain reduces these measured outcomes to quantities defined by the method's own fitted parameters or prior self-referential results. The four-check verifier is a deterministic preprocessing step whose quality is assessed externally via benchmark performance rather than by construction; the method description and baseline comparison remain self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents
SkillRet: A large-scale benchmark for skill re- trieval in LLM agents.Preprint, arXiv:2605.05726. Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InAdvances in Neural Information Pro- cessing Sys...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Dawei Liu, Zongxia Li, Hongyang Du, Xiyang Wu, Shihang Gui, Yongbei Kuang, and Lichao Sun
2024
-
[3]
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Graph of skills: Dependency-aware struc- tural retrieval for massive agent skills.CoRR, abs/2604.05333. Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024a. Lost in the middle: How language models use long contexts.Transactions of the Asso- ciation for Computational Linguistics, 12:157–173. ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
SkillOps: Managing LLM Agent Skill Libraries as Self-Maintaining Software Ecosystems
OpenReview.net. Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, 11 Jesse Thomason, and Animesh Garg. 2023. Prog- prompt: Generating situated robot task plans using large language models. InIEEE International Con- ference on Robotics and Automation, ICRA 2023, London, UK, May 29 - June 2, 2023, pages 11...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Restgpt: Connecting large language models with real-world restful apis, 2023
RestGPT: Connecting large language mod- els with real-world RESTful APIs.arXiv preprint arXiv:2306.06624. Jonathan Uesato, Nate Kushman, Ramana Kumar, Fran- cis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. Solving math word problems with process- and outcome- based feedback.arXiv:2211.14275. Guanzhi Wang, Yuqi ...
-
[6]
find tomato in cabinets
OpenReview.net. A Library/benchmark match note A pre-experiment sanity check on skills_200 (the GoS runner default) returned identical 5% reward across all four modes on ALF- World. Inspection showed file-organizer and sqlite-map-parser surfacing for the query “find tomato in cabinets”; skills_200 haszero alfworld-* skills, so the agent’s behaviour is ind...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.